알파카-rlhf
RLHF(인간 피드백을 통한 강화 학습)를 사용한 LLaMA 미세 조정.
온라인 데모
DeepSpeed Chat의 수정 사항
1단계
- alpaca_rlhf/deepspeed_chat/training/step1_supervised_finetuning/main.py#main()
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- 응답에 대해서만 훈련하고 EOS를 추가하세요
- end_of_conversation_token 제거
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#PromptDataset# getitem
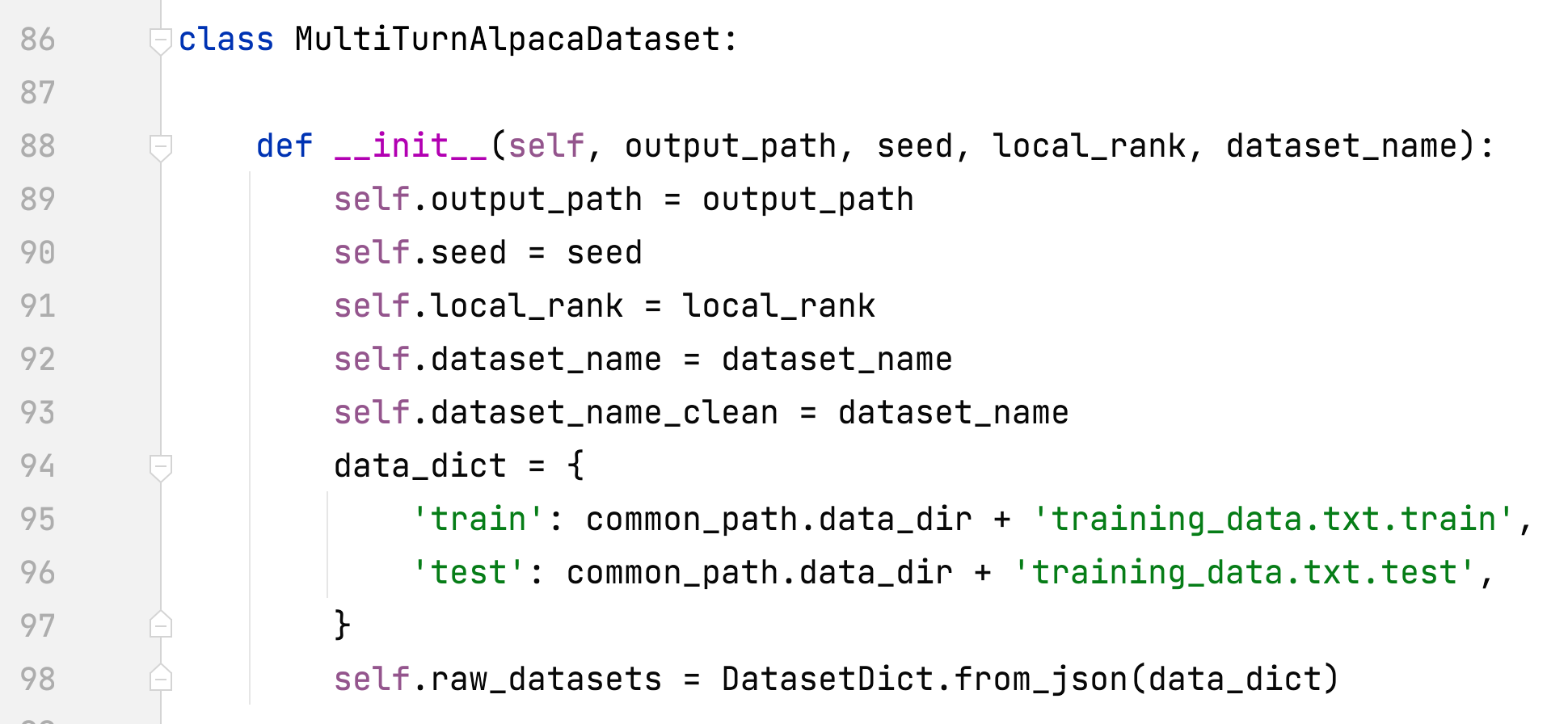
- alpaca_rlhf/deepspeed_chat/training/utils/data/raw_datasets.py#MultiTurnAlpacaDataset
- MultiTurnAlpacaDataset 추가
- alpaca_rlhf/deepspeed_chat/training/utils/module/lora.py#convert_linear_layer_to_lora
2단계
