MELD
1.0.0
IQ 테스트 LLM에 관심이 있다면 새로운 작업인 AlgoPuzzleVQA를 확인하세요.
Resnet을 사용하여 추출한 시각적 기능을 공개했습니다 - https://github.com/declare-lab/MM-Align
업데이트된 기준을 보려면 다음 링크를 방문하세요: Conv-Emotion
데이터를 다운로드하려면 wget을 사용하세요: wget http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz
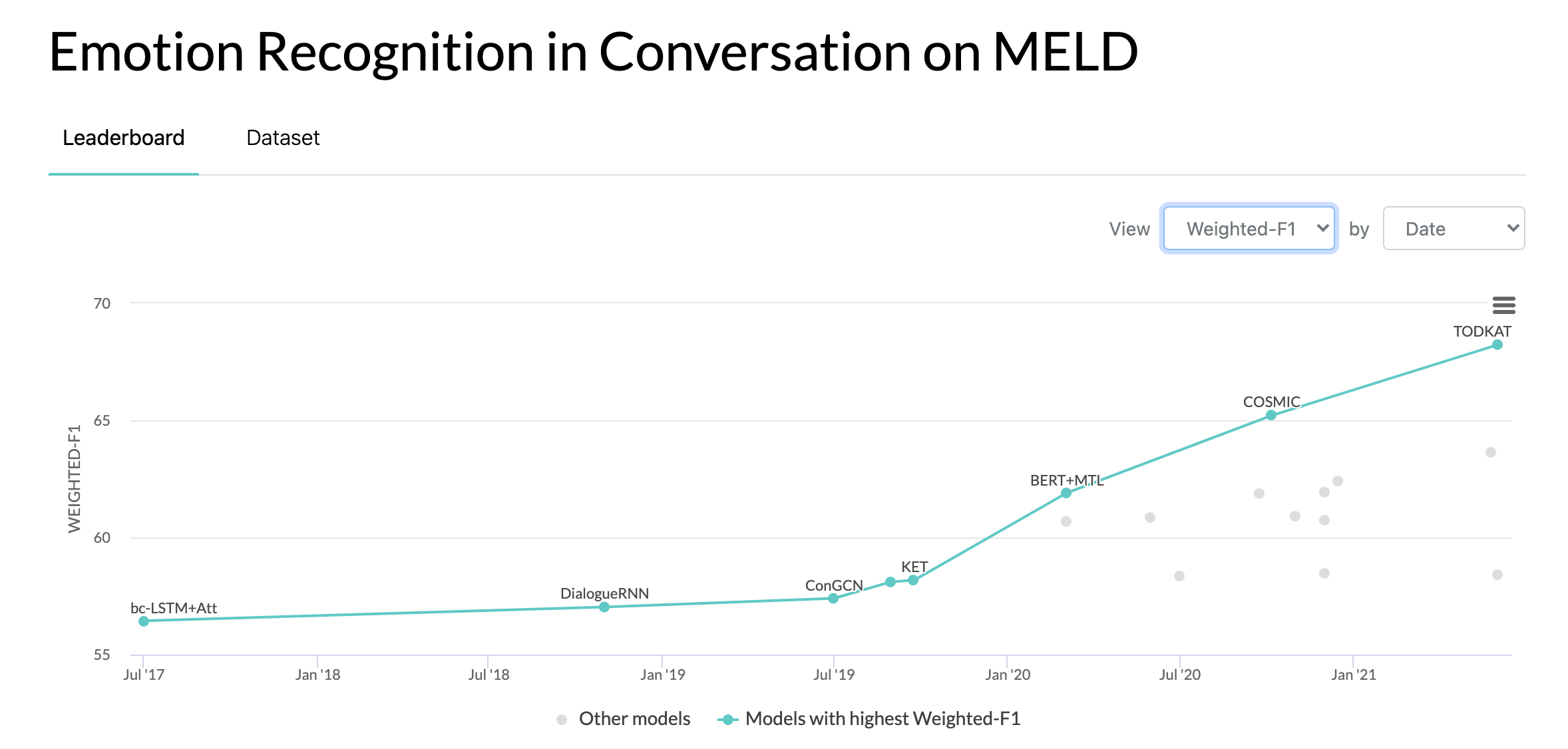
2020년 10월 10일: MELD 데이터 세트에 대한 대화의 감정 인식에 관한 새로운 논문 및 SOTA. 코드는 COSMIC 디렉토리를 참조하세요. 논문 읽기 - COSMIC: 대화에서 eMotion 식별을 위한 COMmonSense 지식.
