files search guide
1.0.0
이 가이드의 목표는 대부분의 인기 있는 파일 및 데이터베이스에서 텍스트 정보 검색을 단순화하고 검색하기 위한 도구를 설명하는 것입니다.
이는 저널리즘 조사에 도움이 될 수 있으며 문서 유출 및 eDiscovery와 같은 대량의 데이터를 처리할 수 있습니다.
이 가이드는 다양한 형식(대형 텍스트 파일 보관, csv/sql 보관), 문서(pdf, xls/x, doc/x) 및 특수 데이터베이스(1C, Cronos 등)의 침해 검색에 적용됩니다.
영어 버전 | 러시아어 버전
Datashare - 특히 연구원과 언론인 사이에서 대용량 문서 데이터 세트를 공유하도록 설계된 ICIJ의 다중 OS 플랫폼입니다.
PDF, 이미지, 텍스트, 스프레드시트, 슬라이드 등을 검색할 수 있습니다.
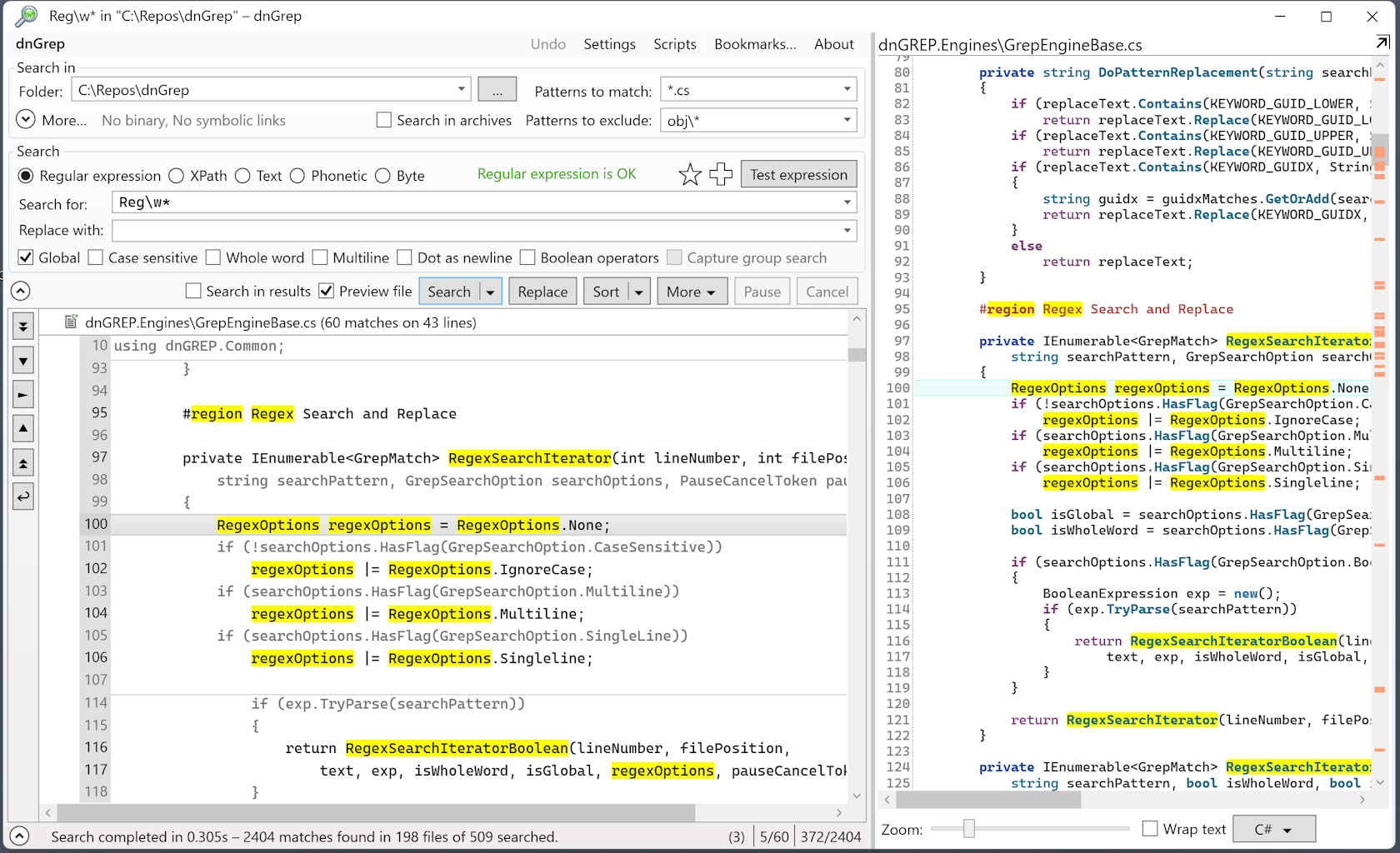
dnGrep - 텍스트 파일, 문서, PDF 및 가장 널리 사용되는 형식의 아카이브를 검색할 수 있는 Windows용 그래픽 사용자 인터페이스 도구입니다. 디렉터리의 정규식과 재귀 검색이 지원됩니다. 추가 기능: Windows 탐색기 통합!
검색 시각화에 대한 몇 가지 문제와 대규모 아카이브의 실패에도 불구하고 dnGrep은 텍스트 파일의 대량 검색을 위한 가장 관점적인 도구처럼 보입니다.
