Interactive RAG
1.0.0
에이전트는 의사 결정 및 작업 수행을 위해 언어 모델을 활용하는 방식을 혁신하고 있습니다. 에이전트는 언어 모델을 사용하여 결정을 내리고 작업을 수행하는 시스템입니다. 이는 복잡한 시나리오를 처리하고 기존 접근 방식에 비해 더 많은 유연성을 제공하도록 설계되었습니다. 에이전트는 언어 모델을 활용하여 정보를 처리하고, 관련 데이터를 검색하고, 수집(청크/포함)하고, 응답을 생성하는 추론 엔진으로 생각할 수 있습니다.
앞으로 에이전트는 언어 모델이 발전함에 따라 텍스트 처리, 작업 자동화, 인간-컴퓨터 상호 작용 개선에 중요한 역할을 하게 될 것입니다.
이 예에서는 특히 동적 RAG(검색 증강 생성)에서 에이전트를 활용하는 데 중점을 둘 것입니다. ActionWeaver 및 MongoDB Atlas를 사용하면 대화 상호 작용을 통해 실시간으로 RAG 전략을 수정할 수 있습니다. 더 많은 청크를 선택하거나, 청크 크기를 늘리거나, 기타 매개변수를 조정하는 등 RAG 접근 방식을 미세 조정하여 원하는 응답 품질과 정확성을 얻을 수 있습니다. 자연어를 사용하여 벡터 데이터베이스에 소스를 추가/제거할 수도 있습니다!
# LLM Config
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
"summarize_chunks": True, # adds latency at ingest, everything comes at a cost
}
텍스트 청킹은 훌륭하지만 어떻게 저장합니까?
요약하면 공간이 절약되고 작업 속도가 빨라지지만 세부 정보가 손실될 수 있습니다.
원시 데이터를 저장하는 것은 정확하지만 부피가 크고 느리며 "시끄럽습니다".
요약의 장점:
요약의 단점:
당신에게 맞는 것은 무엇입니까? 그것은 귀하의 필요에 따라 다릅니다! 고려하다:
데모 1
새 Python 환경 만들기
python3 -m venv env새로운 Python 환경 활성화
source env/bin/activate요구사항 설치
pip3 install -r requirements.txtparams.py에서 매개변수를 설정합니다.
# MongoDB
MONGODB_URI = " "
DATABASE_NAME = " genai "
COLLECTION_NAME = " rag "
# If using OpenAI
OPENAI_API_KEY = " "
# If using Azure OpenAI
OPENAI_TYPE = " azure "
OPENAI_API_VERSION = " 2023-10-01-preview "
OPENAI_AZURE_ENDPOINT = " https://.openai.azure.com/ "
OPENAI_AZURE_DEPLOYMENT = " "
다음 정의를 사용하여 검색 색인을 생성합니다.
{
"mappings" : {
"dynamic" : true ,
"fields" : {
"embedding" : {
"dimensions" : 384 ,
"similarity" : " cosine " ,
"type" : " knnVector "
}
}
}
}환경 설정
export OPENAI_API_KEY=RAG 애플리케이션을 실행하려면
env/bin/streamlit run rag/app.py애플리케이션에서 생성된 로그 정보는 app.log에 추가됩니다.
이 봇은 질문에 답하기, 웹 검색, URL 읽기, 소스 제거, 모든 소스 나열, 메시지 재설정 등의 작업을 지원합니다. 또한 에이전트의 RAG 전략을 동적으로 제어할 수 있는 iRAG라는 작업도 지원합니다.
예: "RAG 구성을 3개의 소스 및 청크 크기 1250으로 설정" => 새로운 RAG 구성:{'num_sources': 3, 'source_chunk_size': 1250, 'min_rel_score': 0, 'unique': True}.
def __call__(self, text):
text = self.preprocess_query(text)
self.messages += [{"role": "user", "content":text}]
response = self.llm.create(messages=self.messages, actions = [
self.read_url,self.answer_question,self.remove_source,self.reset_messages,
self.iRAG, self.get_sources_list,self.search_web
], stream=True)
return response
봇이 Atlas Vector 스토어에 저장된 데이터와 RAG 전략(소스 수, 청크 크기, min_rel_score 등)에서 질문에 대한 답변을 제공할 수 없는 경우 관련 정보를 찾기 위해 웹 검색을 시작합니다. 그런 다음 봇에게 해당 결과를 읽고 학습하도록 지시할 수 있습니다.
RAG는 훌륭하지만 올바른 "RAG 전략"을 생각해내는 것은 까다롭습니다. 청크 크기와 고유 소스 수는 LLM에서 생성된 응답에 직접적인 영향을 미칩니다.
효과적인 RAG 전략을 개발하는 데 있어서 웹 소스의 수집 프로세스, 청크, 임베딩, 청크 크기 및 사용된 소스의 양이 중요한 역할을 합니다. 청킹은 더 나은 이해를 위해 입력 텍스트를 세분화하고, 임베딩은 의미를 포착하며, 소스 수는 응답 다양성에 영향을 미칩니다. 정확하고 관련성이 높은 응답을 위해서는 청크 크기와 소스 수 사이의 적절한 균형을 찾는 것이 필수적입니다. 최적의 설정을 결정하려면 실험과 미세 조정이 필요합니다.
'검색'에 대해 알아보기 전에 먼저 '수집 프로세스'에 대해 알아보겠습니다.
콘텐츠를 벡터 데이터베이스에 "수집"하는 별도의 프로세스가 있는 이유는 무엇입니까? 에이전트의 마법을 사용하여 벡터 데이터베이스에 새로운 콘텐츠를 쉽게 추가할 수 있습니다.
이러한 임베딩을 저장할 수 있는 다양한 유형의 데이터베이스가 있으며 각각 고유한 용도가 있습니다. 하지만 GenAI 애플리케이션과 관련된 작업에는 MongoDB를 권장합니다.
MongoDB를 가지고 있고 먹을 수 있는 케이크라고 생각하십시오. 이는 쿼리 작성을 위한 언어인 Mongo Query Language의 강력한 기능을 제공합니다. 또한 MongoDB의 모든 뛰어난 기능이 포함되어 있습니다. 게다가 이러한 빌딩 블록(벡터 임베딩)을 저장하고 이에 대한 수학 연산을 모두 한곳에서 수행할 수 있습니다. 이를 통해 MongoDB Atlas는 모든 벡터 임베딩 요구 사항을 충족하는 원스톱 상점이 됩니다!
