nim anywhere
1.0.0

내부 사용자라면 #cdd-nim-anywhere Slack 채널에 가입하시고, 질문이나 피드백이 있으시면 외부 사용자라면 이슈를 열어주세요.
기업용 AI 사용의 주요 이점 중 하나는 내부 데이터를 사용하고 학습할 수 있는 능력입니다. 검색 증강 생성(RAG)은 이를 수행하는 가장 좋은 방법 중 하나입니다. NVIDIA는 파트너와 고객이 효과적인 RAG 파이프라인을 쉽게 구축할 수 있도록 NIM 마이크로 서비스라는 마이크로 서비스 세트를 개발했습니다.
NIM Anywhere에는 RAG용 NIM 통합을 시작하는 데 필요한 모든 도구가 포함되어 있습니다. 기본적으로 전체 규모의 연구실과 프로덕션 환경까지 확장됩니다. 이는 RAG 아키텍처를 구축하고 필요에 따라 NIM을 쉽게 추가할 수 있는 좋은 소식입니다. RAG에 익숙하지 않은 경우 RAG는 모델 자체를 수정하지 않고 추론 중에 관련 외부 정보를 동적으로 검색합니다. 귀하가 기밀 최신 정보가 포함된 로컬 데이터베이스를 보유한 회사의 기술 책임자라고 상상해 보십시오. OpenAI가 데이터에 액세스하는 것을 원하지 않지만 질문에 정확하게 대답하려면 데이터를 이해하는 모델이 필요합니다. 해결책은 언어 모델을 데이터베이스에 연결하고 정보를 제공하는 것입니다.
RAG가 생성 AI 모델의 정확성과 신뢰성을 높이는 데 탁월한 솔루션인 이유에 대해 자세히 알아보려면 이 블로그를 읽어보세요.
빠른 시작 지침을 통해 지금 NIM Anywhere를 시작하고 NIM을 사용하여 첫 번째 RAG 애플리케이션을 구축하세요!
AI Workbench가 NVIDIA의 클라우드 리소스에 액세스할 수 있도록 하려면 개인 키를 제공해야 합니다. 이 키는 nvapi- 로 시작합니다.
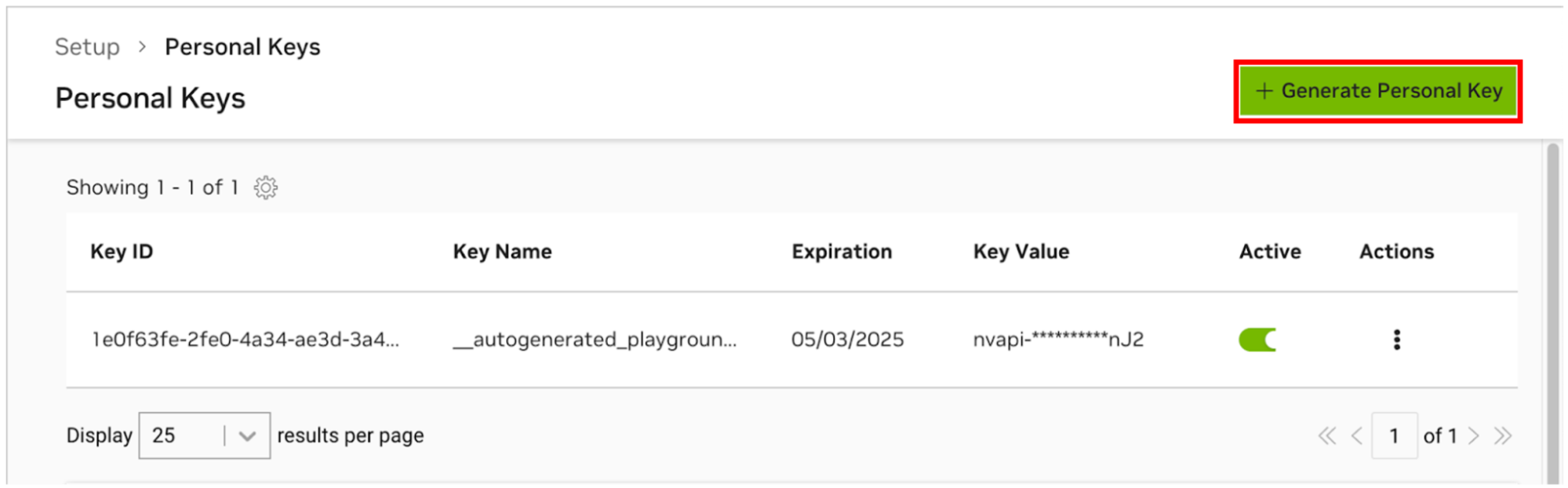
NGC 개인 키 관리자로 이동합니다. 메시지가 나타나면 새 계정을 등록하고 로그인하세요.
힌트 이 도구는 ngc.nvidia.com에 로그인하여 오른쪽 상단의 프로필 메뉴를 확장하고 설정을 선택한 다음 개인 키 생성을 선택하여 찾을 수 있습니다.
개인 키 생성 을 선택합니다.
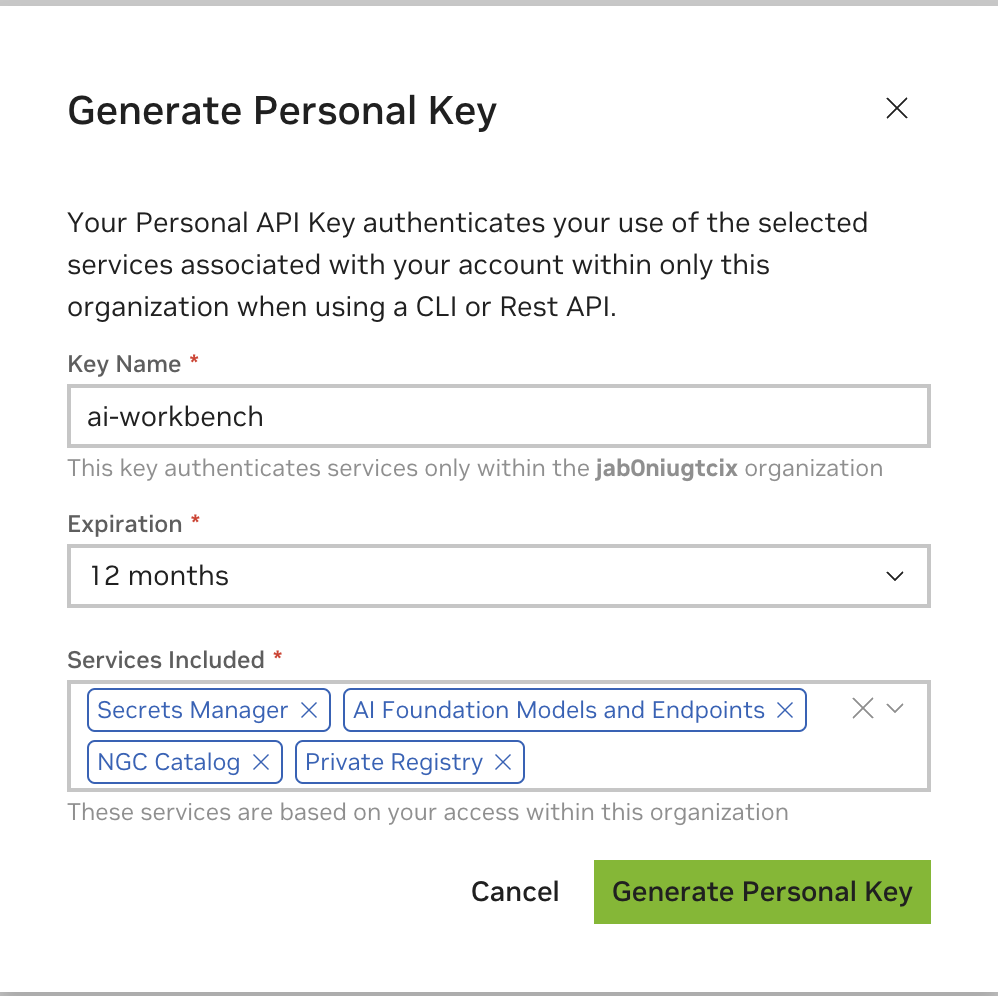
키 이름으로 임의의 값을 입력하고 12개월 만료가 허용되며 모든 서비스를 선택합니다. 완료되면 개인 키 생성을 누르세요.
