Multi Modality Arena
1.0.0
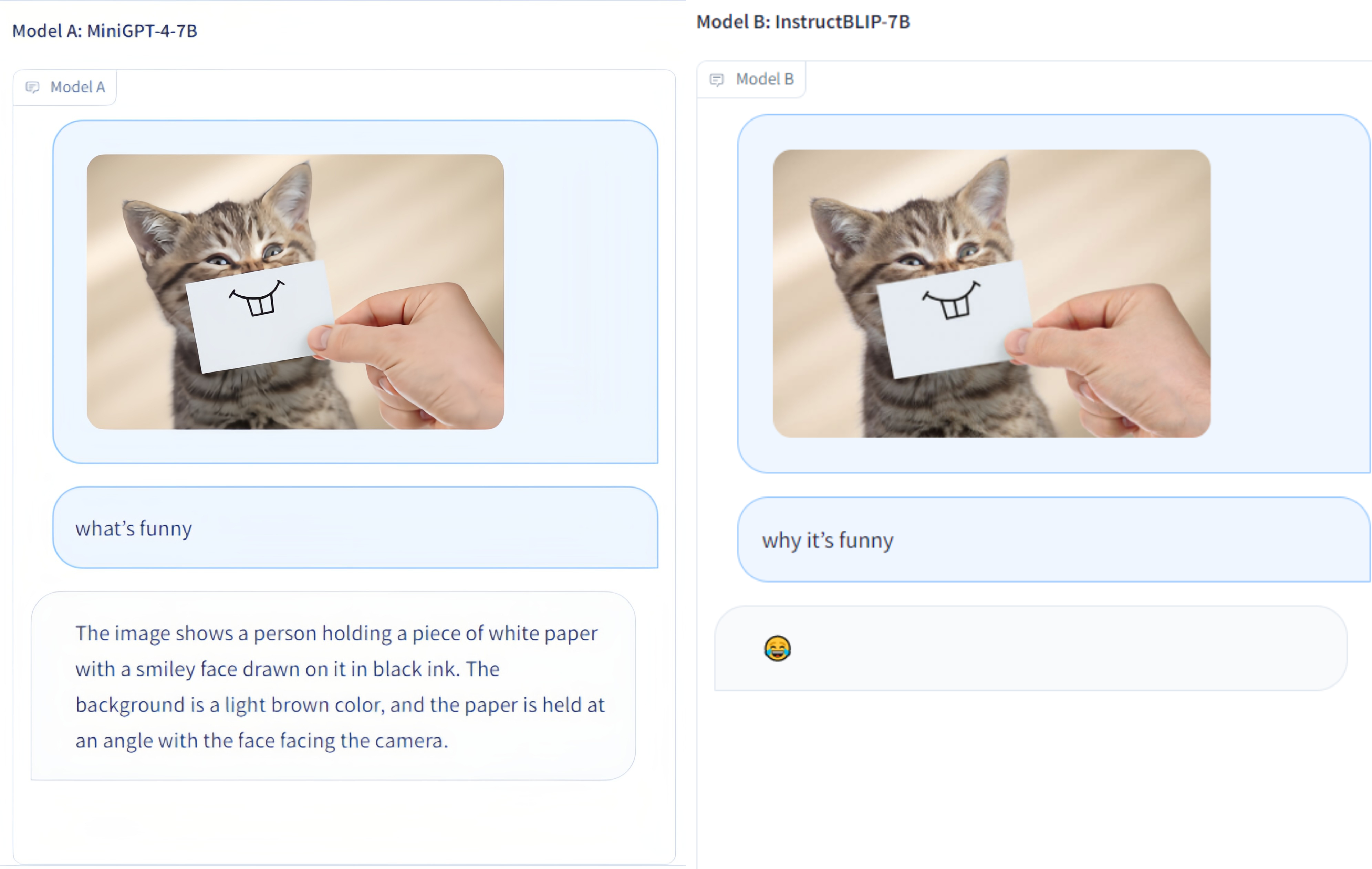
Multi-Modality Arena 는 대규모 다중 양식 모델을 위한 평가 플랫폼입니다. Fastchat에 이어 두 명의 익명 모델을 나란히 놓고 시각적 질문 답변 작업을 비교합니다. 우리는 데모를 출시하고 이 평가 계획에 모든 사람의 참여를 환영합니다.