@action("read_url", stop=True)
def read_url(self, urls: List[str]):
"""
Invoke this ONLY when the user asks you to 'read', 'add' or 'learn' some URL(s).
This function reads the content from specified sources, and ingests it into the Knowledgebase.
URLs may be provided as a single string or as a list of strings.
IMPORTANT! Use conversation history to make sure you are reading/learning/adding the right URLs.
Parameters
----------
urls : List[str]
List of URLs to scrape.
Returns
-------
str
A message indicating successful reading of content from the provided URLs.
"""
with self.st.spinner(f"```Analyzing the content in {urls}```"):
loader = PlaywrightURLLoader(urls=urls, remove_selectors=["header", "footer"])
documents = loader.load_and_split(self.text_splitter)
self.index.add_documents(
documents
)
return f"```Contents in URLs {urls} have been successfully ingested (vector embeddings + content).```"
{
"mappings": {
"dynamic": true,
"fields": {
"embedding": {
"dimensions": 384, #dimensions depends on the model
"similarity": "cosine",
"type": "knnVector"
}
}
}
}
def recall(self, text, n_docs=2, min_rel_score=0.25, chunk_max_length=800,unique=True):
#$vectorSearch
print("recall=>"+str(text))
response = self.collection.aggregate([
{
"$vectorSearch": {
"index": "default",
"queryVector": self.gpt4all_embd.embed_query(text), #GPT4AllEmbeddings()
"path": "embedding",
#"filter": {},
"limit": 15, #Number (of type int only) of documents to return in the results. Value can't exceed the value of numCandidates.
"numCandidates": 50 #Number of nearest neighbors to use during the search. You can't specify a number less than the number of documents to return (limit).
}
},
{
"$addFields":
{
"score": {
"$meta": "vectorSearchScore"
}
}
},
{
"$match": {
"score": {
"$gte": min_rel_score
}
}
},{"$project":{"score":1,"_id":0, "source":1, "text":1}}])
tmp_docs = []
str_response = []
for d in response:
if len(tmp_docs) == n_docs:
break
if unique and d["source"] in tmp_docs:
continue
tmp_docs.append(d["source"])
str_response.append({"URL":d["source"],"content":d["text"][:chunk_max_length],"score":d["score"]})
kb_output = f"Knowledgebase Results[{len(tmp_docs)}]:n```{str(str_response)}```n## n```SOURCES: "+str(tmp_docs)+"```nn"
self.st.write(kb_output)
return str(kb_output)
함수 호출 API를 위한 경량 래퍼인 ActionWeaver를 사용하면 MongoDB Atlas를 사용하여 관련 정보를 효율적으로 검색하고 수집하는 사용자 프록시 에이전트를 구축할 수 있습니다.
프록시 에이전트는 클라이언트 요청을 다른 서버나 리소스에 보낸 다음 응답을 다시 가져오는 중개자입니다.
이 에이전트는 대화형 및 사용자 정의 가능한 방식으로 사용자에게 데이터를 제공하여 전반적인 사용자 경험을 향상시킵니다.
UserProxyAgent 에는 chunk_size (예: 1000), num_sources (예: 2), unique (예: True) 및 min_rel_score (예: 0.00)와 같이 사용자 정의할 수 있는 여러 RAG 매개변수가 있습니다.
class UserProxyAgent:
def __init__(self, logger, st):
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
}
ActionWeaver를 선택하기로 한 결정에 영향을 준 몇 가지 주요 이점은 다음과 같습니다.
에이전트는 기본적으로 환경을 인식하고, 결정을 내리고, 특정 목표를 달성하도록 설계된 컴퓨터 프로그램 또는 시스템입니다.
에이전트를 어느 정도의 자율성을 표시하고 사용자 또는 소유자를 대신하여 해당 환경에서 작업을 수행하지만 상대적으로 독립적인 방식으로 수행하는 소프트웨어 엔터티로 생각하십시오. 목표를 달성하기 위한 옵션을 숙고하여 스스로 조치를 수행하려면 주도권이 필요합니다. 에이전트의 핵심 아이디어는 언어 모델을 사용하여 수행할 일련의 작업을 선택하는 것입니다. 일련의 작업이 코드에 하드코딩되어 있는 체인과 달리 에이전트는 언어 모델을 추론 엔진으로 사용하여 수행할 작업과 순서를 결정합니다.
작업은 에이전트가 호출할 수 있는 기능입니다. 작업과 관련하여 두 가지 중요한 디자인 고려 사항이 있습니다.
Giving the agent access to the right actions
Describing the actions in a way that is most helpful to the agent
두 가지를 모두 고려하지 않으면 작동하는 에이전트를 구축할 수 없습니다. 에이전트에 올바른 작업 집합에 대한 액세스 권한을 부여하지 않으면 에이전트는 부여한 목표를 결코 달성할 수 없습니다. 액션을 잘 설명하지 않으면 에이전트가 액션을 제대로 사용하는 방법을 알 수 없습니다.
