ACM MM'18 최우수 학생 논문
싱가포르 국립대학교(NUS)의 학습 및 비전(LV) 그룹의 다중 인간 구문 분석 프로젝트는 군중 장면에서 인간에 대한 세밀한 시각적 이해의 한계를 뛰어넘기 위해 제안되었습니다.
Multi-Human Parsing은 객체 위치(경계 상자)에 대한 개략적인 예측만 제공하는 객체 감지와 같은 기존의 잘 정의된 객체 인식 작업과 크게 다릅니다. 신체 부위 및 패션 카테고리에 대한 자세한 정보 없이 인스턴스 수준의 마스크만 예측하는 인스턴스 세분화; 다양한 신원을 구별하지 않고 카테고리 수준의 픽셀별 예측을 수행하는 인간 구문 분석.
실제 시나리오에서는 여러 사람이 상호 작용하는 설정이 더 현실적이고 일반적입니다. 따라서 각 개인의 세밀한 의미 정보와 전체 그룹의 관계 및 상호 작용을 모두 고려하는 작업, 해당 데이터 세트 및 기본 방법이 매우 필요합니다.
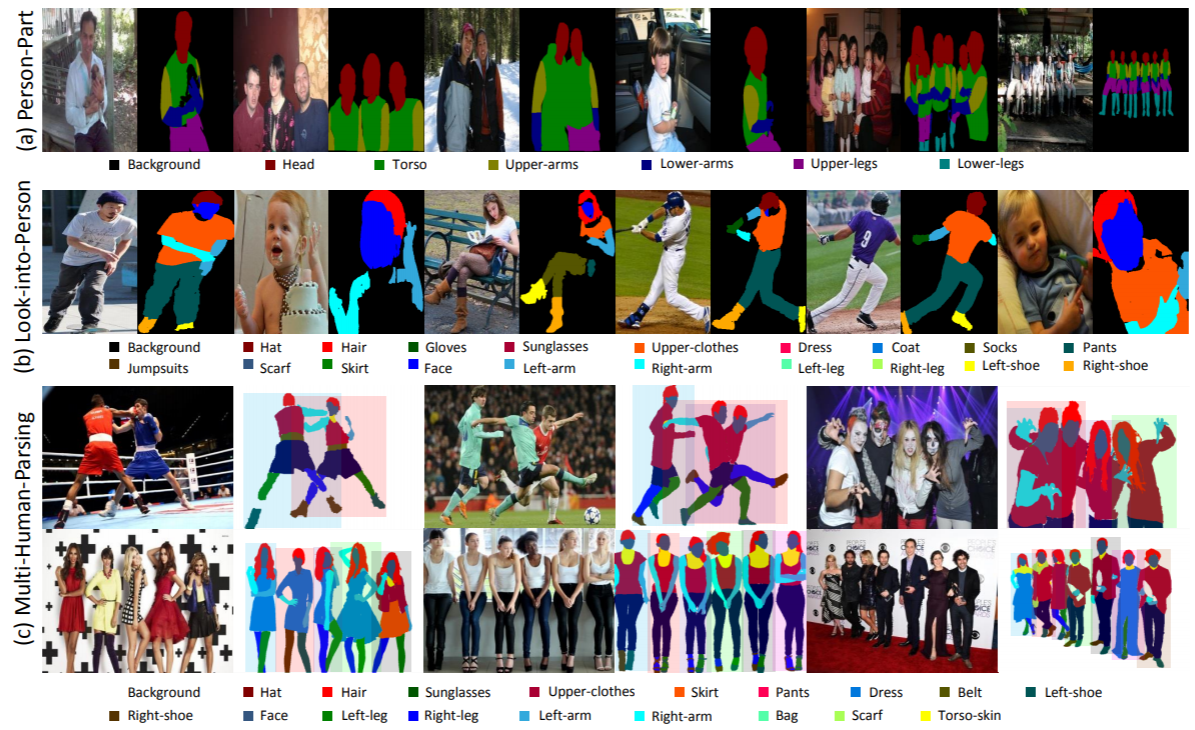
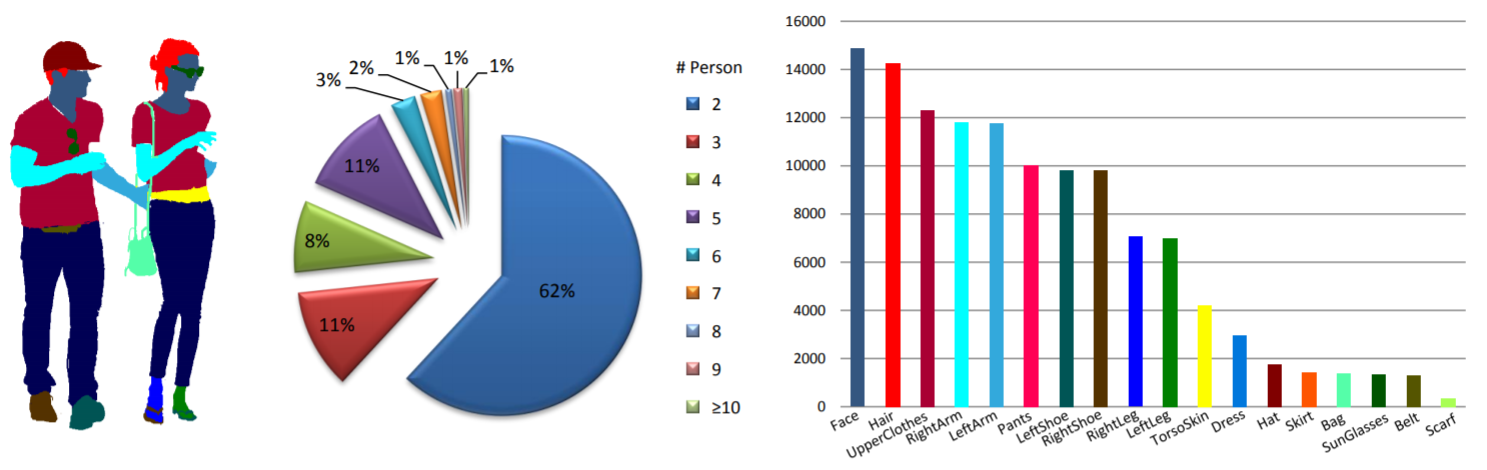
통계: MHP v1.0 데이터 세트에는 4,980개의 이미지가 포함되어 있으며 각 이미지에는 최소 2명(평균 3명)이 포함되어 있습니다. 우리는 무작위로 980개의 이미지와 해당 주석을 테스트 세트로 선택합니다. 나머지는 3,000개의 이미지로 구성된 훈련 세트와 1,000개의 이미지로 구성된 검증 세트를 구성합니다. 각 인스턴스에 대해 "모자", "머리카락", "선글라스", "상의", "치마", "바지", "드레스", "배경" 카테고리를 제외하고 18개의 의미 카테고리가 정의되고 주석이 추가됩니다. 벨트”, “왼쪽 신발”, “오른쪽 신발”, “얼굴”, “왼쪽 다리”, “오른쪽 다리”, “왼쪽 팔”, “오른쪽 팔”, “가방”, “스카프” 및 “몸통 피부”. 각 인스턴스에는 해당 카테고리가 현재 이미지에 나타날 때마다 완전한 주석 세트가 있습니다.
위챗 뉴스.
다운로드: MHP v1.0 데이터 세트는 Google 드라이브 및 Baidu 드라이브(비밀번호: cmtp)에서 사용할 수 있습니다.
자세한 내용은 MHP v1.0 문서(IJCV에 제출)를 참조하세요.

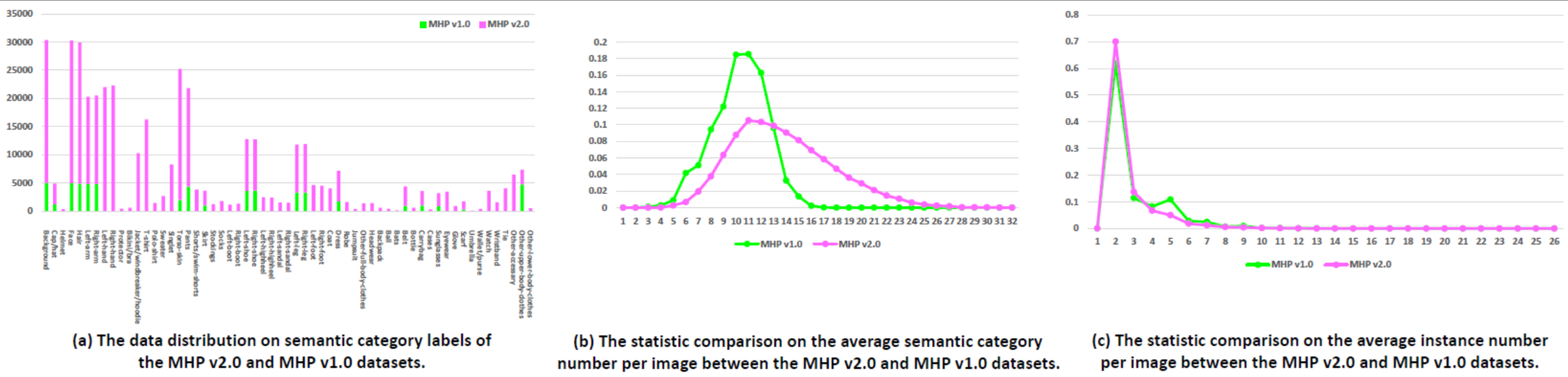

