build your local ragstack chatbot
1.0.0
로컬 추론기인 DataStax Enterprise v7과 로컬 및 개방형 대형 언어 모델인 Mistral을 사용하여 검색 증강 생성을 사용하여 자신만의 Enterprise Co-Pilot을 구축하고 배포하는 이 워크숍에 오신 것을 환영합니다.
이 저장소는 중요한 데이터를 방화벽 내에 보관하여 안전과 보안에 중점을 둡니다!
왜?
DataStax Enterprise, Astra Vector DB 또는 Apache Cassandra를 벡터 저장소로 사용하는 프로덕션 지원 애플리케이션에서 RAG 패턴을 쉽게 구현할 수 있도록 선별된 최고의 오픈 소스 소프트웨어 스택인 DataStax RAGStack을 활용합니다.
당신이 배울 내용:
? 다음 구성 요소를 프로덕션 환경에서 사용하기 위해 DataStax RAGStack을 활용하는 방법:
? Ollama를 로컬 추론 엔진으로 사용하는 방법
? Q&A 스타일 챗봇을 위한 로컬 및 개방형 LLM(대형 언어 모델)으로 Mistral을 사용하는 방법
? Streamlit을 사용하여 멋진 앱을 쉽게 배포하는 방법!
프레젠테이션 슬라이드는 여기에서 확인할 수 있습니다.
이 워크숍에서는 귀하가 다음 항목에 액세스할 수 있다고 가정합니다.
다음 단계에서는 저장소, DataStax Enterprise, Jupyter Notebook 및 Ollama가 포함된 Ollama 추론 엔진을 준비하겠습니다.
먼저, 이 저장소를 로컬 개발 노트북에 복제해야 합니다.
build-your-local-ragstack-chatbot 저장소를 엽니다.
다음과 같이 Use this template -> Ceate new repository 클릭합니다.
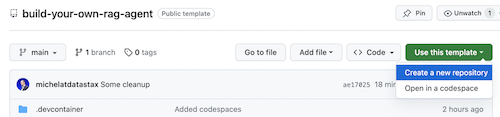
이제 github 계정을 선택하고 새 저장소의 이름을 지정하세요. 이상적으로는 설명도 설정하십시오. Create repository 클릭하세요.
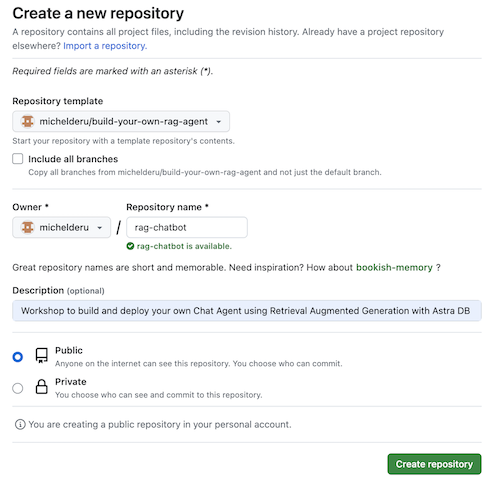
시원한! 방금 자신의 Gihub 계정에 복사본을 만들었습니다!
cd .git clone <url-to-your-repo>cd 이동하세요!이제 락앤롤을 즐길 준비가 되었습니다! ?
가상 환경을 생성하는 것이 유용합니다. 아래를 사용하여 설정하세요.
python3 -m venv myenv
그런 다음 다음과 같이 활성화하십시오.
source myenv/bin/activate # on Linux/Mac
myenvScriptsactivate.bat # on Windows
이제 필요한 패키지 설치를 시작할 수 있습니다.
pip3 install -r requirements.txt
새 터미널 창에서 다음 두 가지 방법 중 하나로 DSE 7을 실행합니다.
docker-compose up
이는 Jupyter 인터프리터를 편리하게 시작하는 이 저장소의 루트에 있는 docker-compose.yml 파일을 사용합니다.
DataStax는 http://localhost:9042에서 실행되며 Jupyter는 http://localhost:8888로 이동하여 액세스할 수 있습니다.
