cape webservices
1.0.0
모든 백엔드 Cape 웹 서비스의 진입점입니다.
프론트엔드 데모가 여기에 있습니다(이미 백엔드를 시작한 경우에만 작동합니다).
Cape는 문서를 자동으로 "읽어" 질문에 대답하는 질문 답변 모델을 관리하는 오픈 소스 라이브러리 모음입니다. 이는 대규모 데이터 세트에 대해 훈련된 최첨단 기계 판독 모델을 기반으로 하며 사용자 피드백을 기반으로 사용하기 쉽고 개선할 수 있는 여러 메커니즘을 포함합니다. 이는 이식 가능 하도록 설계되었습니다. 즉, 단일 랩탑이나 병렬 시스템 클러스터에서 작동하여 계산 속도를 높이고 오픈 소스 친화적 이므로 모든 전문 수준에서 사용할 수 있습니다.
이를 통해 사용자는 다음을 수행할 수 있습니다.
Cape를 사용하는 방법에는 여러 가지가 있습니다.
from cape_responder.responder_core import Responder
Responder.get_answers_from_documents('my-token','How easy is Cape to use', text ="Cape is an open source large-scale question answering system and is super easy to use!")
python3 -m cape_webservices.rundocker run -p 5050:5050 bloomsburyai/cape최소 3GB RAM과 최소 2개의 최신 CPU 코어(가상인 경우 4개)를 권장합니다. Docker를 사용하는 경우 Docker 기본 설정에서 메모리 리소스 제한을 늘려야 합니다.
관리 대시보드가 포함된 웹앱의 독립형 버전을 실행할 수 있습니다. Docker를 설치한 후 Cape 이미지를 업데이트하고 실행합니다.
docker pull bloomsburyai/cape && docker run -ti -p 5050:5050 -p 5051:5051 bloomsburyai/cape
이렇게 하면 백엔드와 프런트엔드 웹 서비스가 모두 시작되고, 기본적으로 두 가지 모두에 대한 터널도 생성되어 공개 URL이 출력됩니다.
RANDOM_STRING_HERE .ngrok.io?configuration={"api":{"backendURL":"https:// RANDOM_STRING_HERE .ngrok와 유사합니다. .io:5050","시간 초과":"15000"}} Docker 이미지의 최신 버전을 가져옵니다(모든 종속성과 기계 판독 모델을 다운로드하는 데 몇 분 정도 걸립니다): docker pull bloomsburyai/cape
Docker 컨테이너를 실행하고 다음 명령을 사용하여 그 안에서 IPython 콘솔을 시작합니다. docker run -ti -p 5050:5050 -p 5051:5051 bloomsburyai/cape ipython3
응답자 가져오기: from cape_responder.responder_core import Responder
질문을 하고 응답(답변 목록)을 저장하고 다음을 사용하여 첫 번째 답변을 표시합니다. response = Responder.get_answers_from_documents('my-token','How easy is Cape to use?', text="Cape is an open source large-scale question answering system and is super easy to use!"); print(response[0]['answerText'])
응답이 어떻게 보이는지에 대해 좀 더 이해하고 싶다면 다음을 사용하여 전체 응답을 표시하십시오. print(response)
Linux 시스템에 Cape를 기본적으로 설치하려면 배포/Dockerfile을 살펴보세요.
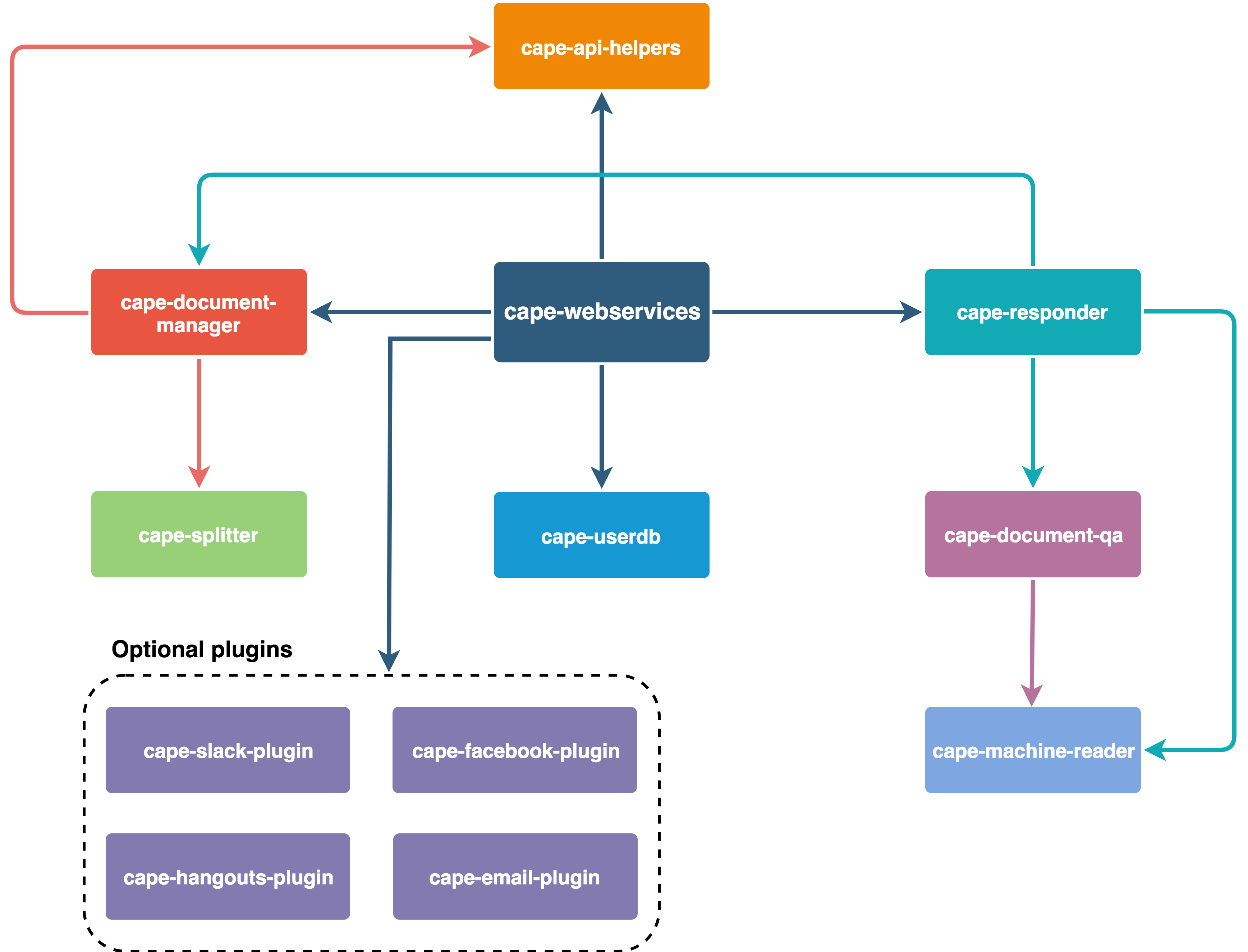
요약하면 Cape가 구성되는 방식은 다음과 같습니다.


