prometeo
1.0.0

임베디드 고성능 컴퓨팅을 위한 실험적 모델링 도구인 prometeo 입니다. prometeo는 고성능 자체 포함 C 코드로 쉽게 변환할 수 있는 고급 언어(Python 자체)로 과학 컴퓨팅 프로그램을 편리하게 작성할 수 있도록 Python 언어의 하위 집합을 기반으로 하는 도메인 특정 언어(DSL)를 제공합니다. 임베디드 장치에 배포 가능.
prometeo의 문서는 https://prometeo.readthedocs.io/en/latest/index.html의 문서 읽기에서 찾을 수 있습니다.
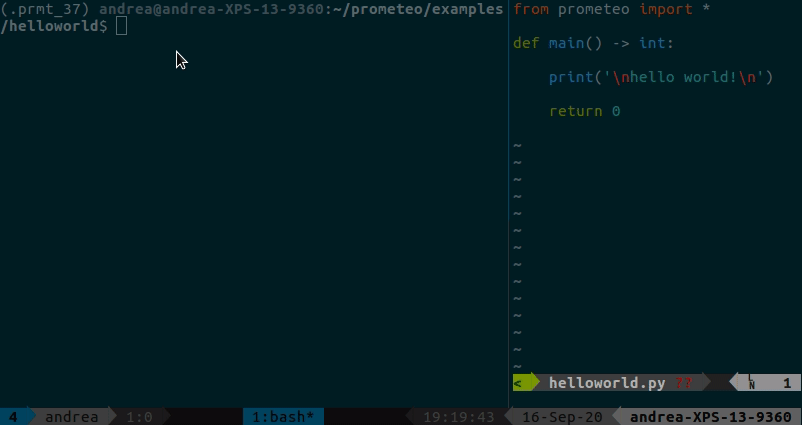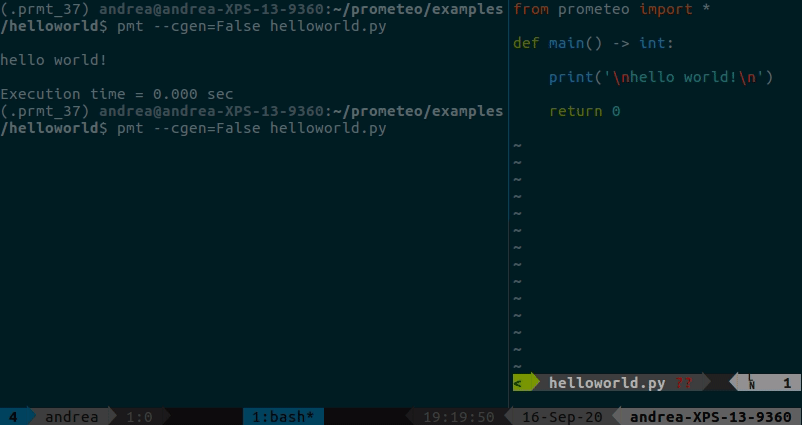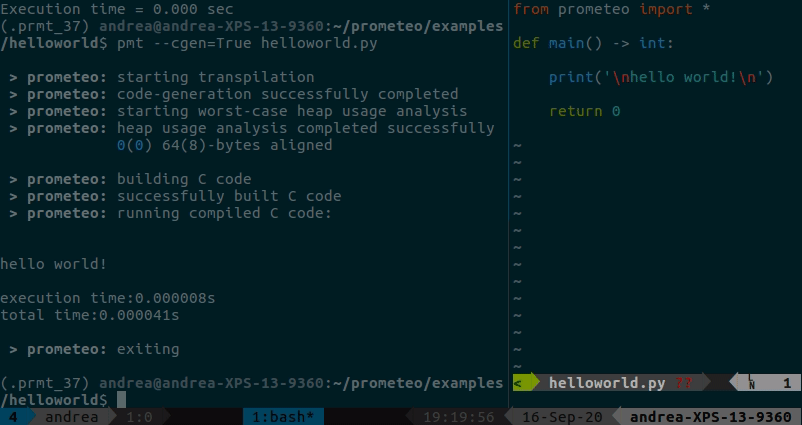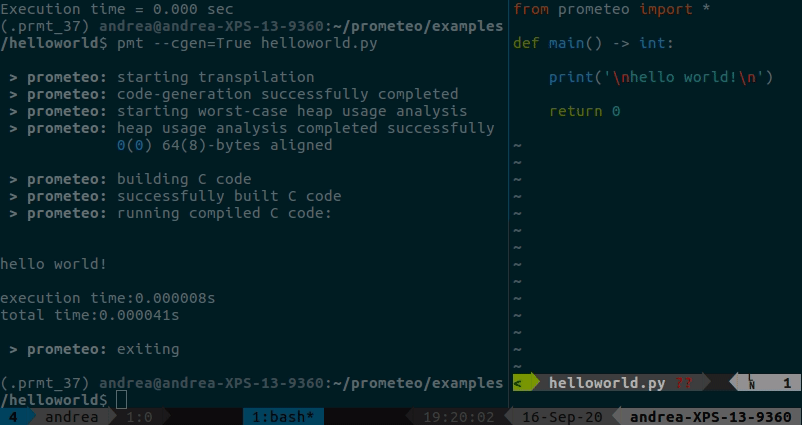
Python에서 간단한 prometeo 프로그램을 실행하거나 C로 트랜스파일하고 빌드하고 실행하는 방법을 보여주는 간단한 hello world 예제는 여기에서 찾을 수 있습니다. 출력에는 힙 사용량 분석 결과와 실행 시간이 표시됩니다(이 경우에는 볼 내용이 많지 않습니다:p).
Prometeo 프로그램은 고성능 선형 대수학 라이브러리 BLASFEO(공개: https://arxiv.org/abs/1704.02457, 코드: https://github.com/giaf/blasfeo)를 호출하는 순수 C 코드로 트랜스파일되므로 실행 시간이 손으로 작성한 고성능 코드와 비슷합니다. 아래 그림은 BLASFEO에 대한 호출과 함께 고도로 최적화된 손으로 작성한 C 코드를 사용하여 Riccati 분해를 수행하는 데 필요한 CPU 시간과 이 예에서 prometeo 트랜스파일된 코드로 얻은 시간을 비교한 것입니다. 