Image to text chrome extension
1.0.0
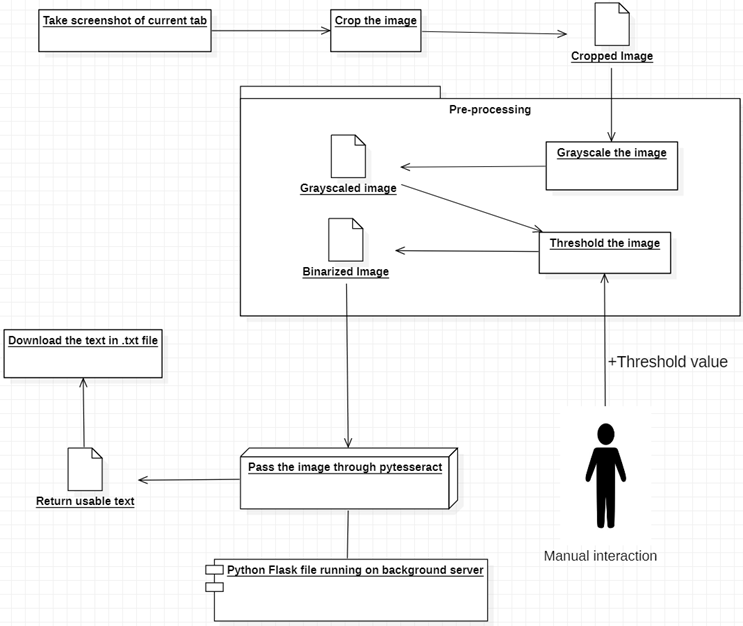
OCR 개념을 사용하여 모든 동영상이나 이미지에서 브라우저의 모든 유형의 텍스트를 인식할 수 있는 Chrome 확장 프로그램입니다. OCR은 광학 문자 인식(Optical Character Recognition)의 약식 또는 이미지의 다른 단어 찾기 텍스트입니다. Google은 이전에 Tesseract OCR이라는 엔진을 출시했습니다. 즉, Google이 이미 훈련된 텍스트 인식 기능이 있는 프로그램을 제공하므로 OCR에서 데이터를 직접 훈련하는 것과 같은 복잡한 작업을 수행할 필요가 없습니다. 그러나 Tesseract에는 정확한 결과를 얻기 위해 따라야 하는 몇 가지 사전 정의된 상황이 있으므로 보다 정확한 결과를 얻으려면 Tesseract를 통과하기 전에 이미지를 사전 처리해야 합니다. 따라서 확장 기능의 경우 먼저 현재 열려 있는 탭에서 스크린샷을 찍은 다음 캔버스를 사용하여 원하는 부분을 자르고 임계값 이진화를 사용하여 조정하여 OCR 요구 사항을 충족하여 보다 정확한 결과를 제공할 수 있습니다. 그런 다음 변환할 수 있도록 pytesseract(Tesseract의 Python 버전)로 보내세요. 마지막에 텍스트를 가져와 .txt 파일 형식으로 다운로드합니다. 따라서 사용자는 메모장이나 다른 텍스트 편집기에서 열어 필요한 경우 텍스트를 비교하고 수정할 수 있습니다.
YouTube나 다른 웹사이트에서 코드 조각을 자주 접하게 되지만, 이제는 다운로드나 복사 링크를 제공하지 않는 코드 조각을 발견할 때마다 튜토리얼 제작자들이 비디오에 쏟는 노력에 크게 감사드립니다. 그래서 해당 비디오에서 코드를 얻기 위해 tesseract 플러그인의 도움으로 이 프로젝트를 만들었으므로 해당 비디오나 이미지에서 텍스트를 추출할 수 있습니다.
모듈 구현 및 데모는 ppt에서 찾을 수 있습니다.
pip install pytesseract
npm i flask
jQuery min 파일은 변경하려는 경우 파일과 함께 첨부되거나 cdn 접근 방식을 사용하여 변경할 수 있습니다.


