PubData
1.0.0

PubData 는 전 세계 모든 생물정보학 데이터베이스를 위한 검색 엔진 및 파일 검색 시스템입니다. PubData PubMed가 생물의학 문헌을 검색하는 방식과 유사한 사용자 친화적인 방식으로 생물의학 FTP 데이터를 검색합니다. PubData 웹 애플리케이션과 독립형 그래픽 사용자 인터페이스(GUI) 소프트웨어 프로그램으로 호스팅되는 반면 PubMed는 온라인 웹 서버로 호스팅됩니다. PubData 는 사용자가 지정한 생물정보학 데이터베이스의 FTP 서버에 패치하고, 내용을 쿼리하고, 다운로드할 파일을 검색할 수 있는 새로운 네트워크 프로그래밍 및 자연어 처리 알고리즘을 기반으로 구축되었습니다.
PubData Python 프로그래밍 언어(특히 Django 및 PyQt4)로 작성되었습니다. PubData 로컬 컴퓨터 네트워크를 통해 주요 생물정보학 데이터베이스의 깊게 중첩된 디렉터리 트리에서 파일을 원격으로 검색, 액세스, 보기 및 검색할 수 있습니다. PubData 모든 주요 생물정보학 데이터베이스를 하나의 소프트웨어 프로그램 아래에 모아 사용자가 인터넷 브라우저를 사용하여 데이터베이스에 하나씩 액세스할 때 발생하는 불필요한 번거로움과 비표준화 복잡성을 피할 수 있게 해줍니다. 더 중요한 것은 사용자가 사용자가 지정한 키워드(예: human , cancer , transcriptome )에 대해 여러 데이터베이스에 동시에 쿼리할 수 있다는 것입니다. 따라서 PubData 사용하면 연구자는 주요 생물정보학 데이터베이스의 FTP 서버에 있는 파일을 하나의 중앙 위치에서 직접 검색, 액세스, 보기 및 다운로드할 수 있습니다. PubData 사용하면 GUI나 웹 애플리케이션만 사용하여 사용자가 로컬 컴퓨터에서 편안하게 여러 생물정보학 FTP 서버를 동시에 탐색할 수 있습니다.
PubData 에서 영감을 얻은 방법을 사용하는 모든 소스 내에서 "Khomtchouk et al.: 'PubData: 전세계 생물정보학 데이터베이스 검색 엔진', 2016: http://dx.doi.org/10.1101/069575"를 인용하십시오.
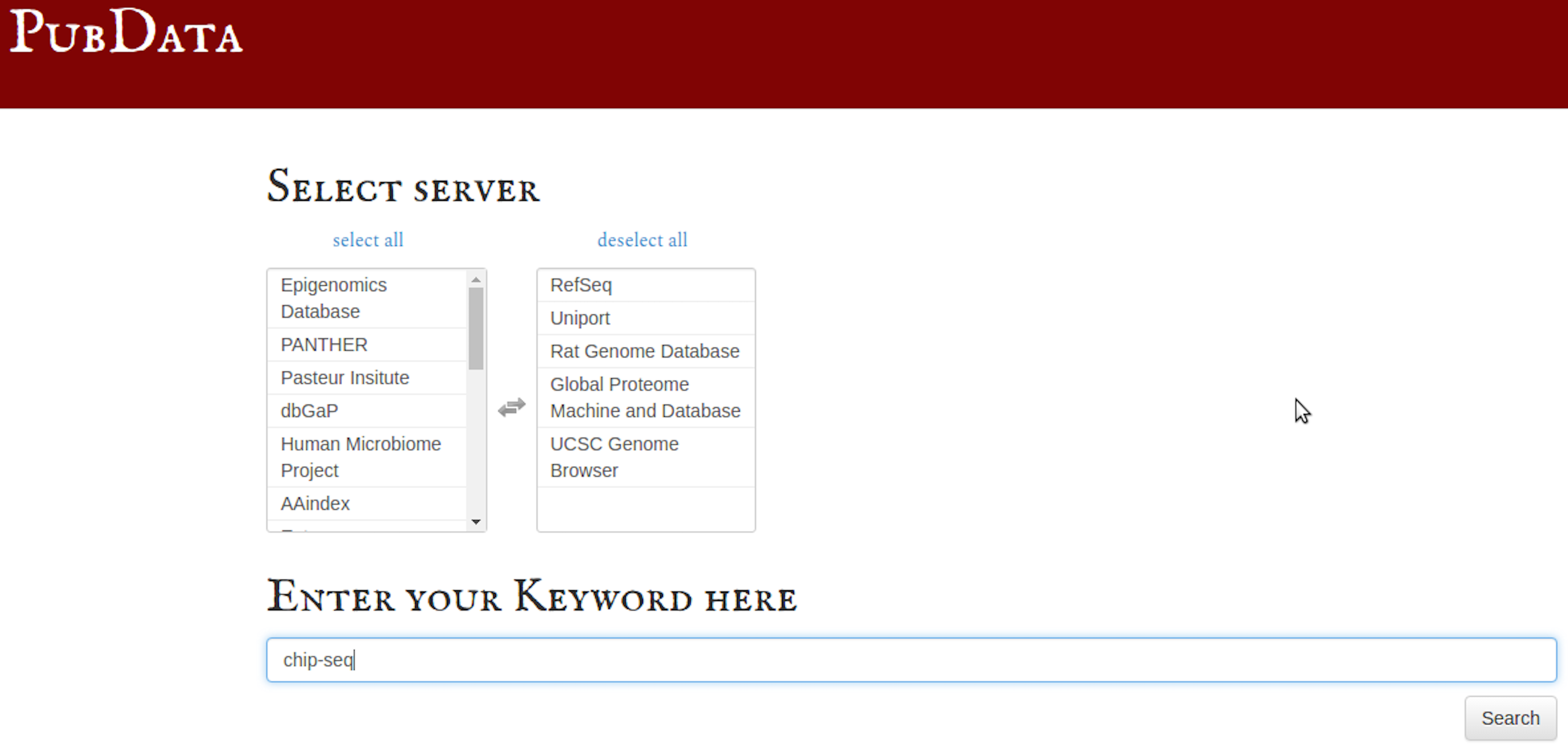
PubData 디렉터리. PubData 열 때 먼저 로그인할 생물정보학 데이터베이스를 선택하세요.