통계: MHP v2.0 데이터 세트에는 25,403개의 이미지가 포함되어 있으며 각 이미지에는 최소 2명(평균 3명)이 포함되어 있습니다. 우리는 무작위로 5,000개의 이미지와 해당 주석을 테스트 세트로 선택합니다. 나머지는 15,403개의 이미지로 구성된 훈련 세트와 5,000개의 이미지로 구성된 검증 세트를 구성합니다. 각 인스턴스에 대해 "배경" 범주(예: "모자/모자", "헬멧", "얼굴", "머리카락", "왼팔", "오른팔")를 제외하고 58개의 의미 범주가 정의되고 주석이 추가됩니다. "왼손잡이", "오른손잡이", "보호대", "비키니/브라", "재킷/바람막이/후드티", "티셔츠", "폴로셔츠", "스웨터", "싱렛", "몸통 피부", "바지", "반바지/수영 반바지", "스커트", "스타킹", "양말", "왼쪽 부츠", "오른쪽 부츠", "왼쪽 신발" ", "오른쪽 신발", "왼쪽 하이힐", "오른쪽 하이힐", "왼쪽 샌들", "오른쪽 샌들", "왼쪽 다리", "오른쪽 다리", "왼발", "오른발", "코트", "드레스", "로브", "점프슈트", "기타 전신복", "모자", "배낭", "공", "박쥐", "벨트", "병", "휴대용 가방", "케이스", "선글라스", "안경", "장갑", "스카프", "우산", "지갑", "시계", "손목밴드", "넥타이", "기타 액세서리", "기타 상체" 및 "기타 하체". 각 인스턴스에는 해당 카테고리가 현재 이미지에 나타날 때마다 완전한 주석 세트가 있습니다. 또한 16개의 밀도 높은 키 포인트("오른쪽 어깨", "오른쪽 팔꿈치", "오른쪽 손목", "왼쪽 어깨", "왼쪽 팔꿈치", "왼쪽 손목", "오른쪽-팔꿈치")를 갖춘 2D 인간 포즈입니다. 엉덩이", "오른쪽 무릎", "오른쪽 발목", "왼쪽 엉덩이", "왼쪽 무릎", "왼쪽 발목", "머리", "목", "척추" 및 "골반". 각 키 포인트에는 가시성(visible-0/occluded-1/out-of-image-2)인지 여부를 나타내는 플래그가 있으며 머리 및 인스턴스 경계 상자도 제공되어 다중 인간 포즈 추정 연구를 용이하게 합니다.
다운로드: MHP v2.0 데이터 세트는 Google 드라이브 및 Baidu 드라이브(비밀번호: uxrb)에서 사용할 수 있습니다.
자세한 내용은 MHP v2.0 논문(ACM MM'18 Best Student Paper)을 참조하세요.