OmniMedVQA 데이터 세트: 127,995개의 QA 항목이 포함된 118,010개의 이미지가 포함되어 있으며, 12가지 다른 양식을 다루고 20개 이상의 인체 해부학적 영역을 참조합니다. 데이터세트는 여기에서 다운로드할 수 있습니다.
12개 모델: 일반 영역 LVLM 8개, 의료 전문 LVLM 4개.
작은 데이터세트: 각 데이터세트에 대해 무작위로 선택된 50개의 샘플, 즉 사용 편의성을 위해 42개의 텍스트 관련 시각적 벤치마크와 총 2.1K개의 샘플.
추가 모델: 추가 4개 모델, 즉 Google Bard를 포함한 총 12개 모델.
ChatGPT 앙상블 평가 : 이전 단어 매칭 접근 방식보다 인간 평가와의 일치도가 향상되었습니다.
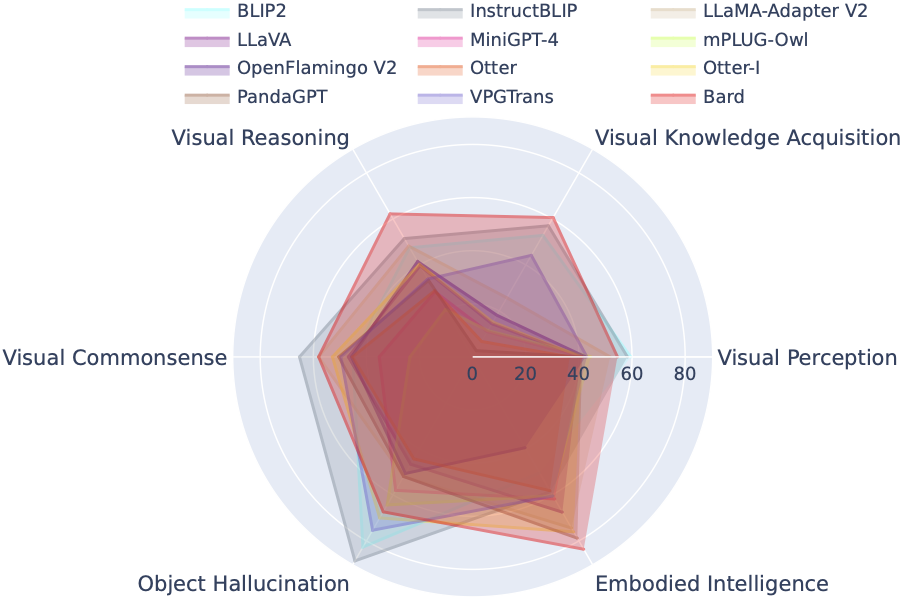
LVLM-eHub는 공개적으로 사용 가능한 LVLM(대형 다중 모드 모델)에 대한 포괄적인 평가 벤치마크입니다. 폭넓게 평가합니다
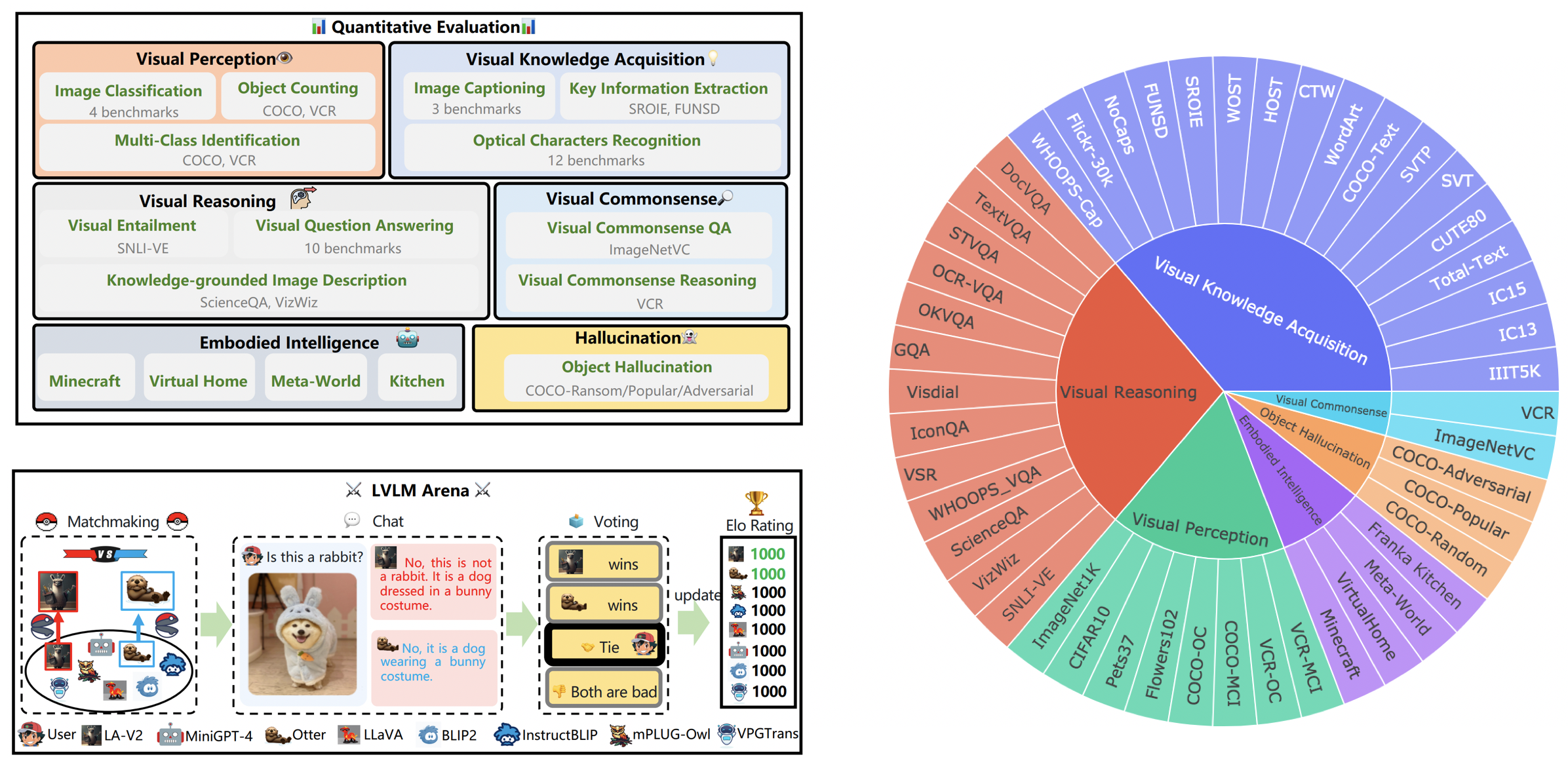
LVLM 순위표는 시각적 인식, 시각적 추론, 시각적 상식, 시각적 지식 획득 및 대상 환각을 포함한 구체적인 목표 능력에 따라 Tiny LVLM 평가에 포함된 데이터 세트를 체계적으로 분류합니다. 이 리더보드에는 포괄성을 강화하기 위해 최근 출시된 모델이 포함되어 있습니다.
