snips nlu
0.20.2
Snips NLU(Natural Language Understanding)는 자연어로 작성된 문장에서 구조화된 정보를 추출할 수 있는 Python 라이브러리입니다.
모든 챗봇과 음성 비서 뒤에는 공통된 기술인 NLU(자연어 이해)가 있습니다. 사용자가 자연어를 사용하여 AI와 상호 작용할 때마다 사용자의 단어는 의미에 대한 기계 판독 가능한 설명으로 번역되어야 합니다.
NLU 엔진은 먼저 사용자의 의도(일명 의도)가 무엇인지 감지한 다음 쿼리의 매개변수(슬롯이라고 함)를 추출합니다. 그런 다음 개발자는 이를 사용하여 적절한 작업이나 응답을 결정할 수 있습니다.
이를 설명하기 위해 예를 들어 다음 문장을 고려해 보겠습니다.
"오후 9시 파리 날씨는 어때?"
적절하게 훈련된 Snips NLU 엔진은 다음과 같은 구조화된 데이터를 추출할 수 있습니다.
{
"intent" : {
"intentName" : " searchWeatherForecast " ,
"probability" : 0.95
},
"slots" : [
{
"value" : " paris " ,
"entity" : " locality " ,
"slotName" : " forecast_locality "
},
{
"value" : {
"kind" : " InstantTime " ,
"value" : " 2018-02-08 20:00:00 +00:00 "
},
"entity" : " snips/datetime " ,
"slotName" : " forecast_start_datetime "
}
]
} 이 경우 식별된 의도는 searchWeatherForecast 이며 두 개의 슬롯(지역 및 날짜/시간)이 추출되었습니다. 보시다시피 Snips NLU는 엔터티 추출 외에 추가 단계를 수행합니다. 엔터티를 해결합니다. 추출된 날짜/시간 값은 실제로 편리한 ISO 형식으로 변환되었습니다.
Snips NLU를 구축한 이유와 내부 작동 방식에 대한 자세한 내용을 보려면 블로그 게시물을 확인하세요. 우리는 또한 Snips Voice Platform의 기계 학습 아키텍처를 제시하는 arxiv에 논문을 게시했습니다.
pip install snips - nlu 현재 우리는 snips-nlu 와 MacOS(10.11 이상), Linux x86_64 및 Windows에 대한 종속성을 위해 사전 구축된 바이너리(휠)를 보유하고 있습니다.
다른 아키텍처/OS의 경우 snips-nlu를 소스 배포판에서 설치할 수 있습니다. 이렇게 하려면 pip install snips-nlu 명령을 실행하기 전에 Rust 및 setuptools_rust를 설치해야 합니다.
Snips NLU는 라이브러리를 사용하기 전에 다운로드해야 하는 외부 언어 리소스에 의존합니다. 다음 명령을 실행하여 특정 언어에 대한 리소스를 가져올 수 있습니다.
python -m snips_nlu download en또는 간단하게:
snips-nlu download en지원되는 언어 목록은 이 주소에서 확인할 수 있습니다.
이 라이브러리의 기능을 테스트하는 가장 쉬운 방법은 명령줄 인터페이스를 이용하는 것입니다.
먼저 샘플 데이터 세트 중 하나를 사용하여 NLU를 교육하는 것부터 시작합니다.
snips-nlu train path/to/dataset.json path/to/output_trained_engine 여기서 path/to/dataset.json 은 훈련 중에 사용될 데이터 세트의 경로이고, path/to/output_trained_engine 은 훈련이 완료된 후 훈련된 엔진이 유지되어야 하는 위치입니다.
그런 다음 다음을 실행하여 대화형으로 문장 구문 분석을 시작할 수 있습니다.
snips-nlu parse path/to/trained_engine path/to/trained_engine 은 이전 단계에서 학습된 엔진을 저장한 위치에 해당합니다.
다음은 snips-nlu를 설치하고 영어 리소스를 가져온 후 샘플 데이터세트 중 하나를 다운로드한 후 컴퓨터에서 실행할 수 있는 샘플 코드입니다.
>> > from __future__ import unicode_literals , print_function
>> > import io
>> > import json
>> > from snips_nlu import SnipsNLUEngine
>> > from snips_nlu . default_configs import CONFIG_EN
>> > with io . open ( "sample_datasets/lights_dataset.json" ) as f :
... sample_dataset = json . load ( f )
>> > nlu_engine = SnipsNLUEngine ( config = CONFIG_EN )
>> > nlu_engine = nlu_engine . fit ( sample_dataset )
>> > text = "Please turn the light on in the kitchen"
>> > parsing = nlu_engine . parse ( text )
>> > parsing [ "intent" ][ "intentName" ]
'turnLightOn'그것이 하는 일은 샘플 날씨 데이터 세트에서 NLU 엔진을 훈련하고 날씨 쿼리를 구문 분석하는 것입니다.
다음은 Snips NLU 엔진을 훈련하는 데 사용할 수 있는 일부 데이터 세트 목록입니다.
2018년 1월, 우리는 2017년 여름에 발표된 학술 벤치마크를 재현했습니다. 이 기사에서 저자는 API.ai(현재 Dialogflow, Google), Luis.ai(Microsoft), IBM Watson 및 Rasa NLU의 성능을 평가했습니다. 공정성을 위해 Rasa NLU의 업데이트된 버전을 사용하고 이를 Snips NLU의 최신 버전(둘 다 진한 파란색)과 비교했습니다.