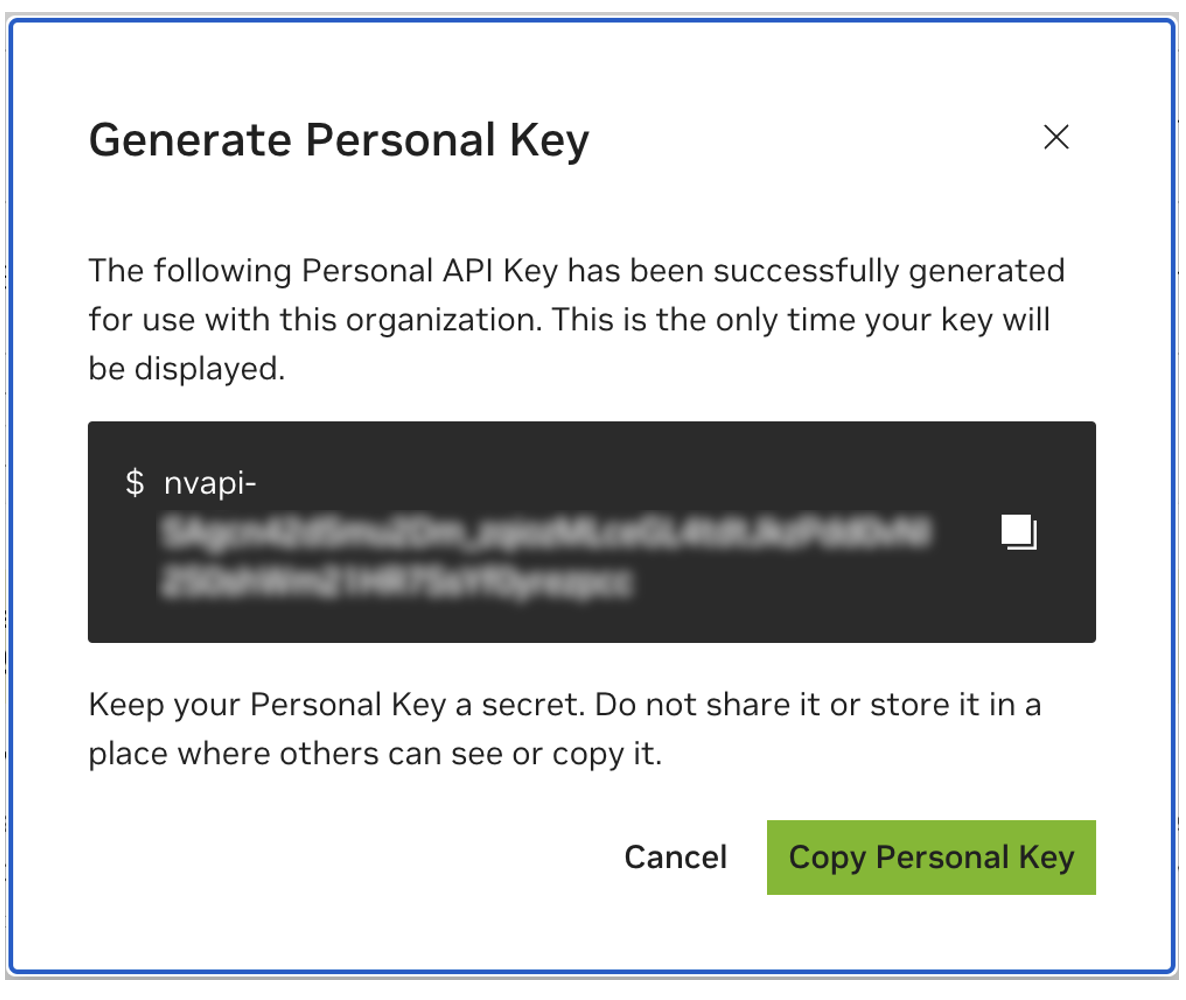
나중에 사용할 수 있도록 개인 키를 저장하세요. Workbench에는 이 정보가 필요하며 나중에 검색할 수 있는 방법이 없습니다. 키를 분실한 경우 새 키를 만들어야 합니다. 이 키를 비밀번호처럼 보호하세요.
이 프로젝트는 NVIDIA AI Workbench와 함께 사용하도록 설계되었습니다. 필수 사항은 아니지만 AI Workbench 없이 이 데모를 실행하려면 사전 구성된 자동화 및 통합을 사용하지 못할 수 있으므로 수동 작업이 필요합니다.
이 빠른 시작 가이드에서는 원격 랩 컴퓨터가 개발에 사용되고 로컬 컴퓨터가 개발 컴퓨터에 원격으로 액세스하기 위한 씬 클라이언트라고 가정합니다. 이를 통해 컴퓨팅 리소스를 중앙에 유지하고 개발자의 이동성을 더욱 높일 수 있습니다. 원격 랩 컴퓨터에서는 Ubuntu를 실행해야 하지만 로컬 클라이언트에서는 Windows, MacOS 또는 Ubuntu를 실행할 수 있습니다. 이 프로젝트를 로컬에만 설치하려면 원격 설치를 건너뛰세요.
흐름도 LR
현지의
하위 그래프 랩 환경
원격 연구실 기계
끝
로컬 <-.ssh.-> 원격 실험실 기계
로컬 클라이언트를 개발에도 사용하려면 Ubuntu가 필요합니다. 원격 랩 컴퓨터를 사용하는 경우 Windows, MacOS 또는 Ubuntu가 될 수 있습니다.
전체 지침은 NVIDIA AI Workbench 사용자 가이드를 참조하세요.
필수 소프트웨어 설치
NVIDIA AI Workbench 설치 프로그램을 다운로드하고 실행합니다. 설치 프로그램이 변경할 수 있도록 Windows에 권한을 부여합니다.
