http connection lifecycle
1.0.0
목차
기술 인터뷰 등에서 자주 묻는 질문은 브라우저에 URL을 입력하면 어떻게 됩니까?입니다. 웹사이트를 서핑할 때 뒤에서 무슨 일이 일어나나요? 일반적인 HTTP 연결 수명주기에는 무엇이 필요합니까? 나는 내가 아는 한도 내에서 이러한 질문에 답변해 드리겠습니다.
연결 프로세스를 살펴보기 전에 기본 OSI 모델(Open Systems Interconnection 모델)을 살펴보겠습니다. OSI 모델은 요청이 시작된 시스템(클라이언트)과 요청을 처리하고 응답을 다시 보내는 시스템(서버) 간의 통신을 표준화하는 개념적 모델입니다. 아래 표는 각 레이어의 중요한 특성 중 일부를 보여줍니다.
| 아니요 | 층 | 하드웨어 | 기능 | 프로토콜/앱 | 추가사항 |
|---|---|---|---|---|---|
| 7 | 애플리케이션 | 서버/PC | 애플리케이션, 사용자 인터페이스 | HTTP, SMTP, DNS | L7 헤더 |
| 6 | 프레젠테이션 | 서버/PC | 암호화 및 구문 변경 처리 | JPEG, MP3 | L6 헤더 |
| 5 | 세션 | 서버/PC | 인증, 권한, 세션 | SCP, OS 스케줄링 | L5 헤더 |
| 4 | 수송 | 방화벽 | 엔드 투 엔드 전달, 오류 제어 | TCP, UDP | L4 헤더 |
| 3 | 회로망 | 라우터 | 네트워크 주소 지정, 라우팅, 스위칭 | IP | L3 헤더 |
| 2 | 데이터링크 | 스위치 | 물리주소, 오류검출, 흐름 | 이더넷, 프레임 릴레이 | L2 헤더/트레일러 |
| 1 | 물리적 | 케이블 | 물리적 네트워크를 통해 전송된 비트 | EIA/TIA | L1 헤더 |
브라우저에 URL을 입력하고 Enter/Return 키를 누르자마자 브라우저(또는 해당 문제의 모든 클라이언트)는 URL[1]을 구문 분석하여 중요한 구성 요소를 추출합니다. 예시 URL은 다음과 같습니다.
https://www.google.com/search?q=cats
여기에서는 Google에서 고양이를 검색하고 있습니다. 위 URL에서 https:// 는 프로토콜이고 google.com www (인터넷)의 호스트이며 /search 경로 매개변수이고 ?q=cats Google에 고양이를 쿼리하고 있음을 나타내는 쿼리 문자열 매개변수입니다. 2].
이제 브라우저는 도달하려는 호스트(이 경우 google.com )에 대한 지식을 갖고 있으므로 해당 IP 주소를 얻으려고 시도합니다. ' .com' 또는 ' .org'와 같은 도메인은 우리가 쉽게 기억할 수 있도록 만들어졌습니다. 그러나 브라우저가 google.com으로 실제 요청을 보내려면 호스트의 IP 주소가 필요합니다. DNS 확인은 특정 도메인 이름에 대한 IP 주소 정보를 얻는 데 도움이 됩니다. DNS는 위 표의 애플리케이션 계층(L7)에 있습니다.
DNS 확인 단계:
$ ipconfig /displaydns 명령을 사용하거나 mac/linux에서 $ log stream --predicate 'process == "mDNSResponder"' --info 명령을 사용하여 DNS 캐시를 확인할 수 있습니다..com , .org 등은 최상위 도메인 이름입니다. 그러면 TLD 이름은 신뢰할 수 있는 이름 서버의 IP 주소를 반환합니다.$ dig google.com
; << >> DiG 9.10.6 <<>> google.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 14345
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 4, ADDITIONAL: 9
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;google.com. IN A
;; ANSWER SECTION:
google.com. 180 IN A 172.217.164.174
;; AUTHORITY SECTION:
google.com. 60552 IN NS ns1.google.com.
google.com. 60552 IN NS ns2.google.com.
google.com. 60552 IN NS ns3.google.com.
google.com. 60552 IN NS ns4.google.com.