비교를 위해 NumPy와 Julia로 얻은 계산 시간도 추가되었습니다. 그러나 Riccati 분해의 마지막 두 구현은 prometeo에서 생성된 C 코드와 직접 코딩한 C 구현만큼 쉽게 삽입할 수 없다는 점에 유의하세요. 모든 벤치마크는 2.30GHz에서 실행되는 i7-7560U CPU가 장착된 Dell XPS-9360에서 실행되었습니다(열 조절로 인한 주파수 변동을 방지하기 위해).
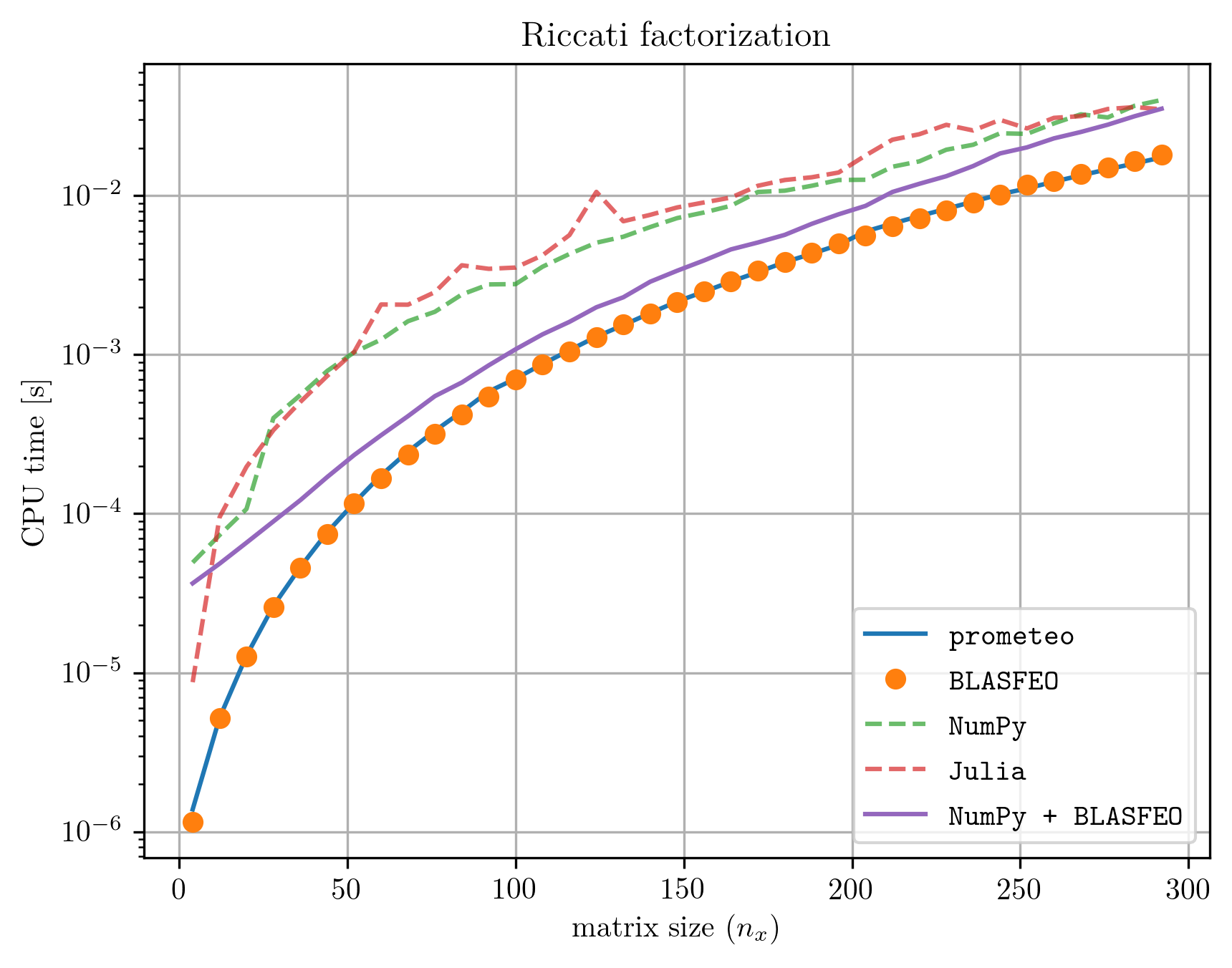
또한, prometeo는 Nuitka와 같은 최첨단 Python 컴파일러보다 성능이 훨씬 뛰어납니다. 아래 표는 Fibonacci 벤치마크에서 얻은 CPU 시간을 보여줍니다.
| 파서/컴파일러 | CPU 시간 [초] |
|---|---|
| 파이썬 3.7(CPython) | 11.787 |
| 누이카 | 10.039 |
| 파이파이 | 1.78 |
| 프로메테오 | 0.657 |
prometeo는 pip install prometeo-dsl 사용하여 PyPI를 통해 설치할 수 있습니다. prometeo는 Python 코드에 정적 유형 지정 정보를 제공하기 위해 유형 힌트를 광범위하게 사용하므로 필요한 최소 Python 버전은 3.6입니다.
로컬 컴퓨터에 소스를 구축하는 prometeo를 설치하려면 다음과 같이 진행할 수 있습니다.
git submodule update --init 실행하여 하위 모듈을 복제합니다.<prometeo_root>/prometeo/cpmt 에서 make install_shared 실행하여 C 백엔드와 연결된 공유 라이브러리를 컴파일하고 설치합니다. 