Lihang
1.0.0
이 책의 제2판이 출판되었습니다. 2019년 5월 이후의 모든 내용 업데이트는 제2판의 초판을 참조합니다.
초판의 내용은 Release first_edition을 참조하세요.
[목차]
학습을 용이하게 하기 위해 일부 도구 설명이 정리되어 있습니다.
이 Repo를 참조해야 하는 경우:
형식: SmirkCao, Lihang, (2018), GitHub repository, https://github.com/SmirkCao/Lihang
또는
@misc{SmirkCao,
author = {SmirkCao},
title = {Lihang},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/SmirkCao/Lihang}},
commit = {c5624a9bd757a5cc88e78b85b89e9221deb08270}
}
이 부분은 "통계적 학습 방법"의 서문과 일치하지 않습니다. 책의 서문 도 잘 작성되어 있으며 다음과 같이 인용됩니다.
- 콘텐츠 선택 측면에서 가장 중요하고 일반적으로 사용되는 방법, 특히 분류 및 라벨링 문제와 관련된 방법을 소개하는 데 중점을 둡니다.
- 책 전체가 체계성을 잃지 않도록 통일된 프레임워크를 사용하여 모든 방법을 논의하도록 노력하세요.
- 정보검색 및 자연어 처리를 전공하는 대학생 및 대학원생에게 적용 가능합니다.
또 한 가지 주목할 점은 작가의 작업 배경이다.
저자는 자연어 처리, 정보 검색, 텍스트 데이터 마이닝 등 통계 학습 방법을 활용하여 텍스트 데이터의 다양한 지능적 처리에 관한 연구를 진행해 왔습니다.
내 모델을 사용하여 유사성 검색을 구현하면 Li 선생님의 책과 유사한 책이 "Semiconductor Optoelectronic Devices"입니다. 어렸을 때 반복해서 읽지 않은 것이 아쉽습니다.
반복해서 읽는 과정에서 책 전체가 두꺼워지고 얇아지기를 바랍니다. 이 시리즈의 모든 문서와 코드는 별도로 명시하지 않는 한 "책에 포함된" 설명은 Li Hang 선생님의 "통계적 학습 방법"을 의미합니다. 다른 참고문헌의 내용을 인용할 경우 링크로 연결해 드립니다.
일부 참고문헌은 Refs에 나열되어 있으며, 그 중 일부는 책의 내용을 이해하는 데 매우 도움이 됩니다. 이러한 파일에 대한 설명 및 설명은 참조 섹션에 해당하는 Refs/README.md에 추가됩니다. 다른 참고문헌에 대한 일부 참고 사항도 이 문서에 추가되었습니다.
참조 다운로드를 용이하게 하기 위해 review02 중에 ref_downloader.sh가 추가되었으며, 이를 사용하여 책에 나열된 참조를 다운로드할 수 있습니다. review02가 진행됨에 따라 업데이트 프로세스가 점차 완료됩니다.
게다가 이항 선생님의 이 책은, 정말 얇습니다 (두 번째 버전은 더 이상 얇지 않습니다) , 그러나 거의 모든 문장은 많은 요점을 제시하며 반복해서 읽을 가치가 있습니다.
책의 목차 뒤에는 기호 정의를 설명하는 기호표가 있으니, 이해가 안 되는 기호가 있으면 책 뒤편에 색인이 있으니, 기호표에서 찾아보시면 됩니다. 그리고 색인을 이용하여 책 위치에 나타나는 해당 기호의 의미를 찾을 수 있습니다. 본 Repo에서는 해당 기호에 대한 설명을 추가하고 해당 기호에 해당하는 페이지 번호를 직접 표시할 수 있도록 Glossary_index.md가 유지됩니다. 진행 상황은 리뷰와 함께 업데이트됩니다.
각 알고리즘이나 예제 뒤에는 ◼️가 표시되어 알고리즘이나 예제가 여기에서 끝난다는 것을 나타냅니다. 이것을 증명 끝 기호라고 합니다. 더 많은 문헌을 읽어보면 알 수 있습니다.
책을 읽을 때 우리는 로그의 밑수에 관해 종종 질문을 받습니다. 이 책에서는 더 중요한 것 중 일부를 강조합니다. 강조되지 않은 부분은 문맥을 통해 이해할 수 있습니다. 또한, 밑을 바꾸는 공식이 있기 때문에 밑이 무엇인지는 크게 중요하지 않습니다. 그 차이는 상수 계수에 있습니다. 그러나 다른 기반을 선택하는 것은 물리적 의미와 문제 해결 고려 사항을 갖습니다. 이 문제를 분석하려면 PRML 1.6의 엔트로피에 대한 설명을 참조하세요.
