Dropout NeuralNetworks
1.0.0
이 연구 프로젝트에서는 MNIST 데이터세트에서 탈락률 변경이 미치는 영향에 중점을 둘 것입니다. 나의 목표는 연구 논문에 사용된 데이터로 아래 그림을 재현하는 것입니다. 이 프로젝트의 목적은 머신러닝 수치가 어떻게 제작되었는지 알아보는 것입니다. 구체적으로, 탈락 확률을 변경하거나 변경하지 않을 때 분류 오류에 미치는 영향에 대해 학습합니다.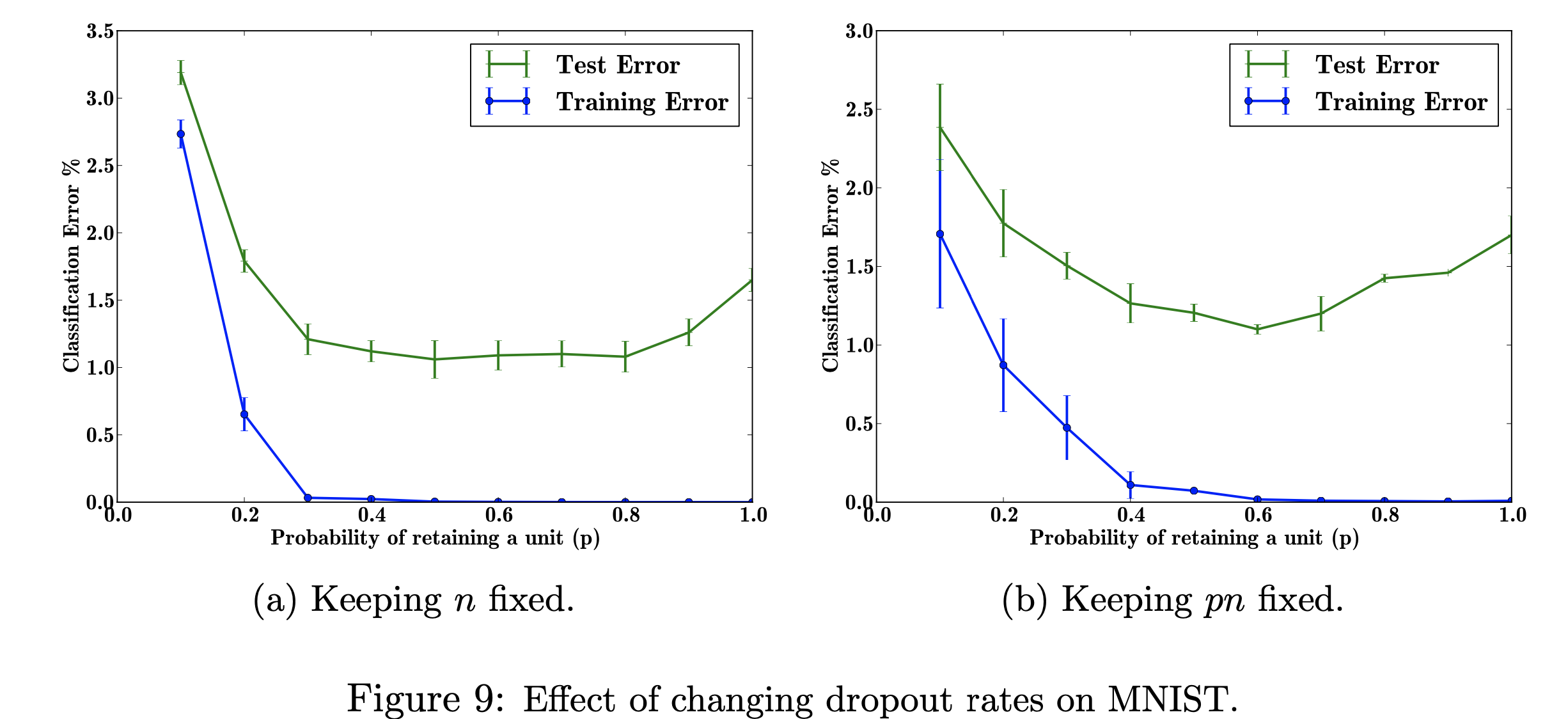 참조 그림: Srivastava, N., Hinton, G.,Krizhevsky, A., Krizhevsky, I., Salakhutdinov, R., 드롭아웃: 신경망의 과적합을 방지하는 간단한 방법, 그림 9
참조 그림: Srivastava, N., Hinton, G.,Krizhevsky, A., Krizhevsky, I., Salakhutdinov, R., 드롭아웃: 신경망의 과적합을 방지하는 간단한 방법, 그림 9
나는 TensorFlow를 사용하여 MNIST 데이터세트에서 드롭아웃을 실행했고, Matplotlib는 논문의 그림을 다시 만드는 데 도움을 주었습니다. 또한 내장된 Decimal 라이브러리를 사용하여 0.0에서 1.0까지 p의 다양한 값을 계산했습니다. 이미 계산된 p 값의 계산 시간을 절약하기 위해 이전에 실행한 데이터를 CSV 파일에 추가하기 위해 라이브러리 "csv"를 가져왔습니다. x축과 y축에서 동일한 단계 크기를 갖도록 플로팅을 얻기 위해 Numpy를 가져왔습니다. 마지막으로 GPU가 아닌 CPU를 사용해서 발생하는 오류를 없애기 위해 "os"를 import 했습니다.
오류율에 영향을 미치는 조정 가능한 초매개변수 'p'(네트워크에서 단위를 유지할 확률)와 숨겨진 레이어 수 'n'의 다양한 값의 효과를 탐색합니다. p와 n의 곱이 고정되면 숨겨진 레이어 수를 일정하게 유지하는 것(그림 9b)에 비해 p의 작은 값에 대한 오류 크기가 감소한 것을 확인할 수 있습니다(그림 9a).