다중 인간 구문 분석: 우리는 MHP v1.0 문서에서 처음 보고된 다중 인간 구문 분석 평가를 위해 두 가지 인간 중심 측정항목을 사용합니다. 두 가지 측정항목은 부분(AP p )(%) 기반 평균 정밀도와 올바르게 구문 분석된 의미 부분(PCP) 비율(%)입니다. 평가 코드는 "Multi-Human-Parsing_MHP" 저장소 아래의 "Evaluation" 폴더를 참조하세요.
다중 인간 자세 추정: MPII에 따라 mAP(%) 평가 척도를 사용합니다.
우리는 군중 장면에서 인간의 시각적 이해에 관한 CVPR 2018 워크숍(VUHCS 2018)을 조직했습니다. 이 워크샵은 NUS, CMU 및 SYSU가 공동으로 진행합니다. VUHCS 2017을 기반으로 우리는 5가지 경쟁 트랙(1인 인간 구문 분석, 다중 인간 인간 구문 분석, 1인 포즈 추정, 다중 인간 포즈 추정 및 미세 분석)을 추가하여 이 워크샵을 더욱 강화했습니다. 세분화된 다중 인간 구문 분석.
결과 제출 및 리더보드.
위챗 뉴스.
다음 논문을 참고하고 인용하는 것을 고려해 보십시오.
@article{zhao2018understanding,
title={Understanding Humans in Crowded Scenes: Deep Nested Adversarial Learning and A New Benchmark for Multi-Human Parsing},
author={Zhao, Jian and Li, Jianshu and Cheng, Yu and Zhou, Li and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
journal={arXiv preprint arXiv:1804.03287},
year={2018}
}
@article{li2017towards,
title={Multi-Human Parsing in the Wild},
author={Li, Jianshu and Zhao, Jian and Wei, Yunchao and Lang, Congyan and Li, Yidong and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
journal={arXiv preprint arXiv:1705.07206},
year={2017}
}