수많은 추론 엔진이 있습니다. UI가 좋은 LM Studio를 선택하세요. 이 노트북에서는 Ollama를 사용하겠습니다.
ollama run mistral 명령을 사용하여 Mistral(~4GB)을 다운로드하는 동안 추론 엔진을 시작합니다.RAM 제한으로 인해 이것이 모두 실패할 경우 Tinllama를 모델로 사용하도록 선택할 수 있습니다.
이 워크숍을 시작하기 위해 먼저 제공된 노트북의 개념을 시험해 보겠습니다. Jupyter Docker 컨테이너 내에서 실행한다고 가정합니다. 그렇지 않은 경우 호스트 이름을 host.docker.internal 에서 localhost 로 변경하세요.
이 노트북은 환각 없이 LLM 상호 작용을 의미 있게 만들기 위한 수단으로 DataStax Enterprise Vector Store를 사용하기 위해 취해야 할 단계를 보여줍니다. 여기서 취한 접근 방식은 검색 증강 생성(Retrieval Augmented Generation)입니다.
당신은 배울 것입니다:
http://localhost:8888로 이동하여 Build_Your_Own_RAG_Meetup.ipnb 라는 루트에서 사용할 수 있는 노트북을 엽니다.
이 워크숍에서는 프런트엔드 웹 애플리케이션을 생성하기 위해 사용하기 매우 간단한 프레임워크인 Streamlit을 사용합니다.
시작하려면 다음과 같이 hello world 애플리케이션을 만들어 보겠습니다.
import streamlit as st
# Draw a title and some markdown
st . markdown ( """# Your Enterprise Co-Pilot
Generative AI is considered to bring the next Industrial Revolution.
Why? Studies show a **37% efficiency boost** in day to day work activities!
### Security and safety
This Chatbot is safe to work with sensitive data. Why?
- First of all it makes use of [Ollama, a local inference engine](https://ollama.com);
- On top of the inference engine, we're running [Mistral, a local and open Large Language Model (LLM)](https://mistral.ai/);
- Also the LLM does not contain any sensitive or enterprise data, as there is no way to secure it in a LLM;
- Instead, your sensitive data is stored securely within the firewall inside [DataStax Enterprise v7 Vector Database](https://www.datastax.com/blog/get-started-with-the-datastax-enterprise-7-0-developer-vector-search-preview);
- And lastly, the chains are built on [RAGStack](https://www.datastax.com/products/ragstack), an enterprise version of Langchain and LLamaIndex, supported by [DataStax](https://www.datastax.com/).""" )
st . divider () 첫 번째 단계는 Streamlit 패키지를 가져오는 것입니다. 그런 다음 st.markdown 호출하여 제목을 작성하고 마지막으로 웹 페이지에 일부 내용을 작성합니다.
이 애플리케이션을 로컬에서 시작하려면 다음과 같이 streamlit 종속성을 설치해야 합니다(전제 조건의 일부로 이미 설치되어 있어야 함).
pip install streamlit이제 앱을 실행합니다.
streamlit run app_1.py그러면 애플리케이션 서버가 시작되고 방금 만든 웹 페이지로 이동하게 됩니다.
간단하지 않나요? ?
이 단계에서는 사용자와 챗봇 상호 작용을 허용하도록 앱을 준비하기 시작합니다. 우리는 다음과 같은 Streamlit 구성요소를 사용할 것입니다: 1. 2. 사용자가 질문을 입력할 수 있도록 st.chat_input 2. 사용자의 입력을 그리는 st.chat_message('human') 3. st.chat_message('assistant') 챗봇의 응답을 그리기 위해
그 결과 다음 코드가 생성됩니다.
# Draw the chat input box
if question := st . chat_input ( "What's up?" ):
# Draw the user's question
with st . chat_message ( 'human' ):
st . markdown ( question )
# Generate the answer
answer = f"""You asked: { question } """
# Draw the bot's answer
with st . chat_message ( 'assistant' ):
st . markdown ( answer ) app_2.py를 사용하여 시도해 보고 다음과 같이 시작하세요.
