Stability AI 및 Runway와의 협력 덕분에 Stable Diffusion이 가능해졌으며 이전 작업을 기반으로 구축되었습니다.
잠재 확산 모델을 사용한 고해상도 이미지 합성
Robin Rombach*, Andreas Blattmann*, Dominik Lorenz, Patrick Esser, Björn Ommer
CVPR '22 구강 | GitHub | arXiv | 프로젝트 페이지
 안정 확산(Stable Diffusion)은 잠재 텍스트-이미지 확산 모델입니다. Stability AI의 넉넉한 컴퓨팅 기부와 LAION의 지원 덕분에 우리는 LAION-5B 데이터베이스의 하위 집합에서 512x512 이미지에 대한 잠재 확산 모델을 훈련할 수 있었습니다. Google의 Imagen과 유사하게 이 모델은 고정된 CLIP ViT-L/14 텍스트 인코더를 사용하여 텍스트 프롬프트에 따라 모델을 조정합니다. 860M UNet 및 123M 텍스트 인코더를 사용하는 이 모델은 상대적으로 가벼우며 최소 10GB VRAM이 있는 GPU에서 실행됩니다. 아래의 이 섹션과 모델 카드를 참조하세요.
안정 확산(Stable Diffusion)은 잠재 텍스트-이미지 확산 모델입니다. Stability AI의 넉넉한 컴퓨팅 기부와 LAION의 지원 덕분에 우리는 LAION-5B 데이터베이스의 하위 집합에서 512x512 이미지에 대한 잠재 확산 모델을 훈련할 수 있었습니다. Google의 Imagen과 유사하게 이 모델은 고정된 CLIP ViT-L/14 텍스트 인코더를 사용하여 텍스트 프롬프트에 따라 모델을 조정합니다. 860M UNet 및 123M 텍스트 인코더를 사용하는 이 모델은 상대적으로 가벼우며 최소 10GB VRAM이 있는 GPU에서 실행됩니다. 아래의 이 섹션과 모델 카드를 참조하세요.
다음을 사용하여 ldm 이라는 적절한 conda 환경을 만들고 활성화할 수 있습니다.
conda env create -f environment.yaml
conda activate ldm
다음을 실행하여 기존 잠재 확산 환경을 업데이트할 수도 있습니다.
conda install pytorch torchvision -c pytorch
pip install transformers==4.19.2 diffusers invisible-watermark
pip install -e .
Stable Diffusion v1은 확산 모델을 위한 860M UNet 및 CLIP ViT-L/14 텍스트 인코더와 함께 다운샘플링 인자 8 자동 인코더를 사용하는 모델 아키텍처의 특정 구성을 나타냅니다. 모델은 256x256 이미지에서 사전 학습된 다음 512x512 이미지에서 미세 조정되었습니다.
참고: Stable Diffusion v1은 일반적인 텍스트-이미지 확산 모델이므로 훈련 데이터에 존재하는 편견과 (잘못된) 개념을 반영합니다. 훈련 절차와 데이터, 모델의 용도에 대한 자세한 내용은 해당 모델 카드에서 확인할 수 있습니다.
가중치는 모델 카드에 명시된 대로 오용 및 피해를 방지하기 위한 특정 사용 기반 제한 사항이 포함되어 있지만 그렇지 않은 경우 허용되는 라이선스에 따라 Hugging Face의 CompVis 조직을 통해 제공됩니다. 라이센스 조건에 따라 상업적인 사용이 허용되지만, 추가 안전 메커니즘 및 고려 사항 없이 서비스 또는 제품에 제공된 가중치를 사용하는 것은 권장되지 않습니다 . 가중치에 대한 알려진 제한 및 편향과 안전하고 윤리적인 배포에 대한 연구가 있기 때문입니다. 일반적인 텍스트-이미지 모델은 지속적인 노력입니다. 가중치는 연구 결과물이므로 그렇게 취급해야 합니다.
CreativeML OpenRAIL M 라이선스는 BigScience와 RAIL Initiative가 책임 있는 AI 라이선스 분야에서 공동으로 수행하는 작업을 바탕으로 제작된 Open RAIL M 라이선스입니다. 라이선스의 기반이 되는 BLOOM Open RAIL 라이선스에 대한 기사도 참조하세요.
우리는 현재 다음과 같은 체크포인트를 제공합니다:
sd-v1-1.ckpt : laion2B-en의 해상도 256x256 에서 237k 단계. laion-high-solution에서 해상도 512x512 의 194k 단계(해상도 >= 1024x1024 인 LAION-5B의 170M 예).sd-v1-2.ckpt : sd-v1-1.ckpt 에서 재개됩니다. laion-aesthetics v2 5+에서 해상도 512x512 의 515k 단계(예상 미학 점수 > 5.0 이고 추가로 원본 크기 >= 512x512 및 추정 워터마크 확률 < 0.5 인 이미지로 필터링된 laion2B-en의 하위 집합) 워터마크 추정 LAION-5B 메타데이터에서 가져온 것이며 미학 점수는 LAION-Aesthetics Predictor를 사용하여 추정됩니다. V2).sd-v1-3.ckpt : sd-v1-2.ckpt 에서 재개됩니다. "laion-aesthetics v2 5+"에서 해상도 512x512 의 195,000단계 및 분류자 없는 안내 샘플링을 개선하기 위해 텍스트 조절을 10% 삭제했습니다.sd-v1-4.ckpt : sd-v1-2.ckpt 에서 재개됩니다. "laion-aesthetics v2 5+"에서 해상도 512x512 의 225,000단계 및 분류자 없는 안내 샘플링을 개선하기 위해 텍스트 조절을 10% 삭제했습니다. 다양한 분류자 없는 안내 척도(1.5, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0) 및 50개의 PLMS 샘플링 단계를 사용한 평가는 체크포인트의 상대적 개선을 보여줍니다. 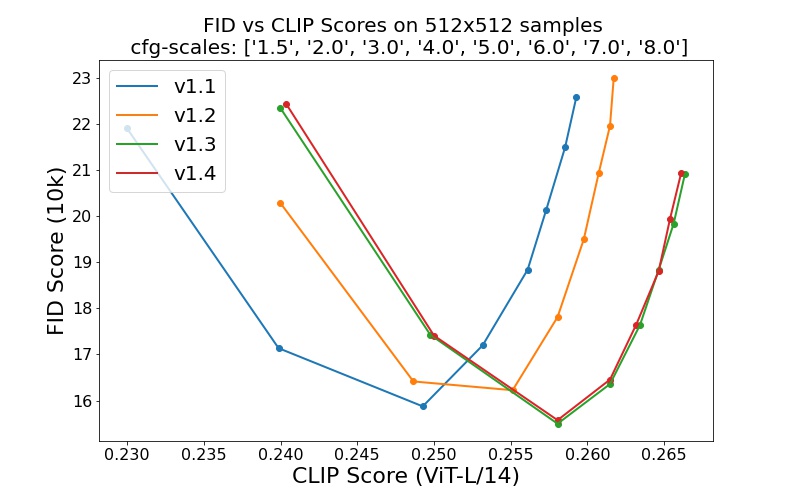


