amazon sagemaker clip search
1.0.0
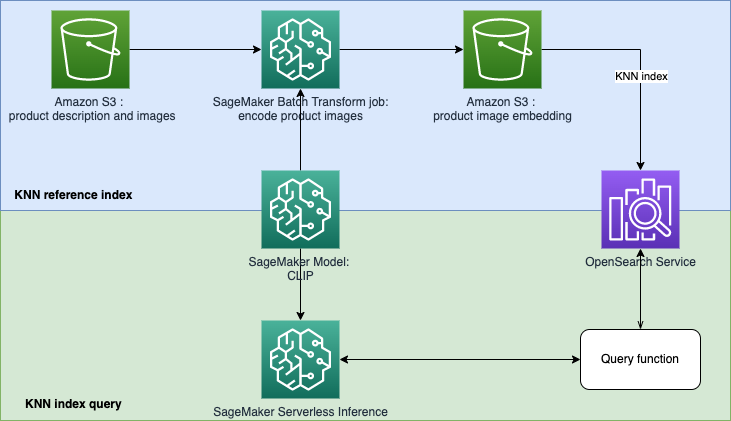
이 저장소는 텍스트 또는 이미지 쿼리를 기반으로 제품을 검색하고 추천하기 위한 기계 학습(ML) 기반 검색 엔진 프로토타입을 구축하는 것을 목표로 합니다. 이는 CLIP(Contrastive Language-Image Pre-Training)을 사용하여 SageMaker 모델을 생성하고, 모델을 사용하여 이미지와 텍스트를 임베딩으로 인코딩하고, 임베딩을 Amazon OpenSearch Service 인덱스로 수집하고, 인덱스를 쿼리하는 방법에 대한 단계별 가이드입니다. OpenSearch 서비스 KNN(k-nearest neighbor) 기능을 사용합니다.
EBR(Embedding-based retrieval)은 검색 및 추천 시스템에 잘 사용됩니다. 가장 가까운(대략적인) 이웃 검색 알고리즘을 사용하여 임베딩 저장소(벡터 데이터베이스라고도 함)에서 유사하거나 밀접하게 관련된 항목을 찾습니다. 기존 검색 메커니즘은 키워드 일치에 크게 의존하고 어휘적 의미나 쿼리 문맥을 무시합니다. EBR의 목표는 사용자에게 자유 텍스트를 사용하여 가장 관련성이 높은 제품을 찾을 수 있는 기능을 제공하는 것입니다. 이는 키워드 일치와 비교하여 검색 프로세스에서 의미론적 개념을 활용하기 때문에 인기가 있습니다.
이 저장소에서는 텍스트 또는 이미지 쿼리를 기반으로 제품을 검색하고 추천하는 기계 학습(ML) 기반 검색 엔진 프로토타입을 구축하는 데 중점을 둡니다. 여기에는 Amazon OpenSearch Service와 KNN(k-nearest neighbor) 기능, Amazon SageMaker 및 서버리스 추론 기능이 사용됩니다. Amazon SageMaker는 모든 개발자와 데이터 과학자에게 완전 관리형 인프라, 도구 및 워크플로를 통해 모든 사용 사례에 대한 ML 모델을 구축, 교육 및 배포할 수 있는 기능을 제공하는 완전 관리형 서비스입니다. Amazon OpenSearch Service는 대화형 로그 분석, 실시간 애플리케이션 모니터링, 웹 사이트 검색 등을 쉽게 수행할 수 있는 완전관리형 서비스입니다.
CLIP(Contrastive Language-Image Pre-Training)은 다양한 이미지와 텍스트 쌍에 대해 훈련된 신경망입니다. CLIP 신경망은 이미지와 텍스트를 모두 동일한 잠재 공간에 투영할 수 있습니다. 즉, 코사인 유사성과 같은 유사성 척도를 사용하여 비교할 수 있습니다. CLIP을 사용하여 제품 이미지나 설명을 임베딩으로 인코딩한 다음 이를 벡터 데이터베이스에 저장할 수 있습니다. 그런 다음 고객은 데이터베이스에서 쿼리를 수행하여 관심이 있을 수 있는 제품을 검색할 수 있습니다. 데이터베이스를 쿼리하려면 고객이 입력 이미지나 텍스트를 제공해야 하며, 입력은 KNN 검색을 위해 벡터 데이터베이스로 보내기 전에 CLIP으로 인코딩됩니다.
여기서 벡터 데이터베이스는 검색 엔진의 역할을 합니다. 이 벡터 데이터베이스는 통합 이미지와 텍스트 기반 검색을 지원하며 이는 특히 전자상거래 및 소매 산업에 유용합니다. 이미지 기반 검색의 한 가지 예는 고객이 사진을 찍어 제품을 검색한 다음 사진을 사용하여 데이터베이스에 쿼리할 수 있다는 것입니다. 텍스트 기반 검색과 관련하여 고객은 자유 형식의 텍스트로 제품을 설명하고 해당 텍스트를 쿼리로 사용할 수 있습니다. 검색 결과는 유사성 점수(코사인 유사성)에 따라 정렬됩니다. 인벤토리 항목이 쿼리(입력 이미지 또는 텍스트)와 더 유사하면 점수는 1에 더 가깝고, 그렇지 않으면 점수는 에 더 가깝습니다. 0. 검색결과 상위 K개의 상품이 귀하의 재고에서 가장 관련성이 높은 상품입니다.
