ChatLM mini Chinese
1.0.0
중국어 |
오늘날의 대규모 언어 모델은 큰 매개변수를 갖는 경향이 있으며, 소비자급 컴퓨터는 모델을 처음부터 학습하는 것은 물론이고 간단한 추론을 수행하는 속도도 느립니다. 이 프로젝트의 목표는 데이터 정리, 토크나이저 훈련, 모델 사전 훈련, SFT 명령 미세 조정, RLHF 최적화 등을 포함하여 생성 언어 모델을 처음부터 훈련하는 것입니다.
ChatLM-mini-English는 0.2B 모델 매개변수(공유 가중치를 포함하여 약 210M)만 있는 소규모 중국어 대화 모델입니다. 최소 4GB의 비디오 메모리( batch_size=1 , fp16 또는 bf16 가 있는 시스템에서 사전 훈련될 수 있습니다. ), float16 로딩 및 추론에는 최소 512MB의 비디오 메모리가 필요합니다.
transformers , accelerate , trl , peft 등을 포함한 Huggingface NLP 프레임워크를 사용합니다.trainer 단일 카드를 사용하거나 단일 시스템에서 여러 카드를 사용하여 단일 시스템에서 사전 교육 및 SFT 미세 조정을 지원합니다. 훈련 중 어느 위치에서든 멈추고 어떤 위치에서든 계속 훈련을 지원합니다.Text-to-Text 사전 훈련 및 비 mask 예측 사전 훈련에 통합되었습니다.sentencepiece 및 huggingface tokenizers 의 토크나이저 훈련을 지원합니다.batch_size=1, max_len=320 구성하면 최소 16GB 메모리 + 4GB 비디오 메모리가 있는 머신에서 사전 학습이 지원됩니다.trainer 신속한 명령 미세 조정을 지원하고 훈련을 계속하기 위한 모든 중단점을 지원합니다.Huggingface trainer 의 sequence to sequence 미세 조정을 지원합니다.peft lora 사용을 지원합니다.Lora adapter 원본 모델에 병합할 수 있습니다.작은 모델을 기반으로 검색 강화 생성(RAG)을 수행해야 하는 경우 내 다른 프로젝트 Phi2-mini-China를 참조할 수 있습니다. 코드는 rag_with_langchain.ipynb를 참조하세요.
? 최신 업데이트
모든 데이터 세트는 인터넷에 게시된 단일 라운드 대화 데이터 세트에서 가져온 것이며 데이터 정리 및 형식화 후 쪽모이 세공 파일로 저장됩니다. 데이터 처리 프로세스는 utils/raw_data_process.py 참조하세요. 주요 데이터 세트에는 다음이 포함됩니다.
Belle_open_source_1M , train_2M_CN 및 train_3.5M_CN 에서 짧은 답변이 있고 복잡한 테이블 구조를 포함하지 않으며 번역 작업(영어 어휘 목록 없음)이 있는 일부 데이터만 선택합니다. 총 370만 행, 정리 후에도 338만 행이 남아 있습니다.N 단어가 답변입니다. 202309 백과사전 데이터를 사용하면 정리 후에도 119만 개의 항목 프롬프트와 답변이 남습니다. Wiki 다운로드: zhwiki, 다운로드한 bz2 파일을 wiki.txt 참조로 변환: WikiExtractor. 총 데이터 세트 수는 1,023만 개입니다. Text-to-Text 사전 학습 세트: 930만 개, 평가 세트: 25,000개(디코딩이 느리기 때문에 평가 세트를 너무 크게 설정하지 않음). 테스트 세트: 900,000. SFT 미세 조정 및 DPO 최적화 데이터 세트는 아래와 같습니다.
T5 모델(텍스트-텍스트 변환 변환기)에 대한 자세한 내용은 통합 텍스트-텍스트 변환기를 사용하여 전이 학습의 한계 탐색 문서를 참조하세요.
모델 소스 코드는 Huggingface에서 제공됩니다. T5ForConditionalGeneration을 참조하세요.
모델 구성은 model_config.json을 참조하세요. 공식 T5-base : encoder layer 와 decoder layer 모두 12개 레이어입니다. 이 프로젝트에서는 이 두 매개변수가 10개 레이어로 수정됩니다.
