bloomz.cpp
1.0.0
순수 C/C++에서 HuggingFace의 BLOOM 유사 모델 추론.
이 저장소는 BLOOM 모델을 지원하기 위해 @ggerganov의 놀라운 llama.cpp 저장소 위에 구축되었습니다. BloomForCausalLM.from_pretrained() 사용하여 로드할 수 있는 모든 모델을 지원합니다.
먼저 저장소를 복제하고 빌드해야 합니다.
git clone https://github.com/NouamaneTazi/bloomz.cpp
cd bloomz.cpp
make그런 다음 모델 가중치를 ggml 형식으로 변환해야 합니다. 모든 BLOOM 모델을 변환할 수 있습니다.
허브에서 호스팅되는 일부 가중치는 이미 변환되었습니다. 여기에서 목록을 찾을 수 있습니다.
그렇지 않은 경우 가중치를 변환하는 가장 빠른 방법은 이 변환기 도구를 사용하는 것입니다. Huggingface Hub에서 호스팅되는 공간으로, 귀하를 위해 가중치를 변환 및 수량화하고 이를 귀하가 선택한 저장소에 업로드합니다.
원하는 경우 기계의 중량을 수동으로 변환할 수 있습니다.
# install required libraries
python3 -m pip install torch numpy transformers accelerate
# download and convert the 7B1 model to ggml FP16 format
python3 convert-hf-to-ggml.py bigscience/bloomz-7b1 ./models
# Note: you can add --use-f32 to convert to FP32 instead of FP16선택적으로 모델을 4비트로 양자화할 수 있습니다.
./quantize ./models/ggml-model-bloomz-7b1-f16.bin ./models/ggml-model-bloomz-7b1-f16-q4_0.bin 2마지막으로 추론을 실행할 수 있습니다.