2019년 5월 22일: MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversation이 ACL 2019에서 전체 논문으로 승인되었습니다. 업데이트된 논문은 여기(https://arxiv.org/pdf/1810.02508)에서 확인할 수 있습니다. PDF
2019년 5월 22일: Dyadic MELD가 출시되었습니다. 이는 이중 대화 모델을 테스트하는 데 사용할 수 있습니다.
2018년 11월 15일: train.tar.gz의 문제가 수정되었습니다.
Zhang, Yazhou, Qiuchi Li, Dawei Song, Peng Zhang 및 Panpan Wang. "대화 감정 분석을 위한 양자 기반 대화형 네트워크." IJCAI 2019.
Zhang, Dong, Liangqing Wu, Changlong Sun, Shoushan Li, Qiaoming Zhu 및 Guodong Zhou. "다중 화자 대화에서 감정 감지를 위한 상황 및 화자 감지 의존성을 모두 모델링합니다." IJCAI 2019.
Ghosal, Deepanway, Navonil Majumder, Soujanya Poria, Niyati Chhaya 및 Alexander Gelbukh. "DialogueGCN: 대화에서 감정 인식을 위한 그래프 컨볼루셔널 신경망." EMNLP 2019.
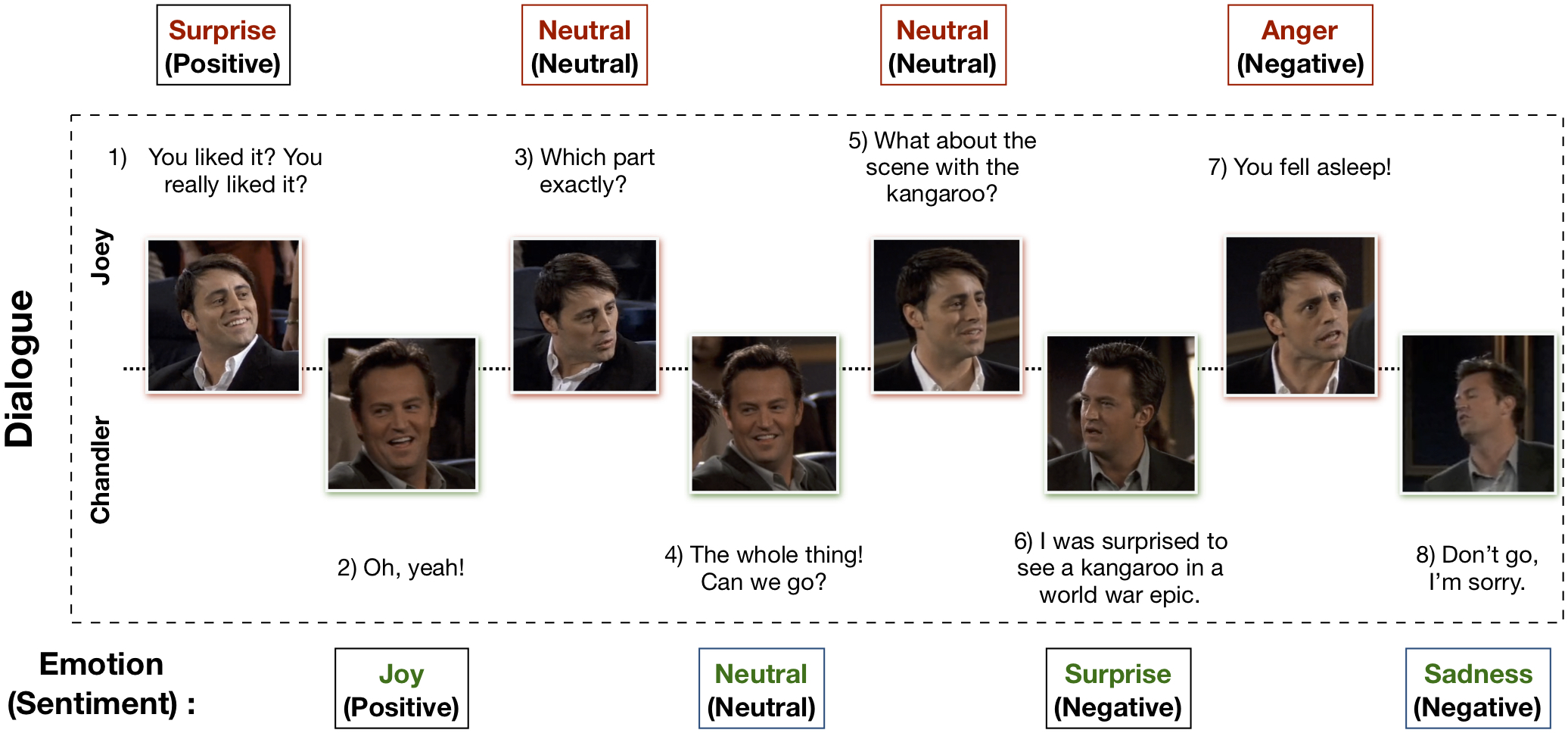