모델 매개변수: 0.2B. 단어 목록 크기: 29298개(중국어와 소량의 영어만 포함)
하드웨어:
# 预训练阶段:
CPU: 28 vCPU Intel(R) Xeon(R) Gold 6330 CPU @ 2.00GHz
内存:60 GB
显卡:RTX A5000(24GB) * 2
# sft及dpo阶段:
CPU: Intel(R) i5-13600k @ 5.1GHz
内存:32 GB
显卡:NVIDIA GeForce RTX 4060 Ti 16GB * 1 토크나이저 훈련 : 기존 tokenizer 훈련 라이브러리는 큰 말뭉치를 만날 때 OOM 문제가 있으므로 BPE 와 유사한 방법으로 단어 빈도를 기반으로 전체 말뭉치를 병합하고 구성하며 실행하는 데 반나절이 걸립니다.
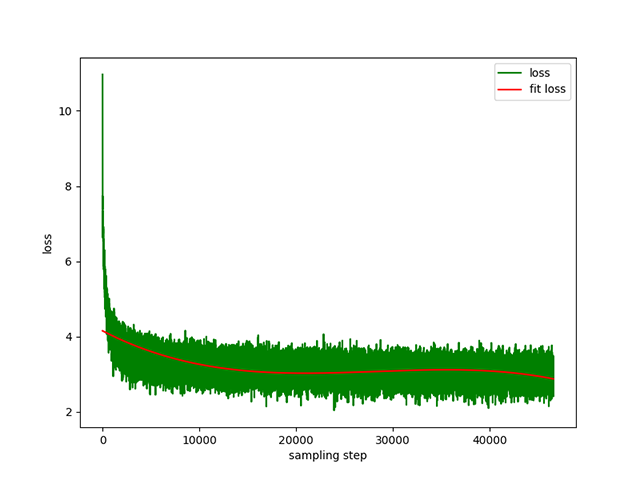
Text-to-Text 사전 학습 : 동적 학습률은 1e-4 ~ 5e-3 이고 사전 학습 시간은 8일입니다. 훈련 손실:
belle 교육 데이터 세트를 사용합니다(명령 및 답변 길이 모두 512 미만). 학습률은 1e-7 ~ 5e-5 의 동적 학습률이며 미세 조정 시간은 2일입니다. 미세 조정 손실: 
chosen 텍스트로 사용됩니다. 2 단계에서 SFT 모델 배치는 데이터 세트에서 프롬프트를 generate 하고 rejected 텍스트를 가져옵니다. dpo 전체 선호도를 최적화하고 학습하는 데 속도는 le-5 , 반 정밀도 fp16 , 총 2 epoch 이며 3시간이 걸립니다. DPO 손실: 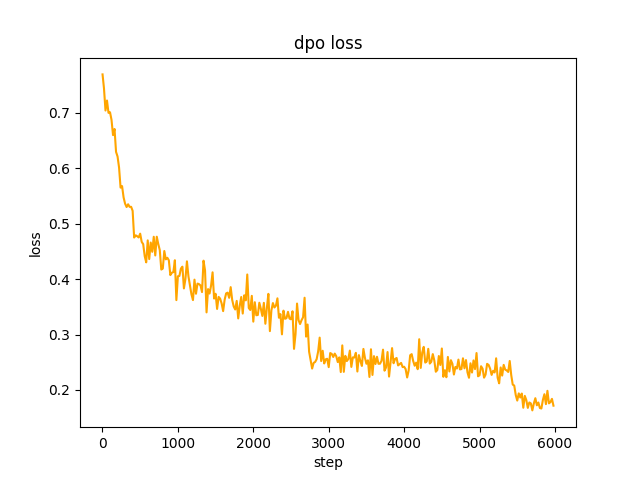
기본적으로 huggingface transformers 의 TextIteratorStreamer 는 greedy search 만 지원하는 스트리밍 대화를 구현하는 데 사용됩니다. beam sample 과 같은 다른 생성 방법이 필요한 경우 cli_demo.py 의 stream_chat 매개변수를 False 로 변경하세요. 

