Phi2 mini Chinese
1.0.0
이 프로젝트는 오픈 소스 코드와 모델 가중치가 있고 사전 훈련 데이터가 적은 실험적인 프로젝트입니다. 더 나은 중국어 소형 모델이 필요한 경우 ChatLM-mini-English 프로젝트를 참조할 수 있습니다.
주의
이 프로젝트는 실험적인 프로젝트이며 훈련 데이터, 모델 구조, 파일 디렉터리 구조 등을 포함하여 언제든지 큰 변경이 있을 수 있습니다. 모델의 첫 번째 버전이며 tag v1.0 확인하세요.
예를 들어, 문장 끝에 마침표를 추가하거나, 번체 중국어를 중국어 간체로 변환하거나, 반복되는 구두점을 삭제하거나(예: 일부 대화 자료에 "。。。。。" 가 많이 포함되어 있음), NFKC 유니코드 표준화(주로 전체- 너비를 반 너비로 변환 및 웹 페이지 데이터 u3000 xa0) 등
구체적인 데이터 정리 프로세스는 ChatLM-mini-English 프로젝트를 참조하세요.
이 프로젝트는 byte level BPE 토크나이저를 사용합니다. 단어 분할기에 제공되는 훈련 코드에는 char level 과 byte level 의 두 가지 유형이 있습니다.
훈련 후 토크나이저는 어휘에 t , n 등과 같은 일반적인 특수 기호가 있는지 확인하는 것을 기억합니다. 특수 문자가 포함된 텍스트를 encode 및 decode 하여 복원할 수 있는지 확인할 수 있습니다. 이러한 특수 문자가 포함되지 않은 경우 add_tokens 함수를 통해 추가하세요. 어휘 크기를 얻으려면 len(tokenizer) 사용하십시오. tokenizer.vocab_size add_tokens 함수를 통해 추가된 문자를 계산하지 않습니다.
토크나이저 훈련은 많은 메모리를 소비합니다.
byte level 1억 문자를 훈련하려면 최소 32G 의 메모리가 필요합니다(실제로 32G 로는 충분하지 않으며 스왑이 자주 트리거됩니다). 13600k 훈련에는 약 1시간이 걸립니다.
6억 5천만 문자(정확히 중국어 Wikipedia의 데이터 양)의 char level 훈련에는 최소 32G의 메모리가 필요합니다. 스왑 13600K 여러 번 트리거되기 때문에 실제 사용량은 32G보다 훨씬 더 많이 걸립니다. 시간.
따라서 데이터 세트가 큰 경우(GB 수준) tokenizer 학습 시 해당 데이터 세트에서 샘플링하는 것이 좋습니다.
비지도 사전 학습에는 주로 bell open source 의 BELLE 데이터 세트를 사용하여 많은 양의 텍스트를 사용합니다.
데이터 세트 형식: 하나의 샘플에 하나의 문장이 너무 길면 잘려서 여러 샘플로 나눌 수 있습니다.
CLM 사전 훈련 과정에서 모델 입력과 출력은 동일하며, 교차 엔트로피 손실을 계산할 때 1비트만큼 이동( shift )해야 합니다.
백과사전 코퍼스 처리 시 각 항목 끝에 '[EOS]' 표시를 추가하는 것을 권장합니다. 다른 말뭉치 처리도 비슷합니다. doc 의 끝(기사의 끝일 수도 있고 문단의 끝일 수도 있음)은 '[EOS]' 로 표시되어야 합니다. 시작 표시 '[BOS]' 추가할 수 있거나 추가할 수 없습니다.
주로 bell open source 의 데이터 세트를 사용합니다. BELLE 사장님 감사합니다.
SFT 훈련의 데이터 형식은 다음과 같습니다.
text = f"##提问: n { example [ 'instruction' ] } n ##回答: n { example [ 'output' ][ EOS ]" 모델이 손실을 계산할 때 "##回答:" 표시 앞 부분을 무시합니다( "##回答:" 도 무시됩니다). "##回答:" 끝부터 시작합니다.
EOS 문장 끝 특수 표시를 추가하는 것을 잊지 마십시오. 그렇지 않으면 모델을 decode 할 때 언제 중지해야 할지 알 수 없습니다. BOS 문장 시작 표시는 채우거나 비워둘 수 있습니다.
더 간단하고 메모리 절약형 DPO 기본 설정 최적화 방법을 채택합니다.
개인 선호도에 따라 SFT 모델을 미세 조정합니다. 데이터 세트는 prompt , chosen 및 rejected 세 개의 열을 구성해야 합니다. rejected 열에는 sft 단계의 기본 모델의 일부 데이터가 있습니다(예: sft는 4개의 epoch 를 훈련합니다. 0.5 epoch 체크포인트 모델) 생성, 생성된 rejected 과 chosen 간의 유사성이 0.9보다 높으면 이 데이터가 필요하지 않습니다.
DPO 프로세스에는 두 가지 모델이 있는데, 하나는 학습할 모델이고 다른 하나는 참조 모델입니다. 로드할 때 실제로는 동일한 모델이지만 참조 모델은 매개변수 업데이트에 참여하지 않습니다.