설치 마법사의 지침을 따르십시오. WSL2를 설치해야 하는 경우 Windows에 권한을 부여하여 변경하고 요청 시 로컬 컴퓨터를 재부팅하세요. 시스템이 다시 시작되면 NVIDIA AI Workbench 설치 프로그램이 자동으로 재개됩니다.
Docker를 컨테이너 런타임으로 선택합니다.
GitHub.com을 통해 로그인 옵션을 사용하여 GitHub 계정에 로그인하세요.
요청된 경우 Git 작성자 정보를 입력하세요.
전체 지침은 NVIDIA AI Workbench 사용자 가이드를 참조하세요.
필수 소프트웨어 설치
NVIDIA AI Workbench 디스크 이미지( .dmg 파일)를 다운로드하여 엽니다.
AI Workbench를 애플리케이션 폴더로 드래그하고 애플리케이션 실행기에서 NVIDIA AI Workbench를 실행하세요. 
Docker를 컨테이너 런타임으로 선택합니다.
GitHub.com을 통해 로그인 옵션을 사용하여 GitHub 계정에 로그인하세요.
요청된 경우 Git 작성자 정보를 입력하세요.
전체 지침은 NVIDIA AI Workbench 사용자 가이드를 참조하세요. Workbench 사용자가 될 사용자로 이 설치를 실행하십시오. root 로 이 단계를 실행하지 마십시오.
필수 소프트웨어 설치
NVIDIA AI Workbench 설치 프로그램을 다운로드하여 실행 가능하게 만든 다음 실행하세요. 다음 명령을 사용하여 파일을 실행 가능하게 만들 수 있습니다.
chmod +x NVIDIA-AI-Workbench- * .AppImageAI Workbench가 NVIDIA 드라이버를 자동으로 설치합니다(필요한 경우). 드라이버를 설치한 후 로컬 시스템을 재부팅한 다음 바탕 화면에서 NVIDIA AI Workbench 아이콘을 두 번 클릭하여 AI Workbench 설치를 다시 시작해야 합니다.
Docker를 컨테이너 런타임으로 선택합니다.
GitHub.com을 통해 로그인 옵션을 사용하여 GitHub 계정에 로그인하세요.
요청된 경우 Git 작성자 정보를 입력하세요.
원격 시스템에는 Ubuntu만 지원됩니다.
전체 지침은 NVIDIA AI Workbench 사용자 가이드를 참조하세요. Workbench를 사용할 사용자로 이 설치를 실행하십시오. root 로 이 단계를 실행하지 마십시오.
로컬 시스템에서 원격 시스템으로 SSH 키 기반 인증이 활성화되어 있는지 확인하십시오. 현재 활성화되어 있지 않은 경우 대부분의 상황에서는 다음 명령을 사용하여 활성화할 수 있습니다. 원격 주소를 반영하도록 REMOTE_USER 및 REMOTE-MACHINE 변경합니다.
ssh - keygen -f " C:Userslocal-user.sshid_rsa " - t rsa - N ' "" '
type $ env: USERPROFILE .sshid_rsa.pub | ssh REMOTE_USER @REMOTE - MACHINE " cat >> .ssh/authorized_keys " if [ ! -e ~ /.ssh/id_rsa ] ; then ssh-keygen -f ~ /.ssh/id_rsa -t rsa -N " " ; fi
ssh-copy-id REMOTE_USER@REMOTE-MACHINE원격 호스트에 SSH로 접속합니다. 그런 다음 다음 명령을 사용하여 NVIDIA AI Workbench 설치 프로그램을 다운로드하고 실행합니다.
mkdir -p $HOME /.nvwb/bin &&
curl -L https://workbench.download.nvidia.com/stable/workbench-cli/ $( curl -L -s https://workbench.download.nvidia.com/stable/workbench-cli/LATEST ) /nvwb-cli- $( uname ) - $( uname -m ) --output $HOME /.nvwb/bin/nvwb-cli &&
chmod +x $HOME /.nvwb/bin/nvwb-cli &&
sudo -E $HOME /.nvwb/bin/nvwb-cli installAI Workbench가 NVIDIA 드라이버를 자동으로 설치합니다(필요한 경우). 드라이버를 설치한 후 원격 시스템을 재부팅한 다음 이전 단계의 명령을 다시 실행하여 AI Workbench 설치를 다시 시작해야 합니다.
Docker를 컨테이너 런타임으로 선택합니다.
GitHub.com을 통해 로그인 옵션을 사용하여 GitHub 계정에 로그인하세요.
요청된 경우 Git 작성자 정보를 입력하세요.
원격 설치가 완료되면 로컬 AI Workbench 인스턴스에 원격 위치를 추가할 수 있습니다. AI Workbench 애플리케이션을 열고 원격 위치 추가를 클릭한 후 필요한 정보를 입력합니다. 완료되면 위치 추가 를 클릭합니다.
REMOTE-MACHINE 과 동일해야 합니다.REMOTE_USER 와 동일해야 합니다./home/USER/.ssh/id_rsa 여야 합니다.로컬 사용을 위해 이 프로젝트를 다운로드하는 방법에는 복제와 포크라는 두 가지 방법이 있습니다.
이 저장소를 복제하는 것이 권장되는 시작 방법입니다. 이는 로컬 수정을 허용하지 않지만 시작하는 것이 가장 빠릅니다. 이는 또한 업데이트를 가져오는 가장 쉬운 방법을 허용합니다.
변경 사항을 저장할 수 있으므로 개발 시 이 저장소를 포크하는 것이 좋습니다. 그러나 업데이트를 받으려면 포크 관리자가 정기적으로 업스트림 저장소에서 가져와야 합니다. 포크에서 작업하려면 GitHub의 지침을 따른 다음 이 섹션의 나머지 부분에서 개인 포크에 대한 URL을 참조하세요.
로컬 NVIDIA AI Workbench 창을 엽니다. 표시된 위치 목록에서 방금 설정한 원격 위치를 선택하거나 로컬에서 작업하려는 경우 로컬을 선택합니다.
