sandbox toy semantic search
1.0.0
################################################################################
# ____ _ ____ _ _ #
# / ___|___ | |__ ___ _ __ ___ / ___| __ _ _ __ __| | |__ _____ __ #
# | | / _ | '_ / _ '__/ _ ___ / _` | '_ / _` | '_ / _ / / #
# | |__| (_) | | | | __/ | | __/ ___) | (_| | | | | (_| | |_) | (_) > < #
# _______/|_| |_|___|_| ___| |____/ __,_|_| |_|__,_|_.__/ ___/_/_ #
# #
# This project is part of Cohere Sandbox, Cohere's Experimental Open Source #
# offering. This project provides a library, tooling, or demo making use of #
# the Cohere Platform. You should expect (self-)documented, high quality code #
# but be warned that this is EXPERIMENTAL. Therefore, also expect rough edges, #
# non-backwards compatible changes, or potential changes in functionality as #
# the library, tool, or demo evolves. Please consider referencing a specific #
# git commit or version if depending upon the project in any mission-critical #
# code as part of your own projects. #
# #
# Please don't hesitate to raise issues or submit pull requests, and thanks #
# for checking out this project! #
# #
################################################################################
관리자: jcudit 및 lsgos
프로젝트 유지 기간(YYYY-MM-DD): 2023-03-14