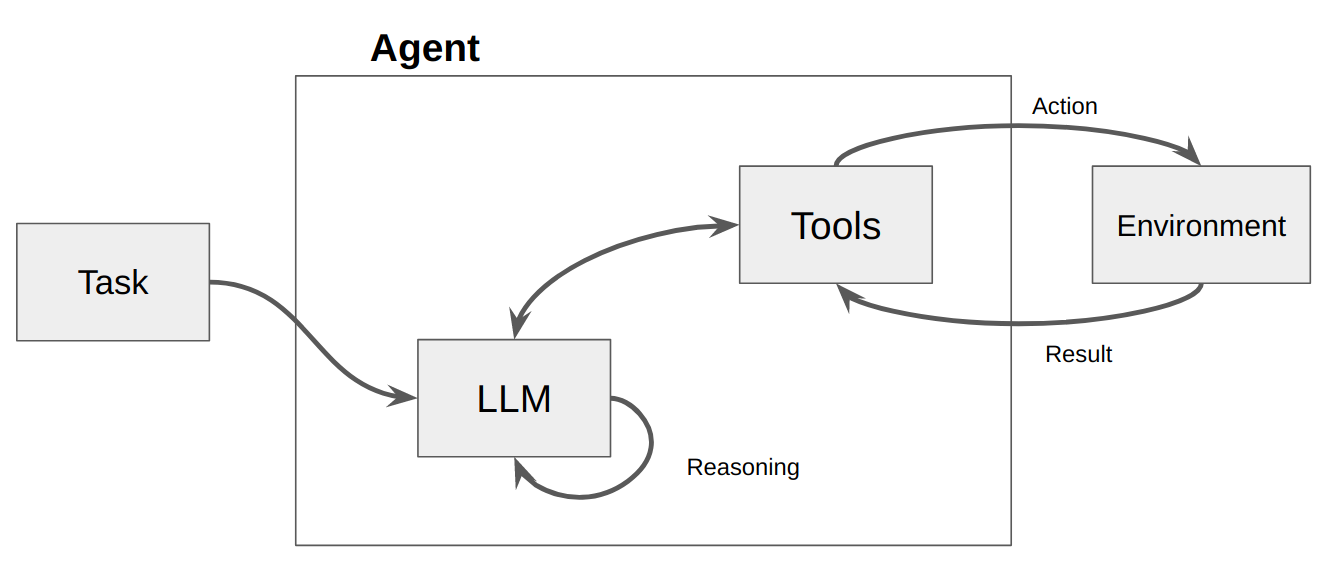
그런 다음 LLM이 호출되어 사용자에 대한 응답 또는 취해야 할 작업이 발생합니다. 응답이 필요하다고 판단되면 응답이 사용자에게 전달되고 해당 주기가 완료됩니다. 조치가 필요하다고 판단되면 해당 조치를 취하고 관찰(조치 결과)이 이루어집니다. 해당 작업 및 해당 관찰이 프롬프트에 다시 추가되고(이를 "에이전트 스크래치 패드"라고 함) 루프가 재설정됩니다. 업데이트된 에이전트 스크래치 패드를 사용하여 LLM이 다시 호출됩니다.
ActionWeaver에서는 stop=True|False 를 액션에 추가하여 루프에 영향을 줄 수 있습니다. stop=True 인 경우 LLM은 즉시 함수의 출력을 반환합니다. 이는 또한 LLM이 여러 함수를 호출하는 것을 제한합니다. 이 데모에서는 stop=True 만 사용합니다.
ActionWeaver는 orch_expr(SelectOne[actions]) 및 orch_expr(RequireNext[actions]) 사용하여 더 복잡한 루프 제어도 지원하지만 이에 대해서는 2부에서 다루겠습니다.
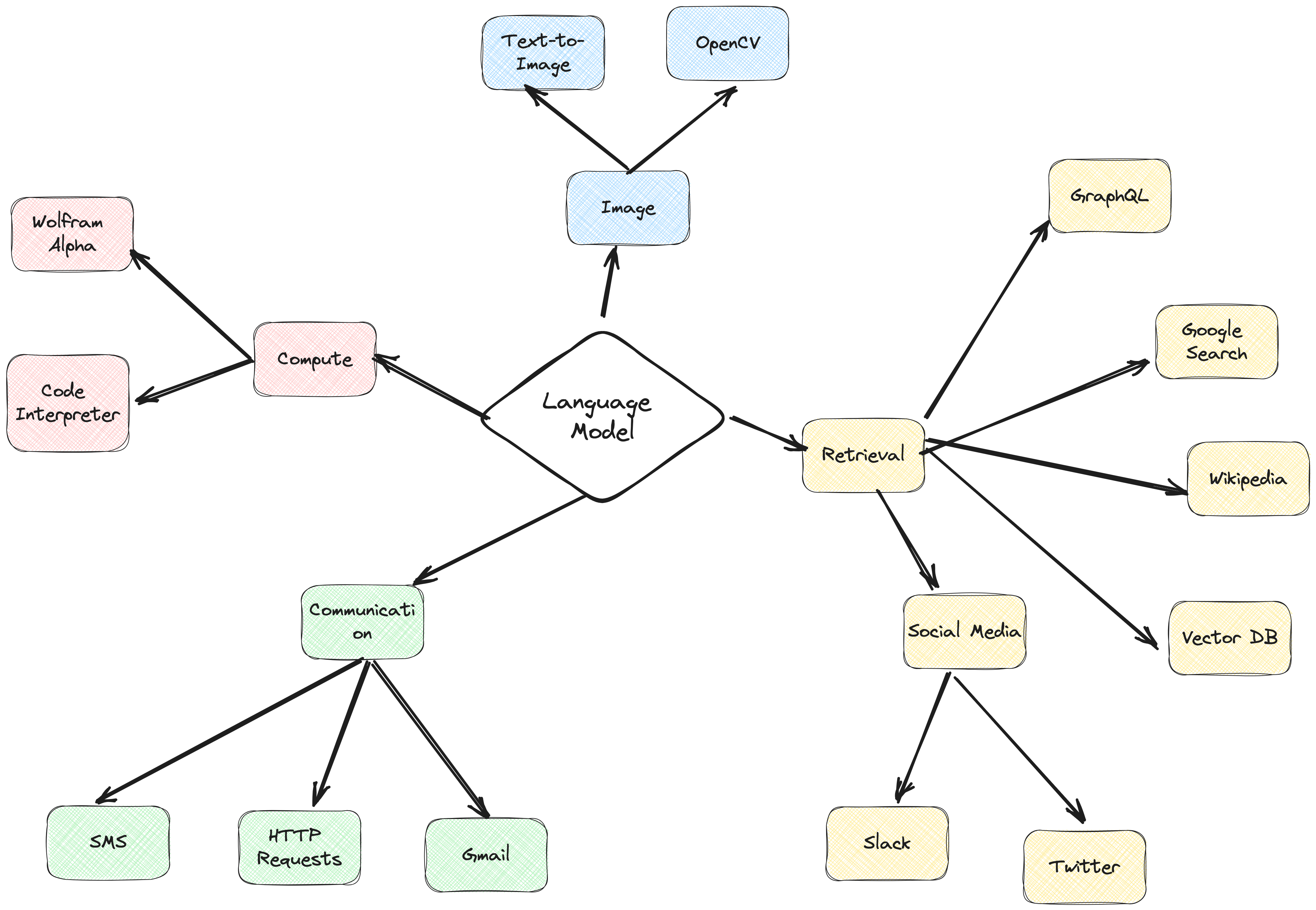
ActionWeaver 에이전트 프레임워크는 함수 호출을 핵심으로 하는 AI 애플리케이션 프레임워크입니다. 이는 기존 컴퓨팅 시스템과 언어 모델 모델의 강력한 추론 기능을 원활하게 병합할 수 있도록 설계되었습니다. ActionWeaver는 LLM 함수 호출 개념을 기반으로 구축된 반면, Langchain 및 Haystack과 같은 널리 사용되는 프레임워크는 파이프라인 개념을 기반으로 구축되었습니다.