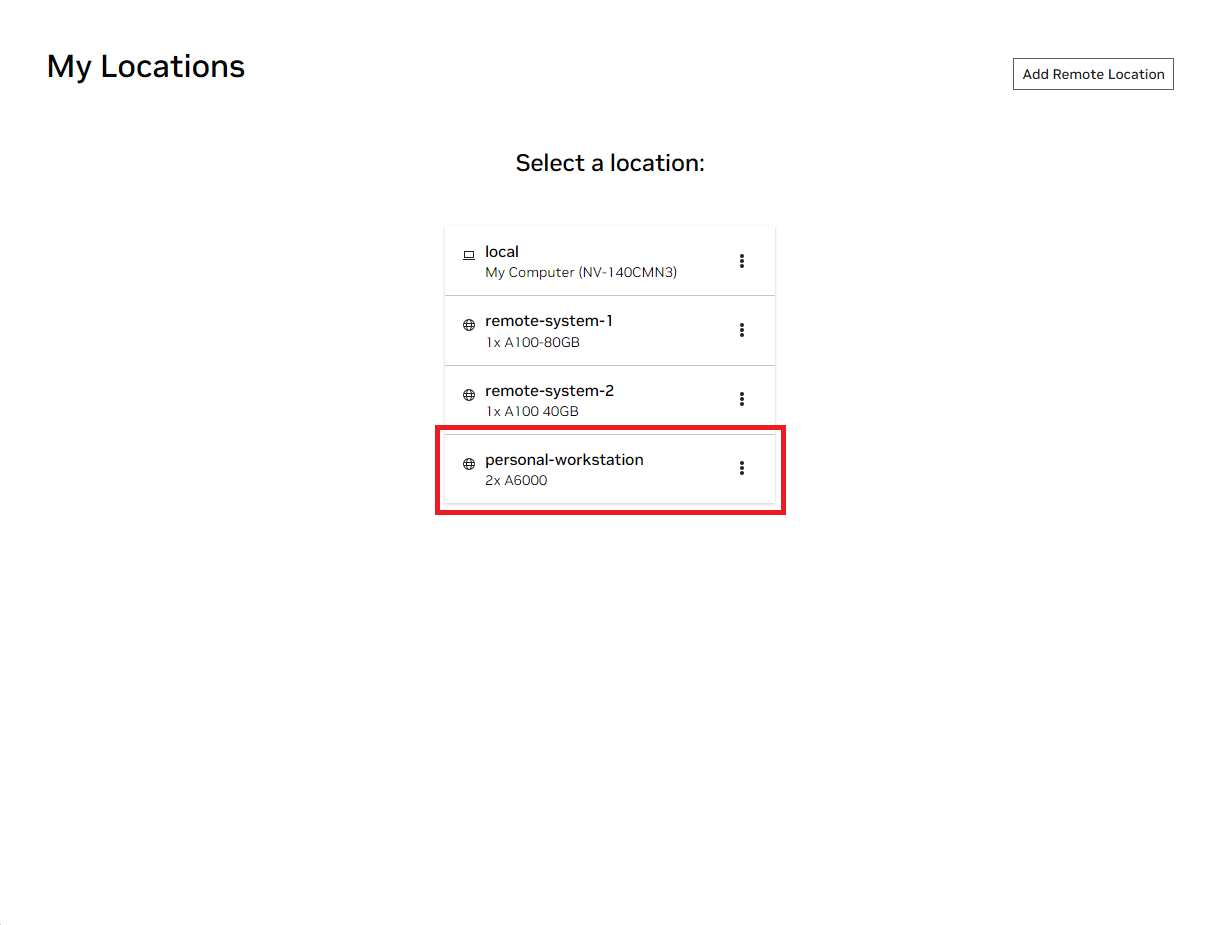
해당 위치에 들어가면 Clone Project 를 선택합니다.
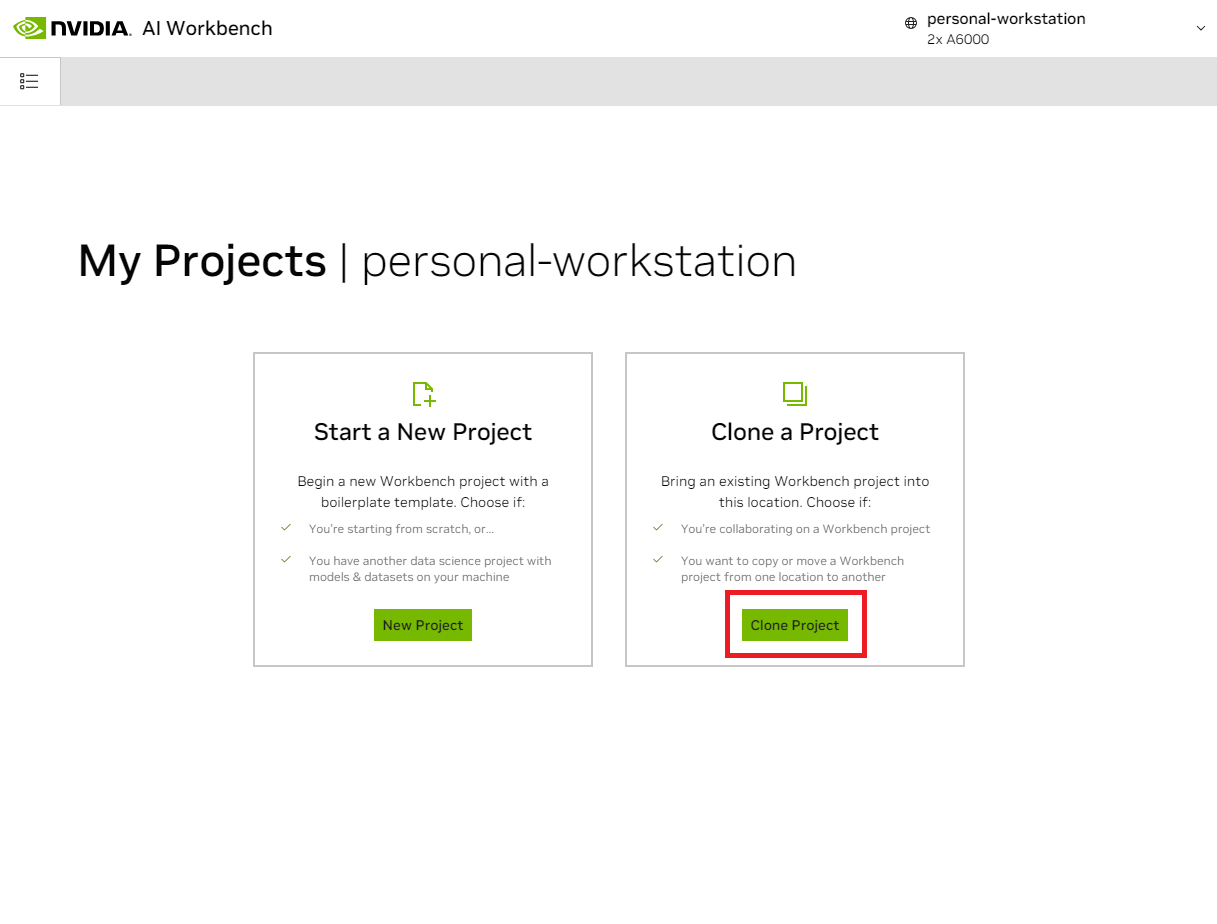
'Clone Project' 팝업 창에서 Repository URL을 https://github.com/NVIDIA/nim-anywhere.git 으로 설정하세요. 경로를 기본값인 /home/REMOTE_USER/nvidia-workbench/nim-anywhere.git 으로 그대로 둘 수 있습니다. 복제를 클릭하세요.`