이는 Cohere API를 사용하여 간단한 의미 검색 엔진을 구축하는 방법의 예입니다. 이는 생산 준비가 되어 있거나 효율적으로 확장하기 위한 것이 아니라(이러한 목적에 맞게 조정될 수 있음) 오히려 Cohere의 LLM(대형 언어 모델)에서 생성된 표현으로 구동되는 검색 엔진 생성의 용이성을 보여주는 역할을 합니다.
여기에 사용된 검색 알고리즘은 매우 간단합니다. 단순히 co.embed 엔드포인트를 사용하여 질문 표현과 가장 근접하게 일치하는 단락을 찾습니다. 이에 대한 자세한 내용은 아래에 설명되어 있지만 여기에는 진행 상황에 대한 간단한 다이어그램이 나와 있습니다. 먼저 입력 텍스트를 일련의 단락으로 나누고 입력의 주소를 목록에 저장하고 co.embed 사용하여 각 단락에 대한 벡터 임베딩을 생성합니다.
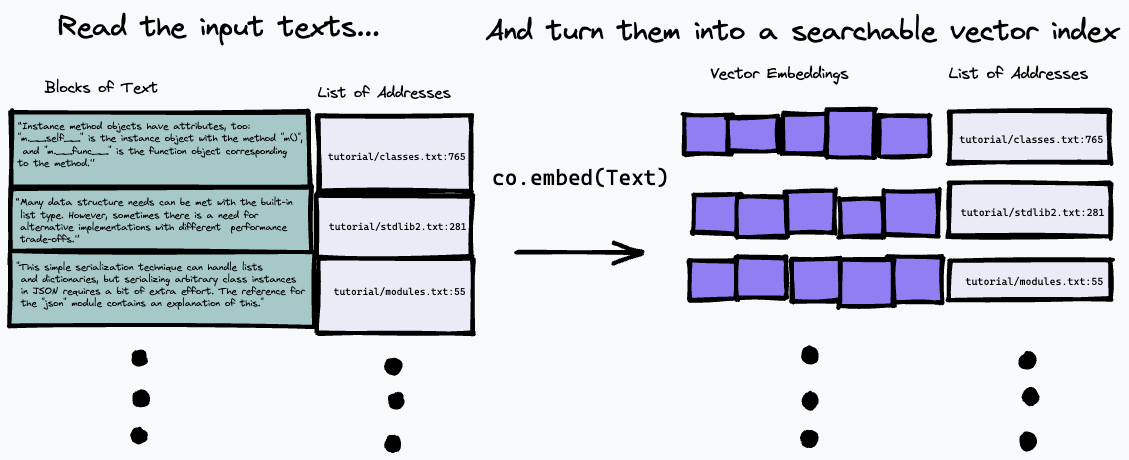
그런 다음 텍스트 쿼리를 삽입하고 벡터 유사성 측정을 사용하여 소스 텍스트에서 가장 가깝게 일치하는 단락을 찾아 인덱스를 쿼리할 수 있습니다(코사인 유사성을 사용함). 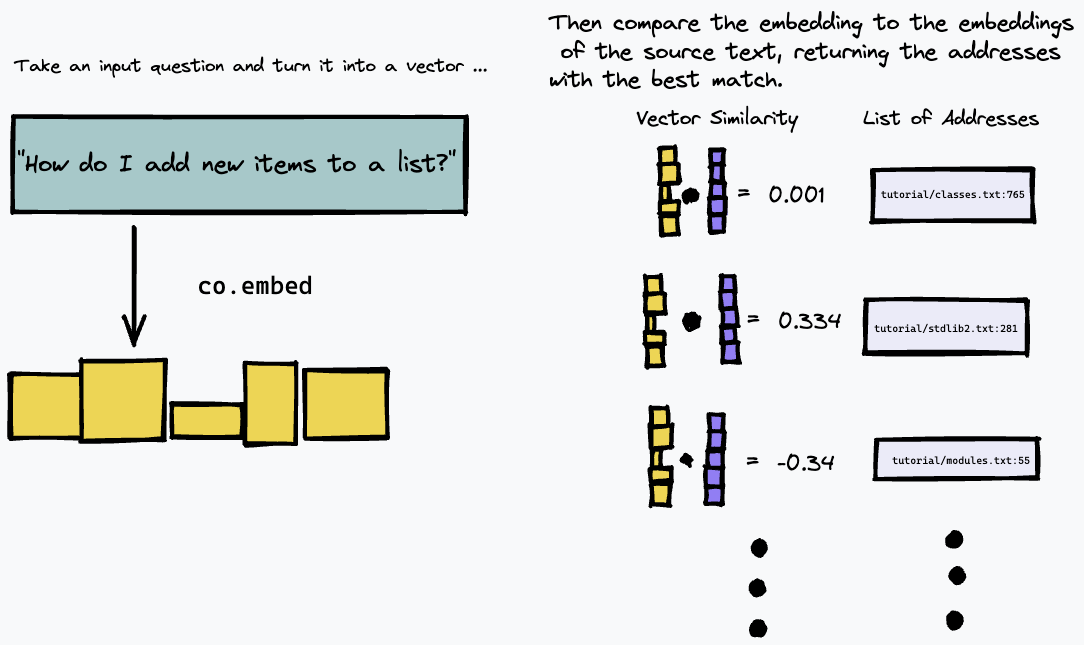
결과적으로, 특정 질문에 대한 답변이 구체적인 지침이나 사실의 목록으로 구성된 기술 문서나 내부 위키와 같이 텍스트의 구체적인 단락으로 제공될 가능성이 있는 텍스트 소스에서 가장 잘 작동합니다. 예를 들어, 정보가 여러 단락에 걸쳐 분산되어 있는 소설과 같은 자유 형식 텍스트에 대한 질문에 대답하는 경우에는 거의 잘 작동하지 않습니다. 이를 위해 텍스트를 색인화하는 다른 방법을 사용해야 합니다.
예를 들어, 이 저장소는 최신 Python 문서의 텍스트 버전에 대해 간단한 의미 체계 검색 엔진을 구축합니다.
Python 요구 사항을 설치하려면 시가 설치되어 있는지 확인하고 다음을 실행하십시오.
# install python deps
poetry install도커도 설치되어 있어야 합니다. OS X에서 홈브류를 사용하는 경우 다음을 실행하는 것이 좋습니다.
brew install --cask dockerOS X에서 처음으로 docker를 실행하기 전에(예: 서버 실행) Docker 앱을 열고 시스템에서 실행하는 데 필요한 권한을 부여하세요.
COHERE_TOKEN 에 Cohere API 키도 있어야 합니다. Cohere 플랫폼에서 하나를 가져와(필요한 경우 계정 생성) 환경에 작성합니다.
export COHERE_TOKEN= < MY_API_KEY > (여기서 <MY_API_KEY> 는 <...> 대괄호 없이 얻은 키입니다).
