Seq2seq Chatbot for Keras
1.0.0
이 저장소에는 seq2seq 모델링을 기반으로 하는 새로운 챗봇 생성 모델이 포함되어 있습니다. 이 모델에 대한 자세한 내용은 생성 대화 에이전트를 위한 엔드투엔드 적대 학습 논문의 섹션 3에서 확인할 수 있습니다. 이 저장소의 아이디어나 코드 조각을 사용하여 출판하는 경우 이 논문을 친절하게 인용해 주세요.
여기에서 사용할 수 있는 훈련된 모델은 ~8K 쌍의 컨텍스트(현재 지점까지의 대화의 마지막 두 발화)와 해당 응답으로 구성된 작은 데이터 세트를 사용했습니다. 데이터는 온라인 영어 강좌의 대화에서 수집되었습니다. 이 훈련된 모델은 폐쇄 도메인 데이터 세트를 사용하여 실제 애플리케이션에 맞게 미세 조정할 수 있습니다.
표준 seq2seq 모델은 입력 및 출력 발언이 서로 다른 언어로 작성되기 때문에 입력 및 출력 시퀀스에 속하는 단어에 대해 서로 다른 사전 확률 분포를 갖는 작업인 신경 기계 번역에서 인기를 얻었습니다. 여기에 제시된 아키텍처는 입력 및 출력 단어에 대해 동일한 사전 분포를 가정합니다. 따라서 새로운 모델의 채택을 통해 인코딩과 디코딩 과정 사이에 임베딩 레이어(Glove pre-trained word embedding)를 공유합니다. 상황 민감도를 향상시키기 위해 사고 벡터(즉, 인코더 출력)는 현재 지점까지 대화의 마지막 두 발화를 인코딩합니다. 답변 생성 시 맥락을 잊지 않기 위해 생각 벡터를 현재 지점까지 생성된 불완전 답변을 인코딩하는 밀집 벡터에 연결합니다. 결과 벡터는 답변의 현재 토큰을 예측하는 밀집 레이어에 제공됩니다. 우리 모델의 장점에 대한 더 나은 통찰력을 얻으려면 우리 논문의 섹션 3.1을 참조하십시오.
알고리즘은 예측된 토큰을 불완전한 답에 포함시키고 이를 아래 표시된 모델의 오른쪽 입력 레이어에 다시 공급하는 방식으로 반복됩니다.
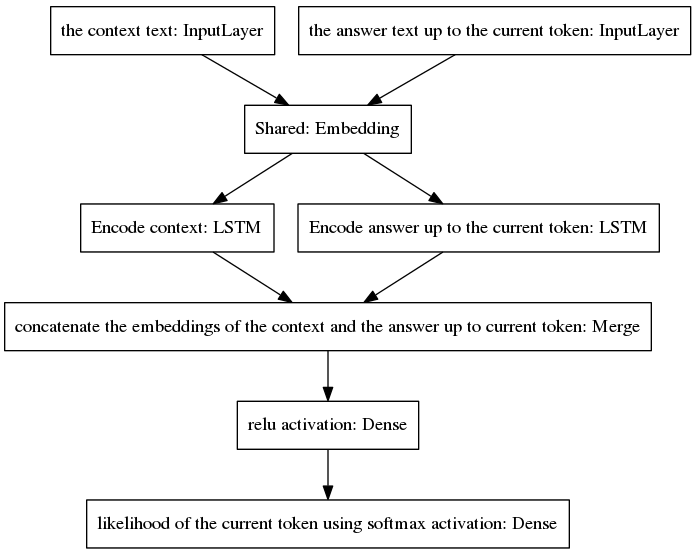
위 그림에서 볼 수 있듯이 두 개의 LSTM은 병렬로 배열되어 있는 반면, canonical seq2seq에는 반복적인 인코더 및 디코더 계층이 직렬로 배열되어 있습니다. 반복 레이어는 시간에 따른 역전파 중에 전개되어 많은 수의 중첩된 함수가 발생하므로 그라데이션이 사라질 위험이 더 높습니다. 이는 게이트 아키텍처의 경우에도 표준 seq2seq 모델의 반복 레이어의 캐스케이드로 인해 악화됩니다. LSTM과 같은 것입니다. 나는 이것이 표준 seq2seq보다 훈련 중에 내 모델이 더 잘 작동하는 이유 중 하나라고 생각합니다.