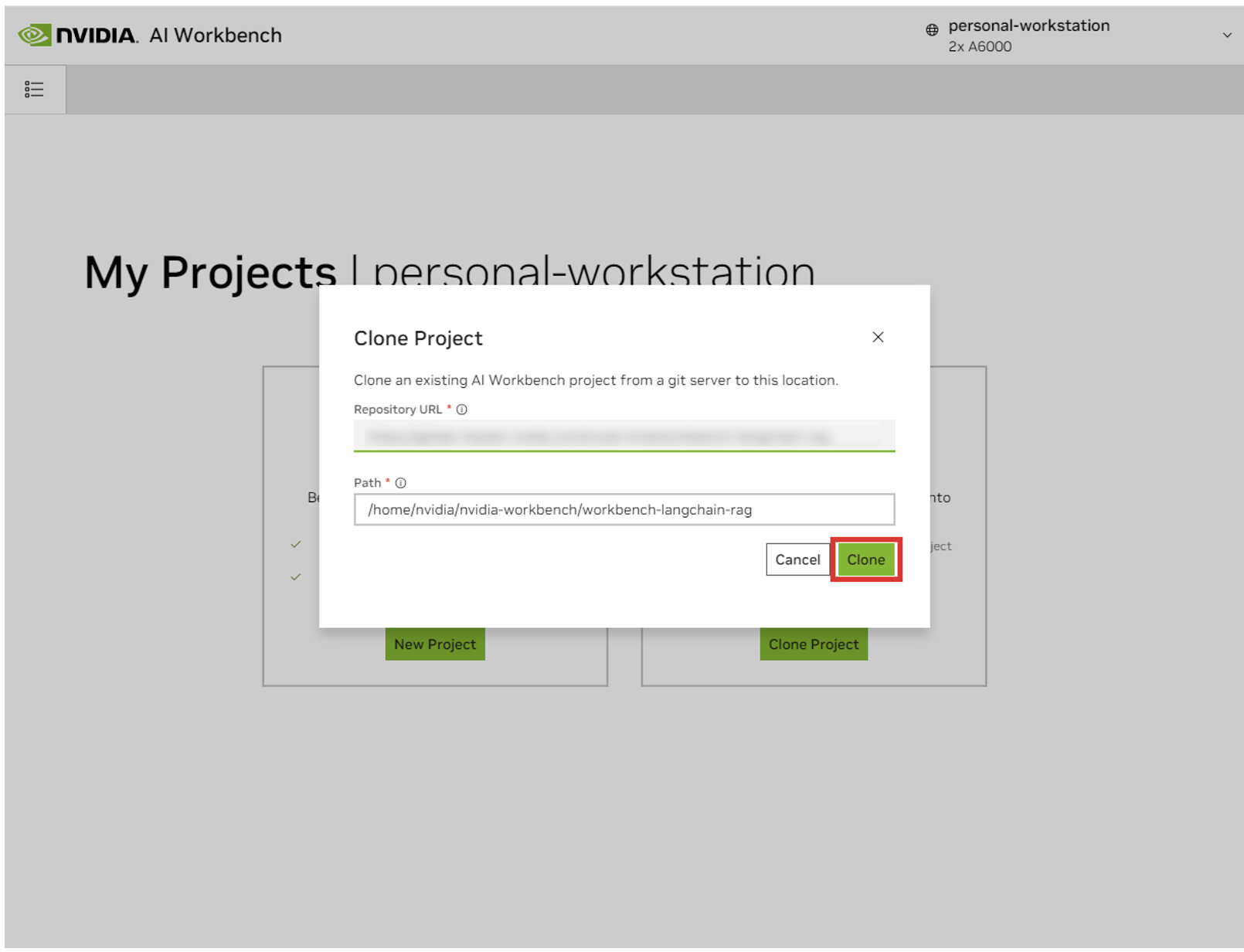
새 프로젝트 페이지로 리디렉션됩니다. Workbench는 개발 환경을 자동으로 부트스트랩합니다. 창 하단에서 출력을 확장하면 실시간 진행 상황을 볼 수 있습니다.
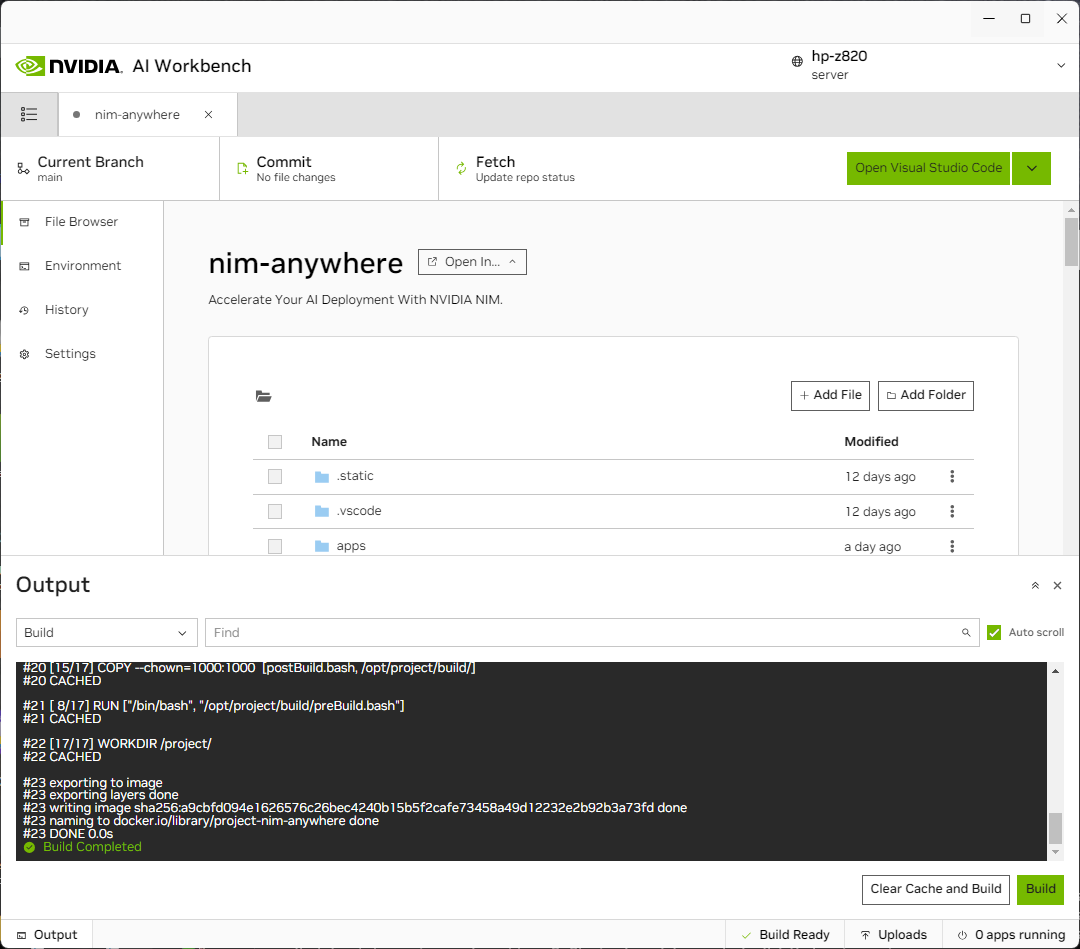
프로젝트는 로컬 컴퓨터 리소스와 함께 작동하도록 구성되어야 합니다.
처음 실행하기 전에 프로젝트별 구성을 제공해야 합니다. 프로젝트 구성은 왼쪽 패널의 환경 탭을 사용하여 수행됩니다.
