MoEL
1.0.0


이것은 논문의 PyTorch 구현입니다:
MoEL: 공감하는 청취자의 혼합 . Zhaojiang Lin , Andrea Madotto, Jamin Shin, Peng Xu, Pascale Fung EMNLP 2019 [PDF]
이 코드는 PyTorch >= 0.4.1을 사용하여 작성되었습니다. 이 툴킷에 포함된 소스 코드나 데이터세트를 작업에 사용하는 경우 다음 논문을 인용해 주세요. Bibtex는 다음과 같습니다.
@article{lin2019moel,
title={MoEL: 공감하는 청취자들의 혼합},
작성자={Lin, Zhaojiang 및 Madotto, Andrea 및 Shin, Jamin 및 Xu, Peng 및 Fung, Pascale},
저널={arXiv 사전 인쇄 arXiv:1908.07687},
연도={2019}
}
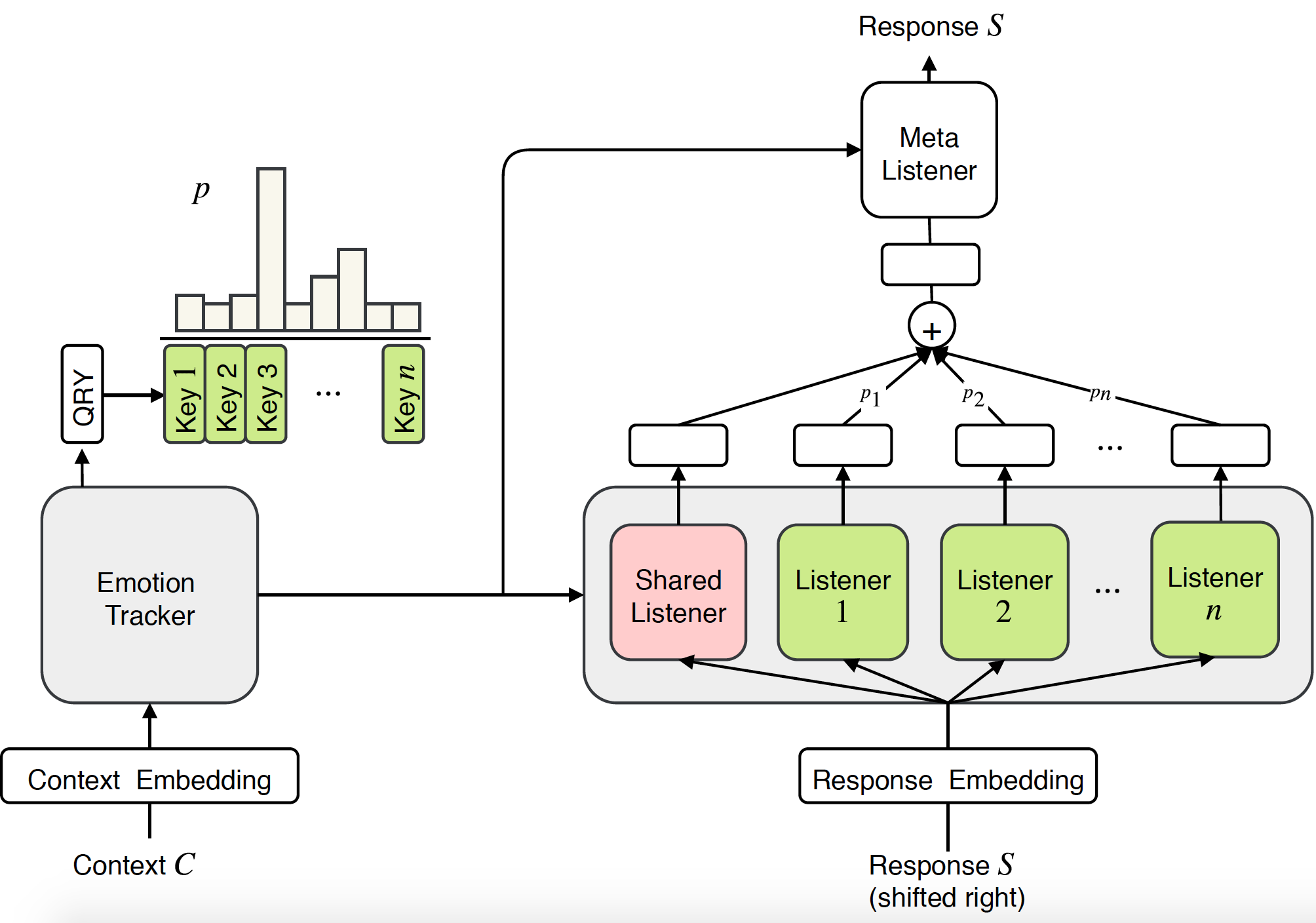
공감 대화 시스템에 대한 이전 연구는 주로 특정 감정에 대한 반응을 생성하는 데 중점을 두었습니다. 그러나 공감을 위해서는 감정적인 반응을 일으키는 능력도 필요하지만, 더 중요한 것은 사용자의 감정을 이해하고 적절하게 대응하는 능력도 필요합니다. 본 논문에서는 대화 시스템에서 공감을 모델링하기 위한 새로운 엔드투엔드 접근 방식인 MoEL(Mixture of Empathetic Listeners)을 제안합니다. 우리 모델은 먼저 사용자 감정을 포착하고 감정 분포를 출력합니다. 이를 기반으로 MoEL은 각각 특정 감정에 반응하도록 최적화된 적절한 Listener(들)의 출력 상태를 부드럽게 결합하고 공감적인 반응을 생성합니다. 공감 대화 데이터 세트에 대한 인간의 평가는 MoEL이 공감, 관련성 및 유창성 측면에서 다중 작업 훈련 기준을 능가한다는 것을 확인합니다. 또한, 다양한 청취자의 생성된 응답에 대한 사례 연구는 우리 모델의 높은 해석 가능성을 보여줍니다.