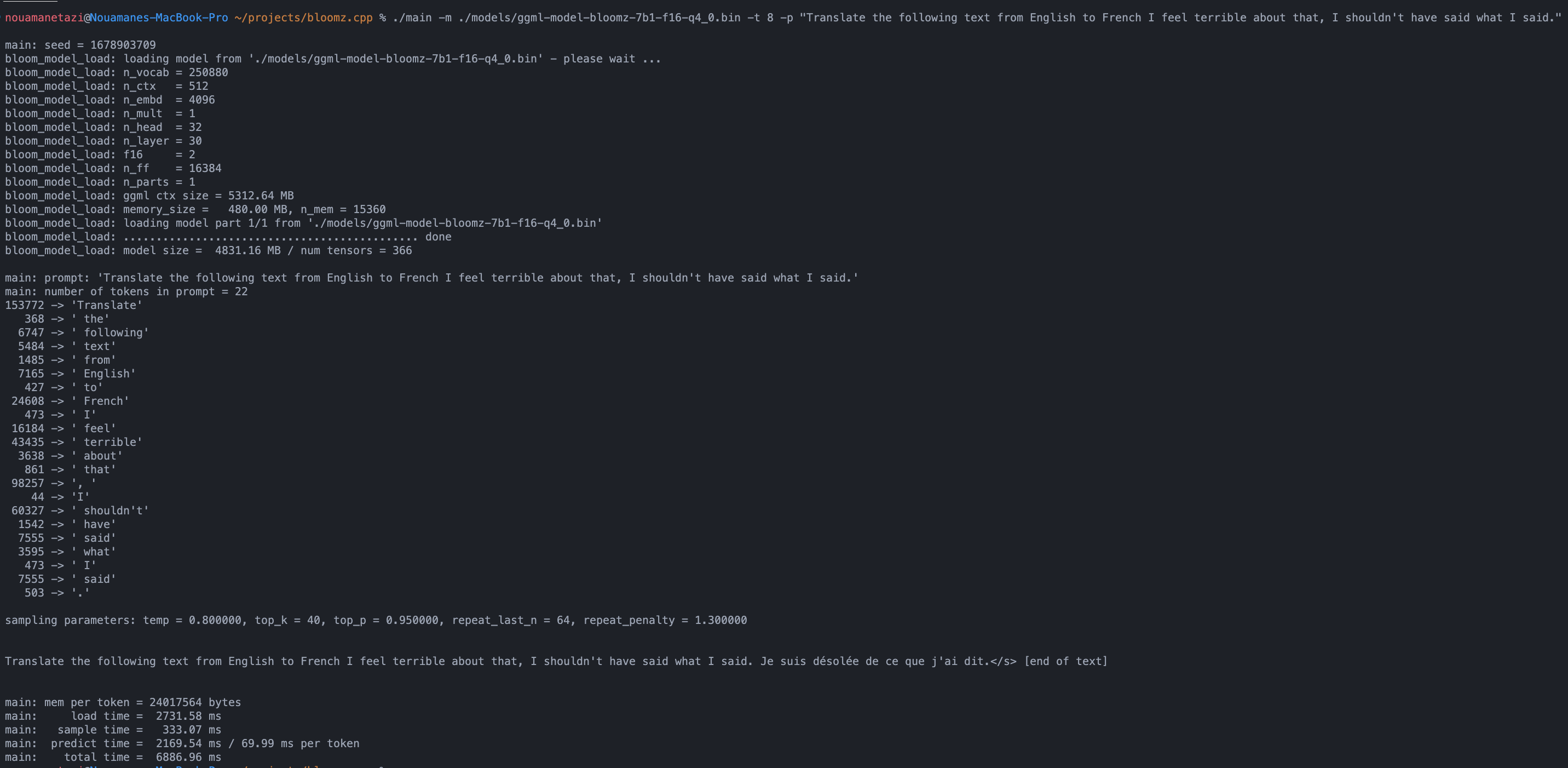
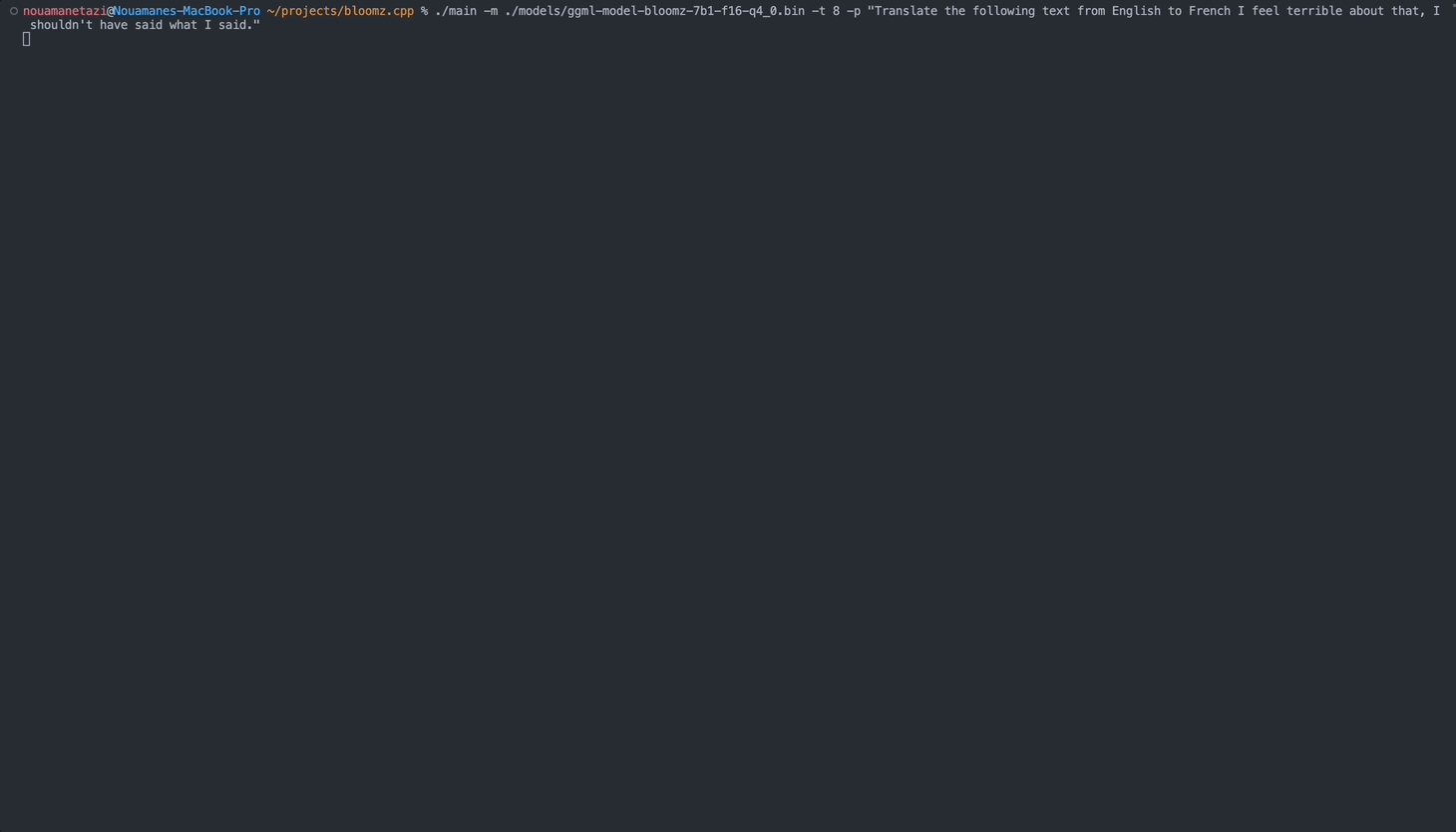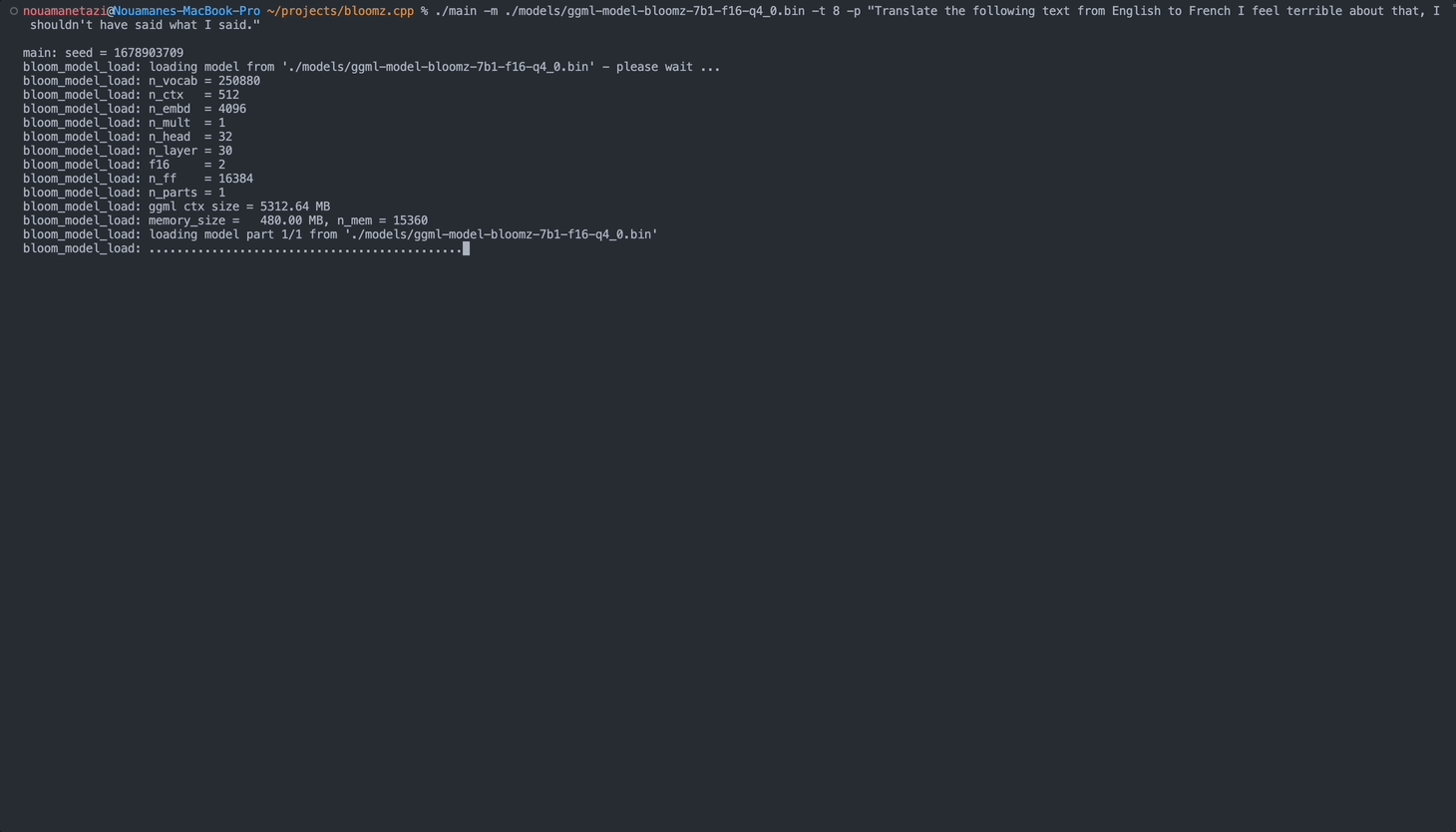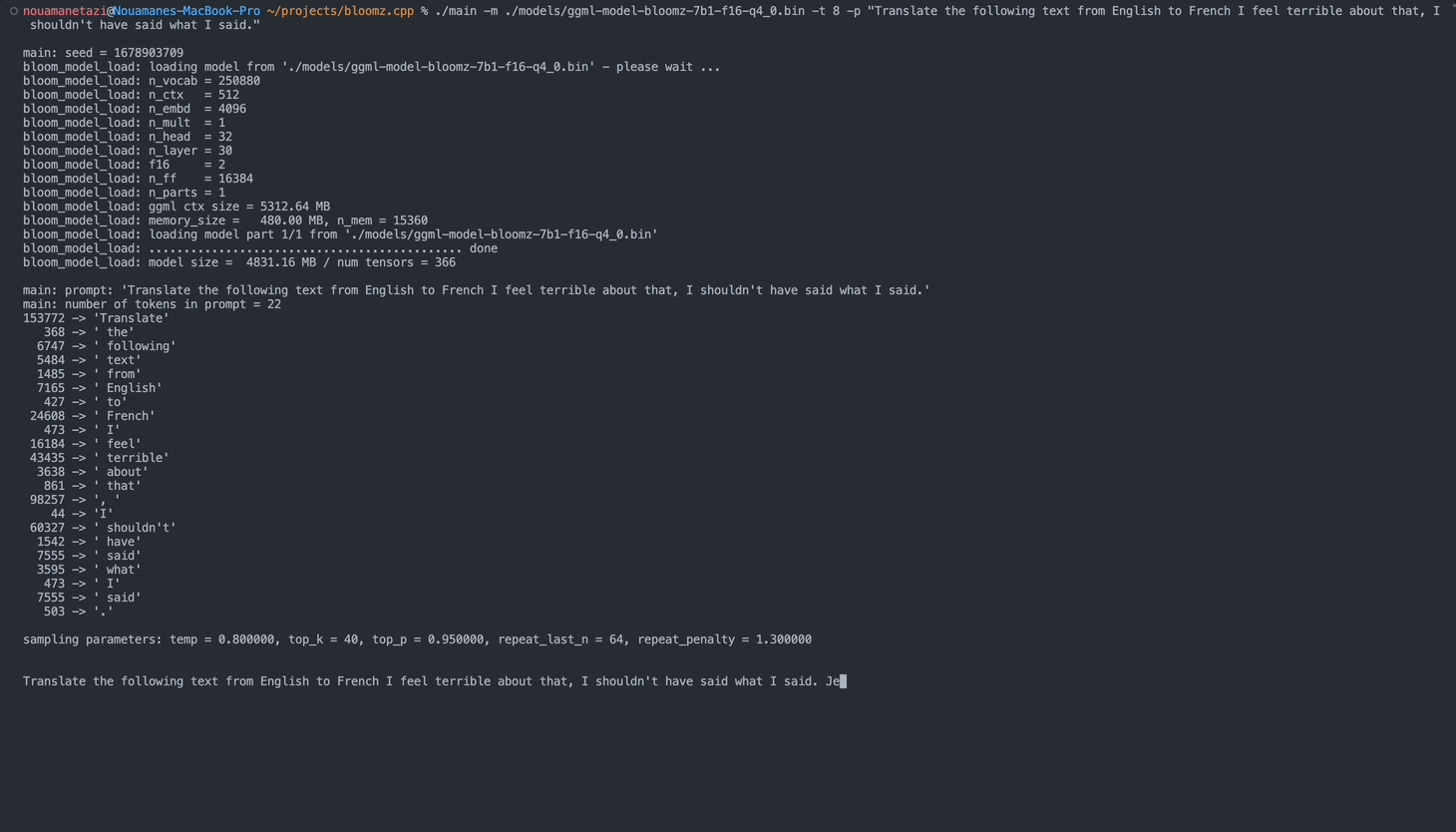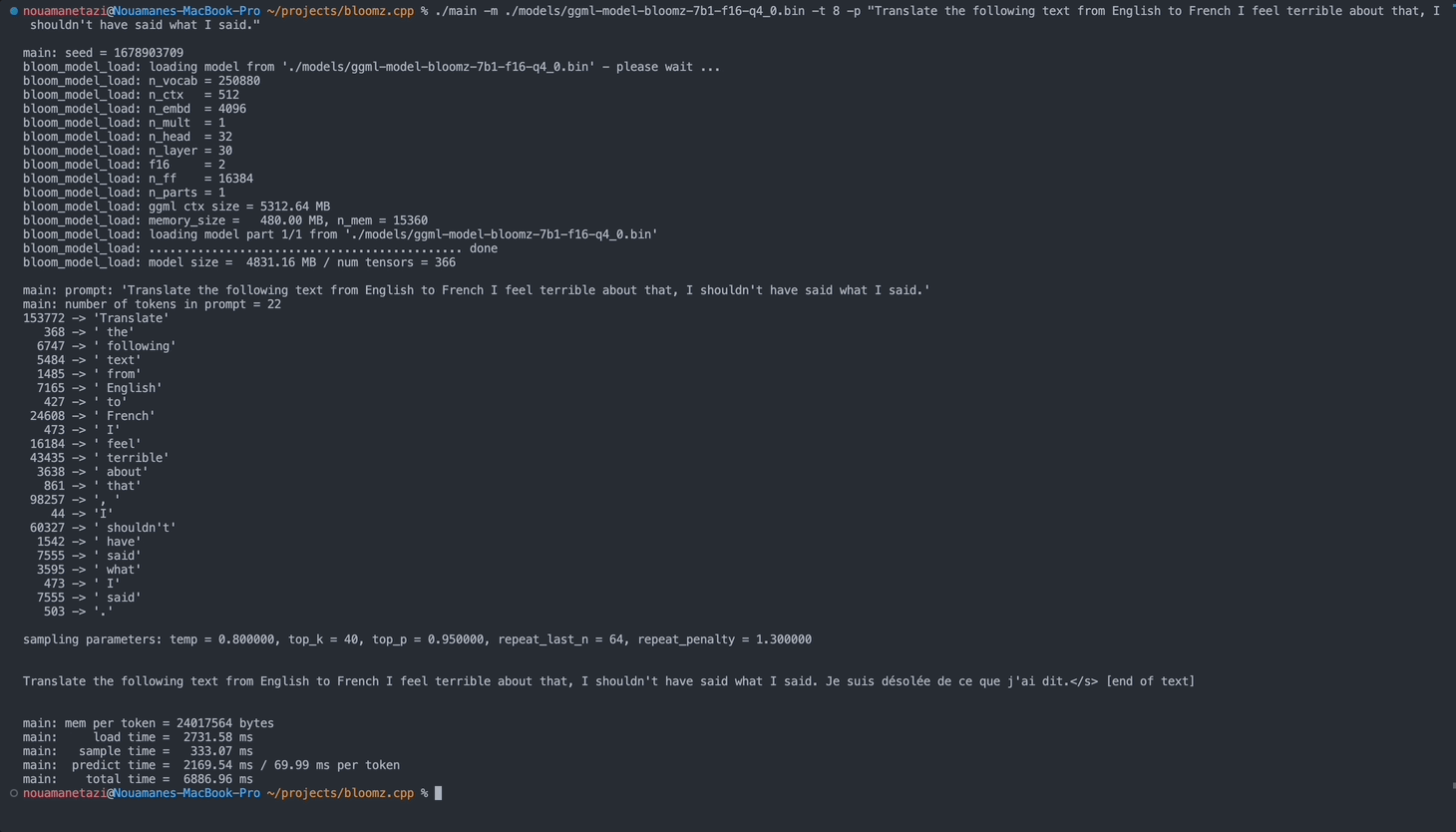
./main -m ./models/ggml-model-bloomz-7b1-f16-q4_0.bin -t 8 -n 128출력은 다음과 같아야 합니다.
make && ./main -m models/ggml-model-bloomz-7b1-f16-q4_0.bin -p ' Translate "Hi, how are you?" in French: ' -t 8 -n 256