자세한 내용은 https://thinhdanggroup.github.io/function-calling-openai/를 참조하세요.
개발자는 간단한 데코레이터를 사용하여 모든 Python 함수를 도구로 연결할 수 있습니다. 다음 예에서는 OpenAI API에 의해 호출되는 get_sources_list 작업을 소개합니다.
ActionWeaver는 데코레이팅된 메서드의 서명과 문서 문자열을 설명으로 활용하여 OpenAI의 함수 API에 전달합니다.
ActionWeaver는 문서 문자열/데코레이터 정보를 OpenAI API에 대한 올바른 형식으로 변환하는 간단한 래퍼를 제공합니다.
@action(name="get_sources_list", stop=True)
def get_sources_list(self):
"""
Invoke this to respond to list all the available sources in your knowledge base.
Parameters
----------
None
"""
sources = self.collection.distinct("source")
if sources:
result = f"Available Sources [{len(sources)}]:n"
result += "n".join(sources[:5000])
return result
else:
return "N/A"
작업에 stop=True를 추가하면 LLM이 함수의 출력을 즉시 반환하지만 이는 또한 LLM이 여러 함수를 호출하는 것을 제한한다는 의미입니다. 예를 들어, NYC와 San Francisco의 날씨에 대해 질문하면 모델은 각 도시에 대해 두 개의 개별 함수를 순차적으로 호출합니다. 그러나 stop=True 사용하면 첫 번째 함수가 먼저 쿼리하는 도시에 따라 NYC 또는 San Francisco에 대한 날씨 정보를 반환하면 이 프로세스가 중단됩니다.
이 봇이 내부적으로 어떻게 작동하는지 더 깊이 이해하려면 bot.py 파일을 참조하세요. 또한 ActionWeaver 저장소를 탐색하여 자세한 내용을 확인할 수 있습니다.
추론 추적을 생성하면 모델이 작업 계획을 유도, 추적 및 업데이트하고 예외를 처리할 수도 있습니다. 이 예에서는 CoT(사고 사슬)와 결합된 ReAct를 사용합니다.
생각의 사슬
추론 + 행동
[EXAMPLES]
- User Input: What is MongoDB?
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "answer_question".
- Action: "answer_question"('What is MongoDB?')
- User Input: Reset chat history
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "reset_messages".
- Action: "reset_messages"()
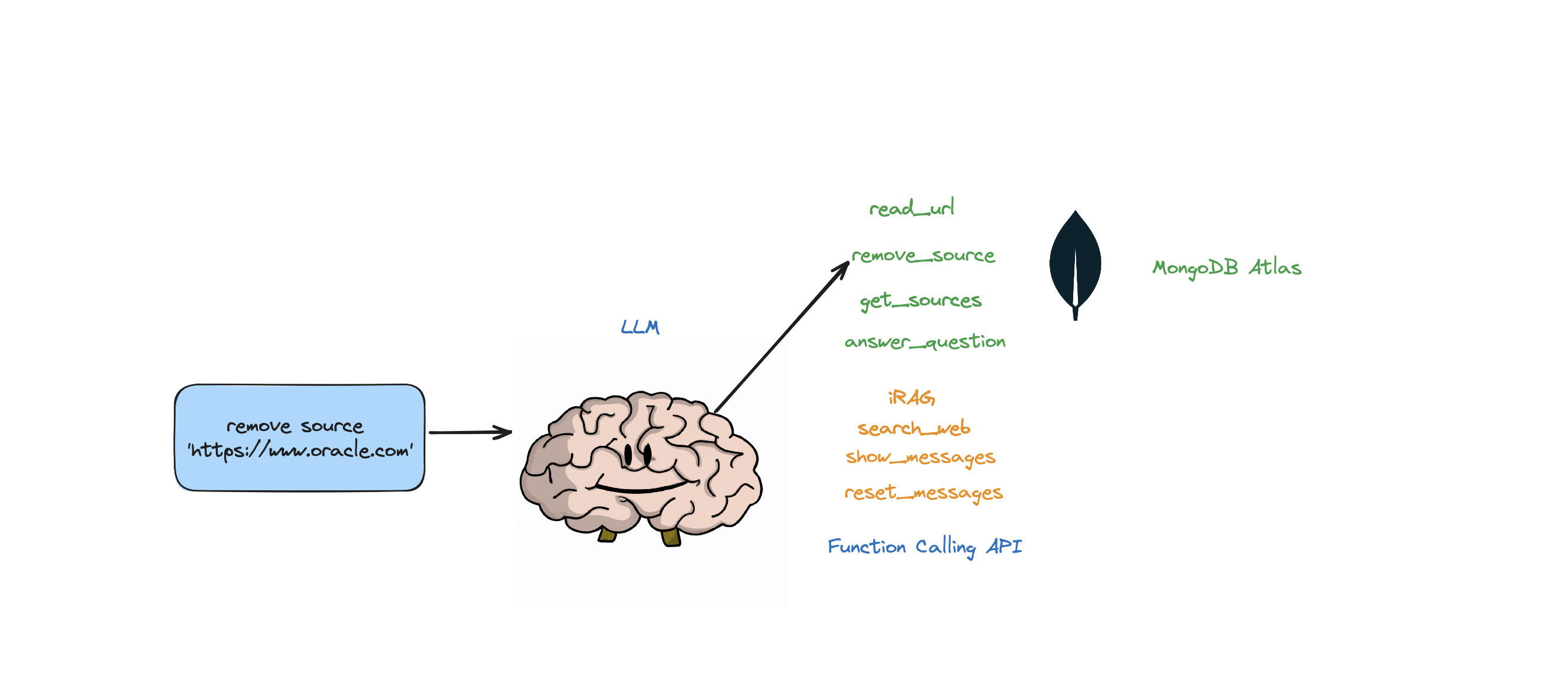
- User Input: remove source https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "remove_source".
- Action: "remove_source"(['https://www.google.com', 'https://www.example.com'])
- User Input: read https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "read_url".
- Action: "read_url"(['https://www.google.com','https://www.example.com'])
[END EXAMPLES]
이 예에서는 CoT(사고의 사슬)와 ReAct 프롬프트 기술이 모두 사용됩니다. 방법은 다음과 같습니다.