변수 섹션까지 아래로 스크롤하여 NGC_HOME 항목을 찾습니다. ~/.cache/nvidia-nims 와 같이 설정되어야 합니다. 여기에 있는 값은 워크벤치에서 사용됩니다. 이 디렉터리를 컨테이너에 탑재하는 Mounts 섹션에도 동일한 위치가 나타납니다.
비밀 섹션까지 아래로 스크롤하여 NGC_API_KEY 항목을 찾습니다. 구성을 누르고 이전에 생성된 NGC에 대한 개인 키를 제공합니다.
마운트 섹션까지 아래로 스크롤합니다. 여기서는 두 개의 마운트를 구성해야 합니다.
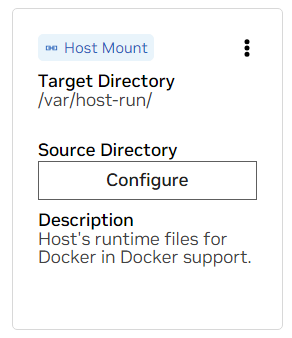
에이. /var/host-run에 대한 마운트를 찾습니다. 이는 개발 환경이 Docker에서 Docker라는 패턴으로 호스트의 Docker 데몬에 액세스할 수 있도록 하는 데 사용됩니다. 구성을 누르고 /var/run 디렉토리를 제공하십시오.
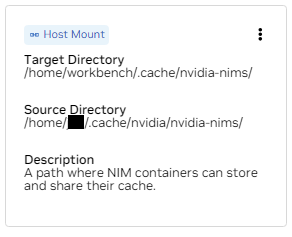
비. /home/workbench/.cache/nvidia-nims에 대한 마운트를 찾으십시오. 이 마운트는 모델 파일을 캐시할 수 있는 NIM용 런타임 캐시로 사용됩니다. 이 캐시를 호스트와 공유하면 디스크 사용량과 네트워크 대역폭이 줄어듭니다.
nim 캐시가 아직 없거나 확실하지 않은 경우 다음 명령을 사용하여 /home/USER/.cache/nvidia-nims 에 생성하세요.
mkdir -p ~ /.cache/nvidia-nims
chmod 2777 ~ /.cache/nvidia-nims이러한 설정이 변경된 후에 재구축이 발생합니다.
Build Ready 메시지와 함께 빌드가 완료되면 모든 애플리케이션을 사용할 수 있게 됩니다.
가장 기본적인 LLM 체인조차도 몇 가지 추가 마이크로서비스에 의존합니다. 이는 인메모리 대안을 개발하는 동안 무시할 수 있지만 프로덕션으로 이동하려면 코드 변경이 필요합니다. 다행히 Workbench는 개발 환경을 위한 추가 마이크로서비스를 관리합니다.
힌트: 각 애플리케이션에 대해 왼쪽 하단에 있는 출력 링크를 클릭하고 드롭다운 메뉴를 선택한 다음 관심 있는 애플리케이션을 선택하여 UI에서 디버그 출력을 모니터링할 수 있습니다.
이 작업공간에 번들로 포함된 모든 애플리케이션은 환경 > 애플리케이션 으로 이동하여 제어할 수 있습니다.
먼저 Milvus Vector DB 와 Redis를 켭니다. Milvus는 구조화되지 않은 지식 기반으로 사용되고 Redis는 대화 기록을 저장하는 데 사용됩니다.
이러한 서비스가 시작되면 체인 서버를 안전하게 시작할 수 있습니다. 여기에는 추론 체인을 수행하기 위한 사용자 정의 LangChain 코드가 포함되어 있습니다. 기본적으로 로컬 Milvus 및 Redis를 사용하지만 LLM 및 임베딩 모델 추론에는 ai.nvidia.com을 사용합니다.
[선택사항]: 다음으로 LLM NIM을 시작합니다. LLM NIM을 처음 시작하면 이미지와 최적화된 모델을 다운로드하는 데 약간의 시간이 걸립니다.
에이. 장기간 시작하는 동안 LLM NIM이 시작되는지 확인하기 위해 UI 왼쪽 하단에 있는 출력 창을 사용하여 로그를 보면 진행 상황을 관찰할 수 있습니다.
비. 로그에 인증 오류가 표시되면 제공된 NGC_API_KEY에 NIM에 대한 액세스 권한이 없다는 의미입니다. NVIDIA AI Enterprise 지원 또는 평가판이 있는 NGC 조직에서 올바르게 생성되었는지 확인하세요.
기음. 로그가 멈춘 것처럼 보이는 경우 ..........: Pull complete . ..........: Verifying complete , 또는 ..........: Download complete ; 이는 컨테이너 이미지의 다양한 레이어가 다운로드되었다는 Docker의 일반적인 출력입니다.
디. 여기서 다른 오류가 있으면 해결해야 합니다.
체인 서버가 가동되면 채팅 인터페이스를 시작할 수 있습니다. 인터페이스를 시작하면 자동으로 브라우저 창에서 열립니다.
데모 개발을 시작하려면 데이터가 벡터 데이터베이스에 수집되는 방법을 보여주는 Jupyter Notebook과 함께 샘플 데이터세트가 제공됩니다.
PDF 문서를 벡터 데이터베이스로 가져오려면 AI Workbench의 앱 실행 프로그램을 사용하여 Jupyter를 엽니다.
code/upload-pdfs.ipynb 에서 Jupyter Notebook을 사용하여 기본 데이터 세트를 수집합니다. 기본 데이터 세트를 사용하는 경우 변경할 필요가 없습니다.
사용자 정의 데이터 세트를 사용하는 경우 이를 Jupyter의 data/ 디렉터리에 업로드하고 필요에 따라 제공된 노트북을 수정합니다.
이 프로젝트에는 몇 가지 데모 서비스에 대한 애플리케이션과 외부 서비스와의 통합이 포함되어 있습니다. 이는 모두 NVIDIA AI Workbench에 의해 조정됩니다.
데모 서비스는 모두 code 폴더에 있습니다. 코드 폴더의 루트 수준에는 기술 심층 분석을 위한 몇 가지 대화형 노트북이 있습니다. 체인 서버는 LangChain과 함께 NIM을 활용하는 샘플 애플리케이션입니다. (여기서 체인 서버는 RAG를 사용하거나 사용하지 않고 실험할 수 있는 옵션을 제공합니다.) Chat Frontend 폴더에는 체인 서버를 실행하기 위한 대화형 UI 서버가 포함되어 있습니다. 마지막으로, 검색 채점 및 검증을 보여주기 위해 평가 디렉터리에 샘플 노트북이 제공됩니다.
마인드맵
root((AI 워크벤치))
데모 서비스
체인 서버<br />LangChain + NIM
프런트엔드<br />대화형 데모 UI
평가<br />결과 검증
노트북<br />고급 사용법
통합
Redis</br>대화 기록
Milvus</br>벡터 데이터베이스
LLM NIM</br>최적화된 LLM
체인 서버는 구성 파일이나 환경 변수를 사용하여 구성할 수 있습니다.