기본 설치 경로는 <prometeo_root>/prometeo/cpmt/install 입니다.virtualenv --python=<path_to_python3.6> <path_to_new_virtualenv> 사용하여 가상 환경을 설정할 수 있습니다.pip install -e . <prometeo_root> 에서 Python 패키지를 설치합니다. 마지막으로 pmt <example_name>.py --cgen=<True/False> 사용하여 <root>/examples 의 예제를 실행할 수 있습니다. 여기서 --cgen 플래그는 코드가 Python 인터프리터에 의해 실행되는지 또는 C 코드가 실행되는지 여부를 결정합니다. 생성되어 컴파일되고 실행됩니다.
Python 코드( examples/simple_example/simple_example.py )
from prometeo import *
n : dims = 10
def main () -> int :
A : pmat = pmat ( n , n )
for i in range ( 10 ):
for j in range ( 10 ):
A [ i , j ] = 1.0
B : pmat = pmat ( n , n )
for i in range ( 10 ):
B [ 0 , i ] = 2.0
C : pmat = pmat ( n , n )
C = A * B
pmat_print ( C )
return 0 표준 Python 인터프리터(버전 >3.6 필요)로 실행할 수 있으며 pmt simple_example.py --cgen=False 명령을 사용하여 설명된 선형 대수 연산을 수행합니다. 동시에 코드는 prometeo로 구문 분석되고 추상 구문 트리(AST)를 분석하여 다음과 같은 고성능 C 코드를 생성할 수 있습니다.