MELD(Multimodal EmotionLines 데이터 세트)는 EmotionLines 데이터 세트를 강화하고 확장하여 생성되었습니다. MELD에는 EmotionLines에서 사용할 수 있는 동일한 대화 인스턴스가 포함되어 있지만 텍스트와 함께 오디오 및 시각적 양식도 포함됩니다. MELD에는 Friends TV 시리즈의 1400개 이상의 대화와 13000개 이상의 발언이 있습니다. 여러 연사가 대화에 참여했습니다. 대화의 각 발화에는 분노, 혐오, 슬픔, 기쁨, 중립, 놀라움, 두려움 등 7가지 감정 중 하나로 표시되어 있습니다. MELD에는 각 발화에 대한 감정(긍정적, 부정적 및 중립적) 주석도 있습니다.
| 통계 | 기차 | 데브 | 시험 |
|---|---|---|---|
| # 양식 | {a,v,t} | {a,v,t} | {a,v,t} |
| # 고유 단어 수 | 10,643 | 2,384 | 4,361 |
| 평균 발화 길이 | 8.03 | 7.99 | 8.28 |
| 최대. 발화 길이 | 69 | 37 | 45 |
| 평균 대화당 감정 수 | 3.30 | 3.35 | 3.24 |
| 대화 수 | 1039 | 114 | 280 |
| 발언 수 | 9989 | 1109 | 2610 |
| 스피커 수 | 260 | 47 | 100 |
| # 감정변화 | 4003 | 427 | 1003 |
| 평균 발언의 지속 시간 | 3.59초 | 3.59초 | 3.58초 |
자세한 내용은 https://affective-meld.github.io를 방문하세요.