여기에서 벤치마크를 다운로드할 수 있으며, 자세한 내용은 여기에서 확인할 수 있습니다.
| 계급 | 모델 | 버전 | 점수 |
|---|---|---|---|
| 1 | 인턴VL | InternVL-채팅 | 327.61 |
| 2 | InternLM-XComposer-VL | InternLM-XComposer-VL-7B | 322.51 |
| 3 | 음유 시인 | 음유 시인 | 319.59 |
| 4 | Qwen-VL-채팅 | Qwen-VL-채팅 | 316.81 |
| 5 | LLaVA-1.5 | 비쿠나-7B | 307.17 |
| 6 | 지시하다BLIP | 비쿠나-7B | 300.64 |
| 7 | InternLM-XComposer | InternLM-XComposer-7B | 288.89 |
| 8 | 블립2 | 플란T5xl | 284.72 |
| 9 | 블리바 | 비쿠나-7B | 284.17 |
| 10 | 스라소니 | 비쿠나-7B | 279.24 |
| 11 | 치타 | 비쿠나-7B | 258.91 |
| 12 | LLaMA-어댑터-v2 | LLaMA-7B | 229.16 |
| 13 | VPG트랜스 | 비쿠나-7B | 218.91 |
| 14 | 수달 이미지 | Otter-9B-LA-InContext | 216.43 |
| 15 | 비주얼GLM-6B | 비주얼GLM-6B | 211.98 |
| 16 | mPLUG-올빼미 | LLaMA-7B | 209.40 |
| 17 | LLaVA | 비쿠나-7B | 200.93 |
| 18 | MiniGPT-4 | 비쿠나-7B | 192.62 |
| 19 | 수달 | 수달-9B | 180.87 |
| 20 | OFv2_4BI | RedPajama-INCITE-Instruct-3B-v1 | 176.37 |
| 21 | 팬더GPT | 비쿠나-7B | 174.25 |
| 22 | 라빈 | LLaMA-7B | 97.51 |
| 23 | 마이크 | 플란T5xl | 94.09 |
2024년 3월 31일. 의료용 LVLM에 대한 대규모 종합 평가 벤치마크인 OmniMedVQA를 출시합니다. 한편, 일반 도메인 LVLM은 8개, 의료 전문 LVLM은 4개입니다. 자세한 내용은 MedicalEval을 참조하세요.
2023년 10월 16일. 최근 출시된 8개 모델이 포함되어 보완된 LVLM-eHub에서 파생된 능력 수준 데이터세트 분할을 제시합니다. 데이터 세트 분할, 평가 코드, 모델 추론 결과 및 종합 성능 표에 액세스하려면tiny_lvlm_evaluation ✅을 방문하세요.
2023년 8월 8일 [Tiny LVLM-eHub]를 출시했습니다. 평가 소스 코드와 모델 추론 결과는tiny_lvlm_evaluation에서 오픈 소스로 제공됩니다.
2023년 6월 15일. 대규모 비전 언어 모델 평가 벤치마크인 [LVLM-eHub]를 출시합니다. 코드가 곧 제공될 예정입니다.
2023년 6월 8일. VPGTrans의 저자인 Dr. Zhang의 수정에 감사드립니다. VPGTrans의 저자는 주로 NUS와 Tsinghua University 출신입니다. 이전에 VPGTrans를 다시 구현할 때 몇 가지 사소한 문제가 있었지만 실제로 성능이 더 좋다는 것을 발견했습니다. 더 많은 모델 작성자를 원하시면 이메일로 토론을 위해 저에게 연락해주세요. 또한 보다 정확한 결과를 얻을 수 있는 모델 순위 목록을 따르십시오.
5월. 2023년 2월 22일. mPLUG-Owl의 저자인 Dr. Ye의 수정에 감사드립니다. mPLIG-Owl 구현 시 몇 가지 사소한 문제를 수정했습니다.
현재 무작위 전투에 참여하고 있는 모델은 다음과 같습니다.
KAUST/MiniGPT-4
세일즈포스/BLIP2
세일즈포스/InstructBLIP
다모아카데미/mPLUG-Owl
NTU/수달
위스콘신대학교 매디슨/LLaVA
상하이 AI 연구소/llama_adapter_v2
NUS/VPG트랜스
이 모델에 대한 자세한 내용은 ./model_detail/.model.jpg 에서 확인할 수 있습니다. 우리는 경기장에서 더 많은 다중 양식 모델을 호스팅하기 위해 컴퓨팅 리소스를 예약하려고 노력할 것입니다.
