feathr
v1.0.0

Feathr는 LinkedIn에서 수년간 프로덕션에 널리 사용되어온 데이터 및 AI 엔지니어링 플랫폼으로, 2022년에 오픈소스화되었습니다. 현재 LF AI & Data Foundation 산하 프로젝트입니다.
오픈 소싱 Feathr 및 Feathr on Azure에 대한 공지와 LF AI & Data Foundation의 공지를 읽어보세요.
Feathr를 사용하면 다음을 수행할 수 있습니다.
Feathr는 데이터 유출을 방지하기 위해 특정 시점의 올바른 의미론을 사용하여 기능 변환을 자동으로 계산하고 이를 교육 데이터에 결합하고 프로덕션에서 온라인으로 사용할 수 있도록 기능을 구체화 및 배포하는 AI 모델링에 특히 유용합니다.
Feathr를 시험해 보는 가장 쉬운 방법은 Feathr의 기능을 대부분 갖춘 독립형 컨테이너인 Feathr Sandbox를 사용하는 것이며 5분 안에 생산성을 발휘할 수 있습니다. 이를 사용하려면 다음 명령을 실행하면 됩니다.
# 80: Feathr UI, 8888: Jupyter, 7080: Interpret
docker run -it --rm -p 8888:8888 -p 8081:80 -p 7080:7080 -e GRANT_SUDO=yes feathrfeaturestore/feathr-sandbox:releases-v1.0.0그리고 Feathr 빠른 시작 jupyter 노트북을 볼 수 있습니다.
http://localhost:8888/lab/workspaces/auto-w/tree/local_quickstart_notebook.ipynb노트북을 실행하면 모든 기능이 UI에 등록되며 다음 위치에서 Feathr UI를 방문할 수 있습니다.
http://localhost:8081Python 환경에 Feathr 클라이언트를 설치하려면 다음을 사용하십시오.
pip install feathr또는 GitHub의 최신 코드를 사용하세요.
pip install git+https://github.com/feathr-ai/feathr.git#subdirectory=feathr_projectFeathr는 Databricks 및 Azure Synapse와 기본적으로 통합되어 있습니다.
Feathr ARM 배포 가이드에 따라 Azure에서 Feathr을 실행하세요. 이를 통해 Azure Resource Manager 템플릿을 사용하여 자동화된 배포를 빠르게 시작할 수 있습니다.
모든 것을 수동으로 설정하려면 Feathr CLI 배포 가이드를 확인하여 Azure에서 Feathr을 실행할 수 있습니다. 이를 통해 진행 상황을 이해하고 한 번에 하나의 리소스를 설정할 수 있습니다.
| 이름 | 설명 | 플랫폼 |
|---|---|---|
| NYC 택시 데모 | NYC 택시 요금 예측 샘플 데이터를 사용하여 기능을 정의, 구체화 및 등록하는 방법을 보여주는 빠른 시작 노트북입니다. | Azure Synapse, Databricks, 로컬 스파크 |
| Databricks Quickstart NYC 택시 데모 | NYC 택시 요금 예측 샘플 데이터가 포함된 빠른 시작 Databricks 노트북입니다. | 데이터브릭스 |
| 기능 임베딩 | 사전 학습된 Transformer 모델 및 호텔 리뷰 샘플 데이터를 사용하여 기능 임베딩을 정의하고 사용하는 방법을 보여주는 Feathr UDF 예입니다. | 데이터브릭스 |
| 사기 탐지 데모 | 사용자 계정, 거래 데이터 등 여러 데이터 소스를 사용하여 Feature Store를 보여주는 예입니다. | Azure Synapse, Databricks, 로컬 스파크 |
| 제품 추천 데모 | 제품 추천 시나리오가 포함된 Feathr Feature Store 예시 노트북 | Azure Synapse, Databricks, 로컬 스파크 |
더 많은 예를 보려면 Feathr 전체 기능을 읽어보세요. 다음은 몇 가지 선택된 것입니다:
Feathr는 직관적인 UI를 제공하므로 사용 가능한 모든 기능과 해당 계보를 검색하고 탐색할 수 있습니다.
Feathr UI를 사용하여 기능을 검색하고, 데이터 소스를 식별하고, 기능 계보를 추적하고, 액세스 제어를 관리할 수 있습니다. Feathr UI가 무엇을 할 수 있는지 알아보려면 여기에서 최신 라이브 데모를 확인하세요. 로그인하라는 메시지가 표시되면 다음 계정 중 하나를 사용하십시오.