기본적으로 애플리케이션은 다음 위치 모두에서 구성 파일을 검색합니다. 여러 구성 파일이 발견되면 목록에 있는 하위 파일의 값이 우선적으로 적용됩니다.
APP_CONFIG 라는 환경 변수를 통해 추가 구성 파일 경로를 지정할 수 있습니다. 이 파일의 값은 모든 기본 파일 위치보다 우선합니다.
export APP_CONFIG=/etc/my_config.yaml 환경 변수를 사용하여 구성을 설정할 수도 있습니다. 변수 이름의 형식은 다음과 같습니다. APP_FIELD__SUB_FIELD 환경 변수로 지정된 값은 파일의 모든 값보다 우선합니다.
# Your API key for authentication to AI Foundation.
# ENV Variables: NGC_API_KEY, NVIDIA_API_KEY, APP_NVIDIA_API_KEY
# Type: string, null
nvidia_api_key : ~
# The Data Source Name for your Redis DB.
# ENV Variables: APP_REDIS_DSN
# Type: string
redis_dsn : redis://localhost:6379/0
llm_model :
# The name of the model to request.
# ENV Variables: APP_LLM_MODEL__NAME
# Type: string
name : meta/llama3-8b-instruct
# The URL to the model API.
# ENV Variables: APP_LLM_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
embedding_model :
# The name of the model to request.
# ENV Variables: APP_EMBEDDING_MODEL__NAME
# Type: string
name : nvidia/nv-embedqa-e5-v5
# The URL to the model API.
# ENV Variables: APP_EMBEDDING_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
reranking_model :
# The name of the model to request.
# ENV Variables: APP_RERANKING_MODEL__NAME
# Type: string
name : nv-rerank-qa-mistral-4b:1
# The URL to the model API.
# ENV Variables: APP_RERANKING_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
milvus :
# The host machine running Milvus vector DB.
# ENV Variables: APP_MILVUS__URL
# Type: string
url : http://localhost:19530
# The name of the Milvus collection.
# ENV Variables: APP_MILVUS__COLLECTION_NAME
# Type: string
collection_name : collection_1
log_level :
채팅 프런트엔드에는 몇 가지 구성 옵션도 있습니다. 체인서버와 동일하게 설정할 수 있습니다.
# The URL to the chain on the chain server.
# ENV Variables: APP_CHAIN_URL
# Type: string
chain_url : http://localhost:3030/
# The url prefix when this is running behind a proxy.
# ENV Variables: PROXY_PREFIX, APP_PROXY_PREFIX
# Type: string
proxy_prefix : /
# Path to the chain server's config.
# ENV Variables: APP_CHAIN_CONFIG_FILE
# Type: string
chain_config_file : ./config.yaml
log_level :
이 프로젝트에 대한 모든 피드백과 기여를 환영합니다. 개인적인 사용이나 기여를 위해 이 프로젝트를 변경할 때 이 프로젝트에서 포크 작업을 하는 것이 좋습니다. 포크에서 변경이 완료되면 병합 요청이 열려야 합니다.
이 프로젝트는 코드가 지나치게 부담스럽지 않으면서 일관성을 유지할 수 있도록 조정된 Linter로 구성되었습니다. 우리는 다음과 같은 린터를 사용합니다:
임베디드 VSCode 환경은 린팅과 체크를 실시간으로 실행하도록 구성되어 있습니다.
CI 파이프라인에서 수행되는 Linting을 수동으로 실행하려면 /project/code/tools/lint.sh 실행하세요. 개별 테스트는 이름으로 지정하여 실행할 수 있습니다: /project code/tools/lint.sh [deps|pylint|mypy|black|docs|fix] . 수정 모드에서 Lint 도구를 실행하면 Black을 실행하고 README를 업데이트하고 모든 Jupyter 노트북에서 셀 출력을 지워 가능한 내용을 자동으로 수정합니다.
프런트엔드는 필요한 HTML 및 Javascript 개발을 최소화하기 위한 노력으로 설계되었습니다. 바닐라 HTML, Javascript 및 CSS로 생성된 브랜드화되고 스타일이 지정된 애플리케이션 셸이 제공됩니다. 쉽게 사용자 정의할 수 있도록 설계되었지만 반드시 필요한 것은 아닙니다. 프런트엔드의 대화형 구성 요소는 모두 Gradio에서 생성되고 iframe을 사용하여 앱 셸에 마운트됩니다.
앱 셸 상단에는 사용 가능한 보기를 나열하는 메뉴가 있습니다. 각 보기에는 하나 또는 몇 개의 페이지로 구성된 자체 레이아웃이 있을 수 있습니다.
페이지에는 데모를 위한 대화형 구성 요소가 포함되어 있습니다. 페이지의 코드는 code/frontend/pages 디렉터리에 있습니다. 새 페이지를 만들려면:
__init__.py 파일을 만듭니다. Gradio Blocks 레이아웃은 page 라는 변수에 정의되어야 합니다.chat 페이지를 참조하세요.code/frontend/pages/__init__.py 파일을 열고 새 페이지를 가져온 다음 새 페이지를 __all__ 목록에 추가하세요.참고: 새 페이지를 생성해도 프런트엔드에 추가되지 않습니다. 프런트엔드에 표시하려면 뷰에 추가해야 합니다.
보기는 하나 또는 몇 개의 페이지로 구성되며 서로 독립적으로 작동해야 합니다. 뷰는 모두 code/frontend/server.py 모듈에 정의되어 있습니다. 선언된 모든 뷰는 프런트엔드의 메뉴 표시줄에 자동으로 추가되고 UI에서 사용할 수 있게 됩니다.
새 보기를 정의하려면 views 라는 목록을 수정합니다. View 객체의 목록입니다. 개체의 순서는 프런트엔드 메뉴에서의 순서를 정의합니다. 첫 번째 정의된 보기가 기본값이 됩니다.
뷰 객체는 뷰 이름과 레이아웃을 설명합니다. 다음과 같이 선언할 수 있습니다.
my_view = frontend . view . View (
name = "My New View" , # the name in the menu
left = frontend . pages . sample_page , # the page to show on the left
right = frontend . pages . another_page , # the page to show on the right
) 모든 페이지 선언( View.left 또는 View.right )은 선택 사항입니다. 선언되지 않은 경우 웹 레이아웃의 연결된 iframe이 숨겨집니다. 다른 iframe은 공백을 채우기 위해 확장됩니다. 다음 다이어그램은 다양한 레이아웃을 보여줍니다.
블록베타
열 1
메뉴["메뉴바"]
차단하다
열 2
왼쪽 오른쪽
끝
블록베타
열 1
메뉴["메뉴바"]
차단하다
열 1
왼쪽:1
끝
프런트엔드에는 다양한 사용 사례에 맞게 맞춤설정할 수 있는 몇 가지 브랜드 자산이 포함되어 있습니다.
프런트엔드에는 페이지 왼쪽 상단에 로고가 있습니다. 로고를 수정하려면 원하는 로고의 SVG가 필요합니다. 그러면 code/frontend/_assets/index.html 파일을 수정하여 새 SVG를 사용하도록 앱 셸을 쉽게 수정할 수 있습니다. ID가 logo 인 단일 div 있습니다. 이 상자에는 단일 SVG가 포함되어 있습니다. 이를 원하는 SVG 정의로 업데이트하세요.