또는 COHERE_TOKEN=<MY_API_KEY> 아래 make 명령에 대한 추가 인수로 전달할 수 있습니다.
먼저 문서 컬렉션의 의미 색인을 구축하려면 다음 단계를 따르세요. 이러한 단계는 공식 Python 문서에 대한 의미 색인을 생성하지만 임의의 데이터 수집에 맞게 조정될 수 있습니다.
먼저 다음 명령 중 하나를 실행하여 Python 문서를 다운로드합니다.
빨리 시작하고 싶다면 다음을 실행하세요.
make download-python-docs-small문서 세트를 Python 튜토리얼로 제한합니다. 결과가 매우 제한적이므로 빠른 테스트를 위해서만 이 작업을 수행하는 것이 좋습니다 .
전체 Python 문서에 대해 검색 엔진을 테스트하려면 다음을 실행하세요.
make download-python-docs하지만 임베딩을 생성하는 데는 몇 시간이 걸린다는 점에 유의하세요(이 작업은 한 번만 수행하면 됨).
또는 자신만의 텍스트로 실험하고 싶다면 이 저장소의 txt/ 라는 디렉터리에 .txt 파일로 다운로드하면 됩니다.
텍스트가 있으면 이를 임베딩 및 주소의 검색 색인으로 처리해야 합니다.
이 작업은 명령을 사용하여 수행할 수 있습니다.
make embeddings 대상 텍스트가 ./txt/ 디렉토리에 있다고 가정합니다.
이 명령은 ./txt/ 디렉터리에서 .txt 확장자를 가진 파일을 반복적으로 검색하고 각 단락의 포함, 파일 이름 및 줄 번호에 대한 간단한 데이터베이스를 구축합니다.
경고: 검색할 텍스트가 많으면 완료하는 데 시간이 조금 걸릴 수 있습니다!
embeddings.npz 파일이 빌드되면 다음 명령을 사용하여 만든 데이터베이스를 쿼리할 수 있는 간단한 REST 앱을 제공하는 Docker 이미지를 빌드할 수 있습니다.
make build그런 다음 다음을 사용하여 서버를 시작할 수 있습니다.
make run이는 간단한 예에서는 약간 과잉이지만, 큰 텍스트 본문의 인덱스를 구축하는 것이 상대적으로 느리다는 사실을 반영하고 엔진 쿼리 속도를 빠르게 보장하도록 설계되었습니다.
이 프로젝트를 실제 애플리케이션의 빌딩 블록으로 사용하려면 서버 아키텍처에서 텍스트 임베딩 데이터베이스를 유지 관리하고 경량 클라이언트로 쿼리하는 것이 좋습니다. 서버를 Docker 애플리케이션으로 패키징한다는 것은 이를 클라우드 서비스에 배포하여 이를 '실제' 애플리케이션으로 전환하는 것이 매우 간단하다는 것을 의미합니다.
아래 옵션 중 하나에 대해 새 터미널 창을 열면 다음을 실행하는 것을 잊지 마세요.
export COHERE_TOKEN= < MY_API_KEY > 지금까지 가장 쉬운 옵션은 도우미 스크립트를 실행하는 것입니다.
scripts/ask.sh " My query here "데이터베이스를 쿼리합니다. 스크립트는 원하는 결과 수를 지정하는 선택적인 두 번째 인수를 사용합니다.
스크립트는 다음 명령을 사용하여 수정된 vim 인터페이스를 표시합니다.
q 누르세요.상단 창에는 문서에서 결과가 발견된 위치가 표시됩니다.
서버가 실행되면 간단한 REST API를 사용하여 쿼리할 수 있습니다. 여기에서 /docs#/default/search_search_post 로 이동하여 API를 직접 탐색할 수 있습니다. 이는 간단한 JSON REST API입니다. curl 사용하여 쿼리하는 방법은 다음과 같습니다.
curl -X POST -H "Content-Type: application/json" -d '{"query": "How do I append to a list?", "num_results": 3}' http://localhost:8080/search
그러면 각각 쿼리와 의미론적으로 가장 가까운 블록의 파일 이름과 줄 번호( doc_url 및 block_url )가 포함된 길이 num_results 의 JSON 목록이 반환됩니다. 하지만 실제로는 가장 좋은 답변인 파일의 일부만 읽고 싶을 수도 있습니다.