#include "stdlib.h"
#include "simple_example.h"
void * ___c_pmt_8_heap ;
void * ___c_pmt_64_heap ;
void * ___c_pmt_8_heap_head ;
void * ___c_pmt_64_heap_head ;
#include "prometeo.h"
int main () {
___c_pmt_8_heap = malloc ( 10000 );
___c_pmt_8_heap_head = ___c_pmt_8_heap ;
char * pmem_ptr = ( char * ) ___c_pmt_8_heap ;
align_char_to ( 8 , & pmem_ptr );
___c_pmt_8_heap = pmem_ptr ;
___c_pmt_64_heap = malloc ( 1000000 );
___c_pmt_64_heap_head = ___c_pmt_64_heap ;
pmem_ptr = ( char * ) ___c_pmt_64_heap ;
align_char_to ( 64 , & pmem_ptr );
___c_pmt_64_heap = pmem_ptr ;
void * callee_pmt_8_heap = ___c_pmt_8_heap ;
void * callee_pmt_64_heap = ___c_pmt_64_heap ;
struct pmat * A = c_pmt_create_pmat ( n , n );
for ( int i = 0 ; i < 10 ; i ++ ) {
for ( int j = 0 ; j < 10 ; j ++ ) {
c_pmt_pmat_set_el ( A , i , j , 1.0 );
}
}
struct pmat * B = c_pmt_create_pmat ( n , n );
for ( int i = 0 ; i < 10 ; i ++ ) {
c_pmt_pmat_set_el ( B , 0 , i , 2.0 );
}
struct pmat * C = c_pmt_create_pmat ( n , n );
c_pmt_pmat_fill ( C , 0.0 );
c_pmt_gemm_nn ( A , B , C , C );
c_pmt_pmat_print ( C );
___c_pmt_8_heap = callee_pmt_8_heap ;
___c_pmt_64_heap = callee_pmt_64_heap ;
free ( ___c_pmt_8_heap_head );
free ( ___c_pmt_64_heap_head );
return 0 ;
} 이는 고성능 선형 대수학 패키지 BLASFEO에 의존합니다. 생성된 코드는 pmt simple_example.py --cgen=True 실행할 때 쉽게 컴파일되고 실행됩니다.
한 언어로 작성된 프로그램을 유사한 추상화 수준을 가진 다른 언어로 번역하는 것이 매우 다른 추상화 수준을 가진 프로그램으로 번역하는 것보다 훨씬 쉬울 수 있지만(특히 대상 언어가 훨씬 낮은 수준인 경우) Python 프로그램을 C 프로그램으로 번역합니다. 여전히 상당한 추상화 격차가 있으므로 일반적으로 쉬운 작업은 아닙니다. 대략적으로 말하자면, 소스 언어에서 기본적으로 지원하는 기능을 대상 언어로 다시 구현해야 하는 문제가 있습니다. 특히 Python을 C로 번역할 때 두 언어의 서로 다른 추상화 수준과 소스 언어와 대상 언어가 매우 다른 두 가지 유형이라는 사실에서 어려움이 발생합니다. Python은 해석된 오리 유형 및 가비지 입니다. -수집된 언어이며 C는 컴파일 되고 정적으로 유형이 지정된 언어입니다.
생성된 C 코드가 효율적이어야 하고(중소 규모 계산의 경우에도) 임베디드 하드웨어에 배포 가능해야 한다는 제약 조건을 추가하면 Python을 C로 변환하는 작업은 훨씬 더 어려워집니다. 실제로 이러한 두 가지 요구 사항은 생성된 코드가 다음을 사용할 수 없음을 직접적으로 의미합니다. i) 일반적으로 임베디드 하드웨어에서 사용할 수 없는 Python 런타임 라이브러리와 같은 정교한 런타임 라이브러리 ii) 실행을 느리고 신뢰할 수 없게 만드는 동적 메모리 할당 (설정 단계에서 할당되고 크기가 사전에 알려진 메모리에 대한 예외)
소스 간 코드 변환 또는 변환, 특히 Python 코드를 C 코드로 변환하는 것은 미지의 영역이 아니므로 다음에서는 이를 해결하는 몇 가지 기존 프로젝트를 언급합니다. 이를 통해 위에서 설명한 두 가지 요구 사항, 즉 (소규모) 효율성과 내장 가능성 중 하나를 충족하지 못하는 부분과 방법을 강조합니다.