또한, 수식의 상수 계수 문제에 대해서는 반복해를 사용하고 때로는 수식이 어느 정도 단순화되면 수렴 속도가 향상될 수 있다. 세부 사항은 실제로 점차적으로 이해될 수 있습니다.
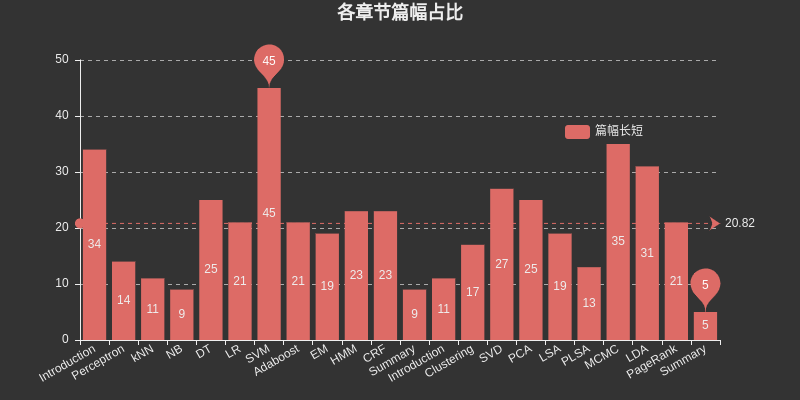
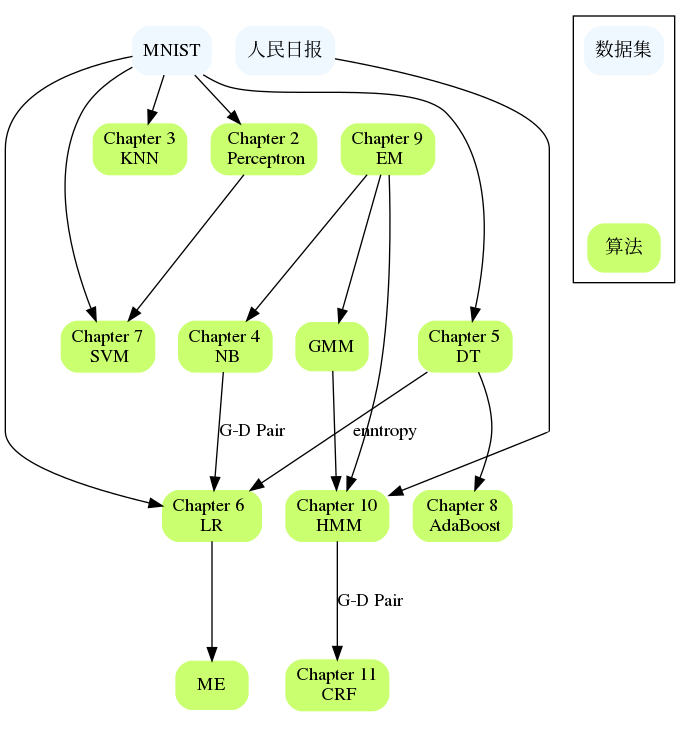
각 장이 차지하는 공간을 나열하려면 여기에 차트를 삽입하세요. 그 중 SVM은 지도 학습 중에서 가장 큰 공간을 차지하고, MCMC는 비지도 학습 중에서 가장 큰 공간을 차지하며, DT, HMM, CRF, SVD, PCA, LDA 및 PageRank는 또한 상대적으로 가장 큰 공간을 차지합니다.
NB와 LR, DT와 AdaBoost, Perceptron과 SVM, HMM과 CRF 등 장이 서로 연관되어 있습니다. 큰 장에서 어려움을 겪으면 이전 장의 내용을 검토하거나 참고 자료를 확인할 수 있습니다. 일반적으로 문제를 더 자세히 설명하고 문제가 있는 부분을 설명하는 참조 자료가 제공됩니다.
소개
통계 학습 방법의 세 가지 요소:
모델
전략
연산
제2판에서는 이 장의 디렉토리 구조를 더 명확하게 재구성했습니다.
퍼셉트론
kNN
NB
DT
LR
최대 엔트로피에 대한 연구는 본 장의 참고문헌 [1](Berger, 1996)을 읽어보는 것이 좋다. 이는 책에 나오는 사례를 이해하고 최대 엔트로피의 원리를 파악하는 데 도움이 된다.
그렇다면 LR과 Maxent가 한 챕터에 배치된 이유는 무엇일까요?
모두 로그 선형 모델에 속합니다.
둘 다 이진 분류 및 다중 분류에 사용될 수 있습니다.