- alpaca_rlhf/deepspeed_chat/training/step2_reward_model_finetuning/main.py#main()
- alpaca_rlhf/deepspeed_chat/training/utils/model/reward_model.py#RewardModel#forward()
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- end_of_conversation_token 제거
3단계
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/main.py#main()
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#DataCollatorRLHF# 호출
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#generate_experience
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#_generate_sequence
스테이 바이 스텝
- 2개의 A100 80G에서 세 단계 모두 실행
- 데이터 세트
- Dahoas/rm-static 허깅페이스 페이퍼 GitHub
- 멀티턴알파카
- 이는 알파카 데이터세트의 다중 회전 버전이며 AlpacaDataCleaned 및 ChatAlpaca를 기반으로 구축되었습니다.
- 먼저 ./alpaca_rlhf 디렉토리를 입력한 후 다음 명령을 실행하십시오.
- 1단계: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step1_supervised_finetuning/main.py --sft_only_data_path MultiTurnAlpaca --data_output_path /root/autodl-tmp/rlhf/tmp/ --model_name_or_path decapoda-research/llama-7b-hf --per_device_train_batch_size 8 --per_device_eval_batch_size 8 --max_seq_len 512 --learning_rate 3e-4 --num_train_epochs 1 --gradient_accumulation_steps 8 --num_warmup_steps 100 --output_dir /root/autodl-tmp/rlhf /배우 --lora_dim 8 --lora_module_name q_proj,k_proj --only_optimize_lora --deepspeed --zero_stage 2
