Seq2seqChatbots
1.0.0
신경 챗봇을 위한 데이터를 유연하게 훈련, 상호 작용 및 생성하기 위한 tensor2tensor 주변의 래퍼입니다.
위키에는 신경 대화 모델링과 관련된 150개 이상의 최근 출판물에 대한 내 메모와 요약이 포함되어 있습니다.
? 자체 학습을 실행하거나 사전 학습된 모델을 실험해 보세요.
✅ tensor2tensor와 통합된 4가지 대화 데이터세트
? tensor2tensor에 설정된 모든 모델이나 하이퍼파라미터와 원활하게 작동합니다.
대화 상자 문제에 대해 쉽게 확장 가능한 기본 클래스
필수 패키지를 설치하고 추가 데이터를 다운로드하는 과정을 안내하는 setup.py를 실행합니다.
python setup.py
여기에서 이 백서에 사용된 모든 훈련된 모델을 다운로드할 수 있습니다. 각 훈련에는 2개의 체크포인트가 포함되어 있습니다. 하나는 검증 손실 최소값에 대한 것이고 다른 하나는 150 epoch 이후에 대한 것입니다. 데이터와 교육 폴더 구조는 서로 정확히 일치합니다.
python t2t_csaky/main.py --mode=train
모드 인수는 {generate_data, train, decode, Experiment} 4개 중 하나일 수 있습니다. 실험 모드에서는 실행 파일의 실험 기능 내에서 수행할 작업을 지정할 수 있습니다. 각 모드의 기능에 대한 자세한 설명은 아래에 나와 있습니다.
이 파일에서 직접 각 모드의 플래그와 매개변수를 제어할 수 있습니다. 시작하는 각 실행에 대해 이 파일이 적절한 디렉터리에 복사되므로 모든 실행의 매개변수에 빠르게 액세스할 수 있습니다. 모든 모드에 대해 설정해야 하는 몇 가지 플래그가 있습니다(구성 파일의 FLAGS 사전).
t2t_usr_dir : 내 코드가 있는 디렉터리의 경로입니다. 디렉터리 이름을 바꾸지 않는 한 이를 변경할 필요가 없습니다.
data_dir : 소스 및 대상 쌍과 기타 데이터를 생성하려는 디렉터리의 경로입니다. 데이터 세트는 이 디렉터리에서 한 수준 높은 raw_data 폴더로 다운로드됩니다.
문제 : tensor2tensor가 필요로 하는 등록된 문제의 이름입니다. 아래 generate_data 섹션에 자세히 설명되어 있습니다. 모든 경로는 저장소의 루트에서 시작되어야 합니다.
이 모드는 데이터를 다운로드 및 전처리하고 소스 및 대상 쌍을 생성합니다. 현재 tensor2tensor에서 제공하는 문제 외에 사용할 수 있는 문제가 6개 등록되어 있습니다.
persona_chat_chatbot : 이 문제는 페르소나를 사용하지 않고 페르소나-채팅 데이터세트를 구현합니다.
daily_dialog_chatbot : 이 문제는 DailyDialog 데이터세트를 구현합니다(주제, 대화 행위 또는 감정을 사용하지 않음).
opensubtitles_chatbot : 이 문제는 OpenSubtitles 데이터세트 작업에 사용될 수 있습니다.
cornell_chatbot_basic : 이 문제는 Cornell Movie-Dialog Corpus를 구현합니다.
cornell_chatbot_separate_names : 이 문제는 동일한 Cornell 코퍼스를 사용하지만 각 발화의 화자와 수신자의 이름이 추가되어 아래와 같은 소스 발화가 생성됩니다.
BIANCA_m0 무슨 좋은 거요? CAMERON_m0
Character_chatbot : 이것은 모든 데이터 세트에서 작동하는 일반적인 문자 기반 문제입니다. 이를 사용하기 전에 위의 문제로 인해 생성된 .txt 파일을 데이터 디렉터리에 배치해야 하며, 그 후에는 이 문제를 사용하여 tensor2tensor 문자 기반 데이터 파일을 생성할 수 있습니다.
구성 파일의 PROBLEM_HPARAMS 사전에는 데이터를 생성하기 전에 설정할 수 있는 문제별 매개변수가 포함되어 있습니다.
num_train_shards / num_dev_shards : 생성된 열차 또는 개발 데이터를 여러 파일에 걸쳐 분할하려는 경우.
vocabulary_size : 문제에 사용하려는 어휘의 크기입니다. 이 어휘 밖의 단어는 토큰으로 대체됩니다.