이전 앱이 아직 실행 중이라면 미리 ctrl-c 눌러 종료하세요.
streamlit run app_2.py이제 질문을 입력하고 다른 질문을 다시 입력하세요. 마지막 질문만 유지되는 것을 볼 수 있습니다.
왜???
이는 Streamlit이 최신 입력을 기반으로 전체 화면을 계속해서 다시 그리기 때문입니다. 질문이 기억나지 않아서 마지막 질문만 보여드립니다.
이 단계에서는 다시 그릴 때마다 기록이 표시되도록 질문과 답변을 추적합니다.
이를 위해 다음 단계를 수행합니다.
messages 라는 st.session_state 에 질문을 추가하세요.messages 라는 st.session_state 에 답변을 추가하세요.for message in st.session_state.messages 같은 루프를 사용하여 기록을 인쇄합니다. 이 접근 방식은 Streamlit 실행 전반에 걸쳐 session_state 상태 저장이기 때문에 작동합니다.
app_3.py에서 전체 코드를 확인하세요.
보시다시피 사전을 사용하여 role (인간 또는 AI일 수 있음)과 question 또는 answer 모두 저장합니다. 브라우저에 올바른 그림이 그려지므로 역할을 추적하는 것이 중요합니다.
다음을 사용하여 실행하세요.
streamlit run app_3.py이제 여러 질문을 추가하면 Streamlit이 다시 실행될 때마다 이러한 질문이 화면에 다시 그려지는 것을 볼 수 있습니다. ?
여기서는 Jupyter Notebook을 사용하여 수행한 작업으로 다시 연결하고 질문을 Mistral Chat Model 호출과 통합하겠습니다.
Streamlit은 사용자가 상호작용할 때마다 코드를 다시 실행한다는 사실을 기억하시나요? 따라서 우리는 Streamlit의 데이터 및 리소스 캐싱을 활용하여 연결이 한 번만 설정되도록 할 것입니다. 캐싱을 정의하기 위해 @st.cache_data() 및 @st.cache_resource() 사용하겠습니다. cache_data 는 일반적으로 데이터 구조에 사용됩니다. cache_resource 는 주로 데이터베이스와 같은 리소스에 사용됩니다.
결과적으로 프롬프트 및 채팅 모델을 설정하는 다음 코드가 생성됩니다.
# Cache prompt for future runs
@ st . cache_data ()
def load_prompt ():
template = """You're a helpful AI assistent tasked to answer the user's questions.
You're friendly and you answer extensively with multiple sentences. You prefer to use bulletpoints to summarize.
QUESTION:
{question}
YOUR ANSWER:"""
return ChatPromptTemplate . from_messages ([( "system" , template )])
prompt = load_prompt ()
# Cache Mistral Chat Model for future runs
@ st . cache_resource ()
def load_chat_model ():
# parameters for ollama see: https://api.python.langchain.com/en/latest/chat_models/langchain_community.chat_models.ollama.ChatOllama.html
# num_ctx is the context window size
return ChatOllama (
model = "mistral:latest" ,
num_ctx = 18192 ,
base_url = st . secrets [ 'OLLAMA_ENDPOINT' ]
)
chat_model = load_chat_model ()이전 예제에서 사용한 정적 응답 대신 이제 체인 호출로 전환하겠습니다.
# Generate the answer by calling Mistral's Chat Model
inputs = RunnableMap ({
'question' : lambda x : x [ 'question' ]
})
chain = inputs | prompt | chat_model
response = chain . invoke ({ 'question' : question })
answer = response . contentapp_4.py에서 전체 코드를 확인하세요.
계속하기 전에 ./streamlit/secrets.toml 에 OLLAMA_ENDPOINT 를 제공해야 합니다. secrets.toml.example 에 예제가 제공됩니다.
# Ollama/Mistral Endpoint
OLLAMA_ENDPOINT = " http://localhost:11434 "이 애플리케이션을 로컬에서 시작하려면 안정적인 버전의 LangChain과 모든 종속성이 포함된 RAGStack을 설치해야 합니다(전제 조건의 일부로 이미 수행되어야 함).
pip install ragstack이제 앱을 실행합니다.
streamlit run app_4.py이제 Chatbot과 질문 및 답변 상호 작용을 시작할 수 있습니다. 물론 DataStax Enterprise Vector Store와의 통합이 없으므로 상황에 맞는 답변은 없습니다. 아직 스트리밍이 내장되어 있지 않기 때문에 상담원이 한 번에 완전한 답변을 얻을 수 있도록 약간의 시간을 주세요.