- --sft_only_data_path MultiTurnAlpaca가 추가되면 먼저 data/data.zip의 압축을 풀어주세요.
- 2단계: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step2_reward_model_finetuning/main.py --data_output_path /root/autodl-tmp/rlhf/tmp/ --model_name_or_path decapoda-research/llama-7b -hf --num_padding_at_beginning 0 --per_device_train_batch_size 4 --per_device_eval_batch_size 64 --learning_rate 5e-4 --num_train_epochs 1 --gradient_accumulation_steps 1 --num_warmup_steps 0 --zero_stage 2 --deepspeed --output_dir /root/autodl-tmp/rlhf/critic --lora_dim 8 --lora_module_name q_proj,k_proj --only_optimize_lora
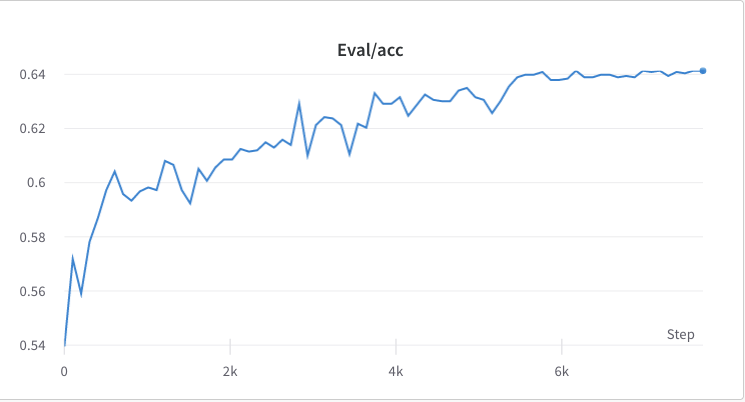
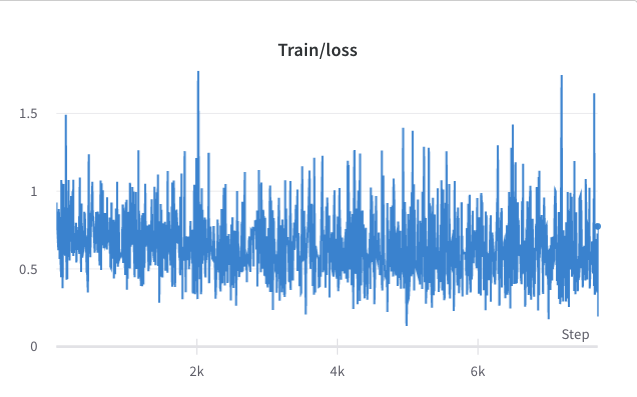
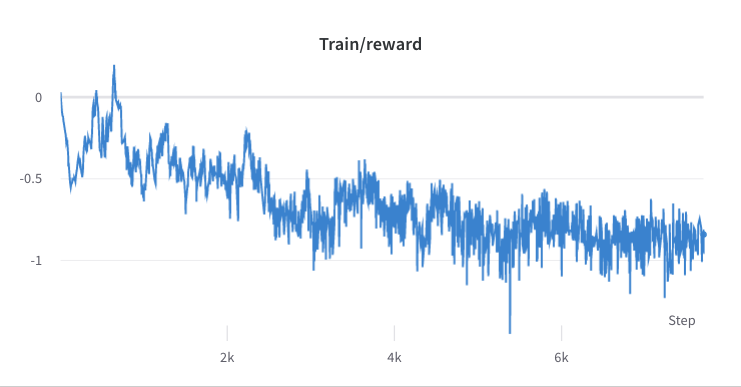
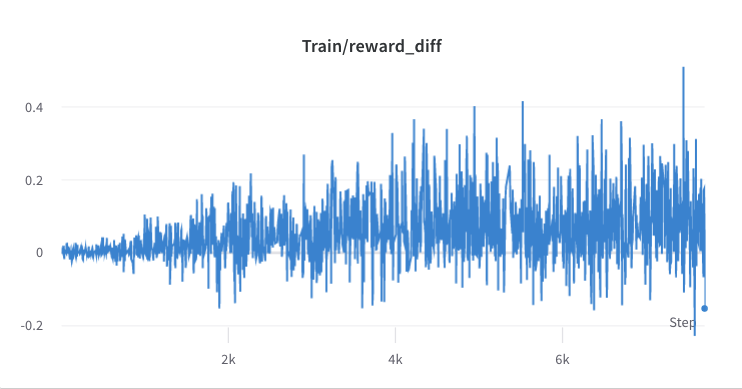
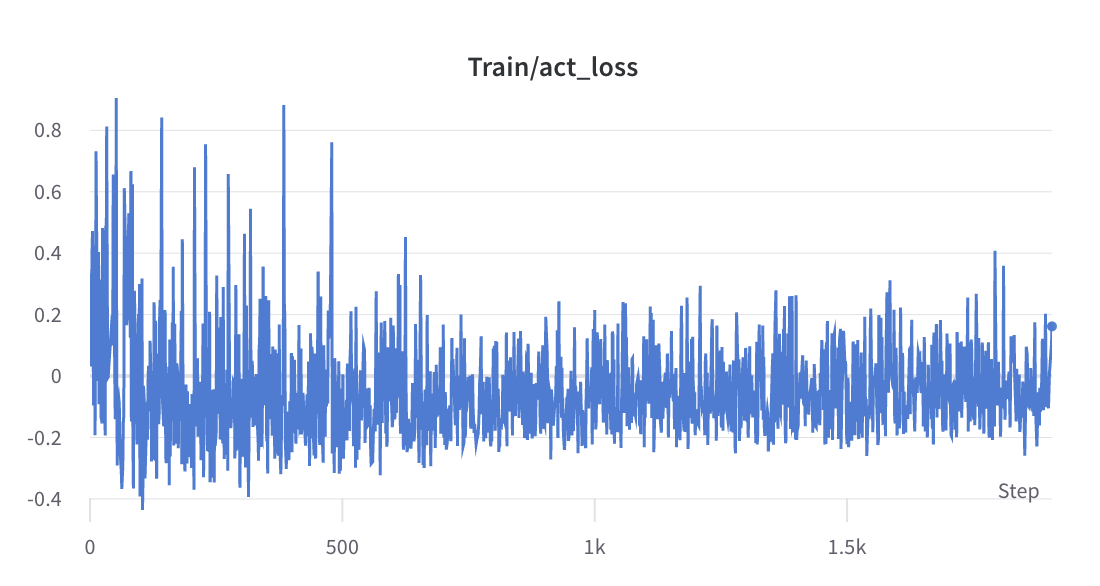
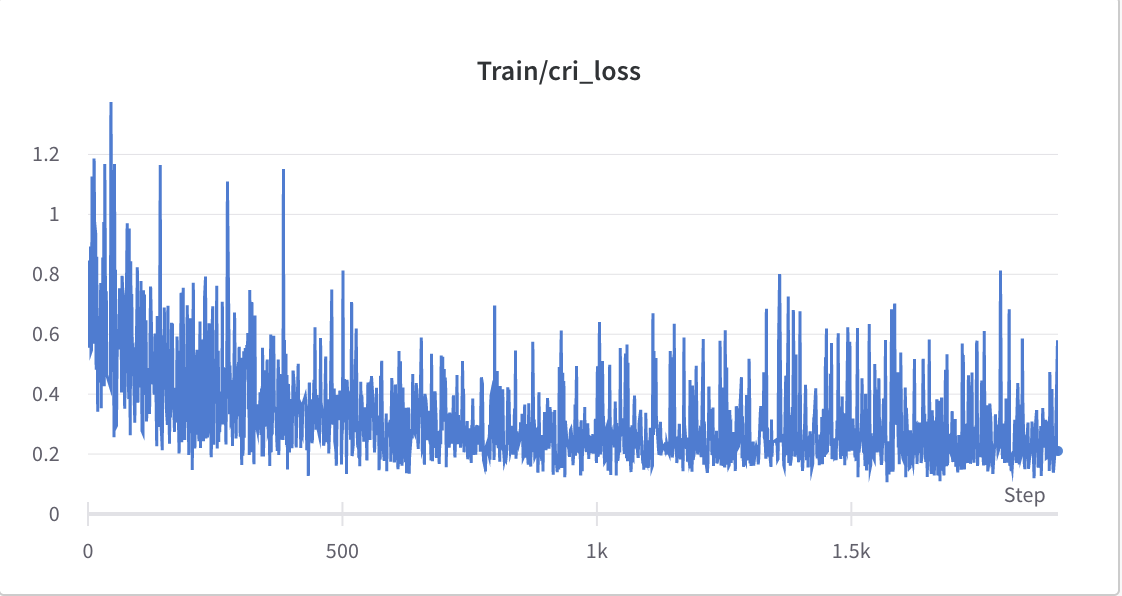
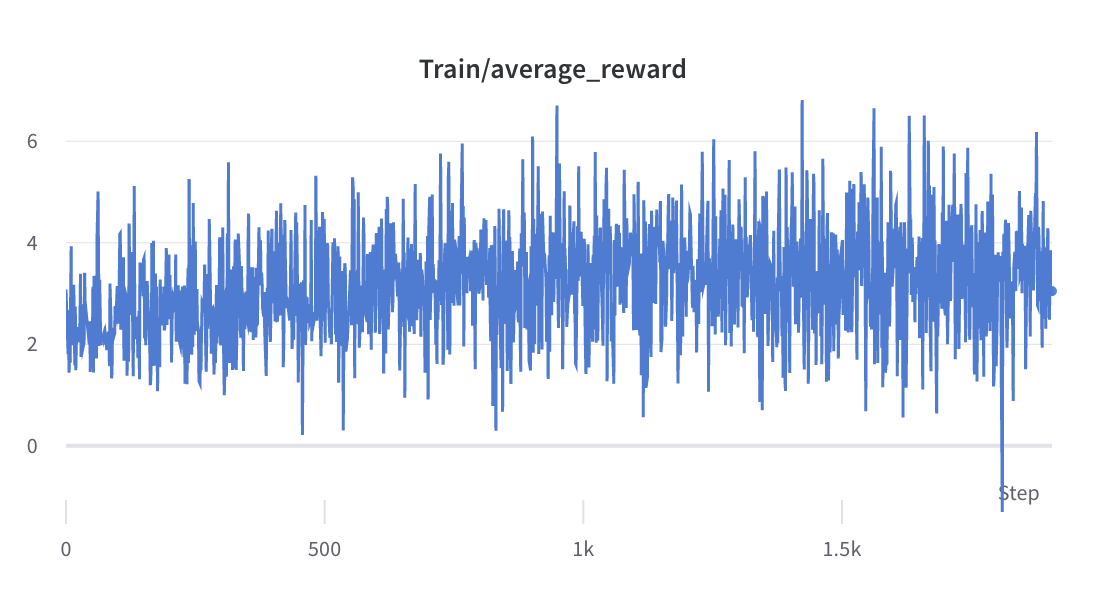
- 2단계 훈련 과정
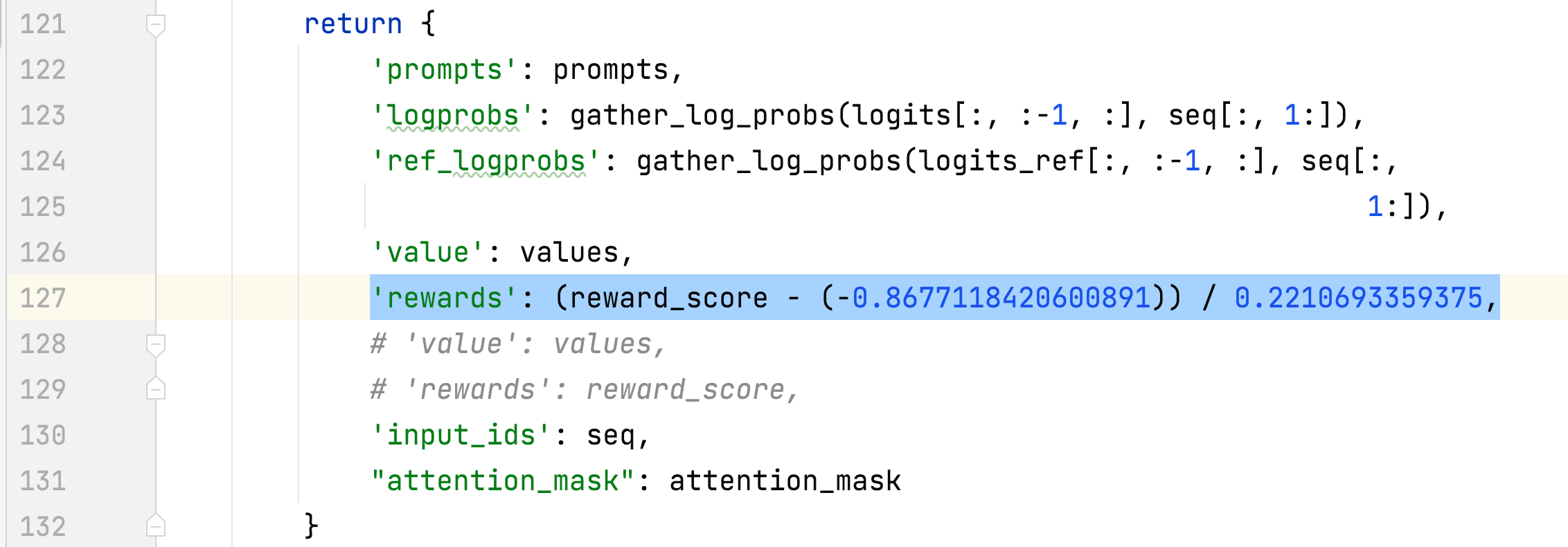
- 선택한 응답의 보상에 대한 평균 및 표준 편차가 수집되어 3단계에서 보상을 정규화하는 데 사용됩니다. 한 실험에서는 각각 -0.8677118420600891 및 0.2210693359375이며 다음에서 사용됩니다. alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#generate_experience 방법: '보상': (reward_score - (-0.8677118420600891)) / 0.2210693359375.