문제가 있습니다. 사전 훈련 데이터 세트는 900만 개가 넘고 모델 매개변수는 0.2B에 불과하며 모든 측면을 다룰 수 없으며 답이 틀리거나 생성기가 말도 안되는 상황이 있습니다.
Huggingface를 연결할 수 없는 경우 modelscope.snapshot_download 사용하여 modelscope에서 모델 파일을 다운로드하세요.
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
import torch
model_id = 'charent/ChatLM-mini-Chinese'
# 如果无法连接huggingface,打开以下两行代码的注释,将从modelscope下载模型文件,模型文件保存到'./model_save'目录
# from modelscope import snapshot_download
# model_id = snapshot_download(model_id, cache_dir='./model_save')
device = torch . device ( 'cuda' if torch . cuda . is_available () else 'cpu' )
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id , trust_remote_code = True ). to ( device )
txt = '如何评价Apple这家公司?'
encode_ids = tokenizer ([ txt ])
input_ids , attention_mask = torch . LongTensor ( encode_ids [ 'input_ids' ]), torch . LongTensor ( encode_ids [ 'attention_mask' ])
outs = model . my_generate (
input_ids = input_ids . to ( device ),
attention_mask = attention_mask . to ( device ),
max_seq_len = 256 ,
search_type = 'beam' ,
)
outs_txt = tokenizer . batch_decode ( outs . cpu (). numpy (), skip_special_tokens = True , clean_up_tokenization_spaces = True )
print ( outs_txt [ 0 ])Apple是一家专注于设计和用户体验的公司,其产品在设计上注重简约、流畅和功能性,而在用户体验方面则注重用户的反馈和使用体验。作为一家领先的科技公司,苹果公司一直致力于为用户提供最优质的产品和服务,不断推陈出新,不断创新和改进,以满足不断变化的市场需求。
在iPhone、iPad和Mac等产品上,苹果公司一直保持着创新的态度,不断推出新的功能和设计,为用户提供更好的使用体验。在iPad上推出的iPad Pro和iPod touch等产品,也一直保持着优秀的用户体验。
此外,苹果公司还致力于开发和销售软件和服务,例如iTunes、iCloud和App Store等,这些产品在市场上也获得了广泛的认可和好评。
总的来说,苹果公司在设计、用户体验和产品创新方面都做得非常出色,为用户带来了许多便利和惊喜。
주의
이 프로젝트의 모델은 TextToText 모델입니다. Pre-training, SFT, RLFH 단계의 prompt , response 및 기타 필드에는 [EOS] 시퀀스 끝 표시를 반드시 추가하세요.
git clone --depth 1 https://github.com/charent/ChatLM-mini-Chinese.git
cd ChatLM-mini-Chinese 이 프로젝트에서는 python 3.10 사용을 권장합니다. 이전 Python 버전은 의존하는 타사 라이브러리와 호환되지 않을 수 있습니다.
핍 설치:
pip install -r ./requirements.txtpip가 CPU 버전의 pytorch를 설치한 경우 다음 명령을 사용하여 CUDA 버전의 pytorch를 설치할 수 있습니다.
# pip 安装torch + cu118
pip3 install torch --index-url https://download.pytorch.org/whl/cu118콘다 설치:
conda install --yes --file ./requirements.txt git 명령을 사용하여 Hugging Face Hub 에서 모델 가중치 및 구성 파일을 다운로드하려면 먼저 Git LFS를 설치한 후 다음을 실행해야 합니다.
# 使用git命令下载huggingface模型,先安装[Git LFS],否则下载的模型文件不可用
git clone --depth 1 https://huggingface.co/charent/ChatLM-mini-Chinese
# 如果无法连接huggingface,请从modelscope下载
git clone --depth 1 https://www.modelscope.cn/charent/ChatLM-mini-Chinese.git
mv ChatLM-mini-Chinese model_save Hugging Face Hub 창고 ChatLM-English-0.2B에서 직접 수동으로 다운로드하고 다운로드한 파일을 model_save 디렉터리로 이동할 수도 있습니다.
말뭉치 요구사항은 최대한 완벽해야 합니다. 백과사전, 코드, 논문, 블로그, 대화 등 여러 말뭉치를 추가하는 것이 좋습니다.