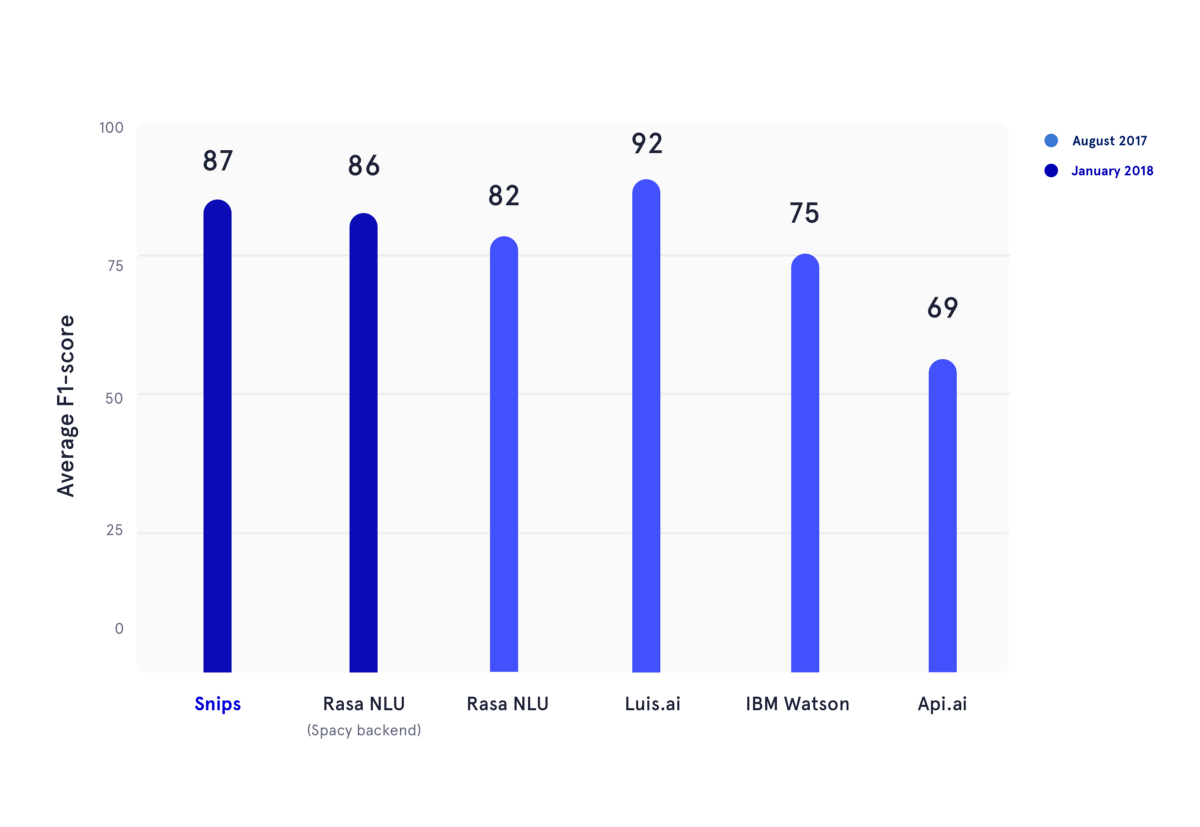
위 그림에서 의도 분류 및 슬롯 채우기의 F1 점수는 여러 NLU 제공업체에 대해 계산되었으며 이전에 언급한 학술 벤치마크에 사용된 세 가지 데이터 세트에서 평균을 냈습니다. 모든 기본 결과는 여기에서 찾을 수 있습니다.
Snips NLU 사용 방법을 알아보려면 패키지 설명서를 참조하세요. 이 설명서에서는 이 라이브러리를 설정하고 사용하는 방법에 대한 단계별 가이드를 제공합니다.
Snips NLU를 사용할 때 다음 논문을 인용하세요.
@article { coucke2018snips ,
title = { Snips Voice Platform: an embedded Spoken Language Understanding system for private-by-design voice interfaces } ,
author = { Coucke, Alice and Saade, Alaa and Ball, Adrien and Bluche, Th{'e}odore and Caulier, Alexandre and Leroy, David and Doumouro, Cl{'e}ment and Gisselbrecht, Thibault and Caltagirone, Francesco and Lavril, Thibaut and others } ,
journal = { arXiv preprint arXiv:1805.10190 } ,
pages = { 12--16 } ,
year = { 2018 }
}포럼에 참여하여 질문을 하고 커뮤니티로부터 피드백을 받으세요.
기여 가이드라인을 참조하세요.
이 라이브러리는 Snips에서 오픈 소스 소프트웨어로 제공합니다. 자세한 내용은 라이센스를 참조하세요.
snips/city, snips/country 및 snips/region 내장 엔터티는 Creative Commons Attribution 4.0 국제 라이선스에 따라 제공되는 Geonames의 소프트웨어를 사용합니다. Geonames에 대한 라이센스 및 보증은 https://creativecommons.org/licenses/by/4.0/legalcode를 참조하십시오.


