LLaMA LoRA Tuner
v0.0.20230421
LoRA(낮은 순위 적응)를 사용하여 LLaMA 모델을 쉽게 평가하고 미세 조정할 수 있습니다.
업데이트 :
dev브랜치에는 새 모델을 시연하는 간단하고 쉬운 방법으로 새로운 채팅 UI와 새로운 데모 모드 구성이 있습니다.그러나 새 버전에는 아직 미세 조정 기능이 없으며 모델 로드 방법을 정의하는 새로운 방법과 새로운 형식의 프롬프트 템플릿(LangChain의)을 사용하므로 이전 버전과 호환되지 않습니다.
자세한 내용은 #28을 참조하세요.
LLM.Tuner.Chat.UI.in.Demo.Mode.mp4
Hugging Face 데모 보기 * UI 데모만 제공합니다. 학습이나 텍스트 생성을 시도하려면 Colab에서 실행하세요.
표준 GPU 런타임을 사용하여 Google Colab에서 한 번의 클릭으로 실행해 보세요 .
Google 드라이브에 데이터를 로드하고 저장합니다.
폴더나 Hugging Face에 저장된 다양한 LLaMA LoRA 모델을 평가해 보세요. 
decapoda-research/llama-7b-hf , nomic-ai/gpt4all-j , databricks/dolly-v2-7b , EleutherAI/gpt-j-6b 또는 EleutherAI/pythia-6.9b 와 같은 기본 모델 간에 전환합니다.
다양한 프롬프트 템플릿과 교육 데이터 세트 형식을 사용하여 LLaMA 모델을 미세 조정하세요. 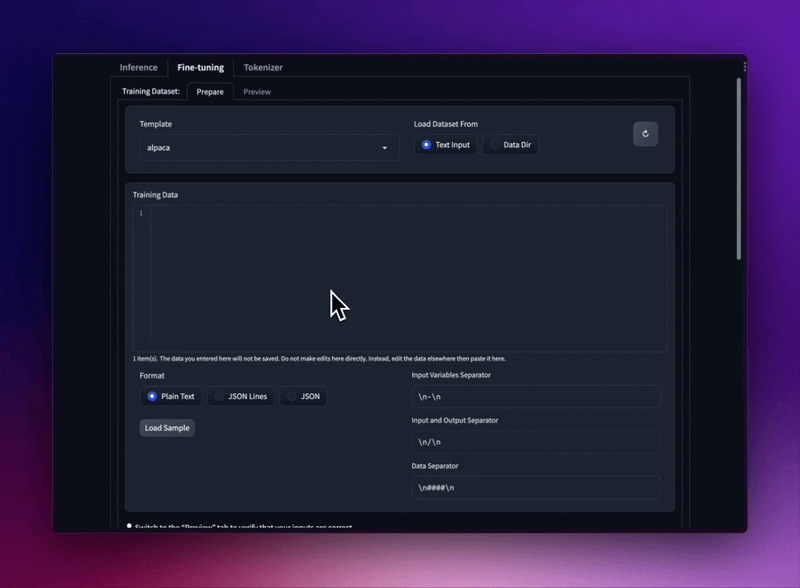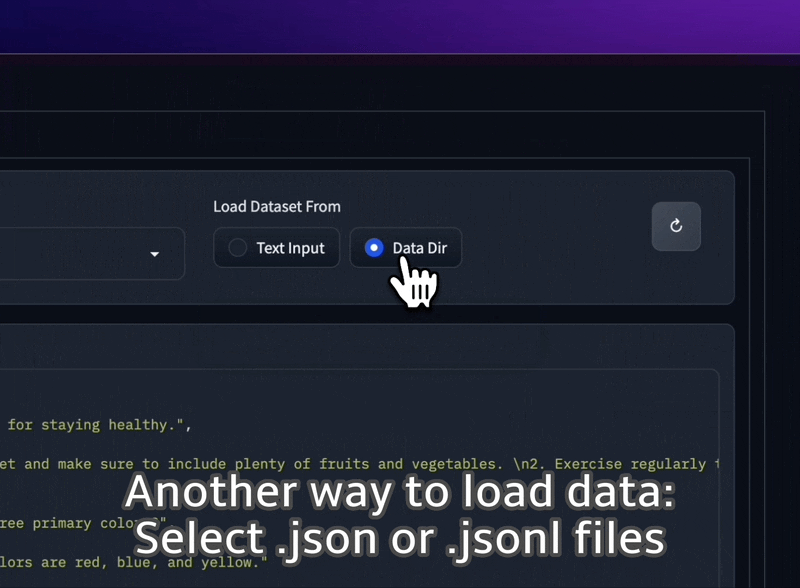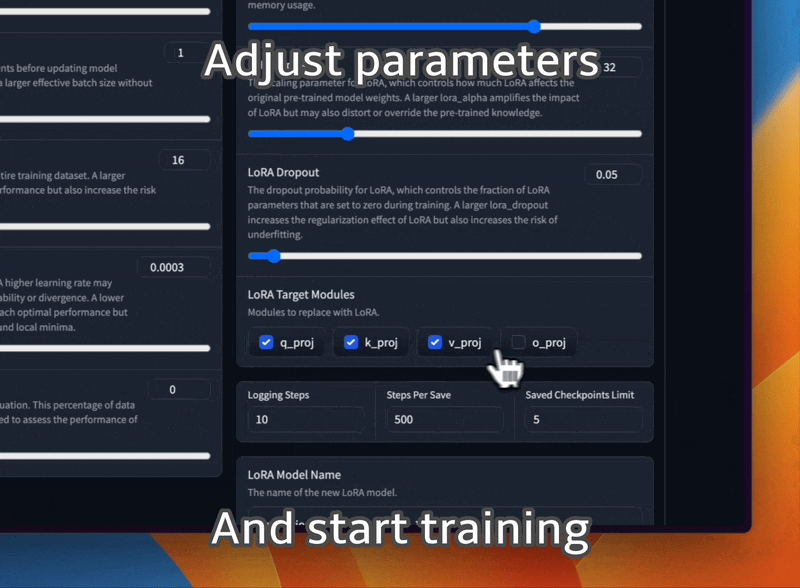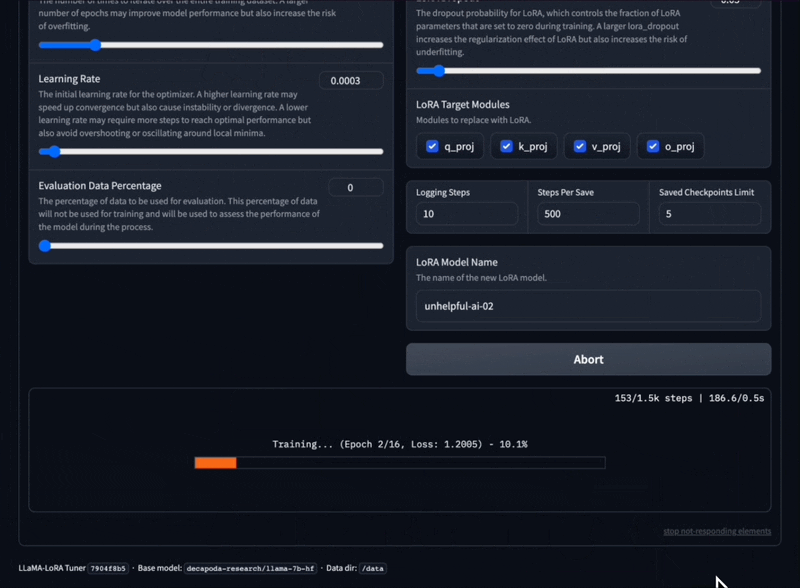
폴더에서 JSON 및 JSONL 데이터세트를 로드하거나 일반 텍스트를 UI에 직접 붙여넣을 수도 있습니다.
Stanford Alpaca seed_tasks, alpaca_data 및 OpenAI "프롬프트"-"완료" 형식을 지원합니다.
프롬프트 템플릿을 사용하여 데이터세트를 DRY로 유지하세요.
이 앱을 실행하는 방법은 다양합니다.
