customer support chatbot
1.0.0
챗봇(Chatbot)은 인간과 유사한 방식으로 대화를 진행하는 컴퓨터 프로그램입니다. 이 프로젝트는 고객 지원 상담원으로서 사용자의 질문에 답변하는 챗봇을 구현합니다. AppleSupport, AmazonHelp, Uber_Support, Delta 및 SpotifyCares와 같은 고객 지원 챗봇이 구현되었습니다. 챗봇은 트위터에서 고객 지원과 사용자 사이에 공개적으로 사용 가능한 대화를 통해 훈련되었습니다.
챗봇은 주의를 기울여 시퀀스 대 시퀀스 딥러닝 모델로 구현됩니다. 프로젝트는 주로 Bahdanau et al.을 기반으로 합니다. 2014, 루옹 외. 2015. 및 Vinyals et al., 2015.
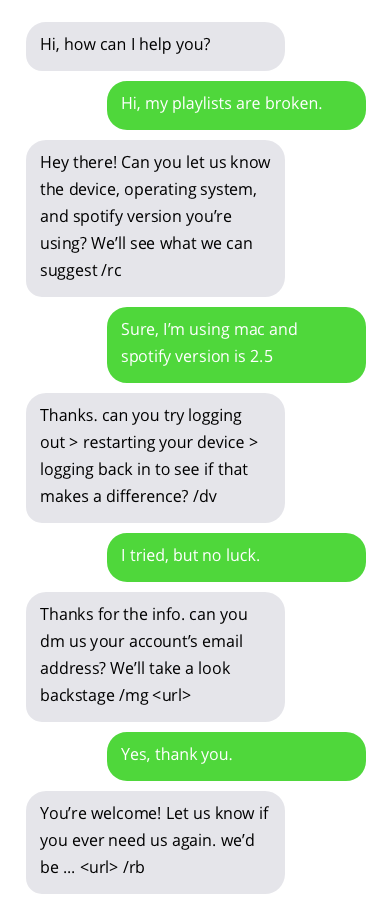
고객 지원 챗봇과의 샘플 대화. 챗봇과의 대화는 이상적이지는 않지만 유망한 결과를 보여줍니다. 챗봇 답변은 회색 거품 안에 있습니다.
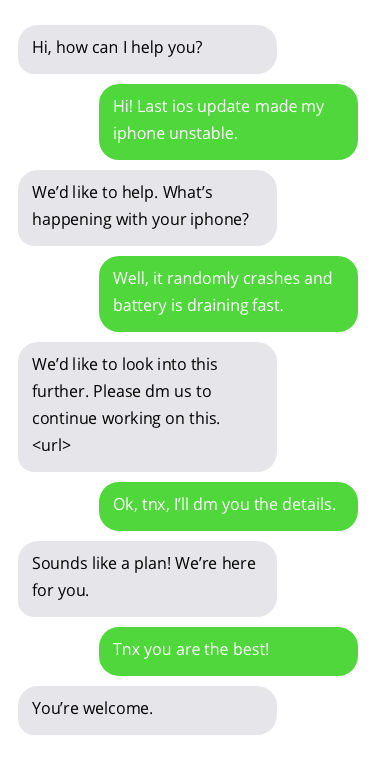
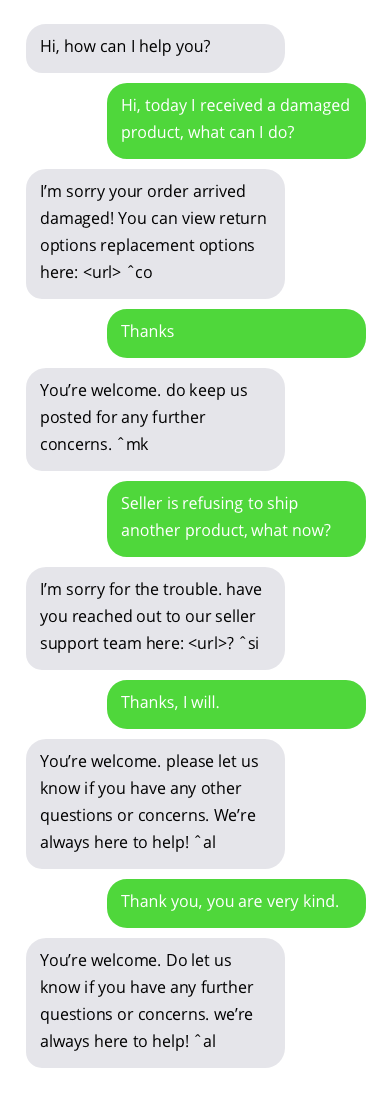
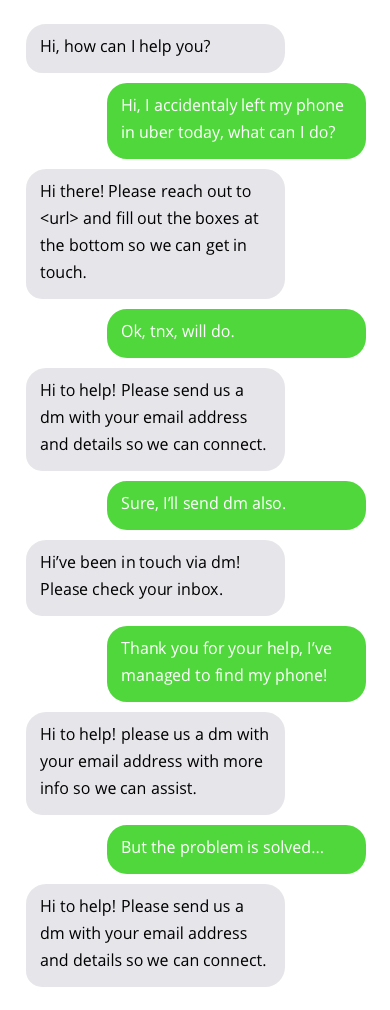
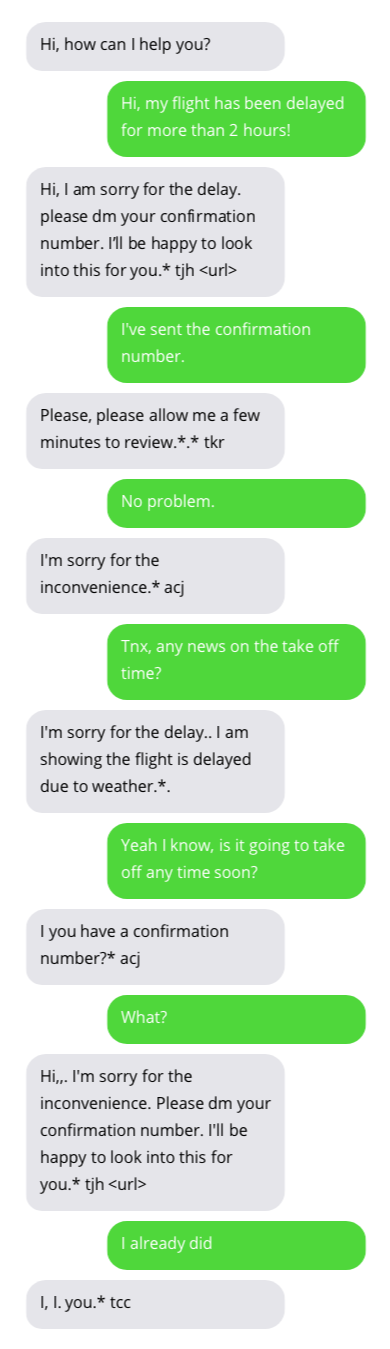
챗봇 훈련에 사용되는 데이터 세트는 여기에서 찾을 수 있습니다. 이 데이터 세트는 Twitter에서 고객 지원과 사용자 간의 공개적으로 사용 가능한 대화를 수집하여 생성되었습니다. 데이터 세트 작성자에게 많은 감사를 드립니다!