이 프로젝트는 주로 위키 중국어 백과사전을 기반으로 합니다. 중국어 위키 자료 구하는 방법: 중국어 위키 다운로드 주소: zhwiki, zhwiki-[存档日期]-pages-articles-multistream.xml.bz2 파일 다운로드, 약 2.7GB, 다운로드한 bz2 파일을 wiki.txt로 변환 참조: WikiExtractor , 그런 다음 Python의 OpenCC 라이브러리를 사용하여 중국어 간체로 변환하고 마지막으로 얻은 wiki.simple.txt 프로젝트 루트 디렉터리의 data 디렉터리에 넣습니다. 여러 말뭉치를 하나의 txt 파일로 직접 병합하세요.
훈련 토크나이저는 많은 메모리를 소비하므로 말뭉치가 매우 큰 경우(병합된 txt 파일이 2G를 초과하는 경우) 범주 및 비율에 따라 말뭉치를 샘플링하여 훈련 시간과 메모리 소비를 줄이는 것이 좋습니다. 1.7GB txt 파일을 훈련하려면 약 48GB의 메모리가 필요합니다(예상, 32GB만 있고 스왑을 자주 실행하고 컴퓨터가 오랫동안 멈췄습니다 T_T). 13600k CPU는 약 1시간이 걸립니다.
char level 과 byte level 의 차이는 다음과 같습니다. (구체적인 사용법 차이는 직접 검색해 보세요.) 토크나이저는 기본적으로 char level 훈련합니다. byte level 이 필요한 경우 train_tokenizer.py 에서 token_type='byte' 설정하면 됩니다.
# 原始文本
txt = '这是一段中英混输的句子, (chinese and English, here are words.)'
tokens = charlevel_tokenizer . tokenize ( txt )
print ( tokens )
# char level tokens输出
# ['▁这是', '一段', '中英', '混', '输', '的', '句子', '▁,', '▁(', '▁ch', 'inese', '▁and', '▁Eng', 'lish', '▁,', '▁h', 'ere', '▁', 'are', '▁w', 'ord', 's', '▁.', '▁)']
tokens = bytelevel_tokenizer . tokenize ( txt )
print ( tokens )
# byte level tokens输出
# ['Ġè¿Ļæĺ¯', 'ä¸Ģ段', 'ä¸Ńèĭ±', 'æ··', 'è¾ĵ', 'çļĦ', 'åı¥åŃIJ', 'Ġ,', 'Ġ(', 'Ġch', 'inese', 'Ġand', 'ĠEng', 'lish', 'Ġ,', 'Ġh', 'ere', 'Ġare', 'Ġw', 'ord', 's', 'Ġ.', 'Ġ)']훈련 시작:
# 确保你的训练语料`txt`文件已经data目录下
python train_tokenizer . py {
"prompt" : "对于花园街,你有什么了解或看法吗? " ,
"response" : "花园街(是香港油尖旺区的一条富有特色的街道,位于九龙旺角东部,北至界限街,南至登打士街,与通菜街及洗衣街等街道平行。现时这条街道是香港著名的购物区之一。位于亚皆老街以南的一段花园街,也就是"波鞋街"整条街约150米长,有50多间售卖运动鞋和运动用品的店舖。旺角道至太子道西一段则为排档区,售卖成衣、蔬菜和水果等。花园街一共分成三段。明清时代,花园街是芒角村栽种花卉的地方。此外,根据历史专家郑宝鸿的考证:花园街曾是1910年代东方殷琴拿烟厂的花园。纵火案。自2005年起,花园街一带最少发生5宗纵火案,当中4宗涉及排档起火。2010年。2010年12月6日,花园街222号一个卖鞋的排档于凌晨5时许首先起火,浓烟涌往旁边住宅大厦,消防接报4 "
}jupyter-lab 또는 jupyter 노트북:
train.ipynb 파일을 참조하세요. 서버와의 연결이 끊어진 후 터미널 프로세스가 종료되는 상황을 고려하지 않으려면 jupyter-lab을 사용하는 것이 좋습니다.
