RLAIF V
1.0.0

Super GPT-4V 신뢰성을 위해 오픈 소스 AI 피드백을 통해 MLLM 정렬
중국어 | 영어
[2024.11.26] 이제 LoRA 훈련을 지원합니다!
[2024.05.28] 이제 arXiv에서 저희 논문을 보실 수 있습니다!
[2024.05.20] RLAIF-V-Dataset은 MiniCPM-Llama3-V 2.5 학습에 사용되며, 이는 첫 번째 엔드 측 GPT-4V 레벨 MLLM을 나타냅니다!
[2024.05.20] RLAIF-V의 코드와 가중치(7B, 12B), 데이터를 오픈소스로 공개합니다!
슈퍼 GPT-4V 신뢰성을 위해 완전 오픈 소스 패러다임에서 MLLM을 정렬하는 새로운 프레임워크인 RLAIF-V를 소개합니다. RLAIF-V는 고품질 피드백 데이터와 온라인 피드백 학습 알고리즘이라는 두 가지 핵심 관점에서 오픈 소스 피드백을 최대한 활용합니다. RLAIF-V의 주목할만한 기능은 다음과 같습니다.
오픈 소스 피드백을 통한 슈퍼 GPT-4V 신뢰성 . RLAIF-V 12B는 오픈 소스 AI 피드백을 통해 학습함으로써 생성 작업과 판별 작업 모두에서 뛰어난 GPT-4V 신뢰성을 달성합니다.
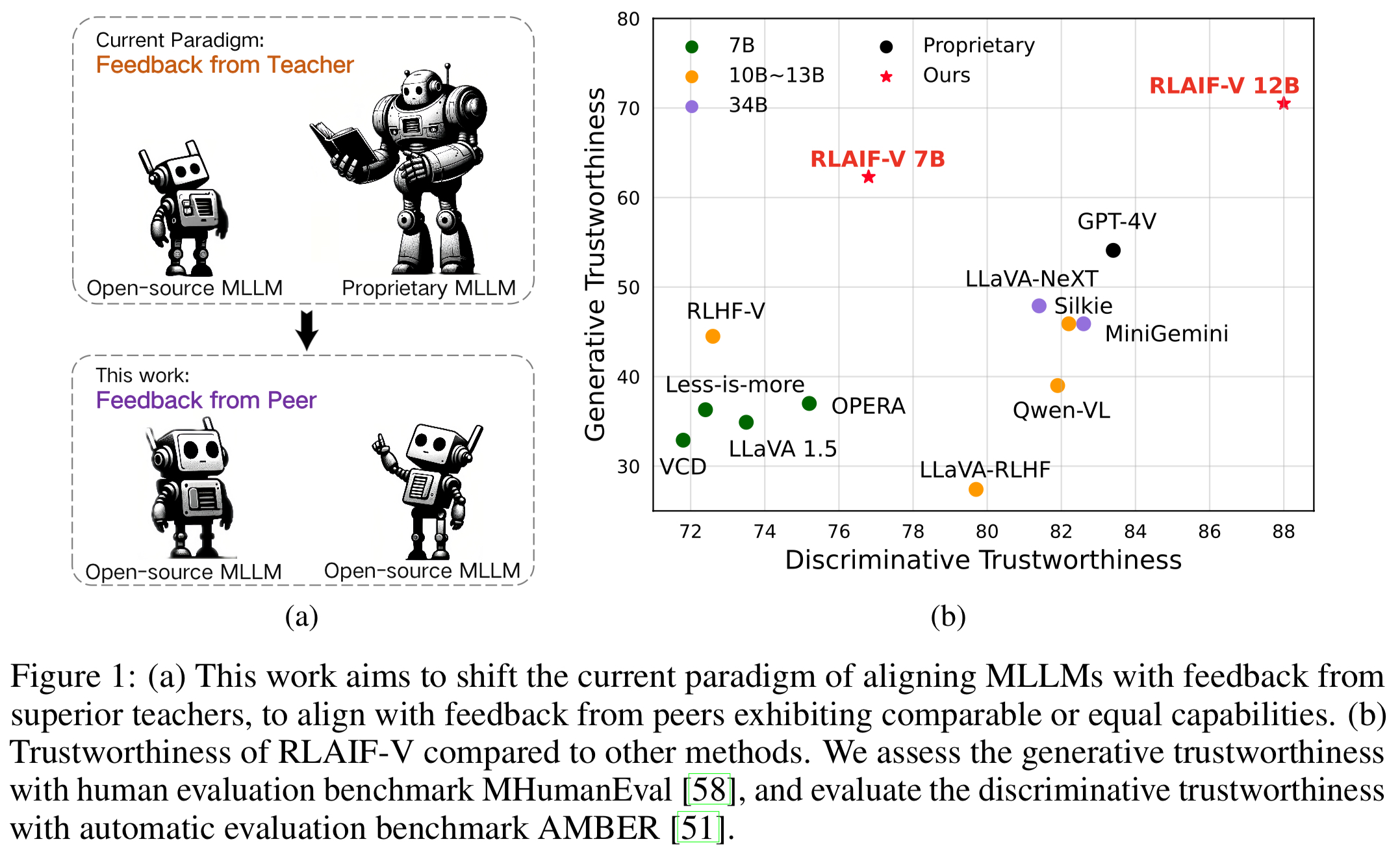
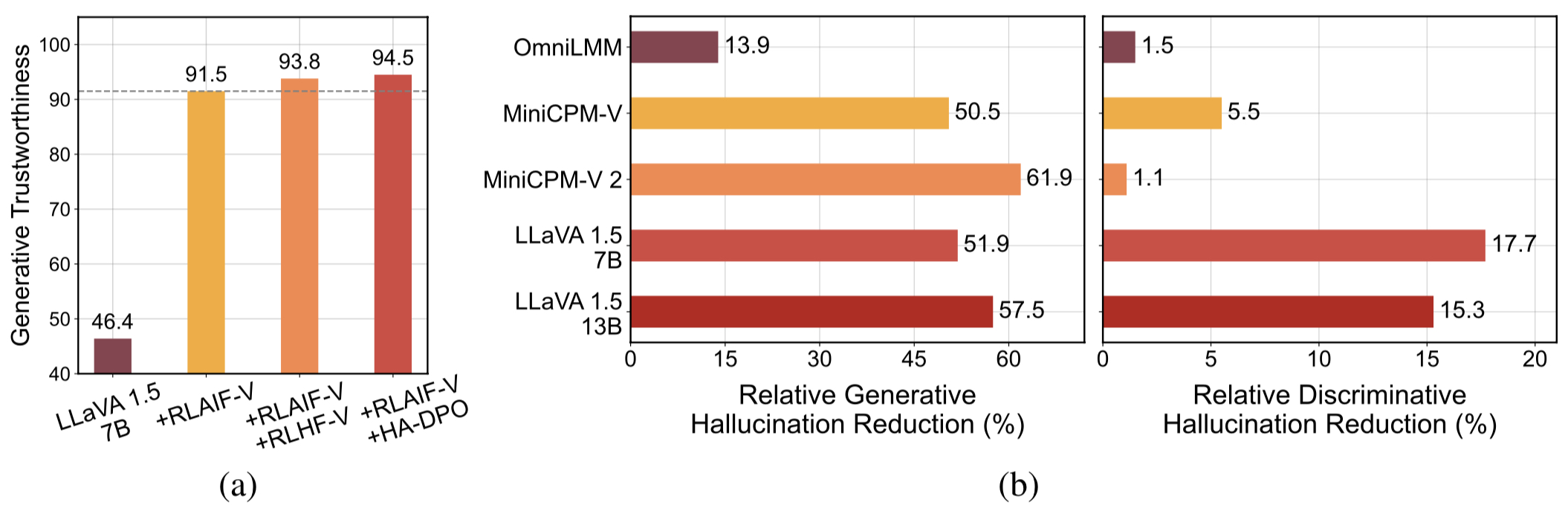
고품질의 일반화 가능한 피드백 데이터 . RLAIF-V에서 사용하는 피드백 데이터는 다양한 MLLM의 환각을 효과적으로 줄입니다 .