두 모델의 학습 방법은 일반적으로 최대 우도 추정 또는 정규화된 최대 우도 추정을 사용하며, 제약 조건이 없는 최적화 문제로 형식화할 수 있으며 해결 방법에는 IIS, GD, BFGS 등이 포함됩니다.
로지스틱 회귀분석에서는 다음과 같이 설명됩니다.
로지스틱 회귀는 이름에도 불구하고 회귀보다는 분류를 위한 선형 모델입니다. 로지스틱 회귀는 문헌에서 로짓 회귀, 최대 엔트로피 분류(MaxEnt) 또는 로그 선형 분류기로도 알려져 있습니다. 단일 시행의 가능한 결과는 로지스틱 함수를 사용하여 모델링됩니다.
이런 설명도 있어요
로지스틱 회귀는 +1과 -1이라는 두 개의 레이블이 있는 최대 엔트로피의 특별한 경우입니다.
이 장의 파생에서는 $yin mathcal{Y}={0,1}$ 속성을 사용합니다.
NLP에서는 로지스틱 회귀를 Maxent라고 부르기도 합니다.
SVM
부스팅
HMM과 CRF는 대개 나중에 확률적 그래픽 모델의 도입으로 이어지므로 여기서 세분화하겠습니다. "머신러닝, Zhou Zhihua"에서는 HMM, MRF, CRF 및 기타 콘텐츠를 포함하기 위해 별도의 확률적 그래픽 모델 장을 사용합니다. 이밖에도 HMM부터 CRF 자체까지 관련 포인트가 많다.
책의 첫 번째 장에서는 지도 학습의 세 가지 응용 프로그램인 분류, 레이블 지정 및 회귀에 대해 설명합니다. 12장에 보충 자료가 있습니다. 이 책에서는 처음 두 장의 학습 방법을 주로 고려합니다. 따라서 여기서도 분할이 적절합니다. 분류 모델은 앞서 소개되었으며, 라벨링 문제는 주로 나중에 소개되었습니다.
여자 이름
EM 알고리즘은 숨겨진 변수가 포함된 확률 모델 매개변수의 최대 우도 추정 이나 최대 사후 확률 추정에 사용되는 반복 알고리즘입니다. (여기서 최대 우도 추정과 최대 사후 확률 추정은 학습 전략 이다)
확률 모델의 변수가 모두 관측 변수인 경우 데이터가 주어지면 최대 우도 추정 방법 또는 베이지안 추정 방법을 사용하여 모델 모수를 직접 추정할 수 있습니다.
참고로, 책에 나온 설명이 이해가 안 되시면 CH04의 Naive Bayes 방법 중 모수 추정 부분을 참고하시기 바랍니다.
코드의 이 부분은 BMM 및 GMM을 구현하므로 살펴볼 가치가 있습니다.
EM에 관해서는 이 장에 대해 많이 쓰여지지 않았습니다. EM은 상위 10개 알고리즘 중 하나입니다. Hinton은 2018년 ICLR에서 Capsule Network "Matrix Capsules with EM Routing"의 두 번째 기사를 게시했습니다.
CH22에서 EM 알고리즘은 기본 기계 학습 방법으로 분류되며 특정 기계 학습 모델을 포함하지 않으며 비지도 학습, 지도 학습 및 준지도 학습에 사용할 수 있습니다.
흠
CRF
요약
이 장에는 몇 페이지만 포함되어 있습니다. 다음 읽기 루틴을 고려해 보세요.
1장부터 읽어보세요
이전 연구에서 불분명한 질문을 발견했다면 이 장을 다시 읽어보세요.
이 장을 두껍게 읽고 이 장에서 다른 10개의 장으로 확장하십시오.
이 장에는 로지스틱 손실 함수를 언급하는 그림 12.2가 있습니다. 여기서 $y$는 $cal{Y}={+1,-1}$에 정의되어야 합니다. $cal{Y}={0,1}$에서 정의됩니다. 여기에 주의하세요.
리 선생님의 책은 정말 읽을 때마다 새로운 것을 얻게 해 줍니다.
두 번째 버전에는 클러스터링, 단일 값 분해, 주성분 분석, 잠재 의미 분석, 확률적 잠재 의미 분석, 마르코프 체인 몬테 카를로 방법, 잠재 Dirichlet 할당 및 PageRank의 8가지 비지도 학습 방법이 추가되었습니다.
소개
클러스터링
이 책의 각 장은 완전히 독립적이지 않습니다. 이 부분에서는 장과 적용 가능한 데이터 세트 간의 연결을 구성하기를 바랍니다. 알고리즘이 얼마나 멀리 구현되고 어떤 데이터 세트에서 실행할 수 있는지도 한 가지 측면입니다.