다양한 형식으로 Python에서 C로 변환을 처리하는 여러 소프트웨어 패키지가 있습니다.
고성능 컴퓨팅의 맥락에서 Numba는 Python으로 작성된 수치 함수를 위한 JIT(Just-In-Time) 컴파일러입니다. 따라서 전체 프로그램이 아닌 적절하게 주석이 달린 Python 함수를 고성능 LLVM 코드로 변환하여 실행 속도를 높이는 것이 목표입니다. Numba는 번역할 코드의 내부 표현을 사용하고 Python 또는 C/C++에서 호출할 수 있는 LLVM 코드를 생성하기 위해 관련된 변수에 대해 (부분적으로) 유형 추론을 수행합니다. 어떤 경우에는, 즉 완전한 유형 추론이 성공적으로 수행될 수 있는 경우 C API에 의존하지 않는 코드가 생성될 수 있습니다( nopython 플래그 사용). 그러나 방출된 LLVM 코드는 BLAS 및 LAPACK 작업에 여전히 Numpy를 사용합니다.
Nuitka 는 모든 Python 구성을 libpython 라이브러리에 연결되는 C 코드로 변환할 수 있는 소스-소스 컴파일러이므로 대규모 Python 프로그램 클래스를 트랜스파일할 수 있습니다. 이를 위해 가장 많이 사용되는 Python 언어 구현 중 하나인 CPython 이 C로 작성된다는 사실에 의존합니다. 실제로 Nuitka는 일반적으로 다음에서 수행되는 CPython 에 대한 호출이 포함된 C 코드를 생성합니다. 파이썬 파서. 매력적이고 일반적인 변환 접근 방식에도 불구하고 libpython 에 대한 본질적인 종속성으로 인해 임베디드 하드웨어에 쉽게 배포할 수 없습니다. 동시에 Python 구성을 CPython 구현에 매우 밀접하게 매핑하기 때문에 중소 규모의 고성능 컴퓨팅에 관해서는 여러 가지 성능 문제가 예상될 수 있습니다. 이는 특히 실행 속도를 늦출 수 있는 유형 검사, 메모리 할당 및 가비지 수집과 관련된 작업이 트랜스파일된 프로그램에 의해 수행된다는 사실에 기인합니다.
Cython은 Python 언어용 C 확장 작성을 용이하게 하는 것을 목표로 하는 프로그래밍 언어입니다. 특히, (선택적으로) 정적으로 유형이 지정된 Python과 유사한 코드를 CPython 에 의존하는 C 코드로 변환할 수 있습니다. Nuitka 에 대한 고려 사항과 유사하게 이는 libpython 에 의존할 수 있을 때마다(그리고 오버헤드가 무시할 수 있을 때, 즉 충분히 대규모 계산을 처리할 때) 강력한 도구가 되지만 여기서 관심 있는 맥락에서는 그렇지 않습니다.
마지막으로, Python을 소스 언어로 사용하지는 않지만 Julia 역시 LLVM 코드로 적시(부분적으로 앞서) 컴파일된다는 점을 언급해야 합니다. 그러나 생성된 LLVM 코드는 Julia 런타임 라이브러리에 의존하므로 Cython 및 Nuitka 에 대한 고려 사항과 유사한 고려 사항이 적용됩니다.
