mlmm evaluation
1.0.0
다국어 대형 언어 모델을 위한 평가 프레임워크
이 리포지토리에는 다국어 대형 언어 모델(LLM)에 대한 벤치마크 데이터세트와 평가 스크립트가 포함되어 있습니다. 이러한 데이터 세트는 26개 언어로 모델을 평가하는 데 사용할 수 있으며 ARC, HellaSwag 및 MMLU의 세 가지 고유한 작업을 포함합니다. 이는 인간 피드백을 통한 강화 학습을 통해 다국어 교육 조정 LLM을 위한 Okapi 프레임워크의 일부로 출시되었습니다.
현재 우리의 데이터 세트는 러시아어, 독일어, 중국어, 프랑스어, 스페인어, 이탈리아어, 네덜란드어, 베트남어, 인도네시아어, 아랍어, 헝가리어, 루마니아어, 덴마크어, 슬로바키아어, 우크라이나어, 카탈로니아어, 세르비아어, 크로아티아어, 힌디어, 벵골어, 타밀어, 네팔어, 말라얄람어, 마라티어, 텔루구어, 칸나다어.
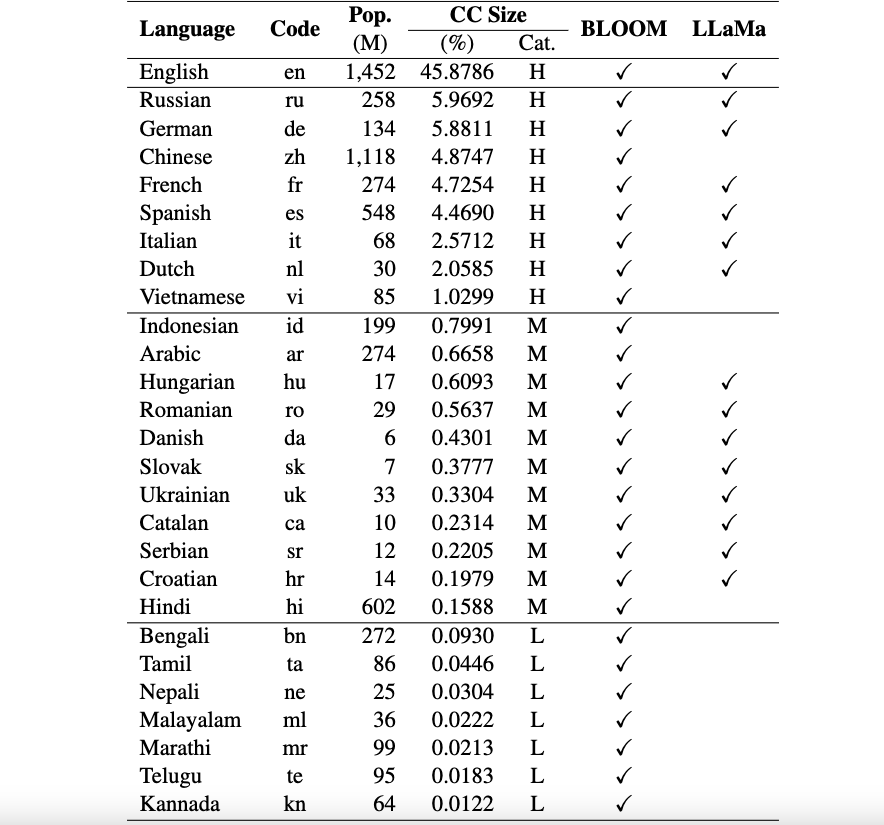
이러한 데이터세트는 원래 ARC, HellaSwag 및 MMLU 데이터세트에서 ChatGPT를 사용하여 영어로 번역되었습니다. 여러 다국어 LLM(예: BLOOM, LLaMa 및 Okapi 모델)에 대한 평가 결과와 함께 데이터 세트를 설명하는 Okapi에 대한 기술 문서를 여기에서 찾을 수 있습니다.
사용 및 라이센스 고지 사항 : 당사의 평가 프레임워크는 연구 용도로만 사용이 허가되었습니다. 데이터 세트는 CC BY NC 4.0(비상업적 사용만 허용)이므로 연구 목적 이외의 용도로 사용해서는 안 됩니다.
저장소 기본 분기에서 lm-eval 설치하려면 다음을 실행하세요.
git clone https://github.com/nlp-uoregon/mlmm-evaluation.git
cd mlmm-evaluation
pip install -e " .[multilingual] " 먼저 다음 스크립트를 사용하여 다국어 평가 데이터 세트를 다운로드해야 합니다.
bash scripts/download.sh세 가지 작업에 대해 모델을 평가하려면 다음 스크립트를 사용할 수 있습니다.
bash scripts/run.sh [LANG] [YOUR-MODEL-PATH]예를 들어 Okapi 베트남어 모델을 평가하려면 다음을 실행할 수 있습니다.
bash scripts/run.sh vi uonlp/okapi-vi-bloom우리는 다국어 LLM의 진행 상황을 추적하기 위한 리더보드를 유지 관리합니다.
우리의 프레임워크는 EleutherAI의 lm-evaluation-harness 저장소에서 대부분 상속되었습니다. 코드를 사용하는 경우 해당 저장소를 친절하게 인용해 주세요.
이 저장소의 데이터, 모델 또는 코드를 사용하는 경우 다음을 인용하십시오.
@article { dac2023okapi ,
title = { Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback } ,
author = { Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu } ,
journal = { arXiv e-prints } ,
pages = { arXiv--2307 } ,
year = { 2023 }
}