;; ADDITIONAL SECTION:
ns1.google.com. 60438 IN A 216.239.32.10
ns1.google.com. 58273 IN AAAA 2001:4860:4802:32::a
ns2.google.com. 60438 IN A 216.239.34.10
ns2.google.com. 131763 IN AAAA 2001:4860:4802:34::a
ns3.google.com. 163770 IN A 216.239.36.10
ns3.google.com. 60541 IN AAAA 2001:4860:4802:36::a
ns4.google.com. 75597 IN A 216.239.38.10
ns4.google.com. 60541 IN AAAA 2001:4860:4802:38::a
;; Query time: 13 msec
;; SERVER: 10.4.4.10#53(10.4.4.10)
;; WHEN: Mon Jun 24 12:20:50 PDT 2019
;; MSG SIZE rcvd: 303OSI 모델의 각 계층에서 정보를 PDU(Packet Data Unit)라고 합니다. 따라서 애플리케이션 계층의 정보를 L7 PDU라고 하고, 네트워크 계층의 정보를 L3 PDU라고 합니다. 각 레이어에는 해당 레이어 헤더가 추가됩니다. 헤더는 본문 앞에 위치하며 의도한 대상에 도달하는 데 필요한 주소 지정 및 기타 데이터를 포함합니다. 반면에 데이터는 최상위 계층에서 아래쪽으로 전달됩니다. L4, L3 및 L2 헤더는 다음과 같습니다.
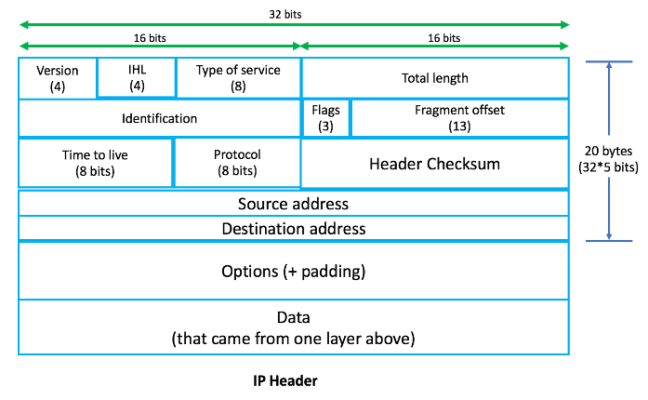
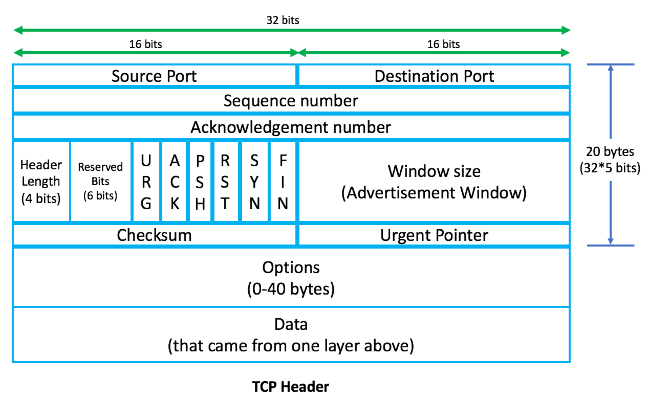
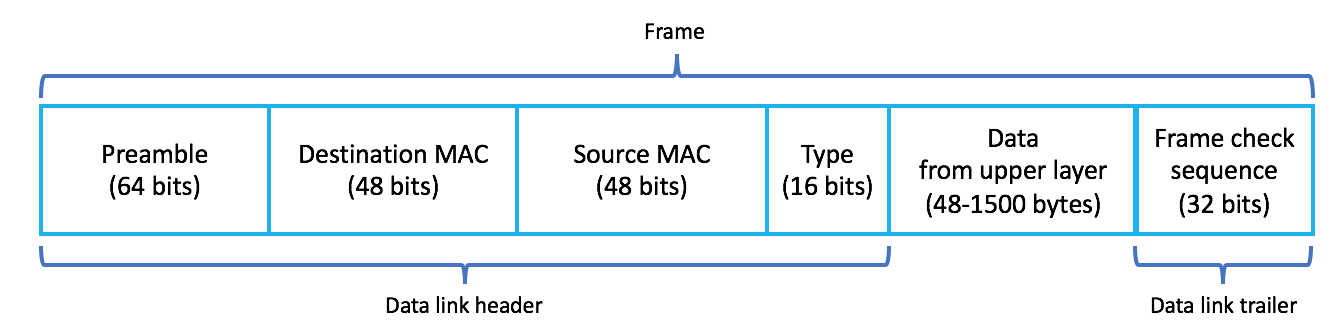
패킷이 Google 도메인 서버에 최종적으로 도달하기 위해 인터넷으로 전송되기 전에 먼저 라우터를 통해 라우팅되어야 합니다. 장치가 다른 장치(이 경우 로컬 라우터)에 물리적으로 연결해야 할 때마다 해당 장치의 MAC 주소(하드웨어 주소)가 필요합니다. 그러나 로컬 머신은 라우터가 기본 출력 경로라는 것을 어떻게 알 수 있습니까? 이 정보는 로컬 시스템 내에서 인터페이스별로 설정된 기본 경로를 통해 획득됩니다. $ ifconfig 명령을 사용하여 기본 경로를 확인할 수 있습니다.