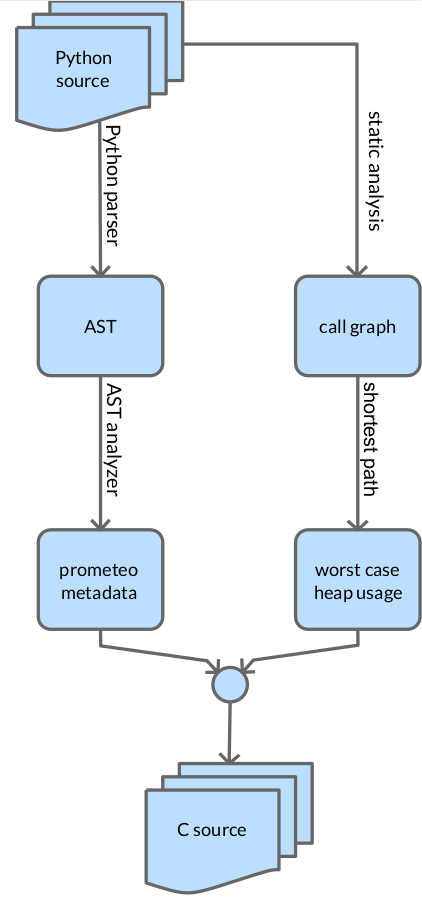
Python 언어의 제한된 하위 집합을 사용하여 작성된 프로그램을 C 프로그램으로 변환하는 작업은 prometeo 의 변환기를 사용하여 수행됩니다. 이 소스-소스 변환 도구는 포함 가능한 고성능 C 코드를 생성하기 위해 트랜스파일할 소스 파일과 관련된 AST(추상 구문 트리)를 분석합니다. 그렇게 하려면 Python 코드에 특별한 규칙을 적용해야 합니다. 이는 해석된 고급 오리 유형 언어를 컴파일된 저수준 정적 유형 언어로 변환하는 매우 어려운 작업을 가능하게 합니다. 이를 통해 결과 언어가 호스트 언어(Python 자체)의 구문을 사용하고 prometeo 의 경우 표준 Python 인터프리터에서도 실행될 수 있다는 점에서 임베디드 DSL이라고도 하는 것을 정의합니다. .
from prometeo import *
nx : dims = 2
nu : dims = 2
nxu : dims = nx + nu
N : dims = 5
def main () -> int :
# number of repetitions for timing
nrep : int = 10000
A : pmat = pmat ( nx , nx )
A [ 0 , 0 ] = 0.8
A [ 0 , 1 ] = 0.1
A [ 1 , 0 ] = 0.3
A [ 1 , 1 ] = 0.8
B : pmat = pmat ( nx , nu )
B [ 0 , 0 ] = 1.0
B [ 1 , 1 ] = 1.0
Q : pmat = pmat ( nx , nx )
Q [ 0 , 0 ] = 1.0
Q [ 1 , 1 ] = 1.0
R : pmat = pmat ( nu , nu )
R [ 0 , 0 ] = 1.0
R [ 1 , 1 ] = 1.0
A : pmat = pmat ( nx , nx )
B : pmat = pmat ( nx , nu )
Q : pmat = pmat ( nx , nx )
R : pmat = pmat ( nu , nu )
RSQ : pmat = pmat ( nxu , nxu )
Lxx : pmat = pmat ( nx , nx )
M : pmat = pmat ( nxu , nxu )
w_nxu_nx : pmat = pmat ( nxu , nx )
BAt : pmat = pmat ( nxu , nx )
BA : pmat = pmat ( nx , nxu )
pmat_hcat ( B , A , BA )
pmat_tran ( BA , BAt )
RSQ [ 0 : nu , 0 : nu ] = R
RSQ [ nu : nu + nx , nu : nu + nx ] = Q
# array-type Riccati factorization
for i in range ( nrep ):
pmt_potrf ( Q , Lxx )
M [ nu : nu + nx , nu : nu + nx ] = Lxx
for i in range ( 1 , N ):
pmt_trmm_rlnn ( Lxx , BAt , w_nxu_nx )
pmt_syrk_ln ( w_nxu_nx , w_nxu_nx , RSQ , M )
pmt_potrf ( M , M )
Lxx [ 0 : nx , 0 : nx ] = M [ nu : nu + nx , nu : nu + nx ]
return 0 마찬가지로 위의 코드( example/riccati/riccati_array.py )는 pmt riccati_array.py --cgen=False 명령을 사용하여 표준 Python 인터프리터로 실행할 수 있으며 prometeo는 대신 pmt riccati_array.py --cgen=True 사용하여 C 코드를 생성, 컴파일 및 실행할 수 있습니다. pmt riccati_array.py --cgen=True .