AstroGrep - 사용자가 여러 파일에서 텍스트 검색을 수행할 수 있게 해주는 Windows용 그래픽 사용자 인터페이스가 포함된 도구로, 대규모 문서 세트를 관리해야 하는 사용자에게 특히 유용합니다. 다양한 파일 형식을 지원하며 사용자 친화적인 인터페이스를 제공합니다.
AstroGrep의 주요 장점은 광범위한 파일 배열 내에서 텍스트 검색을 통해 빠른 결과를 제공하는 기능입니다. 또한 AstroGrep은 파일 내에서 검색된 용어를 강조 표시하여 검색 결과 검토 프로세스를 단순화합니다. 또한 더 복잡하고 정확한 검색을 가능하게 하는 정규식 일치와 같은 유용한 기능도 포함되어 있습니다.
그러나 AstroGrep은 주로 텍스트 검색에 중점을 두므로 해당 유틸리티는 텍스트 데이터로 제한되며 Excel 문서, 아카이브, 이미지 또는 오디오 파일 내 검색으로 확장되지 않습니다.
Google Pinpoint - 저널리스트가 대량의 정보를 관리할 수 있도록 설계된 클라우드 도구입니다. 문서(거의 모든 것을 PDF로 변환), 이미지, 오디오 파일을 포함한 다양한 파일 형식을 지원하며 효율적인 데이터 관리를 위해 Google 드라이브와 통합됩니다. 이 도구는 광범위한 데이터 세트를 통해 빠른 검색을 가능하게 하여 연구 효율성을 향상시킵니다.
Pinpoint의 장점에는 데이터 검토 프로세스를 단순화하여 시간을 절약하는 강력한 검색 기능이 포함됩니다. 또한 여러 사용자가 동일한 프로젝트에서 동시에 작업할 수 있도록 공동 작업을 지원합니다.
그러나 클라우드 기반 도구이므로 안정적인 인터넷 연결이 필요합니다.
Unix 도구 grep 검색자의 표준입니다. 검색 패턴과 파일이라는 두 가지 매개변수만 전달해야 하며, 도구는 패턴과 일치하는 행을 검색합니다. 패턴은 간단한 문자열(예: 전화번호 또는 이메일 주소)일 수 있습니다.
grep 다른 유틸리티(또는 해당 구문)에서 사용되므로 몇 가지 주요 인수를 고려해 보겠습니다.
-A number - 각 일치 후 컨텍스트의 number 줄을 인쇄합니다.
-B number - 각 일치 전에 컨텍스트의 number 줄을 인쇄합니다.
-C number - 각 일치 항목을 둘러싼 컨텍스트의 number 줄을 인쇄합니다.
-i - 대소문자를 구분하지 않는 검색: Target 및 target 단어를 검색하면 TARGET 발견됩니다.
-R - 재귀 검색: 도구가 모든 중첩 디렉터리를 검색합니다(*를 파일 이름으로 사용할 수 있음).
-a - 모든 파일을 텍스트 파일로 처리합니다. Binary file (standard input) matches 오류가 발생한 경우 사용합니다.
grep 사용법의 예:
grep -iR target dumps/* - dumps 디렉토리의 모든 텍스트 파일을 통해 target 단어(대소문자 구분 안 함)를 검색합니다.
XLSX 파일을 CSV 로 변환하고 검색에 grep 사용하거나 xlsxgrep 도구를 사용하는 것이 가장 좋습니다.
사용 예:
xlsxgrep target -H -N -r dumps/*
.gz 및 .tgz 아카이브를 검색하려면 zgrep 사용하는 것이 가장 좋습니다.
이 도구는 다음을 제외하고 grep 과 직접 유사합니다.
-R 지원되지 않습니다. zgrep 사용법의 예:
zgrep -ia target dumps/* - 모든 텍스트 파일과 디렉터리 dumps 의 gz-archives를 통해 target 단어(대소문자 구분 안 함)를 검색합니다.
7z 아카이브를 검색하려면 grep 과 함께 7zip 압축 풀기 도구를 사용하는 것이 가장 좋습니다.
사용 예:
7z x archive.7z -so | grep ...
7zip 다른 유형의 아카이브에서도 작동할 수 있습니다.
rar 아카이브를 통해 검색하려면 grep 과 함께 unrar 압축 풀기 도구를 사용하는 것이 가장 좋습니다.
사용 예:
unrar p archive.rar | grep ...
러시아에는 인기 있는 데이터베이스 소프트웨어와 파일 형식인 Cronos 있습니다. 적절한 버전의 공식 클라이언트(Cronos, CronosPlus, CronosPro)를 사용하는 것이 가장 좋습니다. 또는 cronodump 도구를 사용하여 데이터베이스를 CSV 파일로 변환할 수도 있습니다.
git clone https://github.com/alephdata/cronodump && cd cronodump
python3 setup.py install
croconvert --csv cronos_db_directory/
# a new directory will be created
ls cronodump-2022-04-25-02-53-57-293000
БТК.csv Files-FL
grep ...
러시아에는 인기있는 소프트웨어 1C가 있습니다. 1C는 .1CD, .efd 등 자체 파일 형식을 사용합니다. onec_dtools를 사용하여 1C 데이터베이스에서 모든 데이터를 추출하는 사용자 정의 스크립트를 작성하거나 1c-database-converter를 사용하여 데이터베이스를 CSV 파일로 변환할 수 있습니다.
./run.py 8-2-14.1CD
Target: 8-2-14.1CD
Results found: 1
1) Out Dir: 8-2-14.1CD_csv
File Type: 1CD
Status: Exported content of 1CD file
------------------------------
Total found: 1