I llama.cpp build info:
I UNAME_S: Darwin
I UNAME_P: arm
I UNAME_M: arm64
I CFLAGS: -I. -O3 -DNDEBUG -std=c11 -fPIC -pthread -DGGML_USE_ACCELERATE
I CXXFLAGS: -I. -I./examples -O3 -DNDEBUG -std=c++11 -fPIC -pthread
I LDFLAGS: -framework Accelerate
I CC: Apple clang version 13.1.6 (clang-1316.0.21.2.5)
I CXX: Apple clang version 13.1.6 (clang-1316.0.21.2.5)
make: Nothing to be done for ` default ' .
main: seed = 1678899845
llama_model_load: loading model from ' models/ggml-model-bloomz-7b1-f16-q4_0.bin ' - please wait ...
llama_model_load: n_vocab = 250880
llama_model_load: n_ctx = 512
llama_model_load: n_embd = 4096
llama_model_load: n_mult = 1
llama_model_load: n_head = 32
llama_model_load: n_layer = 30
llama_model_load: f16 = 2
llama_model_load: n_ff = 16384
llama_model_load: n_parts = 1
llama_model_load: ggml ctx size = 5312.64 MB
llama_model_load: memory_size = 480.00 MB, n_mem = 15360
llama_model_load: loading model part 1/1 from ' models/ggml-model-bloomz-7b1-f16-q4_0.bin '
llama_model_load: ............................................. done
llama_model_load: model size = 4831.16 MB / num tensors = 366
main: prompt: ' Translate " Hi, how are you? " in French: '
main: number of tokens in prompt = 11
153772 -> ' Translate '
17959 -> ' " H'
76 -> 'i'
98257 -> ', '
20263 -> 'how'
1306 -> ' are'
1152 -> ' you'
2040 -> '?'