모델 체중 huggingface 저장소: Phi2-English-0.2B
from transformers import AutoTokenizer , AutoModelForCausalLM , GenerationConfig
import torch
device = torch . device ( "cuda" ) if torch . cuda . is_available () else torch . device ( "cpu" )
tokenizer = AutoTokenizer . from_pretrained ( 'charent/Phi2-Chinese-0.2B' )
model = AutoModelForCausalLM . from_pretrained ( 'charent/Phi2-Chinese-0.2B' ). to ( device )
txt = '感冒了要怎么办?'
prompt = f"##提问: n { txt } n ##回答: n "
# greedy search
gen_conf = GenerationConfig (
num_beams = 1 ,
do_sample = False ,
max_length = 320 ,
max_new_tokens = 256 ,
no_repeat_ngram_size = 4 ,
eos_token_id = tokenizer . eos_token_id ,
pad_token_id = tokenizer . pad_token_id ,
)
tokend = tokenizer . encode_plus ( text = prompt )
input_ids , attention_mask = torch . LongTensor ([ tokend . input_ids ]). to ( device ),
torch . LongTensor ([ tokend . attention_mask ]). to ( device )
outputs = model . generate (
inputs = input_ids ,
attention_mask = attention_mask ,
generation_config = gen_conf ,
)
outs = tokenizer . decode ( outputs [ 0 ]. cpu (). numpy (), clean_up_tokenization_spaces = True , skip_special_tokens = True ,)
print ( outs ) ##提问:
感冒了要怎么办?
##回答:
感冒是由病毒引起的,感冒一般由病毒引起,以下是一些常见感冒的方法:
- 洗手,特别是在接触其他人或物品后。
- 咳嗽或打喷嚏时用纸巾或手肘遮住口鼻。
- 用手触摸口鼻,特别是喉咙和鼻子。
- 如果咳嗽或打喷嚏,可以用纸巾或手绢来遮住口鼻,但要远离其他人。
- 如果你感冒了,最好不要触摸自己的眼睛、鼻子和嘴巴。
- 在感冒期间,最好保持充足的水分和休息,以缓解身体的疲劳。
- 如果您已经感冒了,可以喝一些温水或盐水来补充体液。
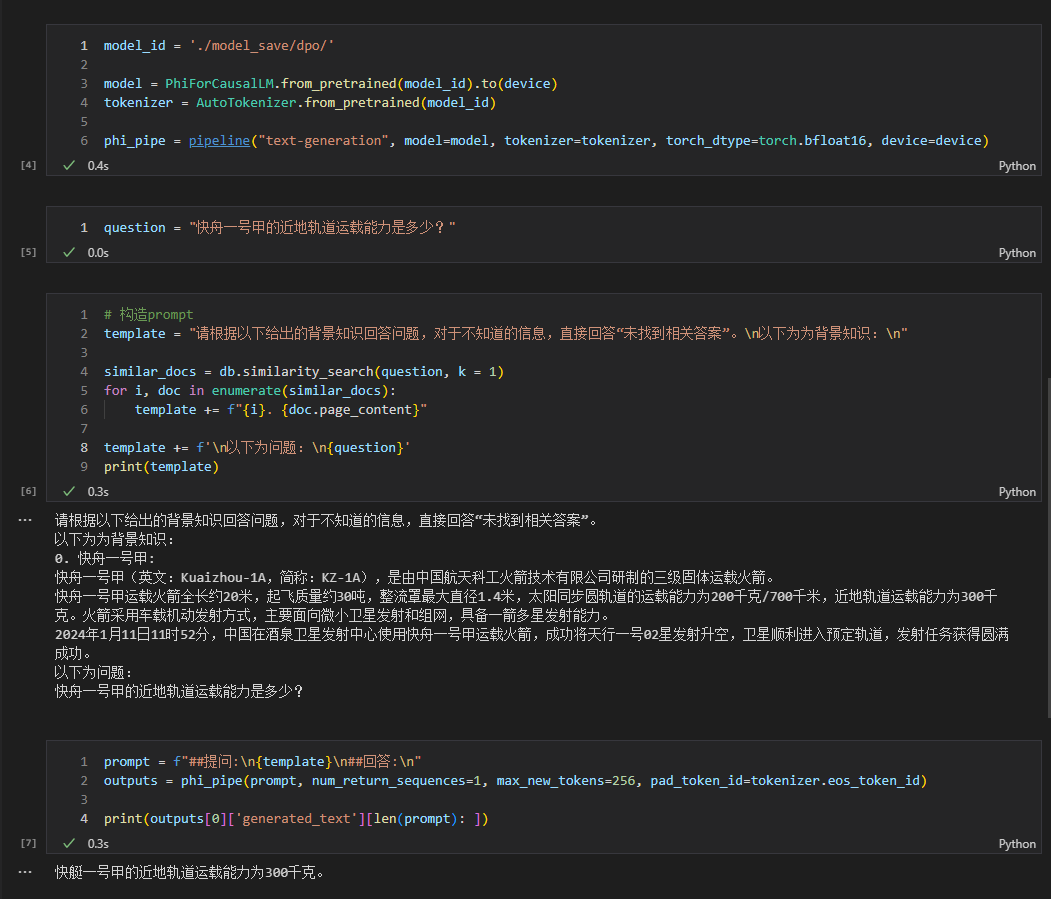
- 另外,如果感冒了,建议及时就医。 특정 코드는 rag_with_langchain.ipynb 참조하세요.
이 프로젝트가 도움이 되었다고 생각하시면 인용해 주세요.
@misc{Charent2023,
author={Charent Chen},
title={A small Chinese causal language model with 0.2B parameters base on Phi2},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/Phi2-mini-Chinese}},
}
본 프로젝트는 오픈 소스 모델 및 코드로 인해 발생하는 데이터 보안 및 여론 위험에 대한 위험과 책임을 지지 않으며, 모델이 오도, 남용, 전파 또는 부적절하게 악용되어 발생하는 위험과 책임을 지지 않습니다.