Google Colab에서 실행 : 시작하는 가장 간단한 방법은 Google 계정만 있으면 됩니다. 표준(무료) GPU 런타임은 마이크로 배치 크기 8로 생성 및 학습을 실행하는 데 충분합니다. 그러나 텍스트 생성 및 학습은 다른 클라우드 서비스에 비해 훨씬 느리므로 Colab은 긴 작업을 실행하는 동안 비활성 상태로 실행을 종료할 수 있습니다.
SkyPilot을 통해 클라우드 서비스에서 실행 : 클라우드 서비스(Lambda Labs, GCP, AWS 또는 Azure) 계정이 있는 경우 SkyPilot을 사용하여 클라우드 서비스에서 앱을 실행할 수 있습니다. 데이터를 보존하기 위해 클라우드 버킷을 탑재할 수 있습니다.
로컬로 실행 : 보유하고 있는 하드웨어에 따라 다릅니다.
단계별 지침은 비디오를 참조하십시오.
이 Colab 노트북을 열고 런타임 > 모두 실행 ( ⌘/Ctrl+F9 )을 선택합니다.
Google 드라이브는 데이터를 저장하는 데 사용되므로 Google 드라이브 액세스를 승인하라는 메시지가 표시됩니다. 설정 및 자세한 내용은 "구성"/"Google 드라이브" 섹션을 참조하세요.
약 5분 동안 실행하면 "Launch"/"Start Gradio UI" 섹션의 출력에 공개 URL이 표시됩니다(예: Running on public URL: https://xxxx.gradio.live ). 앱을 사용하려면 브라우저에서 URL을 엽니다.
SkyPilot 설치 가이드를 따른 후 .yaml 을 생성하여 앱 실행 작업을 정의합니다.
# llm-tuner.yamlresources: 가속기: A10:1 # 1x NVIDIA A10 GPU, Lambda Cloud에서 시간당 약 미화 0.6달러. 지원되는 GPU 유형은 'sky show-gpus'를 실행하고, GPU 유형에 대한 자세한 정보는 'sky show-gpus [GPU_NAME]'을 실행하세요.
클라우드: 람다 # 선택사항; 생략하면 SkyPilot은 자동으로 가장 저렴한 cloud.file_mounts를 선택합니다. # 데이터 디렉터리로 사용될 사전 설정된 클라우드 저장소를 마운트합니다.
# (학습 데이터세트와 훈련된 모델을 저장하기 위해)
# 자세한 내용은 https://skypilot.readthedocs.io/en/latest/reference/storage.html을 참조하세요.
/data:name: llm-tuner-data # 이 이름이 고유한지 또는 이 버킷을 소유하고 있는지 확인하세요. 존재하지 않는 경우 SkyPilot은 이 이름으로 버킷을 생성하려고 시도합니다.store: s3 # [s3, gcs]mode 중 하나일 수 있습니다: MOUNT# LLaMA-LoRA Tuner 저장소를 복제하고 해당 종속성을 설치합니다.setup: | conda create -q python=3.8 -n llm-tuner -y conda activate llm-tuner # LLaMA-LoRA Tuner 저장소를 복제하고 해당 종속성을 설치합니다. [ ! -d llm_tuner ] && git clone https://github.com/zetavg/LLaMA-LoRA-Tuner.git llm_tuner echo '종속성 설치 중...' pip install -r llm_tuner/requirements.lock.txt # 선택 사항: wandb를 다음에 설치 가중치 및 편향에 대한 로깅 활성화 pip install wandb # 선택 사항: 오류 해결을 위해 비트와 바이트를 패치합니다. "libbitsandbytes_cpu.so: 정의되지 않은 기호: cget_col_row_stats" BITSANDBYTES_LOCATION="$(pip show bitandbytes | grep 'Location' | awk '{print $2}')/bitsandbytes" [ -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" ] && [ ! -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so.bak" ] && [ -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cuda121.so" ] && echo 'GPU 지원을 위해 비트앤바이트 패치 중...' && mv "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so.bak" && cp "$BITSANDBYTES_LOCATION/libbitsandbytes_cuda121.so" "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" conda install -q cudatoolkit -y echo '종속성이 설치되었습니다.' # 선택 사항: Cloudflare Tunnel을 설치 및 설정하여 사용자 지정 도메인 이름 [ -f /data/secrets/cloudflared_tunnel_token.txt ] && echo "Installing Cloudflare" &&curl -L --output cloudflared.deb https: //github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64.deb && sudo dpkg -i cloudflared.deb && sudo cloudflared 서비스 제거 || : && sudo cloudflared service install "$(cat /data/secrets/cloudflared_tunnel_token.txt | tr -d 'n')" # 선택 사항: 사전 다운로드 모델 echo "기다릴 필요가 없도록 기본 모델을 사전 다운로드합니다. 