mage ai
0.9.75
데이터 팀에 마법 같은 힘을 부여하세요.
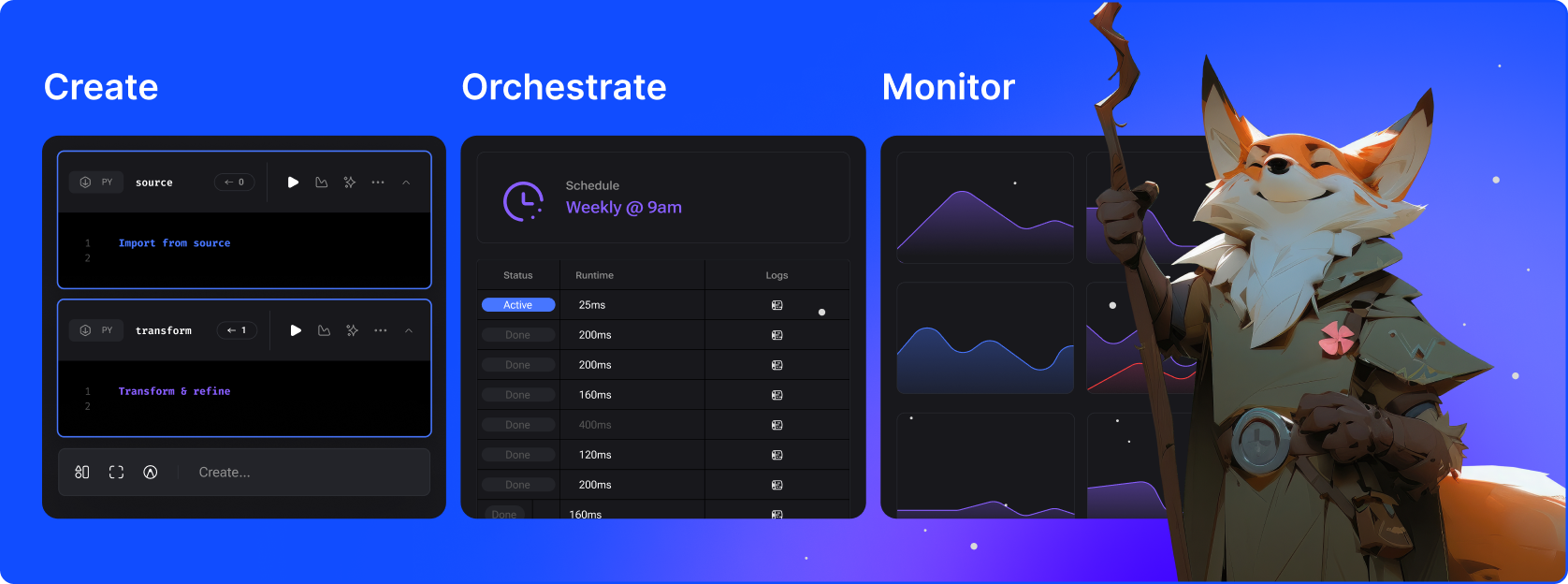
Mage는 데이터 변환 및 통합을 위한 하이브리드 프레임워크입니다. 이는 노트북의 유연성과 모듈식 코드의 엄격함이라는 두 가지 장점을 결합합니다.
타사 소스에서 데이터를 추출하고 동기화합니다.
Python, SQL, R을 사용하여 실시간 및 일괄 파이프라인으로 데이터를 변환합니다.
사전 구축된 커넥터를 사용하여 데이터 웨어하우스 또는 데이터 레이크에 데이터를 로드하세요.
잠을 자지 않고도 수천 개의 파이프라인을 실행, 모니터링 및 조율할 수 있습니다.
또한 수백 가지의 엔터프라이즈급 기능, 인프라 혁신 및 놀라운 놀라움을 제공합니다.
 팀용. 데이터 통합 및 변환을 위한 완전 관리형 플랫폼입니다. 팀용. 데이터 통합 및 변환을 위한 완전 관리형 플랫폼입니다. |  자체 호스팅. 데이터 파이프라인을 구축, 실행, 관리하는 시스템입니다. 자체 호스팅. 데이터 파이프라인을 구축, 실행, 관리하는 시스템입니다. |
시작, 개발 방법, 프로덕션 배포 방법에 대한 문서는 라이브를 확인하세요.
개발자 문서 포털 .
최신 버전의 Mage를 설치하는 권장 방법은 Docker를 통해 다음 명령을 사용하는 것입니다.
docker pull mageai/mageai:최신
pip 또는 conda를 사용하여 Mage를 설치할 수도 있지만, 적절한 환경이 없으면 종속성 문제가 발생할 수 있습니다.
pip 설치 mage-ai
conda install -c conda-forge mage-ai
도움을 찾고 계십니까? 시작하는 가장 빠른 방법은 여기에서 설명서를 확인하는 것입니다.
빠른 예를 찾고 계십니까? 브라우저에서 바로 데모 프로젝트를 열거나 가이드를 확인하세요.
데모 앱을 사용하여 데이터 파이프라인을 구축하고 실행하세요.
경고
라이브 데모는 모든 사람에게 공개됩니다. 민감한 정보(예: 비밀번호, 비밀 등)는 저장하지 마세요.

이미지를 클릭하시면 영상을 재생하실 수 있습니다
| 관현악법 | 관찰 가능성을 통해 데이터 파이프라인을 예약하고 관리합니다. | |
| 공책 | 데이터 파이프라인 코딩을 위한 대화형 Python, SQL, R 편집기입니다. | |
| 데이터 통합 | 타사 소스의 데이터를 내부 대상과 동기화하세요. | |
| 스트리밍 파이프라인 | 실시간 데이터를 수집하고 변환합니다. | |
| DBT | Mage를 사용하여 dbt 모델을 구축, 실행 및 관리하세요. |
3개 파일에 걸쳐 정의된 샘플 데이터 파이프라인 ➝
데이터 로드 ➝
@data_loaderdef load_csv_from_file() -> pl.DataFrame:return pl.read_csv('default_repo/titanic.csv')데이터 변환 ➝
@transformerdef select_columns_from_df(df: pl.DataFrame, *args) -> pl.DataFrame:return df[['Age', 'Fare', 'Survived']]
데이터 내보내기 ➝
@data_exporterdef import_titanic_data_to_disk(df: pl.DataFrame) -> 없음:df.to_csv('default_repo/titanic_transformed.csv')