5 -> ' " '
361 -> ' in '
196427 -> ' French: '
sampling parameters: temp = 0.800000, top_k = 40, top_p = 0.950000, repeat_last_n = 64, repeat_penalty = 1.300000
Translate "Hi, how are you?" in French: Bonjour, comment ça va?</s> [end of text]
main: mem per token = 24017564 bytes
main: load time = 3092.29 ms
main: sample time = 2.40 ms
main: predict time = 1003.04 ms / 59.00 ms per token
main: total time = 5307.23 ms 사용 가능한 옵션 목록은 다음과 같습니다.
usage: ./main [options]
options:
-h, --help show this help message and exit
-s SEED, --seed SEED RNG seed (default: -1)
-t N, --threads N number of threads to use during computation (default: 4)
-p PROMPT, --prompt PROMPT
prompt to start generation with (default: random)
-n N, --n_predict N number of tokens to predict (default: 128)
--top_k N top-k sampling (default: 40)
--top_p N top-p sampling (default: 0.9)
--repeat_last_n N last n tokens to consider for penalize (default: 64)
--repeat_penalty N penalize repeat sequence of tokens (default: 1.3)
--temp N temperature (default: 0.8)
-b N, --batch_size N batch size for prompt processing (default: 8)
-m FNAME, --model FNAME
model path (default: models/ggml-model-bloomz-7b1-f16-q4_0.bin)| 모델 | 디스크 | 메모리 |
|---|---|---|
bloomz-7b1-f16-q4_0 | 4.7GB | 5.3GB |
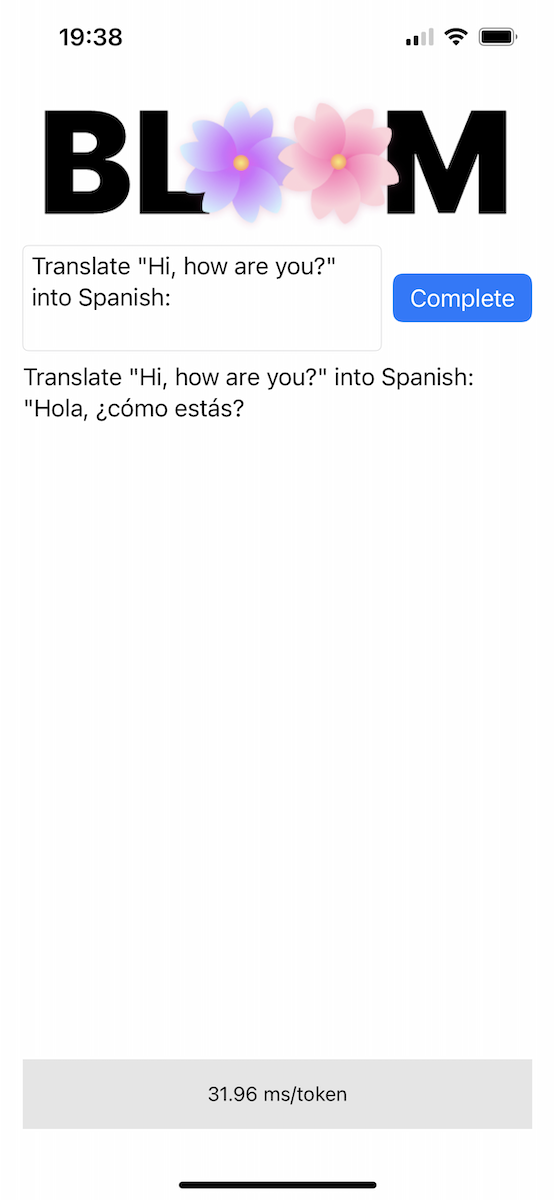
저장소에는 Bloomer 디렉터리에 개념 증명 iOS 앱이 포함되어 있습니다. 해당 폴더 안에 ggml-model-bloomz-560m-f16.bin 이라는 파일을 배치하여 변환된 모델 가중치를 제공해야 합니다. iPhone에서는 다음과 같이 보입니다.