OpenSearch 서비스는 KNN 기반의 텍스트 매칭 및 임베딩 검색을 제공합니다. 이 솔루션에서는 KNN 기반 검색 임베딩을 사용합니다. 이미지와 텍스트를 모두 쿼리로 사용하여 인벤토리에서 항목을 검색할 수 있습니다. 이 통합 이미지 구현 및 KNN 기반 검색 애플리케이션 테스트는 두 단계로 구성됩니다.
이 솔루션은 다음 AWS 서비스 및 기능을 사용합니다.
opensearch.yml 템플릿에서 OpenSearch 도메인을 생성하고 해당 도메인을 사용할 수 있는 SageMaker Studio 실행 역할을 부여합니다.
sagemaker-studio-opensearch.yml 템플릿에서는 새 SageMaker 도메인, 도메인의 사용자 프로필 및 OpenSearch 도메인을 생성합니다. 따라서 StageMaker 사용자 프로필을 사용하여 이 POC를 구축할 수 있습니다.
아래 나열된 단계에 따라 실행할 템플릿 중 하나를 선택할 수 있습니다.
1단계: AWS 콘솔에서 CloudFormation Service로 이동합니다. 
2단계: 템플릿을 업로드하여 CloudFormation 스택 clip-poc-stack 생성합니다.
SageMaker Studio를 이미 실행 중인 경우 opensearch.yml 템플릿을 사용할 수 있습니다. 
현재 SageMaker Studio가 없으면 sagemaker-studio-opensearch.yml 템플릿을 사용할 수 있습니다. Studio 도메인과 사용자 프로필이 생성됩니다.
3단계: CloudFormation 스택 상태를 확인합니다. 생성을 완료하는 데 약 20분이 소요됩니다. 
스택이 생성되면 SageMaker 콘솔로 이동하여 Open Studio 클릭하여 Jupyter 환경으로 들어갈 수 있습니다. 
실행 중에 CloudFormation에 OpenSearch 서비스 연결 역할을 찾을 수 없다는 오류가 표시됩니다. AWS 계정에서 aws iam create-service-linked-role --aws-service-name es.amazonaws.com 실행하여 서비스 연결 역할을 생성해야 합니다.
SageMaker Studio로 blog_clip.ipynb 파일을 열고 Data Science Python 3 커널을 사용하십시오. 처음부터 셀을 실행할 수 있습니다.
구현에는 Amazon Berkeley 객체 데이터 세트가 사용됩니다. 데이터 세트는 다국어 메타데이터와 398,212개의 고유 카탈로그 이미지가 포함된 147,702개의 제품 목록 모음입니다. 아이템 이미지와 아이템 이름은 미국 영어로만 사용됩니다. 데모 목적으로 약 1,600개의 제품을 사용하겠습니다.
이 섹션에서는 이 데모를 실행하기 위한 비용 고려 사항을 간략하게 설명합니다. POC를 완료하면 시간당 2달러 미만의 비용이 드는 OpenSearch 클러스터와 SageMaker Studio가 배포됩니다. 참고: 아래 나열된 가격은 us-east-1 지역을 사용하여 계산됩니다. 비용은 지역마다 다릅니다. 그리고 비용은 시간이 지남에 따라 변경될 수도 있습니다(여기의 가격은 2022년 11월 22일에 기록되었습니다).
자세한 비용 내역은 아래와 같습니다.
OpenSearch 서비스 – 가격은 인스턴스 유형 사용량 및 스토리지 비용에 따라 다릅니다. 자세한 내용은 Amazon OpenSearch 서비스 요금을 참조하세요.
t3.small.search 인스턴스는 시간당 $0.036의 요금으로 약 1시간 동안 실행됩니다.SageMaker – 가격은 Studio 앱, 배치 변환 작업 및 서버리스 추론 엔드포인트에 대한 EC2 인스턴스 사용량에 따라 다릅니다. 자세한 내용은 Amazon SageMaker 가격을 참조하십시오.
ml.t3.medium 인스턴스는 시간당 $0.05로 약 1시간 동안 실행됩니다.ml.c5.xlarge 인스턴스는 시간당 $0.204로 약 6분 동안 실행됩니다.S3 – 저렴한 비용, 저장된 모델/가공품의 크기에 따라 가격이 달라집니다. 매월 처음 50TB의 비용은 저장된 GB당 $0.023입니다. 자세한 내용은 Amazon S3 요금을 참조하세요.
자세한 내용은 기여를 참조하세요.
이 라이브러리는 MIT-0 라이선스에 따라 라이선스가 부여됩니다. 라이센스 파일을 참조하십시오.


