Facebook Messenger Bot
1.0.0
나처럼 말하도록 훈련시킨 FB 메신저 챗봇. 관련 블로그 게시물입니다.
이 프로젝트에서는 다양한 소셜 미디어 사이트의 과거 대화 로그를 기반으로 Sequence To Sequence 모델을 훈련하고 싶었습니다. 이 접근 방식의 동기, ML 모델의 세부 사항 및 각 Python 스크립트의 목적에 대한 자세한 내용은 블로그 게시물에서 읽을 수 있습니다. 하지만 저는 이 README를 사용하여 자신의 챗봇이 자신처럼 대화하도록 훈련하는 방법을 설명하고 싶습니다. .
이러한 스크립트를 실행하려면 다음 라이브러리가 필요합니다.
대화형으로 또는 터미널에 다음을 입력하여 GitHub에서 전체 저장소를 다운로드하고 압축을 풉니다.
git clone https://github.com/adeshpande3/Facebook-Messenger-Bot.git컴퓨터에서 저장소의 최상위 디렉터리로 이동합니다.
cd Facebook-Messenger-Bot우리의 첫 번째 임무는 다양한 소셜 미디어 사이트에서 모든 대화 데이터를 다운로드하는 것입니다. 저는 Facebook, Google Hangouts, LinkedIn을 사용했습니다. 데이터를 가져오는 다른 사이트가 있다면 괜찮습니다. createDataset.py에서 새 메서드를 생성하기만 하면 됩니다.
Facebook 데이터 : 여기에서 데이터를 다운로드하세요. 다운로드한 후에는 message.htm 이라는 상당히 큰 파일을 갖게 됩니다. 꽤 큰 파일이 될 것입니다(저에게는 190MB 이상). 우리는 이 대용량 파일을 분석하고 모든 대화를 추출해야 합니다. 이를 위해 Dillon Dixon이 친절하게 오픈 소스로 제공한 이 도구를 사용하겠습니다. 다음을 실행하여 해당 도구를 설치합니다.
pip install fbchat-archive-parser그런 다음 실행 중입니다.
fbcap ./messages.htm > fbMessages.txt이렇게 하면 모든 Facebook 대화가 상당히 통일된 텍스트 파일로 제공됩니다. 고마워요 딜런! 계속해서 해당 파일을 Facebook-Messenger-Bot 폴더에 저장하세요.
LinkedIn 데이터 : 여기에서 데이터를 다운로드하세요. 다운로드되면 inbox.csv 파일이 표시됩니다. 여기서는 다른 단계를 수행할 필요가 없으며 폴더에 복사하기만 하면 됩니다.
Google 행아웃 데이터 : 여기에서 데이터 양식을 다운로드하세요. 다운로드되면 구문 분석이 필요한 JSON 파일이 제공됩니다. 이를 위해 우리는 이 놀라운 블로그 게시물을 통해 찾은 이 파서를 사용할 것입니다. 데이터를 텍스트 파일에 저장한 다음 폴더를 우리 폴더에 복사하려고 합니다.
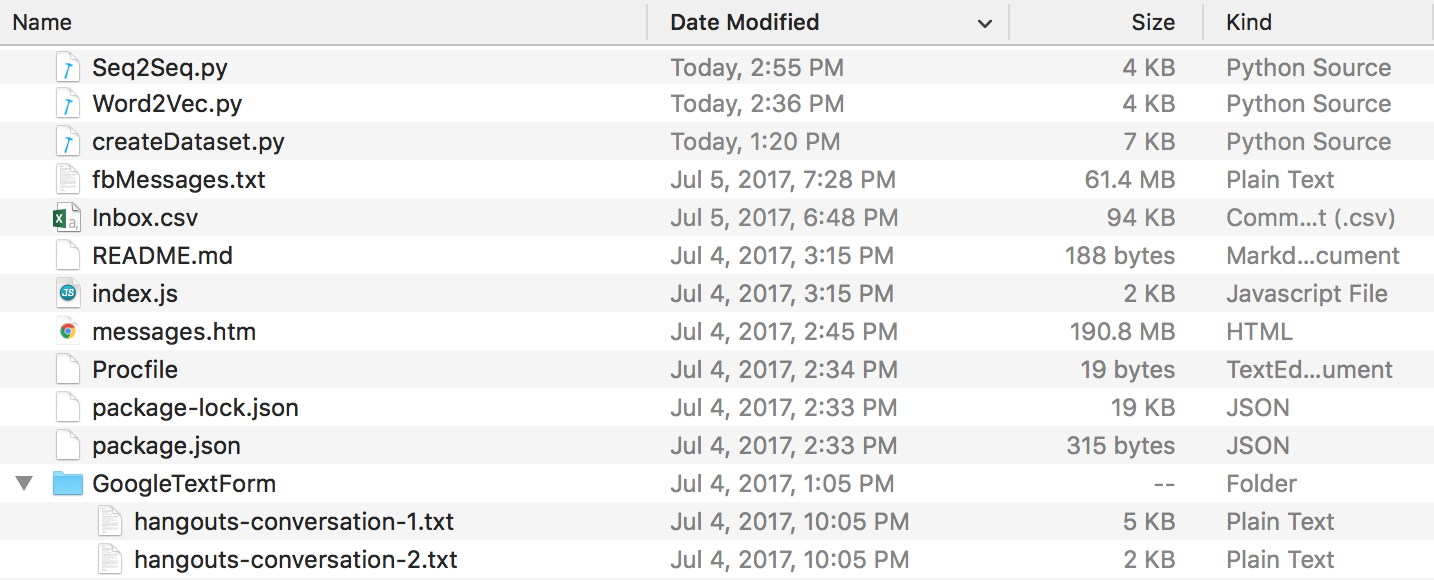
이 모든 작업이 끝나면 다음과 같은 디렉터리 구조를 갖게 됩니다. 폴더와 파일 이름이 다른 경우 이름을 바꾸십시오.
