lance
v0.20.0

ML을 위한 최신 열 형식 데이터 형식입니다. 100배 더 빠른 임의 액세스, 벡터 인덱스, 데이터 버전 관리 등을 위해 두 줄의 코드로 Parquet에서 변환합니다.
Pandas, DuckDB, Polars 및 pyarrow와 호환되며 더 많은 통합이 예정되어 있습니다.
문서 • 블로그 • Discord • Twitter
Lance는 ML 워크플로 및 데이터 세트에 최적화된 최신 열 형식 데이터 형식입니다. Lance는 다음과 같은 경우에 적합합니다.
Lance의 주요 기능은 다음과 같습니다.
고성능 무작위 액세스: 스캔 성능 저하 없이 Parquet보다 100배 빠릅니다.
벡터 검색: 밀리초 단위로 가장 가까운 이웃을 찾고 OLAP 쿼리를 벡터 검색과 결합합니다.
제로 복사, 자동 버전 관리: 추가 인프라 없이 데이터 버전을 관리합니다.
생태계 통합: Apache Arrow, Pandas, Polars, DuckDB 등이 진행 중입니다.
팁
Lance는 활발하게 개발 중이며 기여를 환영합니다. 자세한 내용은 기여 가이드를 참조하세요.
설치
pip install pylance미리보기 릴리스를 설치하려면 다음 안내를 따르세요.
pip install --pre --extra-index-url https://pypi.fury.io/lancedb/ pylance팁
미리 보기 릴리스는 전체 릴리스보다 더 자주 릴리스되며 최신 기능과 버그 수정 사항이 포함되어 있습니다. 정식 릴리스와 동일한 수준의 테스트를 받습니다. 우리는 해당 내용이 최소 6개월 동안 게시되고 다운로드 가능함을 보장합니다. 특정 버전에 고정하려면 안정적인 릴리스를 선호하세요.
랜스로 변신
import lance
import pandas as pd
import pyarrow as pa
import pyarrow . dataset
df = pd . DataFrame ({ "a" : [ 5 ], "b" : [ 10 ]})
uri = "/tmp/test.parquet"
tbl = pa . Table . from_pandas ( df )
pa . dataset . write_dataset ( tbl , uri , format = 'parquet' )
parquet = pa . dataset . dataset ( uri , format = 'parquet' )
lance . write_dataset ( parquet , "/tmp/test.lance" )랜스 데이터 읽기
dataset = lance . dataset ( "/tmp/test.lance" )
assert isinstance ( dataset , pa . dataset . Dataset )팬더
df = dataset . to_table (). to_pandas ()
df덕DB
import duckdb
# If this segfaults, make sure you have duckdb v0.7+ installed
duckdb . query ( "SELECT * FROM dataset LIMIT 10" ). to_df ()벡터 검색
sift1m 하위 집합 다운로드
wget ftp://ftp.irisa.fr/local/texmex/corpus/sift.tar.gz
tar -xzf sift.tar.gz랜스로 바꿔보세요
import lance
from lance . vector import vec_to_table
import numpy as np
import struct
nvecs = 1000000
ndims = 128
with open ( "sift/sift_base.fvecs" , mode = "rb" ) as fobj :
buf = fobj . read ()
data = np . array ( struct . unpack ( "<128000000f" , buf [ 4 : 4 + 4 * nvecs * ndims ])). reshape (( nvecs , ndims ))
dd = dict ( zip ( range ( nvecs ), data ))
table = vec_to_table ( dd )
uri = "vec_data.lance"
sift1m = lance . write_dataset ( table , uri , max_rows_per_group = 8192 , max_rows_per_file = 1024 * 1024 )인덱스 구축
sift1m . create_index ( "vector" ,
index_type = "IVF_PQ" ,
num_partitions = 256 , # IVF
num_sub_vectors = 16 ) # PQ데이터 세트 검색
# Get top 10 similar vectors
import duckdb
dataset = lance . dataset ( uri )
# Sample 100 query vectors. If this segfaults, make sure you have duckdb v0.7+ installed
sample = duckdb . query ( "SELECT vector FROM dataset USING SAMPLE 100" ). to_df ()
query_vectors = np . array ([ np . array ( x ) for x in sample . vector ])
# Get nearest neighbors for all of them
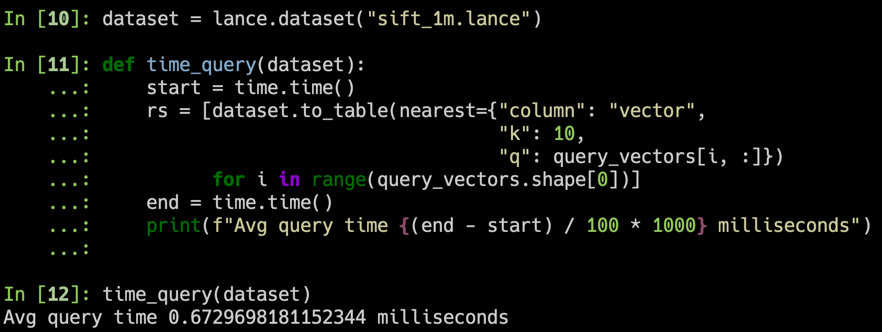
rs = [ dataset . to_table ( nearest = { "column" : "vector" , "k" : 10 , "q" : q })
for q in query_vectors ]| 예배 규칙서 | 설명 |
|---|---|
| 녹 | 핵심 Rust 구현 |
| 파이썬 | Python 바인딩(pyo3) |
| 문서 | 문서 소스 |
여기서는 Lance 디자인의 몇 가지 측면을 강조하겠습니다. 자세한 내용은 전체 Lance 디자인 문서를 참조하세요.