질문부터 시작해 보겠습니다.
What does Daniel Radcliffe get when he turns 18?
보시다시피 CNN 데이터에서 사용할 수 있는 정보 없이도 매우 일반적인 답변을 받게 됩니다.
이제 상황이 정말 흥미로워졌습니다! 이 단계에서는 채팅 모델에 대한 컨텍스트를 실시간으로 제공하기 위해 DataStax Enterprise Vector Store를 통합합니다. 검색 증강 생성을 구현하기 위해 취한 단계:
노트북 덕분에 삽입한 CNN 데이터를 재사용하겠습니다.
이를 활성화하려면 먼저 DataStax Enterprise Vector Store에 대한 연결을 설정해야 합니다.
# Cache the DataStax Enterprise Vector Store for future runs
@ st . cache_resource ( show_spinner = 'Connecting to Datastax Enterprise v7 with Vector Support' )
def load_vector_store ():
# Connect to DSE
cluster = Cluster (
[ st . secrets [ 'DSE_ENDPOINT' ]]
)
session = cluster . connect ()
# Connect to the Vector Store
vector_store = Cassandra (
session = session ,
embedding = HuggingFaceEmbeddings (),
keyspace = st . secrets [ 'DSE_KEYSPACE' ],
table_name = st . secrets [ 'DSE_TABLE' ]
)
return vector_store
vector_store = load_vector_store ()
# Cache the Retriever for future runs
@ st . cache_resource ( show_spinner = 'Getting retriever' )
def load_retriever ():
# Get the retriever for the Chat Model
retriever = vector_store . as_retriever (
search_kwargs = { "k" : 5 }
)
return retriever
retriever = load_retriever ()우리가 해야 할 유일한 일은 벡터 저장소에 대한 호출을 포함하도록 체인을 변경하는 것입니다.
# Generate the answer by calling Mistral's Chat Model
inputs = RunnableMap ({
'context' : lambda x : retriever . get_relevant_documents ( x [ 'question' ]),
'question' : lambda x : x [ 'question' ]
})app_5.py에서 전체 코드를 확인하세요.
계속하기 전에 ./streamlit/secrets.toml 에 DSE_ENDPOINT , DSE_KEYSPACE 및 DSE_TABLE 제공해야 합니다. secrets.toml.example 에 예제가 제공됩니다.
# DataStax Enterprise Endpoint
DSE_ENDPOINT = " localhost "
DSE_KEYSPACE = " default_keyspace "
DSE_TABLE = " dse_vector_table "그리고 앱을 실행합니다.
streamlit run app_5.py다시 질문해 보겠습니다.
What does Daniel Radcliffe get when he turns 18?
보시다시피 이제 Vector Store가 관련 CNN 데이터를 채팅 모델에 제공하므로 매우 상황에 맞는 답변을 받게 됩니다.
답변이 생성되면서 화면에 표시되는 것을 보면 얼마나 멋질까요! 글쎄요, 그건 쉽습니다.
우선, 다음과 같이 새로운 토큰이 생성될 때마다 호출되는 스트리밍 콜백 핸들러를 만듭니다.
# Streaming call back handler for responses
class StreamHandler ( BaseCallbackHandler ):
def __init__ ( self , container , initial_text = "" ):
self . container = container
self . text = initial_text
def on_llm_new_token ( self , token : str , ** kwargs ):
self . text += token
self . container . markdown ( self . text + "▌" )그런 다음 StreamHandler를 사용자로 만들기 위한 채팅 모델을 설명합니다.
response = chain . invoke ({ 'question' : question }, config = { 'callbacks' : [ StreamHandler ( response_placeholder )]}) 위 코드의 response_placeholer 토큰을 작성해야 하는 위치를 정의합니다. 다음과 같이 callint st.empty() 사용하여 해당 공간을 만들 수 있습니다.