CoT(사고 사슬) 프롬프트:
반응 프롬프트:
요약하자면, CoT와 ReAct는 모두 이 예에서 중요한 역할을 합니다. CoT를 사용하면 모델이 단계별로 추론하고 적절한 조치를 선택할 수 있으며, ReAct는 모델이 환경과 상호 작용하고 그에 따라 계획을 업데이트할 수 있도록 하여 이 기능을 확장합니다. 추론과 행동의 이러한 결합은 대규모 언어 모델을 더욱 유연하고 다양하게 만들어 광범위한 작업과 상황을 처리할 수 있게 해줍니다.
상담원에게 질문부터 시작해 보겠습니다. 이 경우 "망고란 무엇인가?" . 가장 먼저 일어날 일은 벡터 임베딩 유사성을 사용하여 관련 정보를 "기억"하려고 시도하는 것입니다. 그런 다음 "기억한" 내용으로 응답을 작성하거나 웹 검색을 수행합니다. 현재 지식 베이스가 비어 있으므로 응답을 공식화하기 전에 몇 가지 소스를 추가해야 합니다.
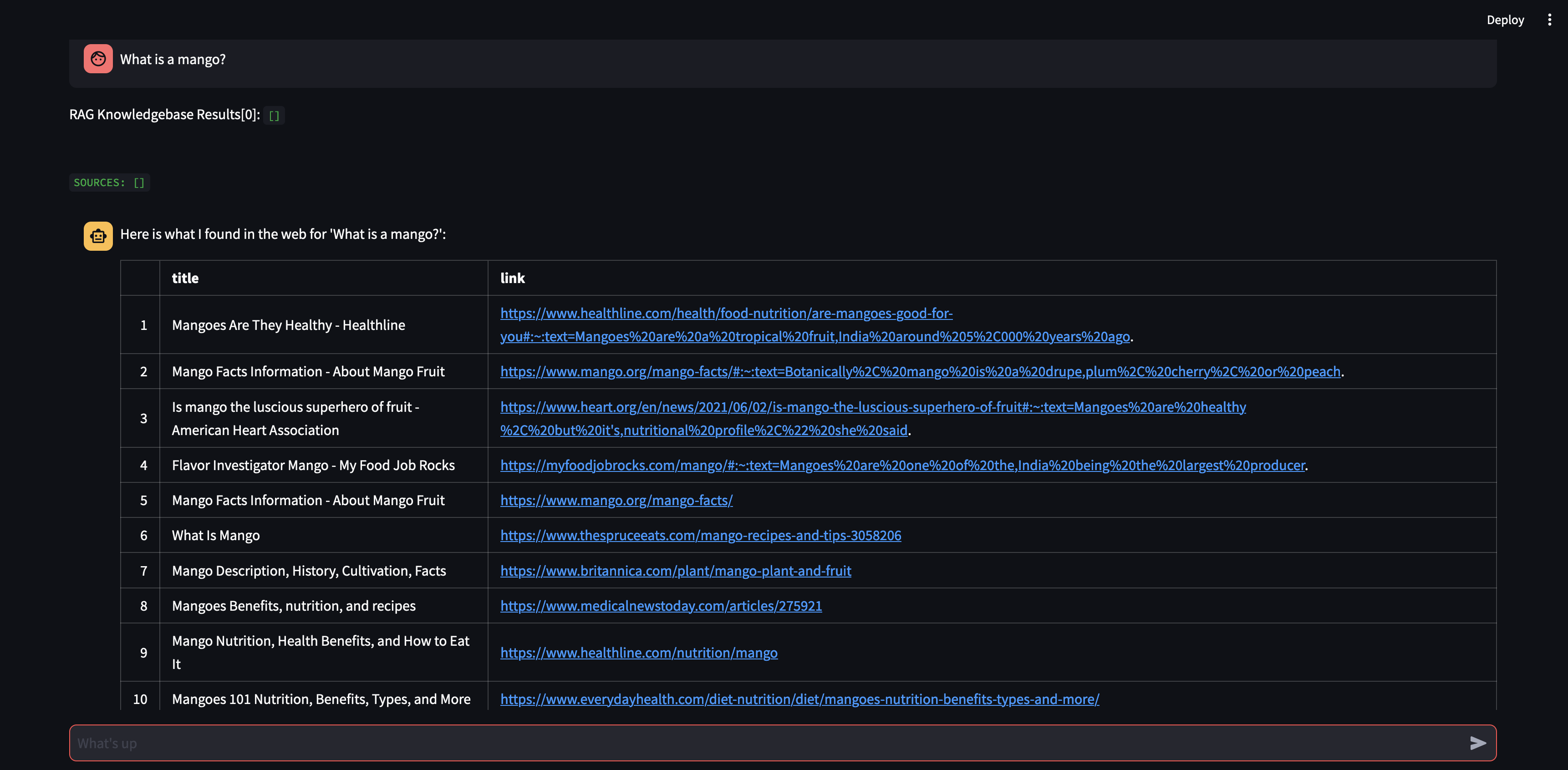
봇은 벡터 데이터베이스의 콘텐츠를 사용하여 답변을 제공할 수 없기 때문에 관련 정보를 찾기 위해 Google 검색을 시작했습니다. 이제 어떤 소스를 "학습"해야 하는지 알 수 있습니다. 이 경우 검색 결과에서 처음 두 소스를 학습하도록 지시하겠습니다.