Stable Diffusion은 CLIP ViT-L/14 텍스트 인코더의 (풀링되지 않은) 텍스트 임베딩을 기반으로 한 잠재 확산 모델입니다. 우리는 샘플링을 위한 참조 스크립트를 제공하지만 디퓨저 통합도 존재하므로 더욱 활발한 커뮤니티 개발이 기대됩니다.
우리는 다음을 포함하는 참조 샘플링 스크립트를 제공합니다.
stable-diffusion-v1-*-original 가중치를 얻은 후 이를 연결합니다.
mkdir -p models/ldm/stable-diffusion-v1/
ln -s <path/to/model.ckpt> models/ldm/stable-diffusion-v1/model.ckpt
그리고 샘플로
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
기본적으로 이는 Katherine Crowson의 PLMS 샘플러 구현인 --scale 7.5 지침 스케일을 사용하고 50단계로 512x512 크기(학습된)의 이미지를 렌더링합니다. 지원되는 모든 인수는 아래에 나열되어 있습니다( python scripts/txt2img.py --help 입력).
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
참고: 모든 v1 버전의 추론 구성은 EMA 전용 체크포인트와 함께 사용하도록 설계되었습니다. 이러한 이유로 use_ema=False 구성에 설정되어 있습니다. 그렇지 않으면 코드는 비EMA 가중치에서 EMA 가중치로 전환을 시도합니다. EMA가 있는 경우와 EMA가 없는 경우의 효과를 조사하려는 경우 두 가지 유형의 가중치를 모두 포함하는 "전체" 체크포인트를 제공합니다. 이에 대해 use_ema=False EMA가 아닌 가중치를 로드하고 사용합니다.
Stable Diffusion을 다운로드하고 샘플링하는 간단한 방법은 디퓨저 라이브러리를 사용하는 것입니다.
# make sure you're logged in with `huggingface-cli login`
from torch import autocast
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained (
"CompVis/stable-diffusion-v1-4" ,
use_auth_token = True
). to ( "cuda" )
prompt = "a photo of an astronaut riding a horse on mars"
with autocast ( "cuda" ):
image = pipe ( prompt )[ "sample" ][ 0 ]
image . save ( "astronaut_rides_horse.png" )SDEdit에서 처음 제안한 확산 노이즈 제거 메커니즘을 사용하면 이 모델을 텍스트 기반 이미지 간 변환 및 업스케일링과 같은 다양한 작업에 사용할 수 있습니다. txt2img 샘플링 스크립트와 유사하게 Stable Diffusion을 사용하여 이미지 수정을 수행하는 스크립트를 제공합니다.
다음은 Pinta에서 만든 대략적인 스케치를 세부적인 작품으로 변환하는 예를 설명합니다.
python scripts/img2img.py --prompt "A fantasy landscape, trending on artstation" --init-img <path-to-img.jpg> --strength 0.8
여기서 강도는 0.0에서 1.0 사이의 값으로 입력 이미지에 추가되는 노이즈의 양을 제어합니다. 1.0에 접근하는 값은 다양한 변형을 허용하지만 입력과 의미상 일치하지 않는 이미지도 생성합니다. 다음 예를 참조하세요.
입력

출력


예를 들어 이 절차는 기본 모델에서 샘플을 확대하는 데에도 사용할 수 있습니다.
확산 모델을 위한 우리의 코드베이스는 OpenAI의 ADM 코드베이스와 https://github.com/lucidrains/denoising-diffusion-pytorch를 기반으로 구축되었습니다. 오픈소스를 제공해 주셔서 감사합니다!
변압기 인코더의 구현은 lucidrains의 x-transformer에서 이루어졌습니다.
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