앱이 준비되면 오랫동안..." python llm_tuner/download_base_model.py --base_model_names='decapoda-research/llama-7b-hf,nomic-ai/gpt4all-j'# 앱을 시작합니다. `hf_access_token`, `wandb_api_key` 및 `wandb_project`는 선택 사항입니다.run: | conda 활성화 llm-tuner python llm_tuner/app.py --data_dir='/data' --hf_access_token="$([ -f /data/secrets/hf_access_token.txt ] && cat /data/secrets/hf_access_token.txt | tr -d 'n')" --wandb_api_key="$([ -f /data/secrets/wandb_api_key.txt ] && cat /data/secrets/wandb_api_key.txt | tr -d 'n')" --wandb_project='llm-tuner' --timezone='대서양/레이캬비크' --base_model= 'decapoda-연구/llama-7b-hf' --base_model_choices='decapoda-research/llama-7b-hf,nomic-ai/gpt4all-j,databricks/dolly-v2-7b' --share그런 다음 클러스터를 시작하여 작업을 실행합니다.
sky launch -c llm-tuner llm-tuner.yaml
-c ... 클러스터 이름을 지정하는 선택적 플래그입니다. 지정하지 않으면 SkyPilot이 자동으로 생성합니다.
터미널에 앱의 공개 URL이 표시됩니다. 앱을 사용하려면 브라우저에서 URL을 엽니다.
sky launch 종료하면 로그 스트리밍만 종료되고 작업이 중지되지는 않습니다. sky queue --skip-finished 사용하여 실행 중이거나 보류 중인 작업의 상태를 확인하고, sky logs <cluster_name> <job_id> 로그 스트리밍에 다시 연결하고, sky cancel <cluster_name> <job_id> 사용하여 작업을 중지할 수 있습니다.
완료되면 sky stop <cluster_name> 실행하여 클러스터를 중지합니다. 대신 클러스터를 종료하려면 sky down <cluster_name> 실행하세요.
예상치 못한 비용이 발생하지 않도록 작업이 완료되면 클러스터를 중지하거나 종료하는 것을 잊지 마세요. 클러스터 비용을 확인하려면 sky cost-report 실행하세요.
클라우드 머신에 로그인하려면 ssh llm-tuner 와 같은 ssh <cluster_name> 실행하세요.
로컬 머신에 sshfs 설치되어 있는 경우 다음과 같은 명령을 실행하여 로컬 컴퓨터에 클라우드 머신의 파일 시스템을 마운트할 수 있습니다.
mkdir -p /tmp/llm_tuner_server && umount /tmp/llm_tuner_server || : && sshfs llm-tuner:/ /tmp/llm_tuner_server
conda create -y python=3.8 -n llm-tuner 콘다는 LLM-튜너를 활성화합니다
pip 설치 -r 요구사항.lock.txt python app.py --data_dir='./data' --base_model='decapoda-research/llama-7b-hf' --timezone='대서양/레이캬비크' --share
터미널에서 앱의 로컬 및 공개 URL을 볼 수 있습니다. 앱을 사용하려면 브라우저에서 URL을 엽니다.
더 많은 옵션을 보려면 python app.py --help 참조하세요.
언어 모델을 로드하지 않고 UI를 테스트하려면 --ui_dev_mode 플래그를 사용하세요.
python app.py --data_dir='./data' --base_model='decapoda-research/llama-7b-hf' --share --ui_dev_mode
Gradio Auto-Reloading을 사용하려면 명령줄 인수가 지원되지 않으므로
config.yaml파일이 필요합니다. 시작할 수 있는 샘플 파일은cp config.yaml.sample config.yaml입니다. 그런 다음gradio app.py실행하세요.
YouTube에서 동영상을 참조하세요.
https://github.com/tloen/alpaca-lora
https://github.com/lxe/simple-llama-finetuner
...
미정