Discord 데이터 : Tyrrrz가 만든 멋진 DiscordChatExporter를 사용하여 불일치 채팅 로그를 추출할 수 있습니다. 설명서에 따라 원하는 단일 채팅 로그를 .txt 형식으로 추출하세요(중요). 그런 다음 repo 디렉터리의 DiscordChatLogs 라는 폴더에 모두 넣을 수 있습니다.
WhatsApp 데이터 : 휴대 전화가 있는지 확인하고 아직 미국 날짜 형식이 아닌 경우 미국 날짜 형식으로 입력하세요. 이는 나중에 로그 파일을 .csv로 구문 분석할 때 중요합니다. 이 목적으로 WhatsApp 웹을 사용할 수 없습니다. 보내려는 채팅을 열고 메뉴 버튼을 탭한 다음 더보기를 탭하고 '채팅 이메일 보내기'를 클릭하세요. 이메일을 자신에게 보내고 컴퓨터에 다운로드하세요. 이렇게 하면 .txt 파일이 제공되며 이를 구문 분석하기 위해 .csv로 변환합니다. 이렇게 하려면 이 링크로 이동하여 로그 파일에 있는 모든 텍스트를 입력하세요. 내보내기를 클릭하고 csv 파일을 다운로드한 후 "whatsapp_chats.csv"라는 이름으로 Facebook-Messenger-Bot 폴더에 저장하세요.
참고 : 위 링크에 제공된 파서가 제거된 것 같습니다. 올바른 형식의 .csv 파일이 아직 있는 경우 해당 파일을 계속 사용할 수 있습니다. 그렇지 않으면 whatsapp 채팅 로그를 .txt 파일로 다운로드하고 repo 디렉터리의 WhatsAppChatLogs 라는 폴더에 모두 저장하세요. createDataset.py whatsapp_chats.csv 라는 .csv 파일을 찾지 못하는 경우에만 이러한 파일을 사용하여 작동합니다.
.txt 채팅 로그를 사용하는 경우 예상되는 형식은 다음과 같습니다.
[20.06.19, 15:58:57] Loris: Welcome to the chat example
[20.06.19, 15:59:07] John: Thanks
(또는)
12/28/19, 21:43 - Loris: Welcome to the chat example
12/28/19, 21:43 - John: Thanks
이제 모든 대화 로그가 깔끔한 형식으로 확보되었으므로 계속해서 데이터세트를 만들 수 있습니다. 우리 디렉토리에서 다음을 실행해 봅시다:
python createDataset.py그런 다음 스크립트가 누구를 찾을지 알 수 있도록 이름을 입력하고 데이터가 있는 소셜 미디어 사이트를 입력하라는 메시지가 표시됩니다. 이 스크립트는 (FRIENDS_MESSAGE, YOUR RESPONSE) 형식의 쌍을 포함하는 Numpy 개체인 대화사전.npy 라는 파일을 생성합니다. ConversationData.txt 라는 파일도 생성됩니다. 이것은 단순히 사전 데이터가 통합된 형태의 큰 텍스트 파일입니다.