로컬 텍스트 파일을 검색할 때 실제로 명령줄 도구를 사용하여 출력을 구문 분석하는 것이 조금 더 쉽습니다. 제공된 Python 스크립트 utils/query_server.py 사용하여 명령줄에서 쿼리합니다. query_server.py 표준 file_name:line_number: 형식으로 결과를 인쇄하므로 vim 의 빠른 수정 모드를 활용하는 좋은 방법으로 실제 결과를 페이지로 이동할 수 있습니다.
컴퓨터에 vim이 있다고 가정하면 간단히 할 수 있습니다.
vim +cw -M -q <(python utils/query_server.py "my_query" --num_results 3)
vim이 검색 알고리즘에 의해 반환된 위치에서 색인화된 텍스트 파일을 열도록 합니다. (창과 Quickfix 탐색기를 모두 닫으려면 :qall 사용하세요). :cn 및 :cp 사용하여 반환된 결과를 순환할 수 있습니다. 결과는 완벽하지 않습니다. 이는 의미론적 검색이므로 일치가 약간 모호할 것으로 예상할 수 있습니다. 그럼에도 불구하고 처음 몇 가지 결과에서 질문에 대한 답을 얻을 수 있는 경우가 종종 있으며 Cohere의 API를 사용하면 질문을 자연어로 표현할 수 있으며 단 몇 줄의 코드만으로 놀랍도록 효과적인 검색 엔진을 구축할 수 있습니다.
일반적인 자연어 질문에 대해 잘 작동하는 검색을 보여주는 Python 문서 사례에서 시도해볼 만한 몇 가지 쿼리는 다음과 같습니다.
How do I put new items in a list? (이 질문은 '추가' 키워드 사용을 피하고 문서에서 추가를 설명하는 방법과 정확히 일치하지 않습니다(목록 끝에 새 항목을 추가하는 데 사용된다고 말합니다). 그러나 의미 검색은 다음을 올바르게 파악합니다. 관련 단락이 여전히 가장 일치합니다.)How do I put things in a list?Are dictionary keys in insertion order?What is the difference between a tuple and a list? (이 질문에 대한 첫 번째 결과는 기본적으로 이 정확한 주제에 대한 FAQ이지만 질문은 다르게 표현되어 있습니다. 그러나 의미론적 검색이므로 우리 알고리즘은 단지 의미가 아닌 의미와 일치하는 결과를 올바르게 선택합니다. 우리 쿼리의 표현)How do I remove an item from a set?How do list comprehensions work? 이 저장소는 매우 간단한 전략을 사용하여 문서를 색인화하고 가장 일치하는 항목을 검색합니다. 첫째, 모든 문서를 단락 또는 '블록'으로 나눕니다. 그런 다음 Cohere의 언어 모델을 사용하여 벡터 임베딩을 생성하기 위해 각 단락에서 co.embed 호출합니다. 그런 다음 각 임베딩 벡터를 해당 문서 및 단락의 줄 번호와 함께 간단한 배열에 '데이터베이스'로 저장합니다.
실제로 검색을 수행하기 위해 FAISS 유사성 검색 라이브러리를 사용합니다. 쿼리를 받으면 동일한 Cohere API 호출을 사용하여 쿼리를 삽입합니다. 그런 다음 FAISS를 사용하여 상단을 찾습니다.
질문이나 의견이 있는 경우 문제를 제기하거나 Discord를 통해 문의해 주세요.
이 프로젝트에 기여하고 싶다면 이 저장소의 CONTRIBUTORS.md 읽고 풀 요청을 제출하기 전에 기여자 라이센스 계약에 서명하세요. Cohere CLA에 서명하기 위한 링크는 Cohere 저장소에 처음 풀 요청을 할 때 생성됩니다.
Toy Semantic Search에는 LICENSE 파일에 있는 MIT 라이센스가 있습니다.