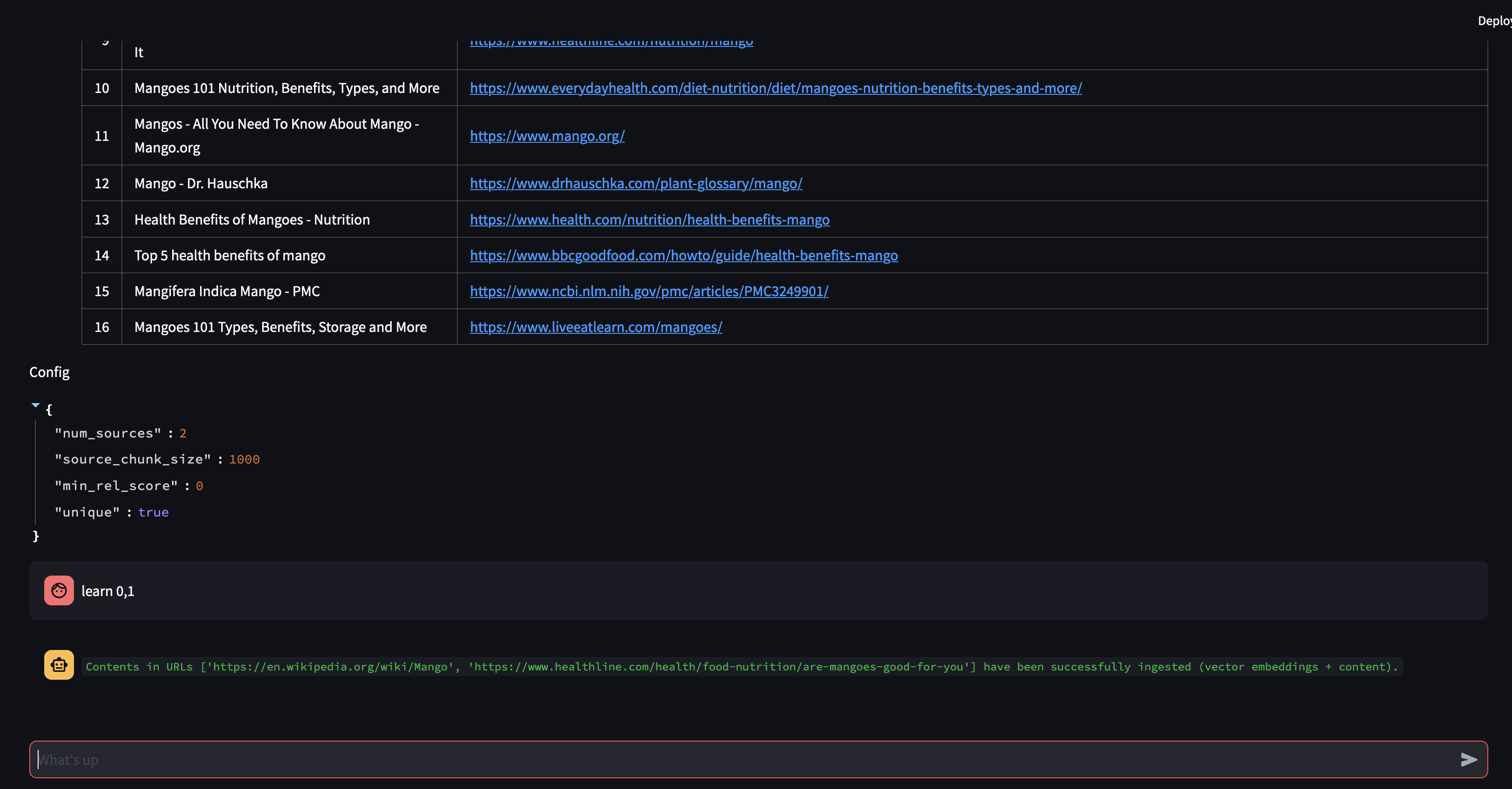
다음으로 RAG 전략을 수정해 보겠습니다! 하나의 소스만 사용하고 500자의 작은 청크 크기를 사용하도록 하겠습니다.
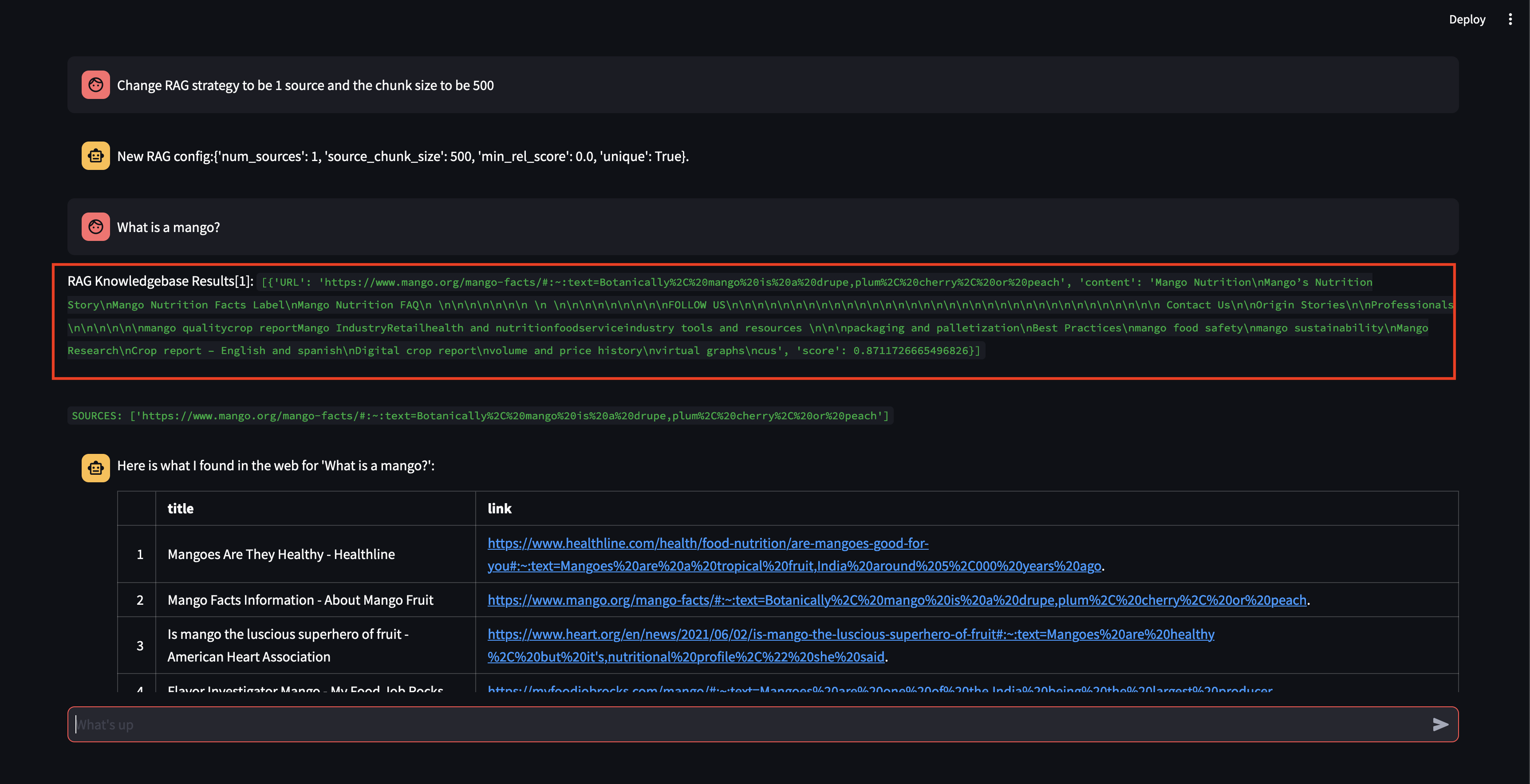
상당히 높은 관련성 점수로 청크를 검색할 수 있었지만 청크 크기가 너무 작고 청크 콘텐츠가 응답을 공식화할 만큼 관련성이 없었기 때문에 응답을 생성할 수 없었습니다. 작은 덩어리로는 응답을 생성할 수 없기 때문에 사용자를 대신하여 웹 검색을 수행했습니다.