IP 주소는 네트워크에서 장치를 찾는 데 사용되는 반면 MAC 주소는 실제 장치를 식별하는 데 사용됩니다. ARP 프로토콜은 IP 주소를 알고 있으면 장치의 MAC 주소를 획득하는 데 사용됩니다. 여기서는 요청하는 시스템이 이미 (정적으로 또는 DHCP 프로토콜을 통해) IP 주소를 수신했다고 가정합니다.
ARP는 OSI 모델의 데이터 링크 계층에 있습니다. 이 경우 로컬 컴퓨터에서 실행되는 웹 브라우저는 인터넷 게이트웨이인 라우터에 연결됩니다.
arp -a 명령을 사용하여 로컬 머신의 터미널에서 확인할 수 있습니다.그런 다음 패킷은 기본 경로로 라우팅됩니다. 기본 경로가 설정되어 있지 않으면 라우터로 라우팅됩니다. 다음 명령을 사용하여 기본 경로를 확인할 수 있습니다.
route get default | grep gateway mac/linux에서는 route get default | grep gateway 또는 netstat -rn , Windows에서는 ipconfig .
예를 들어, 192.168.10.0/24 네트워크에 있고 172.217.164.174/24에서 Google 네트워크에 연결하려고 시도하는 경우(예: 패킷이 라우터에 올 때) 라우터는 라우팅 테이블을 확인하고 트래픽을 다음으로 라우팅하는 방법을 결정합니다. 대상 네트워크에 도달합니다. 따라서 대상 172.217.164.174/24에 도달하도록 지정된 게이트웨이로 패킷을 보냅니다.
클라이언트와 서버 간의 연결; 이 경우 Google 서버에 대한 로컬 시스템은 많은 홉을 필요로 합니다. 각 홉은 본질적으로 대상 경로를 따라 있는 라우터입니다. 여기 라우터는 요청이 한 네트워크에서 다른 네트워크로 이동하는 데 도움이 됩니다. 이동 중인 모든 장치에는 전역적으로 고유한 MAC 주소(하드웨어 주소)가 있습니다.
이제 로컬 머신은 L7 헤더(HTTP), L4 헤더(TCP), L3 헤더(IP), L2 헤더(ARP, MAC 주소), L2 트레일러(프레임 확인 시퀀스) 및 실제 데이터를 사용하여 요청을 생성합니다. 라우터가 패킷을 받으면 L2 헤더/트레일러를 캡슐화 해제하고 수정한 다음 패킷을 다시 캡슐화합니다.