VLarena 플랫폼에 관심이 있으시면 언제든지 Wechat 그룹에 가입하세요.

콘다 환경 만들기
conda create -n 경기장 python=3.10 콘다 활성화 아레나
컨트롤러 및 서버 실행에 필요한 패키지 설치
pip 설치 numpy gradio uvicorn fastapi
그런 다음 각 모델에 대해 충돌하는 Python 패키지 버전이 필요할 수 있으므로 GitHub 저장소를 기반으로 각 모델에 대한 특정 환경을 만드는 것이 좋습니다.
웹 UI를 사용하여 서비스를 제공하려면 사용자와 인터페이스하는 웹 서버, 두 개 이상의 모델을 호스팅하는 모델 작업자, 웹 서버와 모델 작업자를 조정하는 컨트롤러라는 세 가지 주요 구성 요소가 필요합니다.
터미널에서 따라야 할 명령은 다음과 같습니다.
파이썬 컨트롤러.py
이 컨트롤러는 분산 작업자를 관리합니다.
python model_worker.py --모델 이름 SELECTED_MODEL --장치 TARGET_DEVICE
프로세스가 모델 로드를 완료할 때까지 기다리면 "Uvicorn running on ..."이 표시됩니다. 모델 작업자는 컨트롤러에 자신을 등록합니다. 각 모델 작업자에 대해 사용하려는 모델과 장치를 지정해야 합니다.
파이썬 서버_demo.py
이는 사용자가 상호 작용하는 사용자 인터페이스입니다.
다음 단계를 따르면 웹 UI를 사용하여 모델을 제공할 수 있습니다. 이제 브라우저를 열고 모델과 채팅할 수 있습니다. 해당 모델이 나타나지 않을 경우, 그라디오 웹서버를 재부팅해 보세요.
우리는 평가의 질을 향상시키기 위한 모든 기여를 깊이 소중히 여깁니다. 이 섹션은 Contributions to LVLM Evaluation 와 Contributions to LVLM Arena 두 가지 주요 부분으로 구성됩니다.
LVLM_evaluation 폴더에서 최신 버전의 평가 코드에 액세스할 수 있습니다. 이 디렉토리에는 필요한 데이터 세트와 함께 포괄적인 평가 코드 세트가 포함되어 있습니다. 평가 과정에 적극적으로 참여하고 싶다면 주저하지 말고 [email protected]으로 이메일을 통해 평가 결과나 모델 추론 API를 공유해 주세요.
귀하의 모델을 LVLM 경기장에 통합하는 데 관심을 가져주셔서 감사드립니다! 귀하의 모델을 Arena에 통합하려면 다음과 같이 구성된 모델 테스터를 준비하십시오.
class ModelTester:def __init__(self, device=None) -> None:# TODO: 모델 및 필수 사전 프로세서 초기화def move_to_device(self, device) -> None:# TODO: 이 함수는 CPU와 CPU 간에 모델을 전송하는 데 사용됩니다. GPU (선택 사항)def generate(self, image, Question) -> str: # TODO: 모델 추론 코드
또한 Gradio와 같은 플랫폼에서 제공하는 것과 같은 온라인 모델 추론 링크도 열려 있습니다. 귀하의 기여에 진심으로 감사드립니다.
우리는 LVLM 평가 노력에 영감을 준 영향력 있는 작업에 대해 ChatBot Arena의 존경받는 팀과 판사로서 LLM을 판단하는 논문에 감사를 표합니다. 또한 대규모 비전 언어 모델의 발전과 발전에 크게 기여한 LVLM 제공자에게도 진심으로 감사의 말씀을 전하고 싶습니다. 마지막으로 LVLM-eHub에 사용된 데이터 세트 제공자에게 감사드립니다.
이 프로젝트는 비상업적 목적으로만 사용되는 실험적 연구 도구입니다. 보호 장치가 제한되어 있으며 부적절한 콘텐츠가 생성될 수 있습니다. 불법적이거나 유해하거나 폭력적이거나 인종차별적이거나 성적인 내용에는 사용할 수 없습니다.