사전 학습된 모델을 사용하거나 자체 챗봇을 학습하여 챗봇을 시험해 볼 수 있습니다.
pip3 install -r requirements.txt
python3 -m spacy download en사전 훈련된 고객 서비스 챗봇을 다운로드하려면 이 저장소의 루트에서 다음 명령을 실행하세요.
wget https://www.dropbox.com/s/ibm49gx1gefpqju/pretrained-models.zip
unzip pretrained-models.zip
rm pretrained-models.zip
sudo chmod +x predict.py 이제 predict.py 스크립트를 사용하여 고객 서비스 챗봇과 "대화"할 수 있습니다. 다음 고객 서비스 챗봇을 사용할 수 있습니다: apple,amazon,uber,delta,spotify . 다음 예는 apple 고객 서비스 챗봇을 실행하는 방법을 보여줍니다.
./predict.py -cs apple챗봇을 직접 훈련하도록 선택할 수 있습니다. 이 프로젝트에 사용된 Twitter 데이터세트를 다운로드하고 형식을 지정하려면 다음 명령을 실행하세요.
wget https://www.dropbox.com/s/nmnlcncn7jtb7i9/twcs.zip
unzip twcs.zip
mkdir data
mv twcs.csv data
rm twcs.zip
python3 datasets/twitter_customer_support/format.py # this runs for couple of hours
sudo chmod +x train.py경고 이 블록은 몇 시간 동안 실행됩니다!
이제 train.py 사용하여 챗봇을 훈련할 수 있습니다.
train.py seq2seq 챗봇 훈련에 사용됩니다.
usage: train.py [-h] [--max-epochs MAX_EPOCHS] [--gradient-clip GRADIENT_CLIP]
[--batch-size BATCH_SIZE] [--learning-rate LEARNING_RATE]
[--train-embeddings] [--save-path SAVE_PATH]
[--save-every-epoch]
[--dataset {twitter-applesupport,twitter-amazonhelp,twitter-delta,twitter-spotifycares,twitter-uber_support,twitter-all,twitter-small}]
[--teacher-forcing-ratio TEACHER_FORCING_RATIO] [--cuda]
[--multi-gpu]
[--embedding-type {glove.42B.300d,glove.840B.300d,glove.twitter.27B.25d,glove.twitter.27B.50d,glove.twitter.27B.100d,glove.twitter.27B.200d,glove.6B.50d,glove.6B.100d,glove.6B.200d,glove.6B.300d} | --embedding-size EMBEDDING_SIZE]
[--encoder-rnn-cell {LSTM,GRU}]
[--encoder-hidden-size ENCODER_HIDDEN_SIZE]
[--encoder-num-layers ENCODER_NUM_LAYERS]
[--encoder-rnn-dropout ENCODER_RNN_DROPOUT]
[--encoder-bidirectional] [--decoder-type {bahdanau,luong}]
[--decoder-rnn-cell {LSTM,GRU}]
[--decoder-hidden-size DECODER_HIDDEN_SIZE]
[--decoder-num-layers DECODER_NUM_LAYERS]
[--decoder-rnn-dropout DECODER_RNN_DROPOUT]
[--luong-attn-hidden-size LUONG_ATTN_HIDDEN_SIZE]
[--luong-input-feed]
[--decoder-init-type {zeros,bahdanau,adjust_pad,adjust_all}]
[--attention-type {none,global,local-m,local-p}]
[--attention-score {dot,general,concat}]
[--half-window-size HALF_WINDOW_SIZE]
[--local-p-hidden-size LOCAL_P_HIDDEN_SIZE]
[--concat-attention-hidden-size CONCAT_ATTENTION_HIDDEN_SIZE]
Script for training seq2seq chatbot.
optional arguments:
-h, --help show this help message and exit
--max-epochs MAX_EPOCHS
Max number of epochs models will be trained.
--gradient-clip GRADIENT_CLIP
Gradient clip value.
--batch-size BATCH_SIZE
Batch size.
