nlp lt
1.0.0
본 연구의 주요 목적은 리투아니아어에 대한 자연어 처리(NLP) 원리를 연구하고 배우는 것입니다. 고전적인 NLP 방법을 분석하고 그것이 어떻게 작동하는지 보는 것은 흥미롭기 때문에 이 작업에서는 텍스트 분류, 주제 추출, 검색 쿼리 및 클러스터링 아이디어를 구현했습니다. 구현 세부 사항 및 추가 정보는 paper/paper.pdf 에 저장되어 있습니다.
내 작업은 가장 인기 있는 뉴스 웹사이트인 www.delfi.lt에서 원시 데이터를 가져오는 것부터 시작되었기 때문에 텍스트 데이터가 없으면 데이터 분석을 확립할 수 없습니다. 5개 카테고리(범죄[227개 기사], 음악[120개 기사], 영화[167개 기사], 스포츠[136개 기사], 과학[204개 기사])에서 기사를 크롤링하기로 결정했습니다.
분류 성능은 행이 실제 범주이고 열이 예측 범주인 혼동 행렬을 사용하여 측정됩니다. 또한 이러한 접근 방식은 90%의 재현율과 90%의 정밀도에 도달합니다. 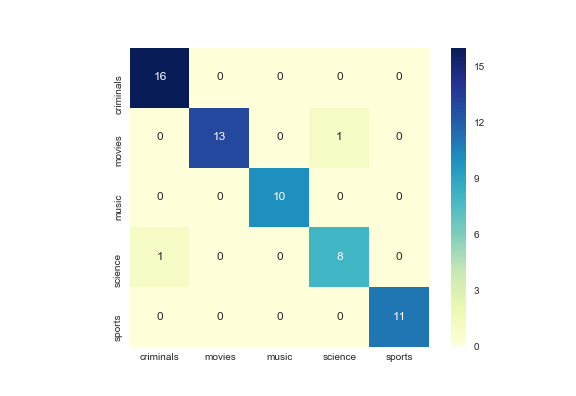
그림에서는 각 구성 요소에 대해 10개의 토큰이 있는 6개의 구성 요소를 보여줍니다. 이러한 결과로부터 우리는 가장 중요한 단어를 탐지하고 각 주성분에 대한 주제를 직관적으로 추측할 수 있습니다. 예를 들어 4개의 주요 구성 요소는 스포츠 및 음악에 대한 정보를 저장하고 6개의 주요 구성 요소는 범죄자에 대한 정보를 저장합니다.
주요 결과는 다음과 같습니다. 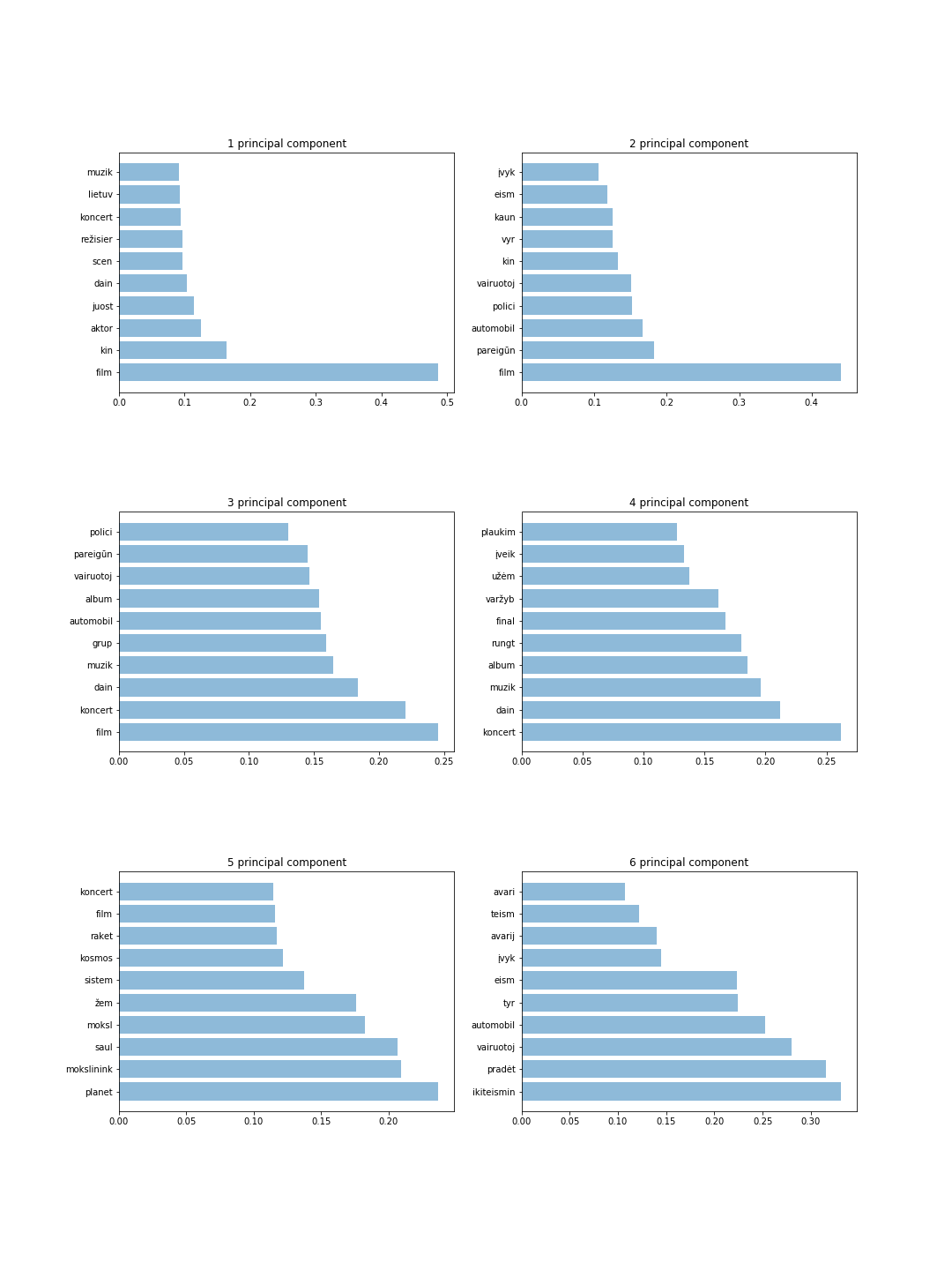
검색은 http://webhome.cs.uvic.ca/~thomo/svd.pdf 기사를 기반으로 하며, 여기서 lsa는 정확한 쿼리 유사성뿐만 아니라 문서 간의 더 깊은 관계를 사용하여 관련 문서를 찾는 데 적용됩니다. 
쿼리 = "švietim apdovanojam"
결과:
진행중