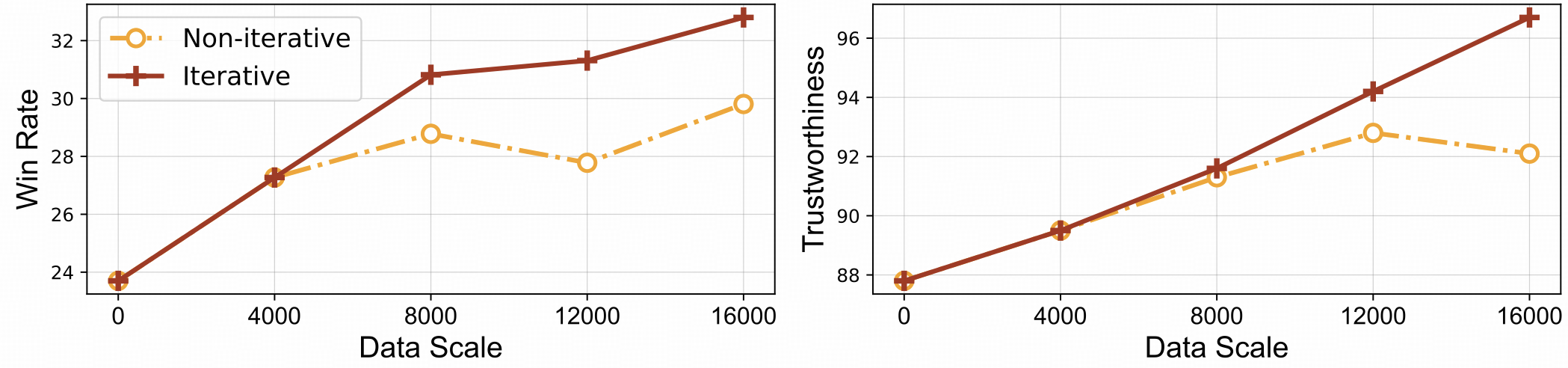
⚡️ 반복 정렬을 통한 효율적인 피드백 학습. RLAIF-V는 비반복 접근 방식에 비해 더 나은 학습 효율성과 더 높은 성능을 모두 발휘합니다.
데이터세트
설치하다
모델 가중치
추론
데이터 생성
기차
평가
개체 HalBench
MMHal 벤치
RefoMB
소환
우리는 다양한 작업과 영역을 포괄하는 AI 생성 선호도 데이터 세트인 RLAIF-V 데이터 세트를 제시합니다. 이 오픈 소스 다중 모드 기본 설정 데이터 세트에는 83,132개의 고품질 비교 쌍이 포함되어 있습니다. 데이터 세트에는 LLaVA 1.5 7B, OmniLMM 12B 및 MiniCPM-V를 포함한 다양한 모델의 각 교육 반복에서 생성된 기본 설정 쌍이 포함되어 있습니다.
이 저장소를 복제하고 RLAIF-V 폴더로 이동합니다.
자식 클론 https://github.com/RLHF-V/RLAIF-V.gitcd RLAIF-V
패키지 설치
conda create -n rlaifv python=3.10 -y conda 활성화 rlaifv pip 설치 -e .
필요한 spaCy 모델 설치
wget https://github.com/explosion/spacy-models/releases/download/en_core_web_trf-3.7.3/en_core_web_trf-3.7.3.tar.gz pip 설치 en_core_web_trf-3.7.3.tar.gz
| 모델 | 설명 | 다운로드 |
|---|---|---|
| RLAIF-V 7B | LLaVA 1.5에서 가장 신뢰할 수 있는 변형 | ? |
| RLAIF-V 12B | OmniLMM-12B를 기반으로 슈퍼 GPT-4V 신뢰성을 달성합니다. | ? |
RLAIF-V 사용 방법을 보여주는 간단한 예를 제공합니다.
from chat import RLAIFVChat, img2base64chat_model = RLAIFVChat('openBMB/RLAIF-V-7B') # 또는 'openBMB/RLAIF-V-12B'image_path="./examples/test.jpeg"msgs = "에 있는 사람들을 자세히 설명하세요. 그림."입력 = {"이미지": image_path, "질문": msgs}답변 = chat_model.chat(입력)인쇄(답변)다음 스크립트를 실행하여 이 예제를 실행할 수도 있습니다.
파이썬 chat.py

질문:
사진 속 자동차는 왜 멈췄나요?
예상 출력:
사진 속 도로에는 양 한 마리가 나타나 도로 위에 자동차 한 대가 멈춰 섰다. 아마도 양들이 길에서 안전하게 벗어날 수 있도록 하거나 동물과의 잠재적인 사고를 피하기 위해 차가 멈췄을 것입니다. 이러한 상황은 특히 도로 근처에서 동물이 돌아다닐 수 있는 지역에서 운전하는 동안 조심하고 주의를 기울이는 것의 중요성을 강조합니다.