--learning-rate LEARNING_RATE
Initial learning rate.
--train-embeddings Should gradients be propagated to word embeddings.
--save-path SAVE_PATH
Folder where models (and other configs) will be saved
during training.
--save-every-epoch Save model every epoch regardless of validation loss.
--dataset {twitter-applesupport,twitter-amazonhelp,twitter-delta,twitter-spotifycares,twitter-uber_support,twitter-all,twitter-small}
Dataset for training model.
--teacher-forcing-ratio TEACHER_FORCING_RATIO
Teacher forcing ratio used in seq2seq models. [0-1]
--embedding-type {glove.42B.300d,glove.840B.300d,glove.twitter.27B.25d,glove.twitter.27B.50d,glove.twitter.27B.100d,glove.twitter.27B.200d,glove.6B.50d,glove.6B.100d,glove.6B.200d,glove.6B.300d}
Pre-trained embeddings type.
--embedding-size EMBEDDING_SIZE
Dimensionality of word embeddings.
GPU:
GPU related settings.
--cuda Use cuda if available.
--multi-gpu Use multiple GPUs if available.
Encoder:
Encoder hyperparameters.
--encoder-rnn-cell {LSTM,GRU}
Encoder RNN cell type.
--encoder-hidden-size ENCODER_HIDDEN_SIZE
Encoder RNN hidden size.
--encoder-num-layers ENCODER_NUM_LAYERS
Encoder RNN number of layers.
--encoder-rnn-dropout ENCODER_RNN_DROPOUT
Encoder RNN dropout probability.
--encoder-bidirectional
Use bidirectional encoder.
Decoder:
Decoder hyperparameters.
--decoder-type {bahdanau,luong}
Type of the decoder.
--decoder-rnn-cell {LSTM,GRU}
Decoder RNN cell type.
--decoder-hidden-size DECODER_HIDDEN_SIZE
Decoder RNN hidden size.
--decoder-num-layers DECODER_NUM_LAYERS
Decoder RNN number of layers.
--decoder-rnn-dropout DECODER_RNN_DROPOUT
Decoder RNN dropout probability.
--luong-attn-hidden-size LUONG_ATTN_HIDDEN_SIZE
Luong decoder attention hidden projection size
--luong-input-feed Whether Luong decoder should use input feeding
approach.
--decoder-init-type {zeros,bahdanau,adjust_pad,adjust_all}
Decoder initial RNN hidden state initialization.
Attention:
Attention hyperparameters.
--attention-type {none,global,local-m,local-p}
Attention type.
--attention-score {dot,general,concat}
Attention score function type.
--half-window-size HALF_WINDOW_SIZE
D parameter from Luong et al. paper. Used only for
local attention.
--local-p-hidden-size LOCAL_P_HIDDEN_SIZE
Local-p attention hidden size (used when predicting
window position).
--concat-attention-hidden-size CONCAT_ATTENTION_HIDDEN_SIZE
Attention layer hidden size. Used only with concat
score function.
predict.py 는 seq2seq 챗봇과 "대화"하는 데 사용됩니다.
usage: predict.py [-h] [-cs {apple,amazon,uber,delta,spotify}] [-p MODEL_PATH]
[-e EPOCH] [--sampling-strategy {greedy,random,beam_search}]
[--max-seq-len MAX_SEQ_LEN] [--cuda]
Script for "talking" with pre-trained chatbot.
optional arguments:
-h, --help show this help message and exit
-cs {apple,amazon,uber,delta,spotify}, --customer-service {apple,amazon,uber,delta,spotify}
-p MODEL_PATH, --model-path MODEL_PATH
Path to directory with model args, vocabulary and pre-
trained pytorch models.
-e EPOCH, --epoch EPOCH
Model from this epoch will be loaded.
--sampling-strategy {greedy,random,beam_search}
Strategy for sampling output sequence.
--max-seq-len MAX_SEQ_LEN
Maximum length for output sequence.
--cuda Use cuda if available.