콘솔:
콘솔 교육에서는 연결이 끊어진 후 프로세스가 종료된다는 점을 고려해야 합니다. 연결 세션을 설정하려면 프로세스 데몬 도구 Supervisor 또는 screen 사용하는 것이 좋습니다.
먼저 accelerate 구성하고 다음 명령을 실행한 후 프롬프트에 따라 선택합니다. accelerate.yaml 참고: DeepSpeed는 Windows에 설치하는 것이 더 까다롭습니다 .
accelerate config 학습을 시작합니다. 프로젝트에서 제공하는 구성을 사용하려면 다음 명령을 accelerate launch 후 --config_file ./accelerate.yaml 매개변수를 추가하세요 . 구성은 단일 머신 2xGPU 구성을 기반으로 합니다.
사전 훈련을 위한 스크립트는 두 가지가 있습니다. 이 프로젝트에 구현된 트레이너는 train.py 에 해당하고, Huggingface에 의해 구현된 트레이너는 pre_train.py 에 해당하며 둘 중 하나를 사용해도 효과는 동일합니다. 이 프로젝트에 구현된 트레이너는 더욱 아름다운 교육 정보를 표시하고 교육 세부 사항(예: 손실 기능, 로그 기록 등)을 더 쉽게 수정할 수 있도록 지원합니다. 이 프로젝트에 구현된 트레이너는 교육을 계속할 수 있도록 지원합니다. ctrl+c 누르면 스크립트를 종료할 때 중단점 정보가 저장됩니다.
단일 기계 및 단일 카드:
# 本项目实现的trainer
accelerate launch ./train.py train
# 或者使用 huggingface trainer
python pre_train.py 여러 카드가 있는 단일 시스템: 2 그래픽 카드 수입니다. 실제 상황에 따라 수정하십시오.
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train
# 或者使用 huggingface trainer
accelerate launch --multi_gpu --num_processes 2 pre_train.py중단점부터 훈련 계속:
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train --is_keep_training=True
# 或者使用 huggingface trainer
# 需要在`pre_train.py`中的`train`函数添加`resume_from_checkpoint=True`
accelerate launch --multi_gpu --num_processes 2 pre_train.pySFT 데이터 세트는 모두 BELLE boss의 기여에서 비롯되었습니다. 감사합니다. SFT 데이터 세트는 generate_chat_0.4M, train_0.5M_CN 및 train_2M_CN이며, 정리 후 남은 행은 약 137만 개입니다. sft 명령을 사용한 미세 조정 데이터 세트의 예:
{
"prompt" : "解释什么是欧洲启示录" ,
"response" : "欧洲启示录(The Book of Revelation)是新约圣经的最后一卷书,也被称为《启示录》、《默示录》或《约翰默示录》。这本书从宗教的角度描述了世界末日的来临,以及上帝对世界的审判和拯救。 书中的主题包括来临的基督的荣耀,上帝对人性的惩罚和拯救,以及魔鬼和邪恶力量的存在。欧洲启示录是一个充满象征和暗示的文本,对于解读和理解有许多不同的方法和观点。 "
} data 디렉토리에 있는 샘플 parquet 파일을 참조하여 자신만의 데이터 세트를 만드십시오. 데이터 세트 형식은 다음과 같습니다. parquet 파일은 프롬프트를 나타내는 prompt 텍스트 열과 response 텍스트 열로 구성됩니다. 이는 예상되는 모델 출력을 나타냅니다. 미세 조정에 대한 자세한 내용은 model/trainer.py 의 train 방법을 참조하세요. is_finetune True 로 설정되면 미세 조정이 기본적으로 임베딩 레이어와 인코더 레이어를 동결하고 디코더만 훈련합니다. 층. 다른 매개변수를 고정해야 하는 경우 코드를 직접 조정하세요.
SFT 미세 조정 실행:
# 本项目实现的trainer, 添加参数`--is_finetune=True`即可, 参数`--is_keep_training=True`可从任意断点处继续训练
accelerate launch --multi_gpu --num_processes 2 ./train.py --is_finetune=True
# 或者使用 huggingface trainer, 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 sft_train.py
python sft_train.py일반적으로 선호되는 두 가지 방법은 PPO와 DPO입니다. 특정 구현에 대해서는 논문과 블로그를 검색하세요.