환경설정
피드백 생성을 위해 OmniLMM 12B 모델과 MiniCPM-Llama3-V 2.5 모델을 제공합니다. 피드백 제공을 위해 MiniCPM-Llama3-V 2.5를 사용하려면 MiniCPM-V GitHub 저장소의 지침에 따라 추론 환경을 구성하세요.
미세 조정된 Llama3 8B 모델(분할 모델 및 질문 변환 모델)을 다운로드하여 각각 ./models/llama3_split 폴더 및 ./models/llama3_changeq 폴더에 저장하세요.
OmniLMM 12B 모델 피드백
다음 스크립트는 LLaVA-v1.5-7b 모델을 사용하여 후보 답변을 생성하고 OmniLMM 12B 모델을 사용하여 피드백을 제공하는 방법을 보여줍니다.
mkdir ./결과 bash ./script/data_gen/run_data_pipeline_llava15_omni.sh
MiniCPM-Llama3-V 2.5 모델 피드백
다음 스크립트는 LLaVA-v1.5-7b 모델을 사용하여 후보 답변을 생성하고 MiniCPM-Llama3-V 2.5 모델을 사용하여 피드백을 제공하는 방법을 보여줍니다. 먼저 ./script/data_gen/run_data_pipeline_llava15_minicpmv.sh 의 minicpmv_python 생성한 MiniCPM-V 환경의 Python 경로로 바꿉니다.
mkdir ./결과 bash ./script/data_gen/run_data_pipeline_llava15_minicpmv.sh
데이터 준비(선택사항)
허깅페이스 데이터세트에 액세스할 수 있는 경우 이 단계를 건너뛰면 RLAIF-V 데이터세트가 자동으로 다운로드됩니다.
데이터세트를 이미 다운로드한 경우 여기 38번째 줄에서 'openbmb/RLAIF-V-Dataset'를 데이터세트 경로로 바꿀 수 있습니다.
훈련
여기서는 1회 반복 으로 모델을 훈련하는 훈련 스크립트를 제공합니다. max_step 매개변수는 데이터 양에 따라 조정되어야 합니다.
완전 미세 조정
완전히 미세 조정을 시작하려면 다음 명령을 실행하세요.
배쉬 ./script/train/llava15_train.sh
로라
다음 명령을 실행하여 lora 훈련을 시작합니다.
pip 설치 peft 배쉬 ./script/train/llava15_train_lora.sh
반복 정렬
논문에서 반복 훈련 과정을 재현하려면 다음 단계를 4번 수행해야 합니다.
S1. 데이터 생성.
기본 모델에 대한 기본 설정 쌍을 생성하려면 데이터 생성 지침을 따르세요. 생성된 jsonl 파일을 Huggingface Parquet로 변환합니다.
S2. 훈련 구성을 변경합니다.
데이터 세트 코드에서 여기의 'openbmb/RLAIF-V-Dataset' 데이터 경로로 바꿉니다.
학습 스크립트에서 --data_dir 새 디렉터리로 바꾸고, --model_name_or_path 기본 모델 경로로 바꾸고, --max_step 4 에포크의 단계 수로 설정하고, --save_steps 1/4 에포크의 단계 수로 설정합니다. .
S3. DPO 교육을 수행합니다.
학습 스크립트를 실행하여 기본 모델을 학습합니다.
S4. 다음 반복을 위해 기본 모델을 선택합니다.
Object HalBench 및 MMHal Bench의 각 체크포인트를 평가하고, 다음 반복의 기본 모델로 가장 성능이 좋은 체크포인트를 선택합니다.
COCO2014 주석 준비
Object HalBench의 평가는 COCO2014 데이터 세트의 캡션 및 분할 주석에 의존합니다. 먼저 COCO 데이터세트 공식 웹사이트에서 COCO2014 데이터세트를 다운로드하세요.
mkdir coco2014cd coco2014 wget http://images.cocodataset.org/annotations/annotations_trainval2014.zip Annotations_trainval2014.zip 압축 풀기
추론, 평가 및 요약
{YOUR_OPENAI_API_KEY} 유효한 OpenAI API 키로 바꾸세요.
참고: 평가는 gpt-3.5-turbo-0613 기반으로 합니다.
# cd RLAIF-Vbash ./script/eval/eval_rlaifv_objhal.sh ./RLAIF-V_weight ./results/RLAIF-V ./coco2014/annotations {YOUR_OPENAI_API_KEY}MMHal 데이터 준비
여기에서 MMHal 평가 데이터를 다운로드하고 eval/data 에 파일을 저장하세요.