Dataset_size : 전체 데이터 세트(0으로 정의)를 사용하지 않으려는 경우 발화 쌍의 수입니다.
Dataset_split : 문제에 대한 열차-발-테스트 분할을 지정합니다.
Dataset_version : 이는 opensubtitles 데이터세트에만 관련됩니다. 이 데이터세트에는 여러 버전이 있으므로 다운로드하려는 데이터세트의 연도를 지정할 수 있습니다.
name_vocab_size : 이는 별도의 이름이 있는 코넬 문제에만 관련됩니다. 페르소나만 포함하는 어휘의 크기를 설정할 수 있습니다.
이 모드를 사용하면 지정된 문제와 하이퍼파라미터를 사용하여 모델을 교육할 수 있습니다. 코드는 tensor2tensor 훈련 스크립트를 호출하므로 tensor2tensor에 있는 모든 모델을 사용할 수 있습니다. 이 외에도 약간 수정된 하위 클래스 모델도 있습니다.
gradient_checkpointed_seq2seq : 자체 hparams를 완전히 사용할 수 있도록 lstm 기반 seq2seq 모델을 약간 수정했습니다. 소프트맥스를 계산하기 전에 LSTM 숨겨진 단위는 여기에서와 같이 2048 선형 단위로 투영됩니다. 마지막으로 이 모델에 그래디언트 체크포인트를 구현해 보려고 했으나, 현재는 좋은 결과를 얻지 못해 제외했습니다.
구성 파일의 FLAGS 사전에 훈련 실행을 위해 지정할 수 있는 몇 가지 추가 플래그가 있으며 그 중 일부는 다음과 같습니다.
train_dir : 훈련 체크포인트 파일이 저장될 디렉터리의 이름입니다.
model : 모델 이름: 위 모델 중 하나이거나 tensor2tensor 정의 모델입니다.
hparams : 등록된 hparams_set를 지정하거나, 구성 파일에서 hparams를 정의하려면 비워 두세요. seq2seq 또는 변환기 모델에 대해 hparams를 지정하려면 구성 파일에서 SEQ2SEQ_HPARAMS 및 TRANSFORMER_HPARAMS 사전을 사용할 수 있습니다(자세한 내용은 확인하세요).
이 모드를 사용하면 훈련된 모델에서 디코딩할 수 있습니다. 다음 매개변수는 디코딩에 영향을 미칩니다(구성 파일의 FLAGS 사전에 있음).
decode_mode : 명령줄을 사용하여 모델과 대화할 수 있는 대화형 이 가능합니다. 파일 모드를 사용하면 응답을 생성할 소스 발언이 포함된 파일을 지정할 수 있으며, 데이터 세트 모드는 제공된 검증 데이터를 무작위로 샘플링하고 응답을 출력합니다.
decode_dir : 디코딩할 파일을 제공할 수 있고 출력된 응답이 여기에 저장될 수 있는 디렉터리입니다.
input_file_name : 파일 모드에서 제공해야 하는 파일 이름( decode_dir 에 위치)
output_file_name : 출력 응답이 저장될 decode_dir 내부의 파일 이름입니다.
beam_size : 빔 검색 사용 시 빔의 크기입니다.
return_beams : False인 경우 상단 빔만 반환하고, 그렇지 않으면 beam_size 개수의 빔을 반환합니다.
다음 결과는 이 두 논문의 결과입니다.