< div id =" logo " class =" logo " >
< svg viewBox =" 0 0 164 30 " > ... </ svg >
</ div > 앱 셸의 스타일은 code/frontend/_static/css/style.css 에 정의되어 있습니다. 이 파일의 색상은 안전하게 수정될 수 있습니다.
다양한 페이지의 스타일은 code/frontend/pages/*/*.css 에 정의되어 있습니다. 이러한 파일에는 사용자 정의 색 구성표를 수정해야 할 수도 있습니다.
Gradio 테마는 code/frontend/_assets/theme.json 파일에 정의되어 있습니다. 이 파일의 색상은 원하는 브랜드로 안전하게 수정할 수 있습니다. 이 파일의 다른 스타일도 변경될 수 있지만 프런트엔드에 큰 변화가 발생할 수 있습니다. Gradio 문서에는 Gradio 테마에 대한 자세한 정보가 포함되어 있습니다.
참고: 이는 대부분의 개발자에게 절대 필요하지 않은 고급 주제입니다.
경우에 따라 서로 통신하는 보기에 여러 페이지가 있어야 할 수도 있습니다. 이를 위해 Javascript의 postMessage 메시징 프레임워크가 사용됩니다. 애플리케이션 셸에 게시된 모든 신뢰할 수 있는 메시지는 페이지가 원하는 대로 메시지를 처리할 수 있는 각 iframe으로 전달됩니다. control 페이지는 이 기능을 사용하여 chat 페이지의 구성을 수정합니다.
다음은 앱 셸( window.top )에 메시지를 게시합니다. 메시지에는 use_kb 키와 true 값이 있는 사전이 포함됩니다. Gradio를 사용하면 이 Javascript는 모든 Gradio 이벤트에서 실행될 수 있습니다.
window . top . postMessage ( { "use_kb" : true } , '*' ) ; 이 메시지는 앱 셸에 의해 모든 페이지에 자동으로 전송됩니다. 다음 샘플 코드는 다른 페이지의 메시지를 사용합니다. 이 코드는 message 이벤트가 수신되면 비동기적으로 실행됩니다. 메시지를 신뢰할 수 있으면 elem_id 가 use_kb 인 Gradio 구성 요소가 메시지에 지정된 값으로 업데이트됩니다. 이러한 방식으로 Gradio 구성 요소의 값을 여러 페이지에 걸쳐 복제할 수 있습니다.
window . addEventListener (
"message" ,
( event ) => {
if ( event . isTrusted ) {
use_kb = gradio_config . components . find ( ( element ) => element . props . elem_id == "use_kb" ) ;
use_kb . props . value = event . data [ "use_kb" ] ;
} ;
} ,
false ) ; README는 자동으로 렌더링됩니다. 직접 편집한 내용은 덮어쓰게 됩니다. README를 수정하려면 각 섹션의 파일을 별도로 편집해야 합니다. 이러한 파일은 모두 결합되고 README가 자동으로 생성됩니다. docs 폴더에서 관련 파일을 모두 찾을 수 있습니다.
문서는 Github Flavored Markdown으로 작성된 다음 Pandoc에 의해 최종 Markdown 파일로 렌더링됩니다. 이 프로세스에 대한 세부 사항은 Makefile에 정의되어 있습니다. 생성되는 파일의 순서는 docs/_TOC.md 에 정의되어 있습니다. 워크벤치 파일 브라우저 창에서 문서를 미리 볼 수 있습니다.
헤더 파일은 문서를 컴파일하는 데 사용되는 첫 번째 파일입니다. 이 파일은 docs/_HEADER.md 에서 찾을 수 있습니다. 이 파일의 내용은 다른 어떤 것보다 먼저 README에 아무런 조작 없이 그대로 기록됩니다.
요약 파일에는 이 프로젝트를 설명하는 빠른 설명과 그래픽이 포함되어 있습니다. 이 파일의 내용은 README의 헤더 바로 뒤, 목차 바로 앞에 추가됩니다. 이 파일은 README에 쓰기 전에 이미지를 삽입하기 위해 Pandoc에서 처리됩니다.
문서에서 가장 중요한 파일은 docs/_TOC.md 에 있는 목차 파일입니다. 이 파일은 최종 README 매뉴얼을 생성하기 위해 연결되어야 하는 파일 목록을 정의합니다. 포함하려면 파일이 이 목록에 있어야 합니다.
이미지를 포함한 모든 정적 콘텐츠를 _static 폴더에 저장합니다. 이것은 조직에 도움이 될 것입니다.
스스로 업데이트하고 작성하는 문서를 갖는 것이 도움이 될 수 있습니다. 동적 문서를 생성하려면 Markdown 형식의 문서를 stdout에 기록하는 실행 파일을 생성하기만 하면 됩니다. 빌드 시간 동안 목차 파일의 항목이 실행 가능하면 해당 항목이 실행되고 그 자리에 해당 stdout이 사용됩니다.
문서 관련 커밋이 푸시되면 GitHub Action이 문서를 렌더링합니다. README에 대한 모든 변경 사항은 자동으로 커밋됩니다.
개발 환경에 대한 대부분의 구성은 환경 변수를 통해 이루어집니다. 환경 변수를 영구적으로 변경하려면 variables.env 수정하거나 Workbench UI를 사용하십시오.
이 프로젝트는 /usr/bin/python3 에서 하나의 Python 환경을 사용하며 종속성은 pip 로 관리됩니다. 모든 개발은 컨테이너 내에서 이루어지기 때문에 Python 환경에 대한 변경 사항은 일시적입니다. Python 패키지를 영구적으로 설치하려면 requirements.txt 파일에 추가하거나 Workbench UI를 사용하세요.
개발 환경은 Ubuntu 22.04를 기반으로 합니다. 기본 사용자는 비밀번호 없이 sudo 액세스 권한을 가지지만 시스템에 대한 모든 변경 사항은 일시적입니다. 설치된 패키지를 영구적으로 변경하려면 해당 패키지를 [ apt.txt ] 파일에 추가하세요. 파일 조작, 환경 변수 추가 등과 같은 운영 체제에 대한 기타 변경 작업을 수행합니다. postBuild.bash 및 preBuild.bash 파일을 사용하십시오.
일반적으로 종속성을 잘못 사용하여 CVE가 노출되지 않도록 종속성을 매달 업데이트하는 것이 좋습니다. 이 프로젝트를 패치하려면 다음 프로세스를 사용할 수 있습니다. 패치 후에 회귀 테스트를 실행하여 업데이트에 문제가 없는지 확인하는 것이 좋습니다.
/project/code/tools/bump.sh 스크립트를 실행하여 자동으로 업데이트할 수 있습니다./project/code/tools/audit.sh 실행하세요. 이 스크립트는 경고 상태의 모든 Python 패키지와 오류 상태의 모든 패키지에 대한 보고서를 인쇄합니다. 오류 상태의 모든 항목에는 활성 CVE 및 알려진 취약점이 있으므로 해결해야 합니다.