다음 의사 코드는 알고리즘을 설명합니다.

이 새로운 모델의 훈련은 몇 번의 epoch에 수렴됩니다. 8K 훈련 예제의 데이터 세트를 사용하면 GPU GTX980에서 실행되는 에포크당 139초의 비용으로 0.0318의 범주형 교차 엔트로피 손실에 도달하는 데 100개의 에포크만 필요합니다. 이 저장소에서 제공되는 이 훈련된 모델의 성능은 Cornell Movie Dialogs Corpus의 ~300K 훈련 예제에서 훈련된 바닐라 seq2seq 모델의 성능만큼 설득력이 있는 것처럼 보이지만 훈련하는 데 훨씬 적은 계산 노력이 필요합니다.
사전 학습된 모델과 채팅하려면 다음 안내를 따르세요.
여기에서 찾을 수 있는 Python 파일 "conversation.py", 어휘 파일 "vocabulary_movie" 및 순 가중치 "my_model_weights20"을 다운로드합니다.
Conversation.py를 실행하세요.
새로운 GAN 기반 교육 알고리즘으로 교육된 새 모델과 대화하려면 다음을 수행하세요.
여기에서 찾을 수 있는 Python 파일 "conversation_discriminator.py", 어휘 파일 "vocabulary_movie" 및 순 가중치 "my_model_weights20.h5", "my_model_weights.h5" 및 "my_model_weights_discriminator.h5"를 다운로드합니다.
대화_차별자.py를 실행합니다.
이 모델은 동일한 훈련 데이터를 사용하여 더 나은 성능을 제공합니다. GAN 기반 모델의 판별자는 두 모델 사이에서 최상의 답변을 선택하는 데 사용됩니다. 하나는 교사 강제로 훈련되고 다른 하나는 새로운 GAN과 유사한 훈련 방법으로 훈련됩니다. 자세한 내용은 이 문서에서 확인할 수 있습니다.
새 모델을 훈련하거나 자체 데이터를 미세 조정하려면 다음을 수행하세요.
처음부터 훈련하려면 my_model_weights20.h5 파일을 삭제하세요. 데이터를 세부적으로 조정하려면 이 파일을 보관하세요.
Glove 폴더 'glove.6B'를 다운로드하고 이 폴더를 챗봇 디렉터리에 포함시킵니다(여기에서 이 폴더를 찾을 수 있습니다). 이 알고리즘은 훈련 중에 미세 조정되는 사전 훈련된 단어 임베딩을 사용하여 전이 학습을 적용합니다.
분할_qa.py를 실행하여 훈련 데이터의 콘텐츠를 'context' 및 '답변'이라는 두 개의 파일로 분할하고, 패딩된 문장을 'Pended_context' 및 'Pended_answers' 파일에 저장하려면 get_train_data.py를 실행하세요.
train_bot.py를 실행하여 챗봇을 훈련시킵니다(GPU를 사용하는 것이 좋습니다. 그렇게 하려면 다음을 입력하십시오: THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32,Exception_verbosity=high python train_bot.py).
훈련 데이터의 이름을 "data.txt"로 지정하세요. 이 파일은 한 줄에 하나의 대화 발언을 포함해야 합니다. 데이터세트가 큰 경우 num_subsets 변수(train_bot.py의 29번째 줄)를 더 큰 숫자로 설정하세요.
Weights_file = 'my_model_weights20.h5' Weights_file_GAN = 'my_model_weights.h5' Weights_file_discrim = 'my_model_weights_discriminator.h5'
다양한 프레임워크에 대한 신경 대화 모델의 현재 구현에 대한 좋은 개요(일부 결과 포함)는 여기에서 찾을 수 있습니다.
우리 모델은 텍스트 요약과 같은 다른 NLP 작업에 적용될 수 있습니다(예: 대안 2: 재귀 모델 A 참조). 우리는 우리 모델을 다른 작업에 적용하는 것을 권장합니다. 이 경우 가능한 한 우리 작업을 인용해 주시기 바랍니다. 2017년 7월에 등록된 이 문서에서 볼 수 있습니다.
이러한 코드는 Ubuntu 14.04.3 LTS, Python 2.7.6, Theano 0.9.0 및 Keras 2.0.4에서 실행될 수 있습니다. 다른 구성을 사용하려면 약간의 조정이 필요할 수 있습니다.