| 기차 | 데브 | 시험 | |
|---|---|---|---|
| 화 | 1109 | 153 | 345 |
| 싫음 | 271 | 22 | 68 |
| 두려움 | 268 | 40 | 50 |
| 기쁨 | 1743년 | 163 | 402 |
| 중립적 | 4710 | 470 | 1256 |
| 비애 | 683 | 111 | 208 |
| 놀라다 | 1205 | 150 | 281 |
다중 모드 데이터 분석은 의사 결정을 위해 다중 병렬 데이터 채널의 정보를 활용합니다. AI의 급속한 성장과 함께 다중 모드 감정 인식은 주로 대화 생성, 다중 모드 상호 작용 등과 같은 많은 도전적인 작업에 대한 잠재적인 응용으로 인해 주요 연구 관심을 얻었습니다. 대화형 감정 인식 시스템은 다음과 같은 적절한 응답을 생성하는 데 사용될 수 있습니다. 사용자 감정을 분석합니다. 다중 모드 감정 인식에 대해 수행된 수많은 작업이 있지만 실제로 대화에서 감정을 이해하는 데 초점을 맞춘 작업은 극소수에 불과합니다. 그러나 이들의 작업은 일대일 대화 이해에만 국한되므로 참가자가 2명 이상인 다자간 대화에서는 감정 인식으로 확장할 수 없습니다. EmotionLines는 시각 및 청각과 같은 다른 양식의 데이터를 포함하지 않으므로 텍스트에 대한 감정 인식을 위한 리소스로만 사용할 수 있습니다. 동시에 감정 인식 연구에 사용할 수 있는 다중 모드 다자간 대화 데이터 세트가 없다는 점에 유의해야 합니다. 이 작업에서는 다중 모드 시나리오를 위한 EmotionLines 데이터 세트를 확장, 개선 및 추가 개발했습니다. 순차적인 감정 인식에는 여러 가지 과제가 있으며 상황 이해가 그 중 하나입니다. 대화의 순서에 따른 감정 변화와 감정 흐름은 정확한 맥락 모델링을 어렵게 만듭니다. 이 데이터 세트에서는 각 대화에 대한 다중 모드 데이터 소스에 액세스할 수 있으므로 컨텍스트 모델링을 개선하여 전반적인 감정 인식 성능에 도움이 될 것이라는 가설을 세웠습니다. 이 데이터 세트는 다중 모드 정서적 대화 시스템을 개발하는 데에도 사용될 수 있습니다. IEMOCAP, SEMAINE은 각 발화에 대한 감정 레이블을 포함하는 다중 모드 대화 데이터 세트입니다. 그러나 이러한 데이터세트는 본질적으로 이중적이므로 Multimodal-EmotionLines 데이터세트의 중요성을 정당화합니다. 공개적으로 사용 가능한 다른 다중 모드 감정 및 정서 인식 데이터 세트는 MOSEI, MOSI, MOUD입니다. 그러나 이러한 데이터세트 중 어느 것도 대화형이 아닙니다.
첫 번째 단계에서는 EmotionLines 데이터세트에 있는 각 대화의 모든 발화에 대한 타임스탬프를 찾는 작업을 다룹니다. 이를 달성하기 위해 우리는 발언의 시작 및 끝 타임스탬프가 포함된 모든 에피소드의 자막 파일을 크롤링했습니다. 이 프로세스를 통해 시즌 ID, 에피소드 ID, 에피소드 내 각 발언의 타임스탬프를 얻을 수 있었습니다. 타임스탬프를 얻는 동안 두 가지 제약 조건을 적용했습니다. (a) 대화에서 발언의 타임스탬프는 오름차순이어야 하며, (b) 대화의 모든 발언은 동일한 에피소드와 장면에 속해야 합니다. 이 두 가지 조건을 제한하면 EmotionLines에서 몇 개의 대화가 여러 개의 자연스러운 대화로 구성되는 것으로 나타났습니다. 우리는 데이터 세트에서 해당 사례를 필터링했습니다. 이 오류 수정 단계로 인해 우리의 경우 EmotionLine과 비교할 때 대화 수가 다릅니다. 각 발화의 타임스탬프를 얻은 후 소스 에피소드에서 해당 시청각 클립을 추출했습니다. 별도로, 우리는 해당 비디오 클립에서 오디오 콘텐츠도 꺼냈습니다. 마지막으로 데이터 세트에는 각 대화에 대한 시각적, 오디오 및 텍스트 양식이 포함되어 있습니다.
이 데이터 세트를 설명하는 논문은 https://arxiv.org/pdf/1810.02508.pdf에서 찾을 수 있습니다.