청크 크기를 500자가 아닌 3000자로 늘리면 어떤 일이 발생하는지 살펴보겠습니다.
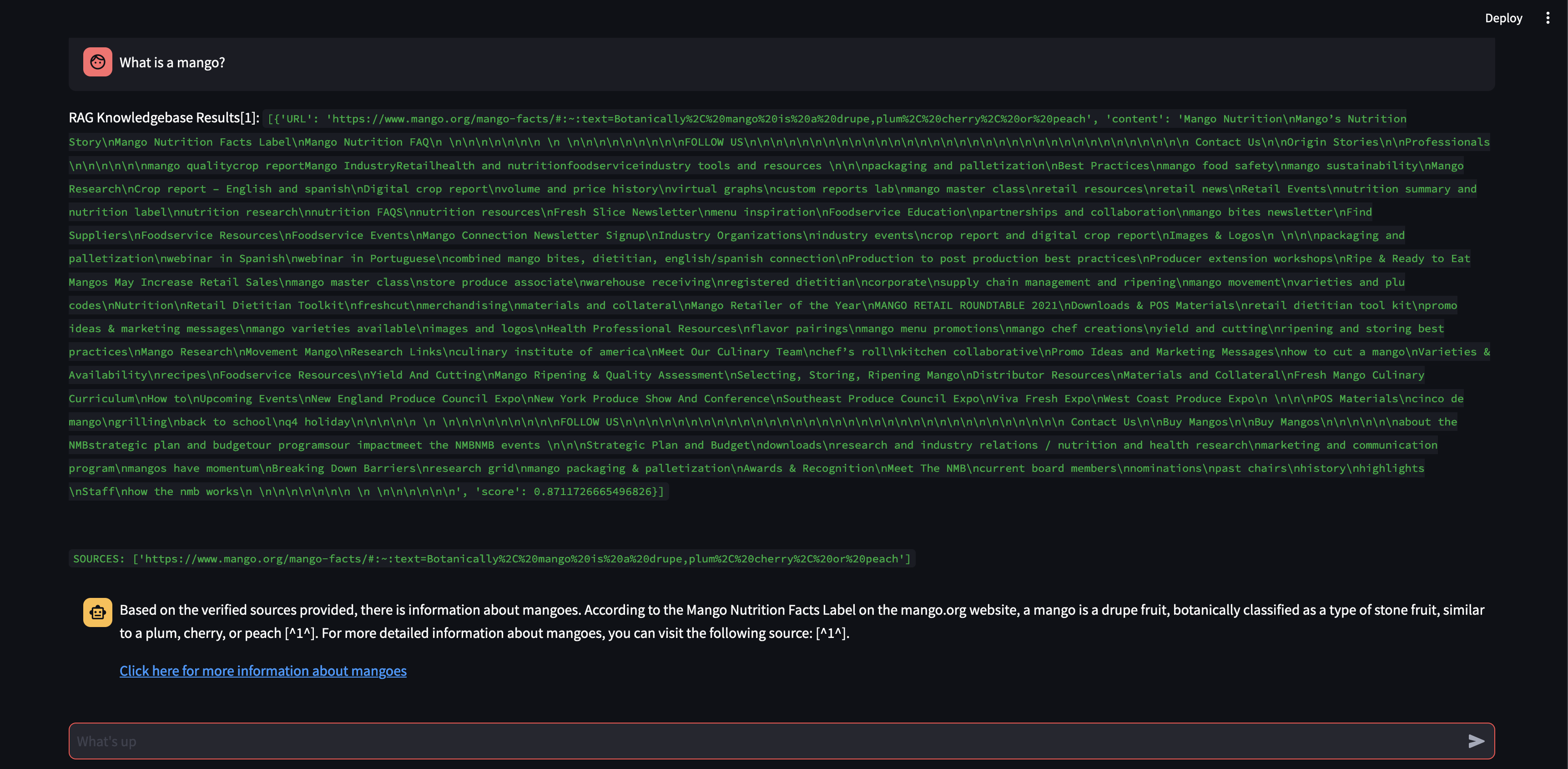
이제 더 큰 청크 크기로 벡터 데이터베이스의 지식을 사용하여 응답을 정확하게 공식화할 수 있었습니다!
다음 질문을 통해 에이전트의 지식 베이스에서 무엇을 사용할 수 있는지 살펴보겠습니다. 지식 베이스에 어떤 소스가 있습니까?