C로 트랜스파일하려면 Python 언어의 하위 집합만 지원됩니다. 그러나 함수 오버로드 및 클래스와 같은 C와 유사하지 않은 기능은 prometeo의 트랜스파일러에서 지원됩니다. 아래의 개조된 Riccati 예제( examples/riccati/riccati_mass_spring_2.py )는 클래스를 만들고 사용하는 방법을 보여줍니다.
from prometeo import *
nm : dims = 4
nx : dims = 2 * nm
sizes : dimv = [[ 8 , 8 ], [ 8 , 8 ], [ 8 , 8 ], [ 8 , 8 ], [ 8 , 8 ]]
nu : dims = nm
nxu : dims = nx + nu
N : dims = 5
class qp_data :
A : List = plist ( pmat , sizes )
B : List = plist ( pmat , sizes )
Q : List = plist ( pmat , sizes )
R : List = plist ( pmat , sizes )
P : List = plist ( pmat , sizes )
fact : List = plist ( pmat , sizes )
def factorize ( self ) -> None :
M : pmat = pmat ( nxu , nxu )
Mxx : pmat = pmat ( nx , nx )
L : pmat = pmat ( nxu , nxu )
Q : pmat = pmat ( nx , nx )
R : pmat = pmat ( nu , nu )
BA : pmat = pmat ( nx , nxu )
BAtP : pmat = pmat ( nxu , nx )
pmat_copy ( self . Q [ N - 1 ], self . P [ N - 1 ])
pmat_hcat ( self . B [ N - 1 ], self . A [ N - 1 ], BA )
pmat_copy ( self . Q [ N - 1 ], Q )
pmat_copy ( self . R [ N - 1 ], R )
for i in range ( 1 , N ):
pmat_fill ( BAtP , 0.0 )
pmt_gemm_tn ( BA , self . P [ N - i ], BAtP , BAtP )
pmat_fill ( M , 0.0 )
M [ 0 : nu , 0 : nu ] = R
M [ nu : nu + nx , nu : nu + nx ] = Q
pmt_gemm_nn ( BAtP , BA , M , M )
pmat_fill ( L , 0.0 )
pmt_potrf ( M , L )
Mxx [ 0 : nx , 0 : nx ] = L [ nu : nu + nx , nu : nu + nx ]
# pmat_fill(self.P[N-i-1], 0.0)
pmt_gemm_nt ( Mxx , Mxx , self . P [ N - i - 1 ], self . P [ N - i - 1 ])
# pmat_print(self.P[N-i-1])
return
def main () -> int :
A : pmat = pmat ( nx , nx )
Ac11 : pmat = pmat ( nm , nm )
Ac12 : pmat = pmat ( nm , nm )
for i in range ( nm ):
Ac12 [ i , i ] = 1.0
Ac21 : pmat = pmat ( nm , nm )
for i in range ( nm ):
Ac21 [ i , i ] = - 2.0
for i in range ( nm - 1 ):
Ac21 [ i + 1 , i ] = 1.0
Ac21 [ i , i + 1 ] = 1.0
Ac22 : pmat = pmat ( nm , nm )
for i in range ( nm ):
for j in range ( nm ):
A [ i , j ] = Ac11 [ i , j ]
for i in range ( nm ):
for j in range ( nm ):
A [ i , nm + j ] = Ac12 [ i , j ]
for i in range ( nm ):
for j in range ( nm ):
A [ nm + i , j ] = Ac21 [ i , j ]
for i in range ( nm ):
for j in range ( nm ):
A [ nm + i , nm + j ] = Ac22 [ i , j ]
tmp : float = 0.0
for i in range ( nx ):
tmp = A [ i , i ]
tmp = tmp + 1.0
A [ i , i ] = tmp
B : pmat = pmat ( nx , nu )
for i in range ( nu ):
B [ nm + i , i ] = 1.0
Q : pmat = pmat ( nx , nx )
for i in range ( nx ):
Q [ i , i ] = 1.0
R : pmat = pmat ( nu , nu )
for i in range ( nu ):
R [ i , i ] = 1.0
qp : qp_data = qp_data ()
for i in range ( N ):
qp . A [ i ] = A
for i in range ( N ):
qp . B [ i ] = B
for i in range ( N ):
qp . Q [ i ] = Q
for i in range ( N ):
qp . R [ i ] = R
qp . factorize ()
return 0면책조항: prometeo는 아직 초기 단계에 있으며 당분간은 몇 가지 선형 대수 연산과 Python 구성만 지원됩니다.