원시 데이터를 다운로드하려면 http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz를 방문하세요. 데이터는 .mp4 형식으로 저장되며 XXX.tar.gz 파일에서 찾을 수 있습니다. 주석은 https://github.com/declare-lab/MELD/tree/master/data/MELD에서 찾을 수 있습니다.
| 열 이름 | 설명 |
|---|---|
| 아니 씨. | 서로 다른 버전이 있거나 서로 다른 하위 집합이 있는 여러 복사본이 있는 경우 주로 발화를 참조하기 위한 발화의 일련 번호 |
| 말 | EmotionLines의 개별 발화를 문자열로 표시합니다. |
| 스피커 | 발화와 관련된 화자의 이름입니다. |
| 감정 | 발화에서 화자가 표현하는 감정(중립, 기쁨, 슬픔, 분노, 놀람, 두려움, 혐오)입니다. |
| 감정 | 발화에서 화자가 표현한 정서(긍정적, 중립적, 부정적)입니다. |
| 대화_ID | 0부터 시작하는 대화의 인덱스입니다. |
| 발화_ID | 0부터 시작하는 대화의 특정 발언의 인덱스입니다. |
| 계절 | 시즌 번호. 특정 발언이 속한 프렌즈 TV 쇼의 |
| 삽화 | 에피소드 번호. 해당 발언이 속한 특정 시즌의 프렌즈 TV 쇼. |
| 시작시간 | 'hh:mm:ss,ms' 형식으로 지정된 에피소드의 발언 시작 시간입니다. |
| 종료 시간 | 'hh:mm:ss,ms' 형식으로 지정된 에피소드의 발화 종료 시간입니다. |
기준 모델 훈련에 사용되는 데이터와 기능으로 구성된 13개의 피클 파일이 있습니다. 다음은 각 피클 파일에 대한 간략한 설명입니다.
import pickle
data , W , vocab , word_idx_map , max_sentence_length , label_index = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_avg_emb , val_text_avg_emb , test_text_avg_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_CNN_emb , val_text_CNN_emb , test_text_CNN_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_emb , val_text_emb , test_text_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_bimodal_emb , val_bimodal_emb , test_bimodal_emb = pickle . load ( open ( filepath , 'rb' ))'./utils/'에는 2개의 Python 스크립트가 제공됩니다.
실험을 위해 모든 레이블은 원-핫 인코딩으로 표시되며 해당 인덱스는 다음과 같습니다.
감정 분류 기준으로는 다음과 같은 등급 가중치를 사용하였다. 인덱싱은 위에서 언급한 것과 동일합니다. 클래스 가중치: [4.0, 15.0, 15.0, 3.0, 1.0, 6.0, 3.0].
기준선을 실행하려면 다음 단계를 따르십시오.
./data/pickles/ 에 복사하세요.baseline/baseline.py 파일을 실행하십시오.python baseline.py -classify [Sentiment|Emotion] -modality [text|audio|bimodal] [-train|-test]python baseline.py -classify Sentiment -modality text -trainpython baseline.py -h 사용하세요../data/models/ 안에 배치하세요. 이 데이터세트가 연구에 유용하다고 생각되면 다음 논문을 인용해 주세요.
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, R. Mihalcea. MELD: 대화 중 감정 인식을 위한 다중 모드 다자간 데이터 세트. ACL 2019.
Chen, SY, Hsu, CC, Kuo, CC 및 Ku, LW EmotionLines: 다자간 대화의 감정 코퍼스. arXiv 사전 인쇄 arXiv:1802.08379 (2018).
다중 모드 EmoryNLP 감정 감지 데이터 세트는 EmoryNLP 감정 감지 데이터 세트를 강화하고 확장하여 생성되었습니다. 여기에는 EmoryNLP 감정 감지 데이터 세트에서 사용할 수 있는 것과 동일한 대화 인스턴스가 포함되어 있지만 텍스트와 함께 오디오 및 시각적 양식도 포함됩니다. 멀티모달 EmoryNLP 데이터세트에는 Friends TV 시리즈의 800개 이상의 대화와 9000개 이상의 발화가 존재합니다. 여러 연사가 대화에 참여했습니다. 대화의 각 발화에는 중립, 기쁨, 평화, 강력, 무서움, 분노, 슬픔 등 7가지 감정 중 하나로 표시되어 있습니다. 주석은 원본 데이터세트에서 빌려왔습니다.