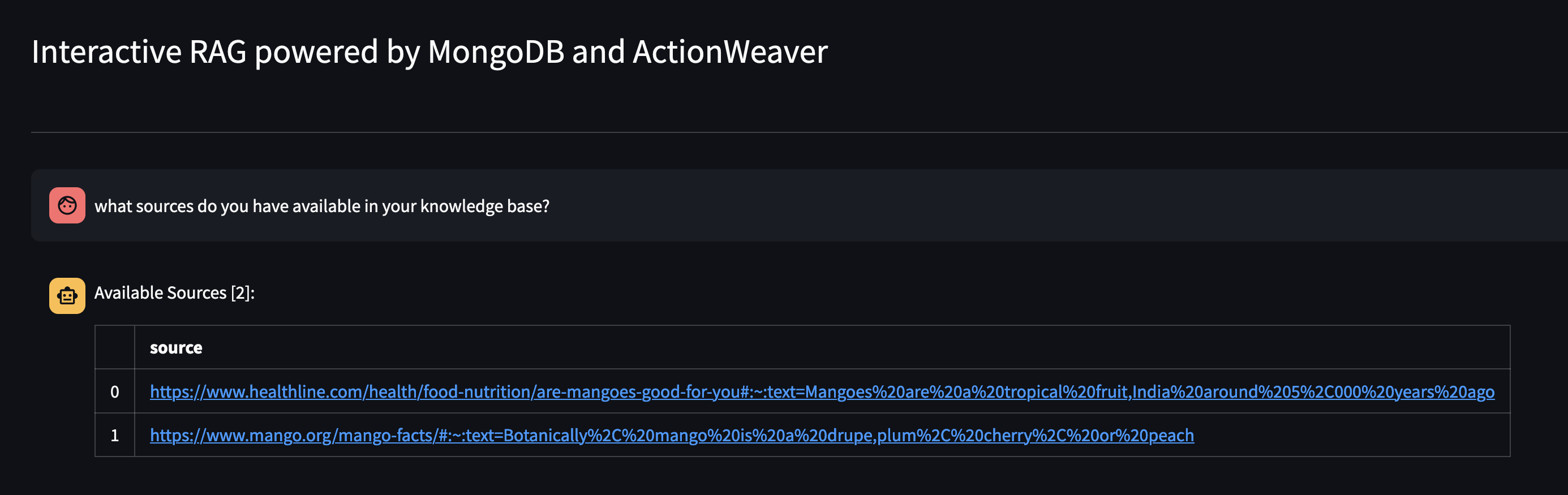
특정 리소스를 제거하려면 다음과 같이 할 수 있습니다.
USER: remove source 'https://www.oracle.com' from the knowledge base
컬렉션의 모든 소스를 제거하려면 다음과 같이 할 수 있습니다.
USER: what sources do you have in your knowledge base?
AGENT: {response}
USER: remove all those sources please
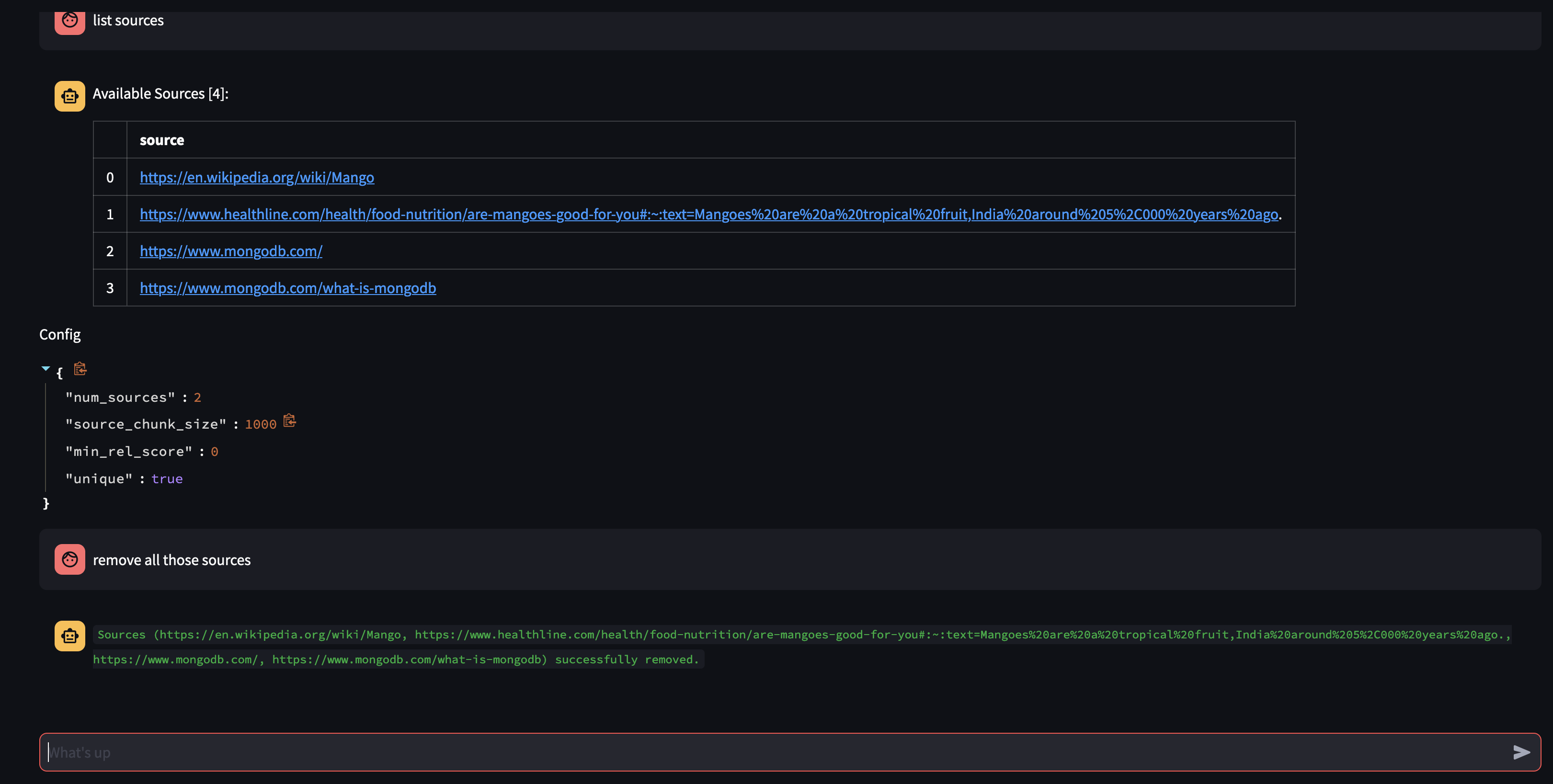
이 데모에서는 AI 에이전트의 내부 작동 방식을 엿볼 수 있으며 대화형 방식으로 사용자 쿼리를 학습하고 응답하는 능력을 보여줍니다. 우리는 내부 지식 기반과 실시간 웹 검색을 완벽하게 결합하여 포괄적이고 정확한 정보를 제공하는 방법을 목격했습니다. 이 기술의 잠재력은 단순하여 질문에 대답하는 것 이상으로 확장됩니다. Function Calling API 의 마법이 없었다면 이 중 어떤 것도 불가능했을 것입니다.
이는 https://github.com/TengHu/Interactive-RAG에서 영감을 받았습니다.
우리는 오픈 소스 커뮤니티의 기여를 환영합니다.
아파치 라이센스 2.0