MMHal Bench를 생성하려면 다음 스크립트를 실행하십시오.
참고: 평가는 gpt-4-1106-preview 기반으로 합니다.
# cd RLAIF-Vbash ./script/eval/eval_rlaifv_mmhal.sh ./RLAIF-V_weight ./results/RLAIF-V {YOUR_OPENAI_API_KEY}준비
GPT-4 평가판을 사용하려면 먼저 pip install openai==0.28 실행하여 openai 패키지를 설치하세요. 다음으로 eval/gpt4.py 의 openai.base 및 openai.api_key 를 원하는 대로 변경하세요.
개발 세트에 대한 평가 데이터는 eval/data/RefoMB_dev.jsonl 에서 찾을 수 있습니다. 각 줄의 image_url 키에서 각 이미지를 다운로드해야 합니다.
종합점수 평가
입력 데이터 파일 eval/data/RefoMB_dev.jsonl 의 answer 키에 모델 답변을 저장합니다. 예를 들면 다음과 같습니다.
{
"image_url": "https://thunlp.oss-cn-qingdao.aliyuncs.com/multimodal_openmme_test_20240319__20.jpg",
"question": "What is the background of the image?",
"type": "Coarse Perception",
"split": "dev",
"answer": "The background of the image features trees, suggesting that the scene takes place outdoors.",
"gt_description": "......"
}모델 결과를 평가하려면 다음 스크립트를 실행하세요.
save_dir="YOUR SAVING DIR" model_ans_path="YOUR MODEL ANSWER PATH" model_name="YOUR MODEL NAME" bash ./script/eval/run_refobm_overall.sh $save_dir $model_ans_path $model_name
환각 점수 평가
종합 점수를 평가한 후 A-GPT-4V_B-${model_name}.json 이름으로 평가 결과 파일이 생성됩니다. 본 평가 결과 파일을 이용하여 환각 점수를 계산하면 다음과 같다.
eval_result="EVAL RESULT FILE PATH, e.g. 'A-GPT-4V_B-${model_name}'"
# Do not include ".json" in your file path!
bash ./script/eval/run_refomb_hall.sh $eval_result참고: 안정성을 높이려면 3회 이상 평가하고 평균 점수를 최종 모델 점수로 사용하는 것이 좋습니다.
사용 및 라이선스 고지 사항 : 데이터, 코드 및 체크포인트는 연구 용도로만 사용이 허가되었습니다. 또한 LLaMA, Vicuna 및 Chat GPT의 라이선스 계약을 따르는 사용으로 제한됩니다. 데이터 세트는 CC BY NC 4.0(비상업적 사용만 허용)이며 데이터 세트를 사용하여 훈련된 모델은 연구 목적 외에는 사용해서는 안 됩니다.
RLHF-V: 우리가 구축한 코드베이스입니다.
LLaVA: RLAIF-V-7B의 명령 모델 및 라벨러 모델입니다.
MiniCPM-V: RLAIF-V-12B의 명령 모델 및 라벨러 모델입니다.
우리의 모델/코드/데이터/논문이 도움이 된다면, 우리의 논문을 인용하고 별표 표시해 주세요 ️!
@article{yu2023rlhf, title={Rlhf-v: 세밀한 교정 인간 피드백의 행동 정렬을 통해 신뢰할 수 있는 mllm을 향해}, 작성자={Yu, Tianyu 및 Yao, Yuan 및 Zhang, Haoye 및 He, Taiwen 및 Han, Yifeng 및 Cui, Ganqu 및 Hu, Jinyi 및 Liu, Zhiyuan 및 Zheng, Hai-Tao 및 Sun, Maosong 및 기타}, 저널={arXiv preprint arXiv:2312.00849}, year={2023}}@article{yu2024rlaifv, title={RLAIF-V: Super GPT-4V 신뢰성을 위해 오픈 소스 AI 피드백을 통해 MLLM 조정}, 작성자={ Yu, Tianyu와 Zhang, Haoye와 Yao, Yuan과 Dang, Yunkai와 Chen, Da와 Lu, Xiaoman 및 Cui, Ganqu 및 He, Taiwen 및 Liu, Zhiyuan 및 Chua, Tat-Seng 및 Sun, Maosong}, 저널={arXiv 사전 인쇄 arXiv:2405.17220}, 연도={2024},
} 