이제 2개의 파일이 있으므로 Word2Vec 모델을 통해 단어 벡터 생성을 시작할 수 있습니다. 이 단계는 다른 단계와 조금 다릅니다. 나중에 볼 수 있는 Tensorflow 함수(seq2seq.py)는 실제로 임베딩 부분도 처리합니다. 따라서 자신만의 벡터를 훈련시키거나 seq2seq 함수를 사용하여 공동으로 수행하도록 결정할 수 있습니다. 이것이 바로 제가 한 일입니다. Word2Vec을 통해 자신만의 단어 벡터를 생성하려면 프롬프트에서 y를 입력하세요(다음을 실행한 후). 그렇지 않은 경우에는 괜찮습니다. n으로 응답하면 이 함수는 wordList.txt만 생성합니다.
python Word2Vec.pyword2vec.py를 전체적으로 실행하면 4개의 다른 파일이 생성됩니다. Word2VecXTrain.npy 및 Word2VecYTrain.npy 는 Word2Vec이 사용할 훈련 행렬입니다. 다른 하이퍼파라미터를 사용하여 Word2Vec 모델을 다시 훈련해야 하는 경우를 대비하여 이를 폴더에 저장합니다. 또한 말뭉치의 모든 고유 단어가 포함된 wordList.txt 도 저장합니다. 저장된 마지막 파일은 생성된 모든 단어 벡터를 포함하는 Numpy 행렬인 embeddingMatrix.npy 입니다.
이제 Seq2Seq 모델을 생성하고 훈련할 수 있습니다.
python Seq2Seq.py이렇게 하면 3개 이상의 서로 다른 파일이 생성됩니다. Seq2SeqXTrain.npy 및 Seq2SeqYTrain.npy 는 Seq2Seq가 사용할 훈련 행렬입니다. 다시 말하지만, 모델 아키텍처를 변경하고 훈련 세트를 다시 계산하고 싶지 않은 경우를 대비하여 이를 저장합니다. 마지막 파일은 저장된 Seq2Seq 모델을 보유하는 .ckpt 파일입니다. 모델은 훈련 루프의 다양한 기간에 저장됩니다. 이는 챗봇을 만든 후에 사용 및 배포됩니다.
이제 저장된 모델이 있으므로 Facebook 챗봇을 만들어 보겠습니다. 그렇게 하려면 이 튜토리얼을 따르는 것이 좋습니다. "봇이 말하는 내용 사용자 정의" 섹션 아래에는 아무것도 읽을 필요가 없습니다. Seq2Seq 모델이 해당 부분을 처리합니다. 중요 - 튜토리얼에서는 노드 프로젝트가 놓일 새 폴더를 생성하라고 지시합니다. 이 폴더는 우리 폴더와 다르다는 점을 명심하세요. 이 폴더는 데이터 전처리 및 모델 교육이 있는 곳으로 생각할 수 있고, 다른 폴더는 Express 앱용으로 엄격하게 예약되어 있습니다(편집: 폴더 내부에서 튜토리얼의 단계를 따라 Node 프로젝트를 만들 수 있다고 생각합니다. 원하는 경우 Procfile 및 index.js 파일이 여기에 있습니다). 튜토리얼 자체만으로도 충분하지만 다음은 단계 요약입니다.
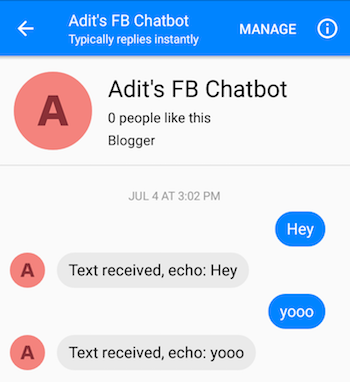
단계를 올바르게 수행한 후에는 챗봇에 메시지를 보내고 응답을 받을 수 있습니다.
아, 거의 다 끝났어요! 이제 저장된 Seq2Seq 모델을 배포할 수 있는 Flask 서버를 만들어야 합니다. 여기에 해당 서버의 코드가 있습니다. 일반적인 구조에 대해 이야기 해 봅시다. Flask 서버에는 일반적으로 모든 엔드포인트를 정의하는 하나의 기본 .py 파일이 있습니다. 우리의 경우에는 app.py가 됩니다. 이것이 모델을 로드하는 곳입니다. 'models'라는 폴더를 생성하고 4개의 파일(체크포인트 파일, 데이터 파일, 인덱스 파일, 메타 파일)로 채워야 합니다. Tensorflow 모델을 저장할 때 생성되는 파일입니다.

이 app.py 파일에서 경로에 대한 입력이 저장된 모델에 공급되고 디코더 출력이 반환되는 문자열인 경로(내 경우에는 /prediction)를 생성하려고 합니다. 여전히 다소 혼란스럽다면 app.py를 자세히 살펴보세요. 이제 app.py와 모델(필요한 경우 기타 도우미 파일)이 있으므로 서버를 배포할 수 있습니다. 우리는 다시 Heroku를 사용할 것입니다. Flask 서버를 Heroku에 배포하는 방법에 대한 다양한 튜토리얼이 있지만 특히 이 튜토리얼이 마음에 듭니다(Foreman 및 Logging 섹션은 필요하지 않습니다).