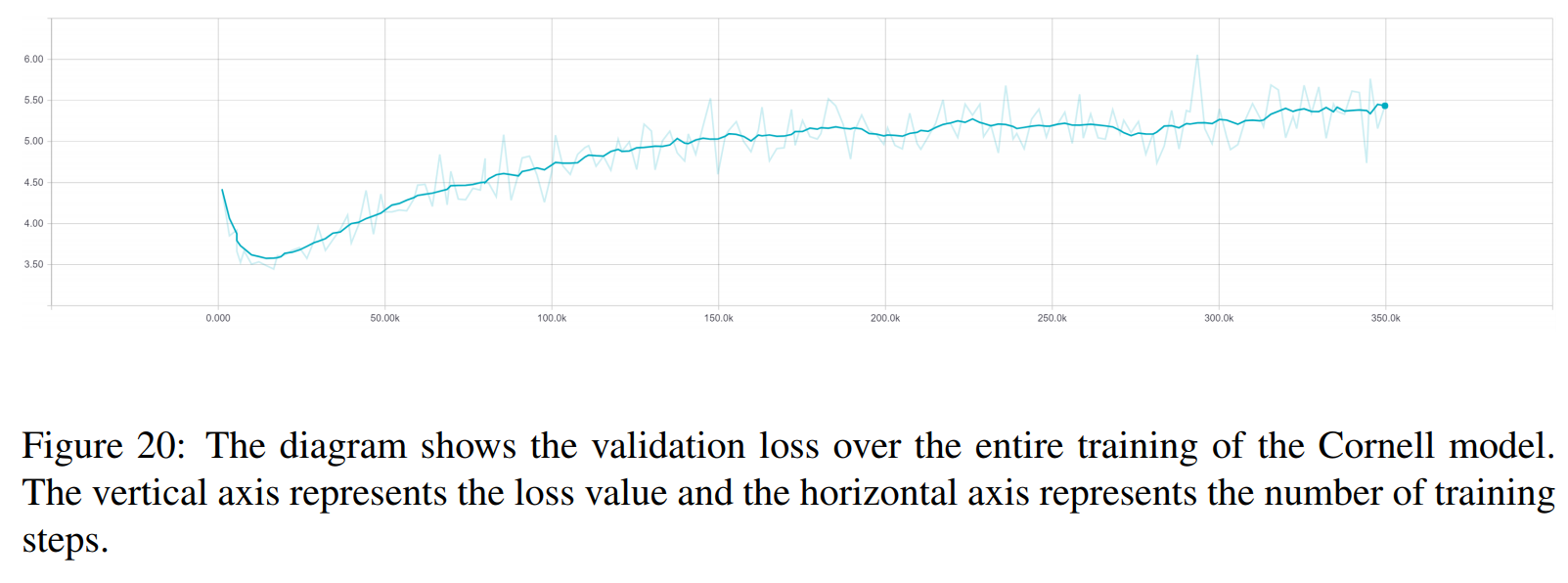

TRF는 Transformer 모델이고, RT는 훈련 세트에서 무작위로 선택된 응답을 의미하고 GT는 Ground Truth 응답을 의미합니다. 측정항목에 대한 설명은 문서를 참조하세요.
S2S는 Cornell에서 훈련된 LSTM을 갖춘 간단한 seq2seq 모델이고, 다른 것들은 Transformer 모델입니다. Opensubtitles F는 Opensubtitles에서 사전 훈련되었으며 Cornell에서 미세 조정되었습니다. 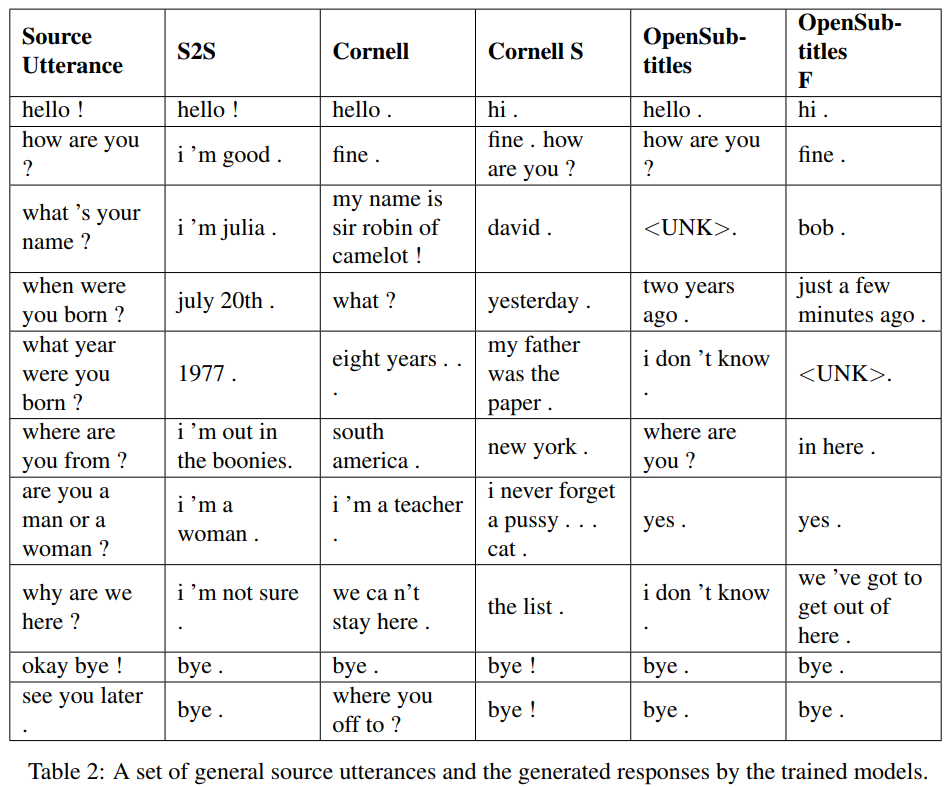
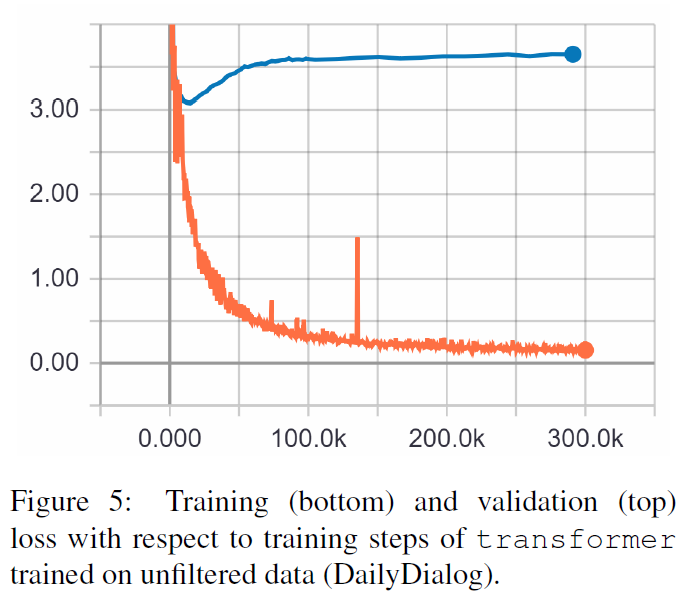

TRF는 Transformer 모델이고, RT는 훈련 세트에서 무작위로 선택된 응답을 의미하고 GT는 Ground Truth 응답을 의미합니다. 측정항목에 대한 설명은 문서를 참조하세요.
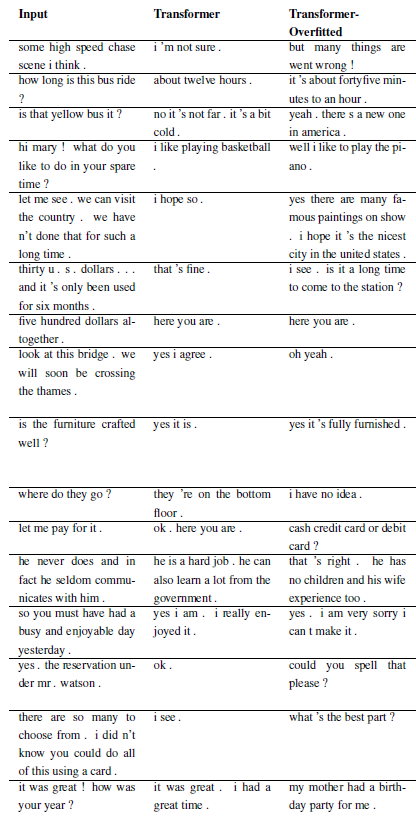
새로운 문제는 WordChatbot을 서브클래싱하여 등록할 수 있으며, CornellChatbotBasic 또는 OpensubtitleChatbot을 서브클래싱하는 것이 더 좋습니다. 몇 가지 추가 기능을 구현하기 때문입니다. 일반적으로 preprocess 및 create_data 함수를 재정의하는 것으로 충분합니다. 자세한 내용은 설명서를 확인하고 예제는 daily_dialog_chatbot을 참조하세요.
tensor2tensor 튜토리얼을 따라 새로운 모델 과 하이퍼파라미터를 추가할 수 있습니다.
Richard Csaky (코드 실행에 도움이 필요한 경우: [email protected])
이 프로젝트는 MIT 라이선스에 따라 라이선스가 부여됩니다. 자세한 내용은 LICENSE 파일을 참조하세요.
업무에 이 저장소를 사용하고 다음 논문을 인용하는 경우 이 저장소에 대한 링크를 포함하세요.
@InProceedings{Csaky:2017,
title = {Deep Learning Based Chatbot Models},
author = {Csaky, Richard},
year = {2019},
publisher={National Scientific Students' Associations Conference},
url ={https://tdk.bme.hu/VIK/DownloadPaper/asdad},
note={https://tdk.bme.hu/VIK/DownloadPaper/asdad}
} 