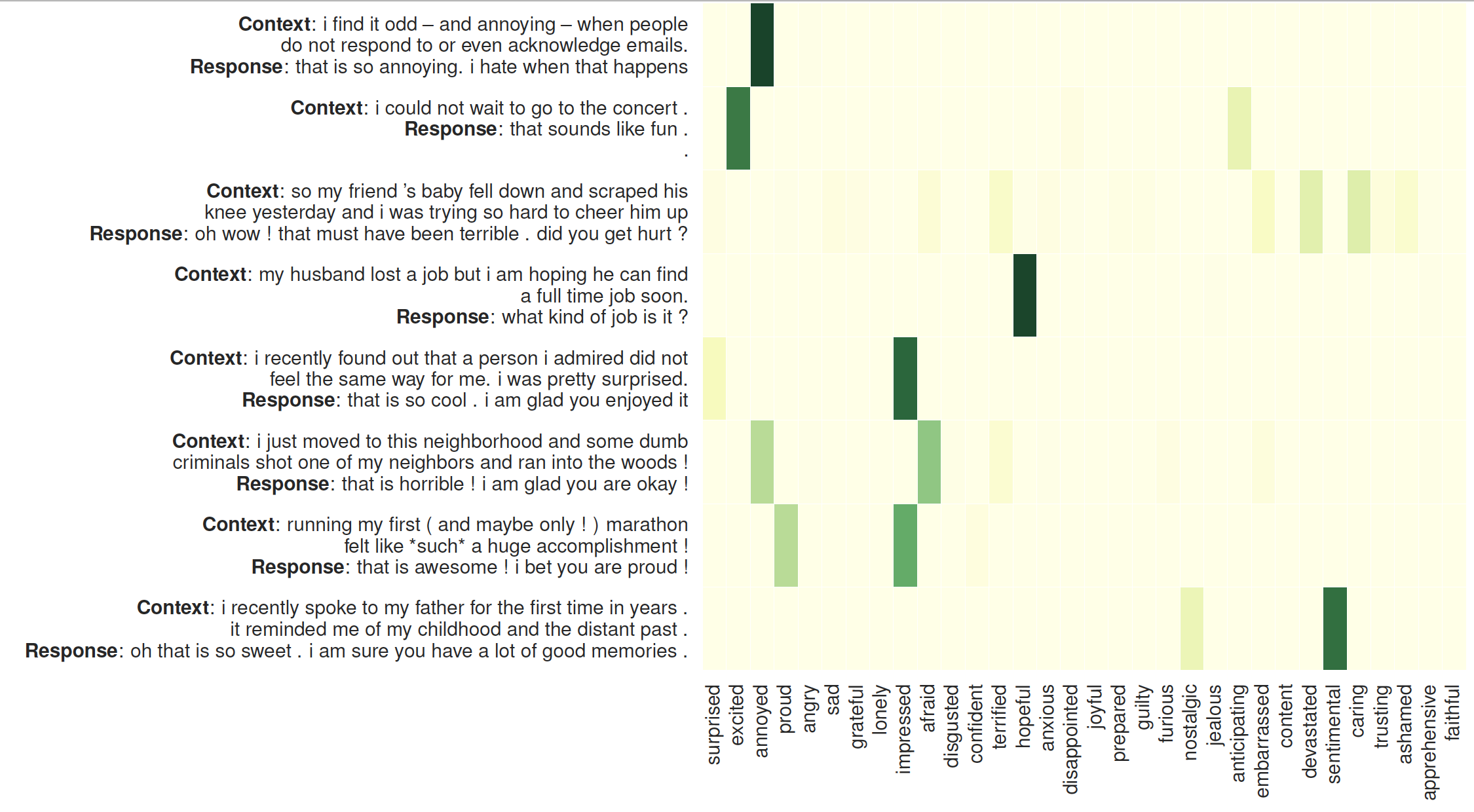
청취자에 대한 관심의 시각화: 왼쪽은 MoEL에서 생성된 응답이 뒤따르는 컨텍스트입니다. 히트맵은 32명의 청취자에 대한 주의 가중치를 보여줍니다.
필요한 패키지를 확인하거나 간단히 명령을 실행하세요.
❱❱❱ pip install -r requirements.txt사전 훈련된 장갑 임베딩 : /Vectors/ 폴더 내부에 장갑.6B.300d.txt가 있습니다 .
빠른 결과
학습을 건너뛰려면 Generation_result.txt 를 확인하세요.
데이터세트
데이터 세트(공감-대화)는 전처리되어 npy 형식으로 저장됩니다: sys_dialog_texts.train.npy, sys_target_texts.train.npy, sys_emotion_texts.train.npy는 컨텍스트(소스), 응답(타겟) 및 감정 레이블의 병렬 목록으로 구성됩니다. (추가 라벨).
교육 및 테스트
모엘
❱❱❱ python3 main.py --model experts --label_smoothing --noam --emb_dim 300 --hidden_dim 300 --hop 1 --heads 2 --topk 5 --cuda --pretrain_emb --softmax --basic_learner --schedule 10000 --save_path save/moel/
변압기 기준선
❱❱❱ python3 main.py --model trs --label_smoothing --noam --emb_dim 300 --hidden_dim 300 --hop 2 --heads 2 --cuda --pretrain_emb --save_path save/trs/
멀티태스킹 변환기 기준
❱❱❱ python3 main.py --model trs --label_smoothing --noam --emb_dim 300 --hidden_dim 300 --hop 2 --heads 2 --cuda --pretrain_emb --multitask --save_path save/multi-trs/