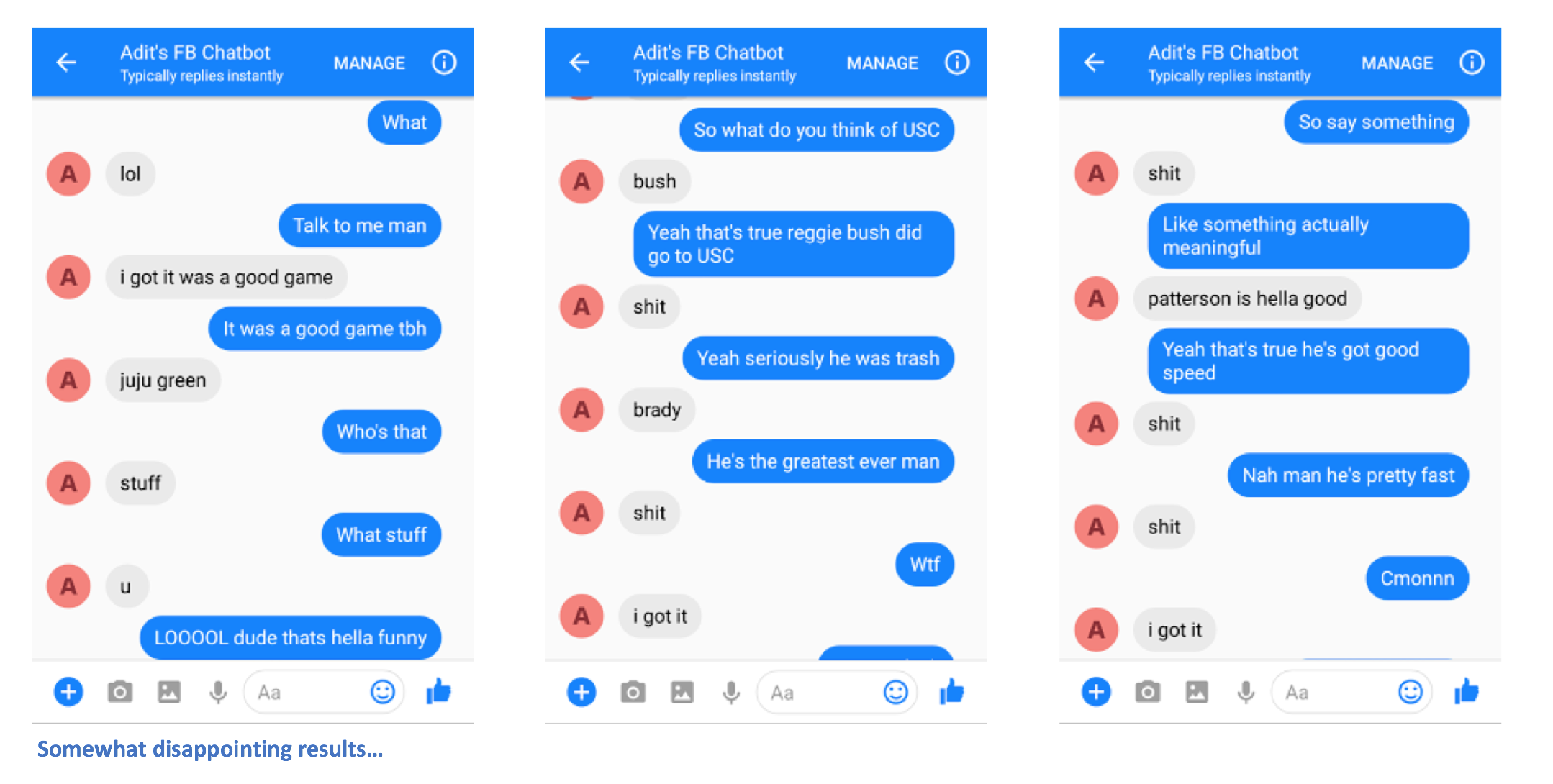
됐어요. 당신은 챗봇에 메시지를 보낼 수 있어야 하고, 어떤 면에서 당신과 유사한 흥미로운 응답을 볼 수 있어야 합니다.
문제가 있거나 이 README를 개선하기 위한 제안 사항이 있으면 알려 주시기 바랍니다. 특정 단계가 불분명하다고 생각되는 경우 알려주시면 최선을 다해 README를 편집하고 명확하게 설명하겠습니다.