# UI placeholder to start filling with agent response
with st . chat_message ( 'assistant' ):
response_placeholder = st . empty ()app_6.py에서 전체 코드를 확인하세요.
그리고 앱을 실행합니다.
streamlit run app_6.py이제 응답이 실시간으로 브라우저 창에 기록되는 것을 볼 수 있습니다.
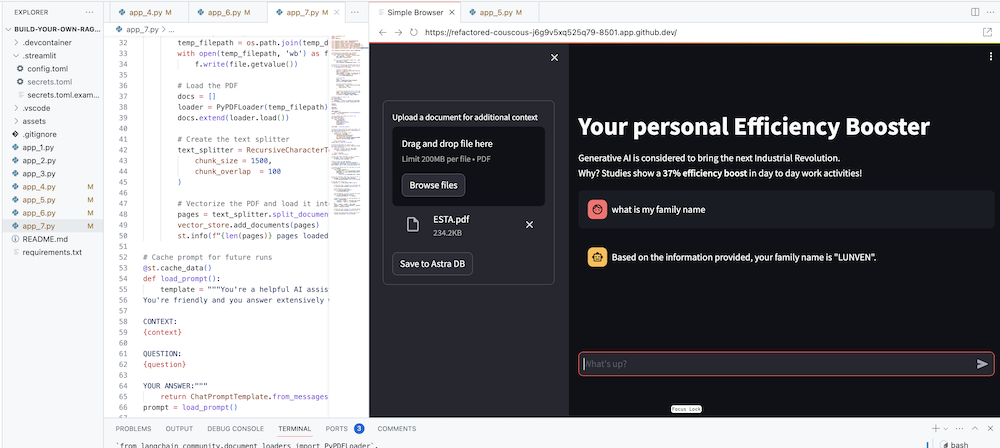
물론 궁극적인 목표는 자신의 회사의 컨텍스트를 에이전트에 추가하는 것입니다. 이를 위해 의미 있고 상황에 맞는 응답을 제공하는 데 사용되는 PDF 파일을 업로드할 수 있는 업로드 상자를 추가할 것입니다!
먼저 Streamlit으로 간단하게 만들 수 있는 업로드 양식이 필요합니다.
# Include the upload form for new data to be Vectorized
with st . sidebar :
with st . form ( 'upload' ):
uploaded_file = st . file_uploader ( 'Upload a document for additional context' , type = [ 'pdf' ])
submitted = st . form_submit_button ( 'Save to DataStax Enterprise' )
if submitted :
vectorize_text ( uploaded_file )이제 콘텐츠를 벡터화하면서 PDF를 로드하고 DataStax Enterprise에 수집하는 기능이 필요합니다.
# Function for Vectorizing uploaded data into DataStax Enterprise
def vectorize_text ( uploaded_file , vector_store ):
if uploaded_file is not None :
# Write to temporary file
temp_dir = tempfile . TemporaryDirectory ()
file = uploaded_file
temp_filepath = os . path . join ( temp_dir . name , file . name )
with open ( temp_filepath , 'wb' ) as f :
f . write ( file . getvalue ())
# Load the PDF
docs = []
loader = PyPDFLoader ( temp_filepath )
docs . extend ( loader . load ())
# Create the text splitter
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 1500 ,
chunk_overlap = 100
)
# Vectorize the PDF and load it into the DataStax Enterprise Vector Store
pages = text_splitter . split_documents ( docs )
vector_store . add_documents ( pages )
st . info ( f" { len ( pages ) } pages loaded." )app_7.py에서 전체 코드를 확인하세요.
이 애플리케이션을 로컬에서 시작하려면 다음과 같이 PyPDF 종속성을 설치해야 합니다(전제 조건의 일부로 이미 설치되어 있어야 함).
pip install pypdf그리고 앱을 실행합니다.
streamlit run app_7.py이제 귀하와 관련된 PDF 문서(더 재미있을수록)를 업로드하고 이에 대해 질문해 보세요. 답변은 관련성이 있고, 의미가 있으며, 상황에 맞는 것임을 알게 될 것입니다! ? 마법이 일어나는 걸 보세요!