| 통계 | 기차 | 데브 | 시험 |
|---|---|---|---|
| # 양식 | {a,v,t} | {a,v,t} | {a,v,t} |
| # 고유 단어 수 | 9,744 | 2,123 | 2,345 |
| 평균 발화 길이 | 7.86 | 6.97 | 7.79 |
| 최대. 발화 길이 | 78 | 60 | 61 |
| 평균 장면당 감정 수 | 4.10 | 4.00 | 4.40 |
| 대화 수 | 659 | 89 | 79 |
| 발언 수 | 7551 | 954 | 984 |
| 스피커 수 | 250 | 46 | 48 |
| # 감정변화 | 4596 | 575 | 653 |
| 평균 발언의 지속 시간 | 5.55초 | 5.46초 | 5.27초 |
| 기차 | 데브 | 시험 | |
|---|---|---|---|
| 즐거운 | 1677년 | 205 | 217 |
| 미친 | 785 | 97 | 86 |
| 중립적 | 2485 | 322 | 288 |
| 평화로운 | 638 | 82 | 111 |
| 강한 | 551 | 70 | 96 |
| 슬픈 | 474 | 51 | 70 |
| 무서운 | 941 | 127 | 116 |
이 데이터 세트의 비디오 클립은 이 링크에서 다운로드할 수 있습니다. 주석 파일은 https://github.com/SenticNet/MELD/tree/master/data/emorynlp에서 찾을 수 있습니다. 3개의 .csv 파일이 있습니다. 이러한 csv 파일의 첫 번째 열에 있는 각 항목에는 여기에서 찾을 수 있는 해당 비디오 클립의 발언이 포함되어 있습니다. 각 발언과 해당 비디오 클립은 시즌 번호, 에피소드 번호, 장면 ID 및 발언 ID로 색인화됩니다. 예를 들어, sea1_ep2_sc6_utt3.mp4 는 클립이 시즌 번호가 있는 발화에 해당함을 의미합니다. 1, 에피소드 번호. 2, scene_id 6 및 utterance_id 3. 장면은 단순히 대화입니다. 이 인덱싱은 원본 데이터세트와 일치합니다. .csv 파일과 비디오 파일은 원본 데이터 세트에 따라 학습, 검증 및 테스트 세트로 구분됩니다. 주석은 원본 EmoryNLP 데이터세트(Zahiri et al.(2018))에서 직접 차용되었습니다.
| 열 이름 | 설명 |
|---|---|
| 말 | EmoryNLP의 개별 발화(문자열)입니다. |
| 스피커 | 발화와 관련된 화자의 이름입니다. |
| 감정 | 발화에서 화자가 표현하는 감정(중립, 기쁨, 평화, 강력, 무서움, 분노, 슬픔)입니다. |
| 장면_ID | 0부터 시작하는 대화의 인덱스입니다. |
| 발화_ID | 0부터 시작하는 대화의 특정 발언의 인덱스입니다. |
| 계절 | 시즌 번호. 특정 발언이 속한 프렌즈 TV 쇼의 |
| 삽화 | 에피소드 번호. 해당 발언이 속한 특정 시즌의 프렌즈 TV 쇼. |
| 시작시간 | 'hh:mm:ss,ms' 형식으로 지정된 에피소드의 발언 시작 시간입니다. |
| 종료 시간 | 해당 에피소드의 발화 종료 시간('hh:mm:ss,ms' 형식)입니다. |
참고 : 자막 불일치로 인해 시작 및 종료 시간을 찾을 수 없는 몇 가지 발화가 있습니다. 이러한 발화는 데이터 세트에서 생략되었습니다. 그러나 우리는 사용자가 원본 데이터 세트에서 해당 발화를 찾고 이에 대한 비디오 클립을 생성하도록 권장합니다.
이 데이터세트가 연구에 유용하다고 생각되면 다음 논문을 인용해 주세요.
S. 자히리(S. Zahiri)와 JD 최. 시퀀스 기반 컨볼루셔널 신경망을 사용한 TV 쇼 대본의 감정 탐지. 감성 콘텐츠 분석에 관한 AAAI 워크숍, AFFCON'18, 2018.
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, R. Mihalcea. MELD: 대화 중 감정 인식을 위한 다중 모드 다자간 데이터 세트. ACL 2019.