훈련 데이터가 제한되어 있으면 입력/출력 간의 복잡한 관계가 많이 발생하며 샘플링 노이즈로 인해 발생합니다. 훈련 세트에는 존재하지만 동일한 분포에서 추출된 경우에도 실제 테스트 데이터에는 존재하지 않습니다. 이러한 합병증은 과적합으로 이어지며, 이는 과적합이 발생하는 것을 방지하는 데 도움이 되는 알고리즘 중 하나입니다. 이 그림의 입력은 손으로 쓴 숫자의 데이터셋이고, 드롭아웃을 추가한 후의 출력은 드롭아웃 방법을 적용한 결과를 설명하는 다른 값입니다. 대체로 드롭아웃을 추가한 후에는 오류가 줄어듭니다.
이것이 적용될 수 있는 실제 문제는 Google 검색입니다. 누군가는 영화 제목을 검색하지만 시각적인 학습자이기 때문에 이미지만 찾고 있을 수도 있습니다. 따라서 텍스트 부분이나 간단한 설명을 삭제하면 이미지 기능에 집중하는 데 도움이 됩니다. 기사에는 (http://yann.lecun.com/exdb/mnist/)에서 데이터를 검색하는 위치가 나와 있습니다. 각 이미지는 28x28 숫자로 표현됩니다. y 레이블은 이미지 데이터 열인 것 같습니다.
이 그림을 재현하는 나의 목표는 데이터를 테스트/훈련하고 p(네트워크에서 단위를 유지할 확률)의 각 확률에 대한 분류 오류를 계산하는 것입니다. 내 목표는 오류가 감소함에 따라 p를 증가시켜 내 구현이 유효하다는 것을 보여주는 것이며, 이 하이퍼 매개변수를 조정하여 동일한 결과를 얻을 것입니다. 784-2048-2048-2048-10 아키텍처를 사용하여 모든 교육 및 테스트 데이터를 반복하고 n을 고정한 다음 pn을 고정되도록 변경하여 이 작업을 수행합니다. 그런 다음 데이터를 csv 파일로 수집/작성하겠습니다. 그러면 이 csv 파일에는 수치를 출력하는 데 필요한 모든 데이터가 포함됩니다. 이 프로젝트에서는 탈락률이 신경망의 전반적인 오류에 어떻게 도움이 되는지 알아볼 것입니다.
보려면 클릭하세요