이제 라우터가 이를 수신하고 캡슐화 해제를 시작합니다. L2 헤더를 조사하여 대상 Mac이 자체인지 확인합니다. 이제 L2 헤더를 제거하고 L3 헤더를 조사하여 요청이 자체가 아닌 Google 서버에 대한 것임을 이해합니다. 그런 다음 라우터는 L3 헤더 내부에 있는 TTL 값을 감소시킵니다. 이제 라우터는 목적지에 도달하는 방법에 대해 다른 라우터가 (RIP 또는 IGP를 통해) 이 라우터에 광고했을 수 있는 모든 가능한 경로에 대한 라우팅 테이블을 조사합니다. 그런 다음 한 라우터는 캐시에 MAC 주소가 없는 경우 ARP를 수행하여 다음 홉 라우터의 MAC 주소를 가져옵니다.
그런 다음 라우터는 L2 트레일러에 계속되는 CRC도 추가합니다. 이는 다음 라우터가 경로에 문제가 발생하여 회선을 통해 패킷이 손상되지 않았음을 알 수 있도록 도와줍니다. 손상되면 프레임이 삭제됩니다.
이 경우 라우터는 L2 헤더와 L2 트레일러를 수정했지만 L3 헤더를 건드리지 않았으므로 그 위에 헤더가 없습니다.
소스 포트 번호 임시 포트 번호는 이고 대상 포트 번호는 80입니다.
TCP - 안정적이고 동일한 주문 서비스입니다. 로컬 머신이 가장 먼저 할 일은 서버에 대한 경로를 알고 있으므로 이제 Google 서버와 3방향 핸드셰이크를 설정하는 것입니다. 연결 설정은 MSS 크기, 초기 시퀀스 번호, ACK 유형, 버퍼 크기 등과 같은 일부 상태 변수를 마무리하는 데 도움이 됩니다.
이 경우 TCP 헤더의 소스 및 대상 포트는 16비트이므로 2^16은 65535입니다. 소스 포트는 클라이언트 애플리케이션을 식별하는 데 사용되는 반면 대상 포트는 웹 서버에서 실행되는 서비스 또는 악마를 식별하는 데 사용됩니다.
클라이언트(웹 브라우저)는 49152 - 65535에서 포트를 선택합니다. 이렇게 하면 두 응용 프로그램이 동일한 포트를 사용하지 않도록 합니다. IP 주소와 함께 포트 주소를 TCP 소켓이라고 합니다. 대상 포트는 IP 패킷의 포트 80입니다.
의사소통 시작:
위의 세 단계를 통해 클라이언트와 서버 간의 TCP 핸드셰이크가 성공했으며 이제 둘 다 데이터 전송에 대한 공통 규칙에 동의했습니다.
TCP 핸드셰이크 후에 보안 웹사이트에 연결하는 경우 TLS 핸드셰이크가 발생합니다. TLS 핸드셰이크를 통해 클라이언트와 서버는 보안 통신의 공통 조건에 동의합니다.
이제부터 TLS 세션은 합의된 대칭 키로 암호화된 애플리케이션(HTTP) 데이터를 전송합니다.
서버는 요청을 처리하고 적절한 응답을 다시 보냅니다. 요청이 포트 80(HTTP) 또는 포트 443(HTTPS)을 통해 서버에 전달되면 Apache 또는 Nginx와 같은 웹 서버는 포트 443을 수신하고 요청 연결을 처리한 후 웹 서비스가 있는 다른 임시 포트로 라우팅합니다. 달리기.
모든 HTTP 클라이언트, 서버 또는 프록시는 언제든지 TCP 전송 연결을 닫을 수 있습니다. 예를 들어 클라이언트가 데이터 전송이 끝났고 열린 연결 채널이 더 이상 필요하지 않음을 감지하면 서버에 연결 종료 요청을 보냅니다. 다음에 클라이언트가 서버와 통신하려면 두 시스템 간에 새로운 연결을 설정해야 합니다.
| [1] | URL 표준 |
| [2] | 구성요소 또는 URL |