PPO 방식(대략적인 선호도 최적화, Proximal Policy Optimization)
1단계: 미세 조정 데이터 세트를 사용하여 감독된 미세 조정(SFT, Supervised Finetuning)을 수행합니다.
2단계: 선호도 데이터 세트(프롬프트에는 최소 2개의 응답, 하나는 원하는 응답, 하나는 원치 않는 응답이 포함되어 있습니다. 여러 응답은 점수별로 정렬될 수 있으며 가장 원하는 응답이 가장 높은 점수를 가짐)를 사용하여 보상 모델(RM)을 훈련합니다. , 보상 모델). peft 라이브러리를 사용하여 Lora 보상 모델을 빠르게 구축할 수 있습니다.
3단계: 모델이 선호도를 충족하도록 RM을 사용하여 SFT 모델에 대한 지도 PPO 교육을 수행합니다.
DPO(Direct Preference Optimization) 미세 조정을 사용합니다( 이 프로젝트는 비디오 메모리를 절약하는 DPO 미세 조정 방법을 사용합니다 ). SFT 모델 획득을 기반으로 긍정적인 답변을 얻기 위해 보상 모델을 훈련할 필요가 없습니다. 선택됨) 및 부정적인 답변(거부됨)을 선택하여 미세 조정을 시작합니다. 미세 조정된 chosen 텍스트는 원본 데이터 세트 alpaca-gpt4-data-zh에서 가져오고 rejected 텍스트는 1 에포크 동안 SFT 미세 조정 후 모델 출력에서 가져옵니다. 다른 두 데이터 세트: huozi_rlhf_data_json 및 rlhf-reward- Single-round-trans_chinese, 병합 후 총 80,000 dpo 데이터.
dpo 데이터 세트 처리 프로세스는 utils/dpo_data_process.py 참조하세요.
DPO 기본 설정 최적화 데이터 세트 예:
{
"prompt" : "为给定的产品创建一个创意标语。,输入:可重复使用的水瓶。 " ,
"chosen" : " "保护地球,从拥有可重复使用的水瓶开始! " " ,
"rejected" : " "让你的水瓶成为你的生活伴侣,使用可重复使用的水瓶,让你的水瓶成为你的伙伴" "
}기본 설정 최적화 실행:
# 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 dpo_train.py
python dpo_train.py model_save 디렉터리에 다음 파일이 있는지 확인하세요. 이 파일은 Hugging Face Hub 창고 ChatLM-English-0.2B에서 찾을 수 있습니다.
ChatLM-mini-Chinese
├─model_save
| ├─config.json
| ├─configuration_chat_model.py
| ├─generation_config.json
| ├─model.safetensors
| ├─modeling_chat_model.py
| ├─special_tokens_map.json
| ├─tokenizer.json
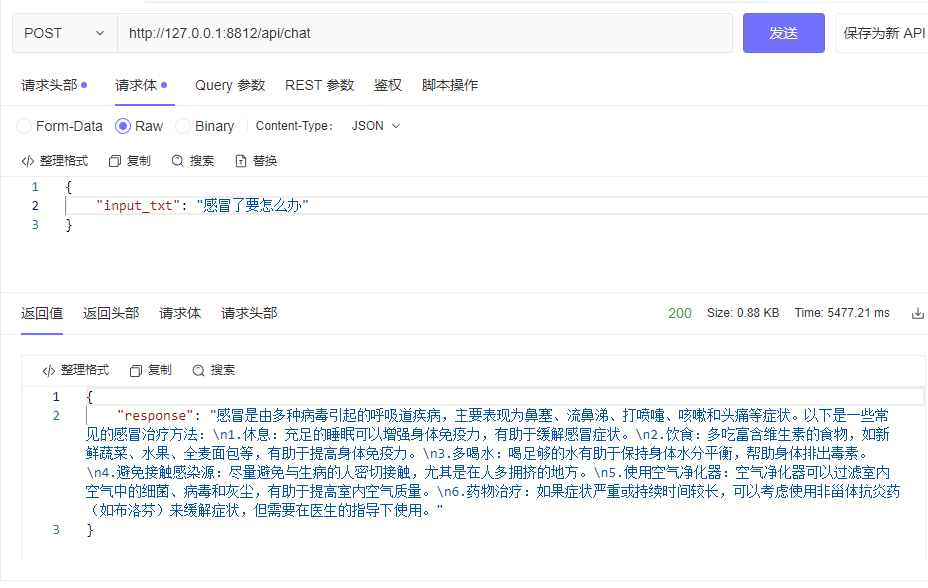
| └─tokenizer_config.jsonpython cli_demo.pypython api_demo.pyAPI 호출 예:
curl --location ' 127.0.0.1:8812/api/chat '
--header ' Content-Type: application/json '