벡터 인덱스 : 임베딩 공간에 대한 유사성 검색을 위한 벡터 인덱스입니다. CPU( x86_64 및 arm )와 GPU( Nvidia (cuda) 및 Apple Silicon (mps) )를 모두 지원합니다.
인코딩 : 빠른 컬럼 스캔과 하위 선형 포인트 쿼리를 모두 달성하기 위해 Lance는 사용자 정의 인코딩과 레이아웃을 사용합니다.
중첩 필드 : Lance는 "감지된 개체에 고양이가 포함된 이미지 찾기"와 같은 효율적인 필터를 지원하기 위해 각 하위 필드를 별도의 열로 저장합니다.
버전 관리 : 매니페스트를 사용하여 스냅샷을 기록할 수 있습니다. 현재 우리는 추가, 덮어쓰기, 색인 생성을 통해 새 버전을 자동으로 생성하는 기능을 지원합니다.
빠른 업데이트 (ROADMAP): 미리 쓰기 로그를 통해 업데이트가 지원됩니다.
풍부한 보조 인덱스 (ROADMAP):
우리는 SIFT 데이터 세트를 사용하여 128D의 1M 벡터로 결과를 벤치마킹했습니다.
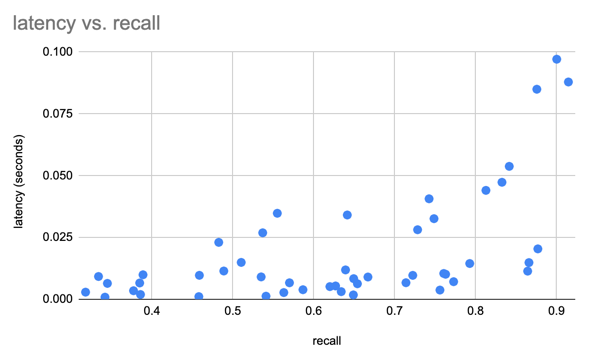
우리는 Parquet 및 원시 이미지/XML과 비교하여 Lance의 예비 성능 테스트를 수행하기 위해 Oxford Pet 데이터 세트를 사용하여 Lance 데이터 세트를 생성합니다. 분석 쿼리의 경우 Lance는 원시 메타데이터를 읽는 것보다 50~100배 더 좋습니다. 일괄 무작위 액세스의 경우 Lance는 쪽모이 세공 파일과 원시 파일보다 100배 더 좋습니다.

기계 학습 개발 주기에는 다음 단계가 포함됩니다.
그래프 LR
A[수집] --> B[탐험];
B --> C[분석];
C --> D[기능 엔지니어];
D --> E[훈련];
E --> F[평가];
F --> C;
E --> G[배포];
G --> H[모니터링];
H --> A;
사람들은 성능의 다양한 단계에 따라 다양한 데이터 표현을 사용하거나 사용 가능한 도구에 따라 제한됩니다. 학계는 주로 주석을 위해 XML/JSON을 사용하고 딥 러닝을 위해 압축된 이미지/센서 데이터를 사용하는데, 이는 데이터 인프라에 통합하기 어렵고 클라우드 스토리지를 통한 훈련 속도가 느립니다. 업계에서는 데이터 레이크(Parquet 기반 기술, 즉 Delta Lake, Iceberg) 또는 데이터 웨어하우스(AWS Redshift 또는 Google BigQuery)를 사용하여 데이터를 수집하고 분석하지만 데이터를 Rikai/ 페타스톰 또는 TFRecord. 여러 단일 목적의 데이터 변환은 물론 클라우드 스토리지와 로컬 교육 인스턴스 간의 복사본 동기화가 일반적인 관행이 되었습니다.
기존의 각 데이터 형식은 원래 설계된 워크로드에 탁월하지만, 데이터 사일로를 줄이고 다단계 ML 개발 주기에 맞게 조정된 새로운 데이터 형식이 필요합니다.
ML 개발 주기의 각 단계에서 다양한 데이터 형식을 비교합니다.
| 창 | 쪽모이 세공 & ORC | JSON 및 XML | TF레코드 | 데이터 베이스 | 창고 | |
|---|---|---|---|---|---|---|
| 해석학 | 빠른 | 빠른 | 느린 | 느린 | 품위 있는 | 빠른 |
| 기능 엔지니어링 | 빠른 | 빠른 | 품위 있는 | 느린 | 품위 있는 | 좋은 |
| 훈련 | 빠른 | 품위 있는 | 느린 | 빠른 | 해당 없음 | 해당 없음 |
| 탐구 | 빠른 | 느린 | 빠른 | 느린 | 빠른 | 품위 있는 |
| 인프라 지원 | 부자 | 부자 | 품위 있는 | 제한된 | 부자 | 부자 |
Lance는 현재 다음 회사에서 생산에 사용됩니다.


