qwen2 in a lambda
1.0.0
2024년 11월 9일에 업데이트됨
(Python의 LLM API가 얼마나 빨리 이동하고 다른 사람이 이 글을 읽을 때까지 주요 변경 사항이 도입될 수 있으므로 날짜를 표시합니다!)
Docker 및 SAM CLI를 사용하여 Qwen GGUF 모델 파일을 AWS Lambda에 넣는 방법에 대한 사소한 연구입니다.
https://makit.net/blog/llm-in-a-lambda-function/에서 수정됨
Lambda + Bedrock이 아닌 Lambda의 기능만 활용하면 AWS 지출을 줄일 수 있는지 알아보고 싶었습니다. 두 서비스 모두 장기적으로 더 많은 비용이 발생하기 때문입니다.
그 아이디어는 상대적으로 리소스를 많이 사용하지 않는 작은 언어 모델에 적합하고 128 - 256MB 메모리 구성에서 1초 미만의 대기 시간을 수신하는 것이었습니다.
나는 메모리에 로드할 최고의 성능/파일 크기가 무엇인지 알아내기 위해 다양한 수준의 양자화를 사용하는 GGUF 모델도 사용하고 싶었습니다.
qwen2-1_5b-instruct-q5_k_m.gguf qwen_fuction/function/ 에 다운로드합니다.app.y / LOCAL_PATH 에서 모델 경로를 변경하세요. qwen_function/function/requirements.txt 아래에 pip 패키지를 설치합니다(바람직하게는 venv/conda 환경에 있음).sam build / sam validate 실행sam local start-api 실행하여 로컬에서 테스트curl --header "Content-Type: application/json" --request POST --data '{"prompt":"hello"}' http://localhost:3000/generate 실행하여 LLM 메시지를 표시합니다.sam deploy --guided 실행하여 AWS에 배포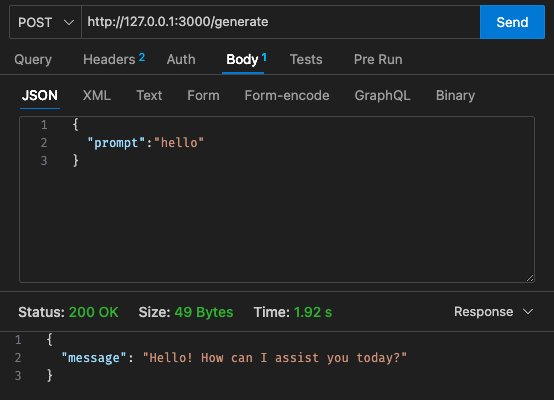
AWS
초기 구성 - 128MB, 30초 시간 초과
조정된 구성 #1 - 512mb, 30초 시간 초과
조정된 구성 #2 - 512MB, 30초 시간 초과
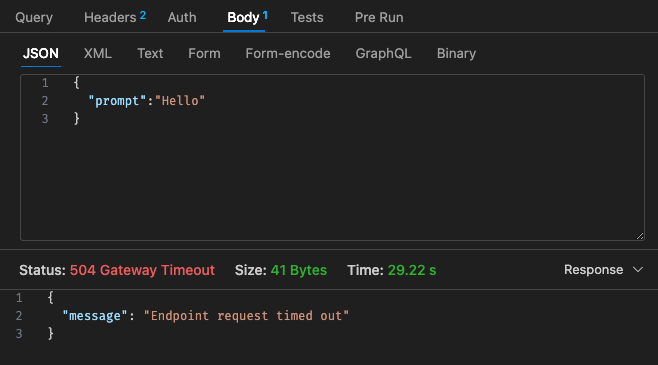
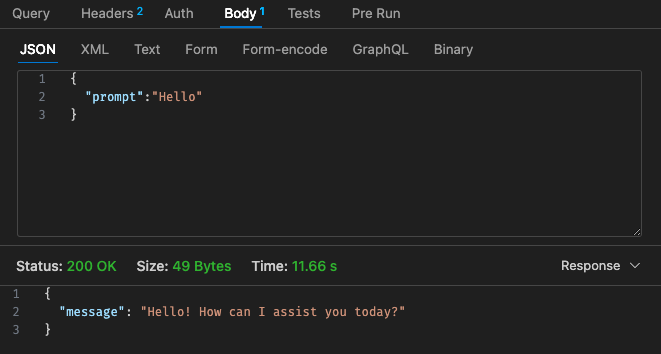
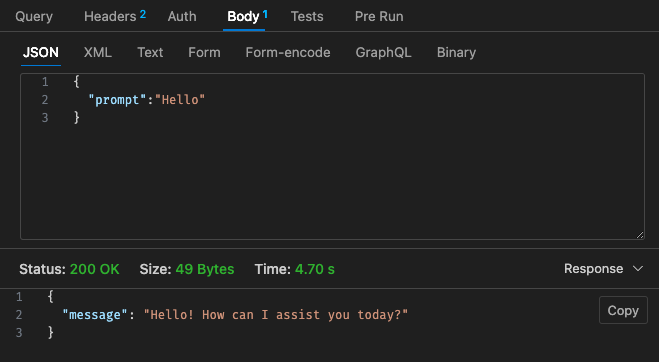
Lambda의 가격 구조를 다시 살펴보면,
Qwen이 포함된 Lambda의 가격 구조가 Claude 3 Haiku에 비해 경쟁력이 없어 보이기 때문에 클라우드에서 AWS Bedrock 등을 사용하여 호스팅된 LLM을 사용하는 것이 더 저렴할 수 있습니다.
또한 API 게이트웨이 시간 제한은 30초 제한 시간 이상으로 쉽게 구성할 수 없습니다. 사용 사례에 따라 이는 그다지 이상적이지 않을 수 있습니다.
로컬을 통한 결과는 컴퓨터 사양에 따라 다릅니다!! 당신의 인식, 기대와 현실이 크게 왜곡될 수 있습니다.
사용 사례에 따라 람다 호출 및 응답당 대기 시간으로 인해 사용자 경험이 저하될 수도 있습니다.
전체적으로, 내 사이드 프로젝트의 Qwen 1.5b를 통해 예산 및 대기 시간 요구 사항을 충족시키지는 못했지만 이것은 재미있는 작은 실험이었다고 생각합니다. 가이드를 제공해 주신 @makit에게 다시 한 번 감사드립니다!