--header ' Authorization: Bearer Bearer '
--data ' {
"input_txt": "感冒了要怎么办"
} ' 
여기서는 다운스트림 미세 조정을 수행하기 위한 예로 텍스트의 삼중항 정보를 사용합니다. 이 작업에 대한 기존 딥러닝 추출 방법은 웨어하우스 pytorch_IE_model을 참조하세요. 예를 들어 《写生随笔》是冶金工业2006年出版的图书,作者是张来亮, 텍스트에서 모든 트리플을 추출합니다 (写生随笔,作者,张来亮) 및 (写生随笔,出版社,冶金工业) .
원본 데이터 세트는 Baidu 삼중 추출 데이터 세트입니다. 처리된 미세 조정 데이터 세트 형식의 예:
{
"prompt" : "请抽取出给定句子中的所有三元组。给定句子:《家乡的月亮》是宋雪莱演唱的一首歌曲,所属专辑是《久违的哥们》 " ,
"response" : " [(家乡的月亮,歌手,宋雪莱),(家乡的月亮,所属专辑,久违的哥们)] "
} 미세 조정을 위해 sft_train.py 스크립트를 직접 사용할 수 있습니다. Finetune_IE_task.ipynb 스크립트에는 자세한 디코딩 프로세스가 포함되어 있습니다. 훈련 데이터 세트에는 약 17000 개의 항목이 있으며, 학습률 5e-5 , 훈련 에포크는 5 . 미세 조정 후에도 다른 작업의 대화 기능이 사라지지 않았습니다.

미세 조정 효과:百度三元组抽取数据集게시한 dev 데이터 세트를 테스트 세트로 사용하여 기존 방법인 pytorch_IE_model과 비교합니다.
| 모델 | F1 점수 | 정밀P | 리콜 R |
|---|---|---|---|
| ChatLM-중국어-0.2B 미세조정 | 0.74 | 0.75 | 0.73 |
| 사전 훈련 없이 ChatLM-중국어-0.2B | 0.51 | 0.53 | 0.49 |
| 전통적인 딥러닝 방법 | 0.80 | 0.79 | 80.1 |
참고: ChatLM-Chinese-0.2B无预训练무작위 매개변수를 직접 초기화하고 학습률 1e-4 로 훈련을 시작하는 것을 의미합니다.
모델 자체는 더 큰 데이터 세트를 사용하여 학습되지 않으며 객관식 질문에 답하기 위한 지침에 맞게 미세 조정되지도 않습니다. C-Eval 점수는 기본적으로 기준 수준이며 필요한 경우 참조로 사용할 수 있습니다. C-Eval 평가 코드 참조: eval/c_eavl.ipynb
| 범주 | 옳은 | 질문_개수 | 정확성 |
|---|---|---|---|
| 인문학 | 63 | 257 | 24.51% |
| 다른 | 89 | 384 | 23.18% |
| 줄기 | 89 | 430 | 20.70% |
| 사회 과학 | 72 | 275 | 26.18% |
이 프로젝트가 도움이 되었다고 생각하시면 인용해 주세요.
@misc{Charent2023,
author={Charent Chen},
title={A small chinese chat language model with 0.2B parameters base on T5},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/ChatLM-mini-Chinese}},
}
본 프로젝트는 오픈 소스 모델 및 코드 또는 모델이 오도, 남용, 유포 또는 부적절하게 악용되어 발생하는 데이터 보안 및 여론 위험으로 인해 발생하는 위험과 책임을 지지 않습니다.