- 3단계: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/main.py --data_output_path /root/autodl-tmp/rlhf/tmp/ --actor_model_name_or_path /root/autodl-tmp/ rlhf/배우/ --tokenizer_name_or_path decapoda-research/llama-7b-hf --critic_model_name_or_path /root/autodl-tmp/rlhf/critic --actor_zero_stage 2 --critic_zero_stage 2 --num_padding_at_beginning 0 --per_device_train_batch_size 4 --per_device_mini_train_batch_size 4 --ppo_epochs 2 --actor_learning_rate 9.65e-6 --critic_learning_rate 5e-6 --gradient_accumulation_steps 1 --deepspeed --actor_lora_dim 8 --actor_lora_module_name q_proj --critic_lora_dim 8 --critic_lora_module_name q_proj,k_proj --only_optimize_lora --output_dir /root/autodl-tmp/rlhf/final
- 추론
- nohup sh run_inference.sh 0 alpaca_rlhf/inference/llama_chatbot_gradio.py --path /root/autodl-tmp/rlhf/final/actor > rlhf_inference.log 2>&1 &
- nohup sh run_inference.sh 0 alpaca_rlhf/inference/llama_chatbot_gradio.py --path /root/autodl-tmp/rlhf/actor > sft_inference.log 2>&1 &
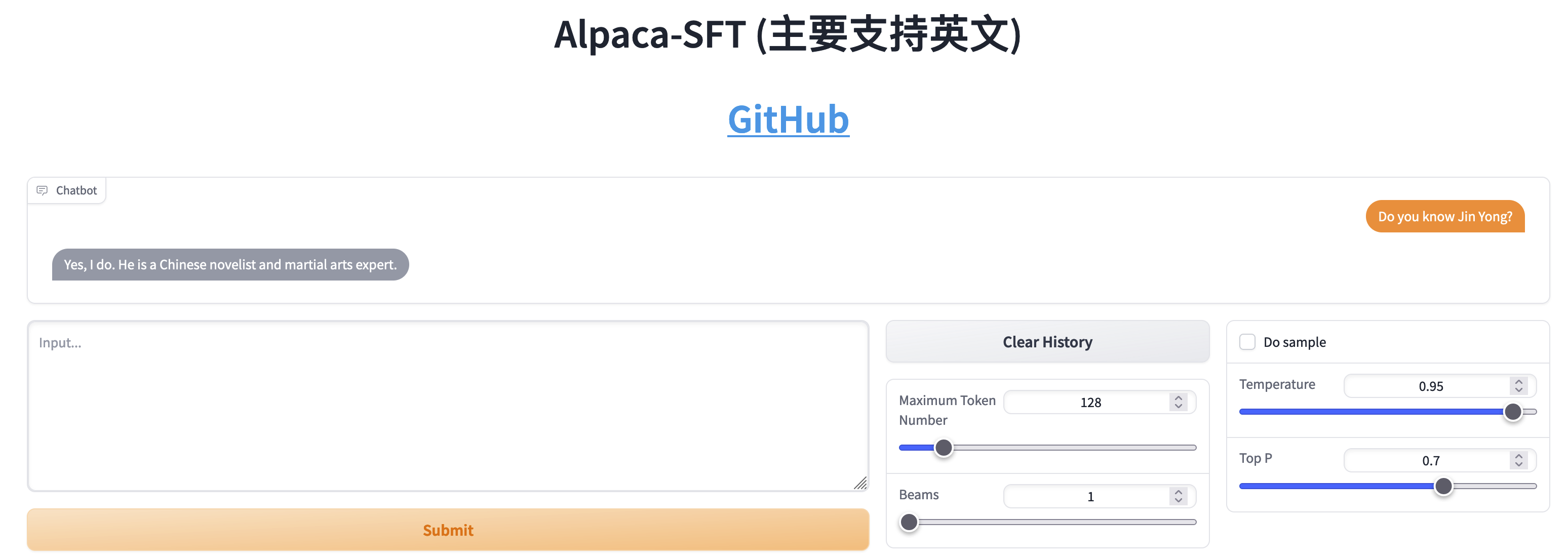
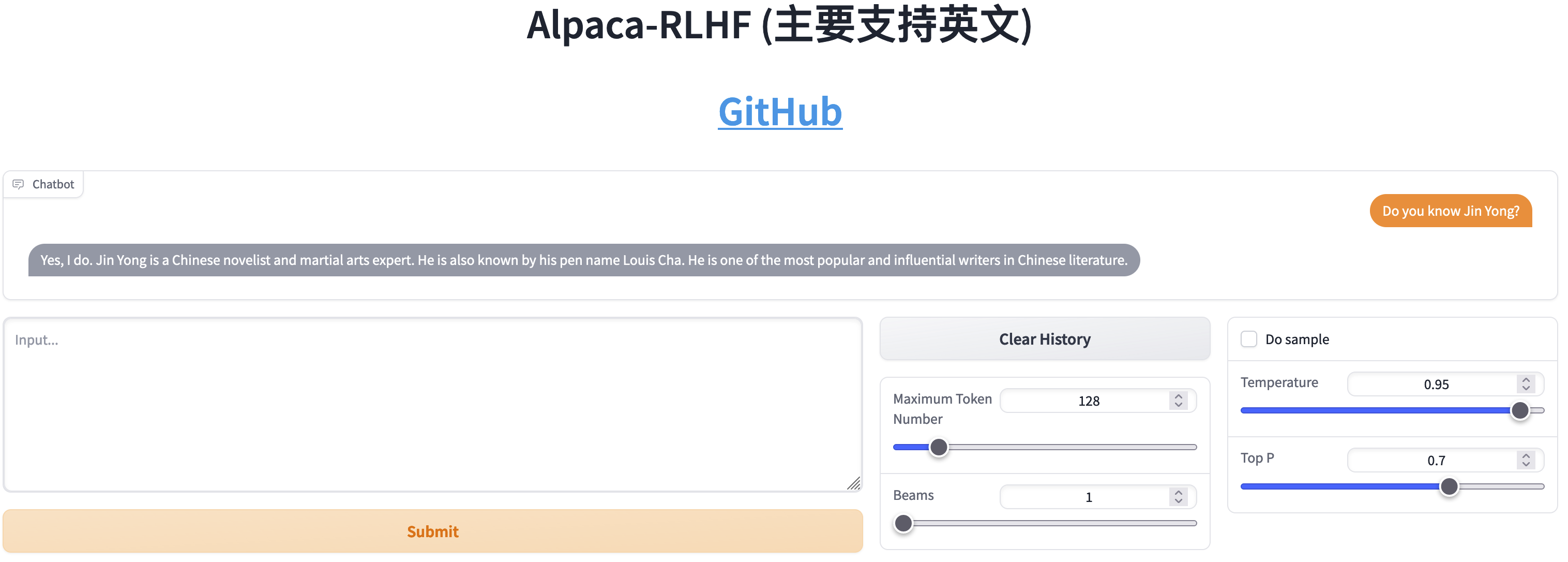
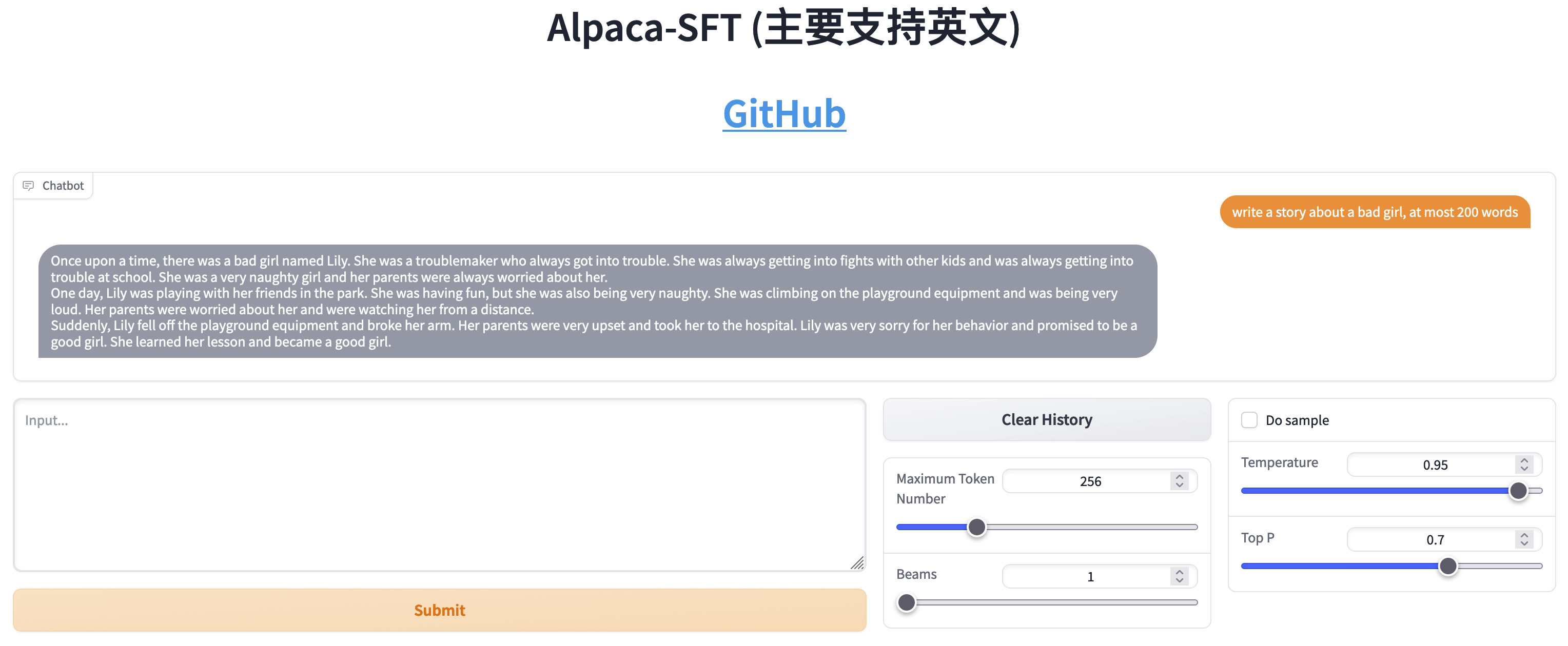
SFT와 RLHF의 비교
참고자료
조항
- 如何正确复现 GPT / RLHF를 지시하시겠습니까?
- 影响PPO算法性能的10个关键技巧(附PPO算法简洁Pytorch实现)
출처
도구
데이터 세트
- Stanford 인간 선호도 데이터세트(SHP)
- HH-RLHF
- hh-rlhf
- 인간 피드백을 통한 강화 학습을 통해 유용하고 무해한 보조자 훈련 [논문]
- 다호아스/정적-hh
- 다호아스/rm-static
- GPT-4-LLM
- 오픈 어시스턴트
관련 저장소