icl selective annotation
1.0.0
종이용 코드 선택적 주석으로 언어 모델이 더 향상됨
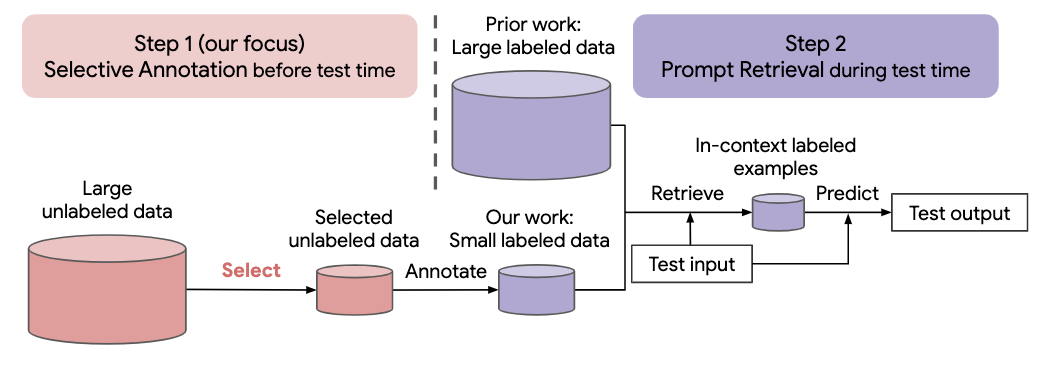
자연어 작업에 대한 최근의 많은 접근 방식은 대규모 언어 모델의 놀라운 능력을 기반으로 구축되었습니다. 대규모 언어 모델은 매개변수 업데이트 없이 몇 가지 작업 데모를 통해 새로운 작업을 학습하는 상황 내 학습을 수행할 수 있습니다. 이 작업은 새로운 자연어 작업을 위한 데이터 세트 생성에 대한 상황 내 학습의 의미를 조사합니다. 최근의 상황 내 학습 방법에서 출발하여 우리는 주석 효율적인 2단계 프레임워크를 공식화합니다. 즉, 레이블이 지정되지 않은 데이터에서 사전에 주석을 추가할 예제 풀을 선택하는 선택적 주석과 주석이 달린 풀에서 작업 예제를 검색하는 프롬프트 검색이 뒤따릅니다. 테스트 시간. 이 프레임워크를 기반으로 우리는 주석을 달기 위한 다양하고 대표적인 사례를 선택하기 위해 감독되지 않은 그래프 기반의 선택적 주석 방법인 vote-k를 제안합니다. 10개 데이터 세트(분류, 상식 추론, 대화 및 텍스트/코드 생성 포함)에 대한 광범위한 실험에서는 선택적 주석 방법이 작업 성능을 크게 향상시키는 것으로 나타났습니다. 평균적으로 vote-k는 주석을 추가할 예시를 무작위로 선택하는 것과 비교하여 주석 예산 18/100에서 12.9%/11.4%의 상대적 이득을 달성합니다. 최첨단 감독 미세 조정 접근 방식과 비교할 때 10개 작업에 걸쳐 주석 비용이 10~100배 더 적 으면서 유사한 성능을 제공합니다. 다양한 크기의 언어 모델, 대체 선택적 주석 방법, 테스트 데이터 도메인 이동이 있는 경우 등 다양한 시나리오에서 프레임워크의 효율성을 추가로 분석합니다. 대규모 언어 모델이 점점 더 새로운 작업에 적용됨에 따라 우리의 연구가 데이터 주석의 기초가 되기를 바랍니다.
이 저장소를 복제하려면 다음 명령을 실행하세요.
git clone https://github.com/HKUNLP/icl-selective-annotation
환경을 설정하려면 셸에서 다음 코드를 실행하세요.
conda env create -f selective_annotation.yml
conda activate selective_annotation
cd transformers
pip install -e .
그러면 우리가 사용한 selected_annotation 환경이 생성됩니다.
다음을 실행하여 환경을 활성화하세요.
conda activate selective_annotation
상황 내 학습 모델인 GPT-J, 태스크인 DBpedia, 선택적 주석 방법인 vote-k(1 GPU, 40GB 메모리)
python main.py --task_name dbpedia_14 --selective_annotation_method votek --model_cache_dir models --data_cache_dir datasets --output_dir outputs
우리의 작업이 도움이 되었다면 인용해 주세요.
@article{Selective_Annotation,
title={Selective Annotation Makes Language Models Better Few-Shot Learners},
author={Hongjin Su and Jungo Kasai and Chen Henry Wu and Weijia Shi and Tianlu Wang and Jiayi Xin and Rui Zhang and Mari Ostendorf and Luke Zettlemoyer and Noah A. Smith and Tao Yu},
journal={ArXiv},
year={2022},
}