PANTHER(진화 관계를 통한 단백질 분석) 분류 시스템 데이터베이스에 로그인했습니다.
목록에 즐겨찾는 데이터베이스가 없으면 수동으로 직접 삽입할 수 있습니다(최근 게시된 데이터베이스의 경우 편리함).
여러 데이터베이스를 동시에 "Google 검색"하려고 한다고 가정해 보겠습니다.
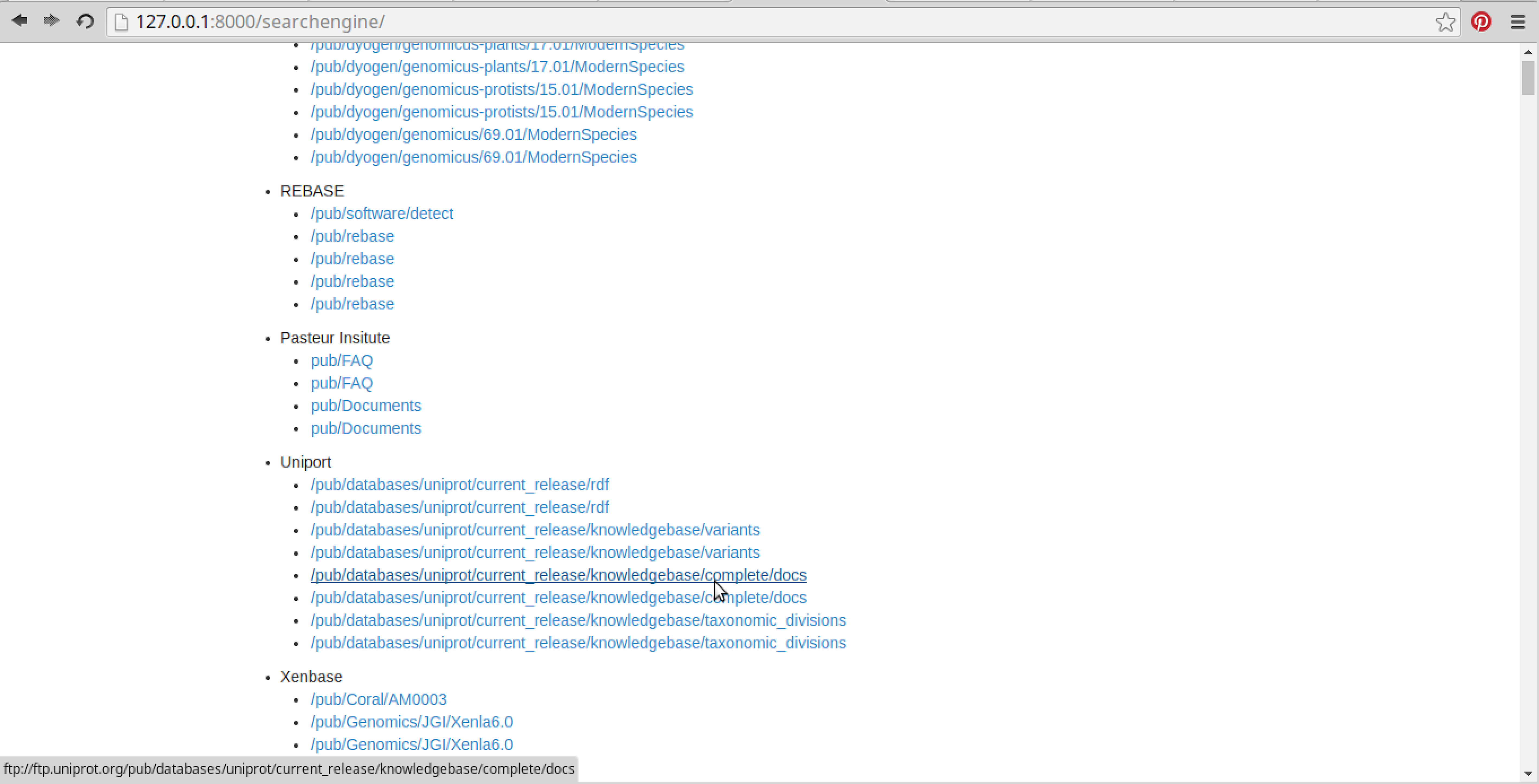
선택한 데이터베이스 전체에서 ChIP-seq 파일에 대한 키워드 검색(여러 키워드도 사용될 수 있음):
선택한 모든 데이터베이스에서 ChIP-seq 파일과 관련된 모든 관련 검색 결과 표시:
선택된 데이터베이스 전체에서 RNA-seq 파일에 대한 키워드 검색(여러 키워드도 사용될 수 있음):
(선택한 데이터베이스의) RNA-seq 파일과 관련된 모든 관련 검색 결과 표시:


