gutenberg dialog
1.0.0
Gutenberg Dialog Dataset의 자신만의 버전을 다운로드하고 구축하기 위한 코드입니다. 새로운 언어로 쉽게 확장 가능합니다. https://ricsinaruto.github.io/chatbot.html에서 다양한 언어로 훈련된 챗봇을 사용해 보세요.
| 다운로드 링크 | 발화 수 | 평균 발화 길이 | 대화 수 | 평균 대화 길이 |
|---|---|---|---|---|
| 영어 | 14 773 741 | 22.17 | 2 526 877 | 5.85 |
| 독일 사람 | 226015 | 24.44 | 43440 | 5.20 |
| 네덜란드 사람 | 129 471 | 24.26 | 23541 | 5.50 |
| 스페인 사람 | 58174 | 18.62 | 6912 | 8.42 |
| 이탈리아 사람 | 41 388 | 19.47 | 6 664 | 6.21 |
| 헝가리 인 | 18816 | 14.68 | 2 826 | 6.66 |
| 포르투갈 인 | 16228 | 21.40 | 2 233 | 7.27 |
? 데이터세트의 크기-품질 균형에 영향을 미치는 매개변수를 조정하여 자체 데이터세트를 생성합니다.
모듈식 인터페이스를 통해 데이터 세트를 다른 언어로 쉽게 확장할 수 있습니다.
? 데이터 세트를 구축할 때 도서를 수동으로 쉽게 제외할 수 있습니다.
필수 패키지를 설치하는 setup.py를 실행합니다.
python setup.py
기본 파일은 저장소의 루트에서 호출되어야 합니다. 아래 명령은 인수로 제공된 쉼표로 구분된 언어에 대한 데이터 세트 구축 파이프라인을 실행합니다. 현재 영어, 독일어, 네덜란드어, 스페인어, 포르투갈어, 이탈리아어, 헝가리어가 지원됩니다.
python code/main.py -l=en,de,nl,es,pt,it,hu -a
설정 가능한 모든 인수는 아래에서 볼 수 있습니다. 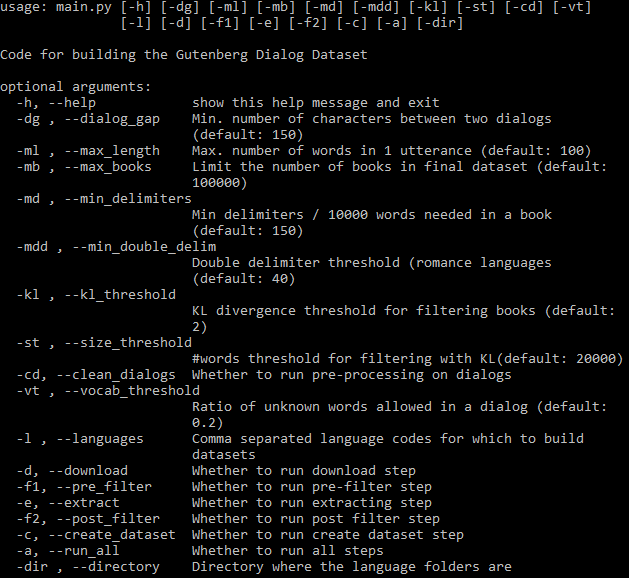
-a 플래그는 전체 파이프라인을 자동으로 실행할지 여부를 제어합니다. -a가 생략되면 플래그를 사용하여 단계의 하위 집합을 지정해야 합니다(위 도움말 참조). 단계가 완료되면 해당 출력은 후속 단계에서 사용될 수 있으며 해당 단계와 관련된 매개변수 또는 코드가 변경된 경우에만 다시 실행됩니다. 모든 단계는 각 언어에 대해 별도로 실행됩니다.
특정 언어에 대한 책을 다운로드하세요.
참고: "책을 다운로드할 수 없습니다."라는 오류와 함께 모든 책을 다운로드하지 못하는 경우, Gutenberg 패키지에서 사용하는 기본 미러에 액세스할 수 없기 때문일 수 있습니다. 이런 일이 발생하는 경우 GUTENBERG_MIRROR 환경 변수를 통해 https://www.gutenberg.org/MIRRORS.ALL에 나열된 대체 미러 중 하나를 사용할 수 있습니다. 예를 들어:
export GUTENBERG_MIRROR="https://gutenberg.pglaf.org"
python code/main.py ...
사전 필터링을 통해 일부 오래된 책과 노이즈가 제거됩니다.
대화는 책에서 추출됩니다. 데이터세트를 새로운 언어로 확장하는 경우(아래 섹션 참조) 이 단계를 수정할 수 있으므로 완료되면 이전 단계를 건너뛸 수 있습니다.
어휘를 기반으로 일부 대화를 제거하는 두 번째 필터링 단계입니다.
최종 데이터세트를 모아 학습/개발/테스트 데이터로 분할합니다. 마지막 단계에서는 최종 데이터세트를 추출하는 데 사용된 모든 책(제목 및 저자 포함)이 포함된 출력 디렉터리에 author_and_title.txt 파일을 생성합니다. 사용자는 이 파일의 줄을 데이터 세트에서 허용해서는 안 되는 책에 해당하는 banned_books.txt 에 수동으로 복사할 수 있습니다. 이후 단계 실행 시 이 파일의 도서는 고려되지 않습니다.
코드는 쉽게 확장되어 다른 언어를 처리할 수 있습니다. 언어 폴더에 <언어 코드>.py라는 파일을 생성해야 합니다. 여기서는 LANG 또는 다른 하위 클래스를 상위 클래스로 사용하여 대문자 언어 코드(예: 영어의 경우 En )라는 이름의 클래스를 정의해야 합니다. self.cfg를 사용하면 구성 매개변수에 액세스할 수 있습니다. 이 클래스 내에는 아래 3가지 함수가 정의되어야 합니다. 예를 보려면 it.py를 참조하세요.
언어통계
이 함수는 키가 잠재적인 구분 기호인 사전을 반환해야 합니다. 각 구분 기호에 대해 한 줄을 입력으로 받아 숫자를 반환하는 함수(사전의 값)를 정의해야 합니다. 예를 들어 이 숫자는 구분 기호 수, 줄에 구분 기호가 있는지 여부에 대한 플래그 등이 될 수 있습니다. 일반적으로 다양한 구분 기호의 중요성에 따라 가중치를 적용한 개수를 사용하는 것이 좋습니다. 값은 각 책에서 사용해야 하는 구분 기호를 결정하고(아래 함수에 전달됨) 구분 기호가 적은 책을 필터링하는 데 사용됩니다. en.py에는 여러 구분 기호의 예가 포함되어 있습니다.
이 함수는 책에서 대화를 추출하여 대화 목록인 self.dialogs 에 추가해야 하며, 각 대화는 연속 발언 목록입니다. Paragraph_list 에는 책이 연속된 단락 목록으로 포함되어 있습니다. delimiter는 대화 상자를 추출하는 데 사용되는 이 파일에서 가장 일반적인 구분 기호입니다.
이 기능은 후처리 대화상자(예: 특정 문자 제거)에 사용됩니다. 발화를 입력으로 사용합니다. nltk 단어 토큰화는 자동으로 실행됩니다.
이 프로젝트는 MIT 라이선스에 따라 라이선스가 부여됩니다. 자세한 내용은 LICENSE 파일을 참조하세요.
작업에 데이터세트나 코드를 사용하고 다음 논문 인용을 고려하는 경우 이 저장소에 대한 링크를 포함하세요.
@inproceedings{Csaky:2021,
title = "The Gutenberg Dialogue Dataset",
author = "Cs{'a}ky, Rich{'a}rd and Recski, G{'a}bor",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics",
month = apr,
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2004.12752",
}