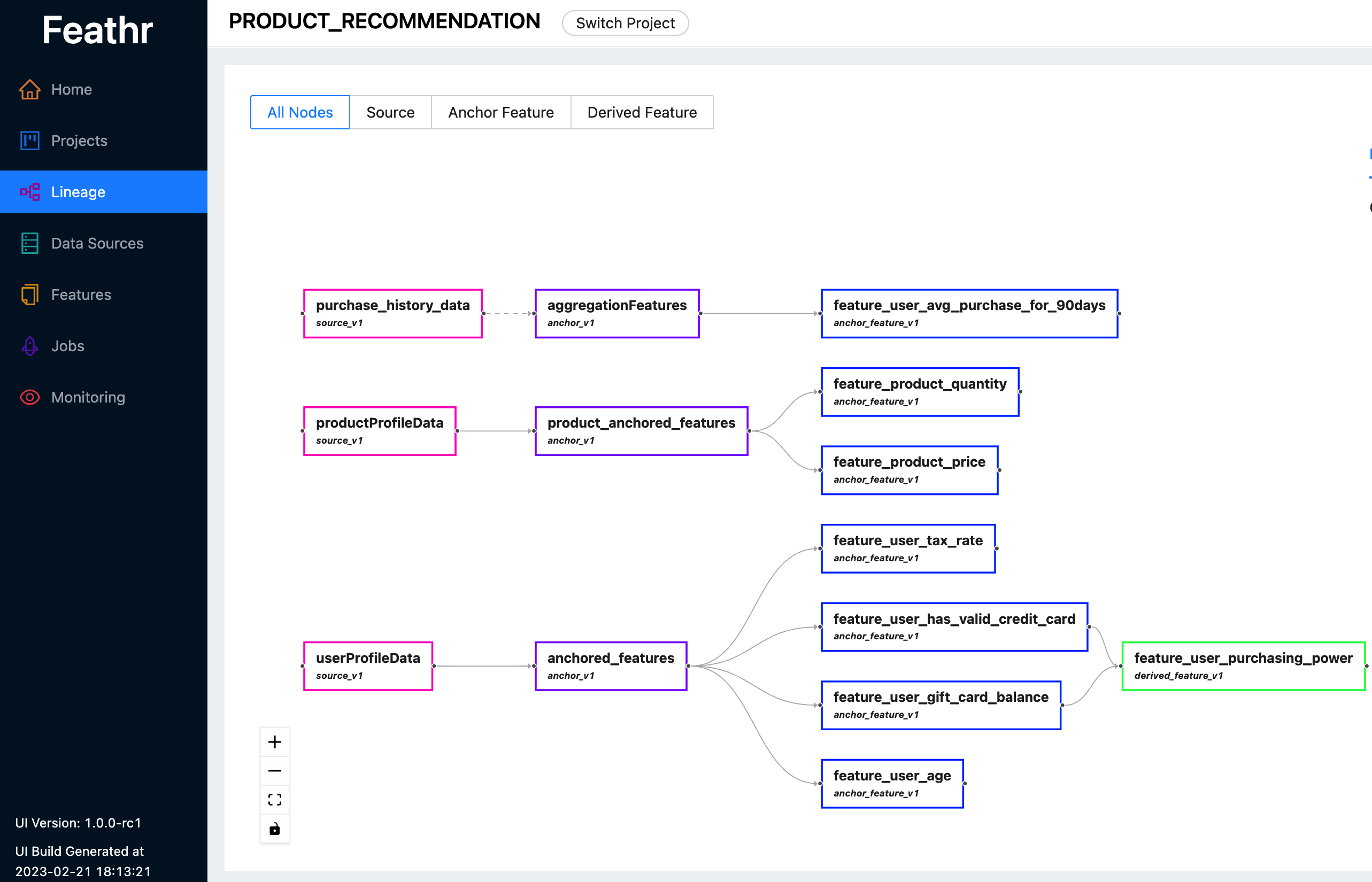
Feathr UI와 그 뒤에 있는 레지스트리에 대한 자세한 내용은 Feathr 기능 레지스트리를 참조하세요.
Feathr는 데이터 과학자의 학습 곡선을 낮추기 위해 기본 PySpark 및 Spark SQL 통합을 통해 고도로 사용자 정의 가능한 UDF를 제공합니다.
def add_new_dropoff_and_fare_amount_column ( df : DataFrame ):
df = df . withColumn ( "f_day_of_week" , dayofweek ( "lpep_dropoff_datetime" ))
df = df . withColumn ( "fare_amount_cents" , df . fare_amount . cast ( 'double' ) * 100 )
return df
batch_source = HdfsSource ( name = "nycTaxiBatchSource" ,
path = "abfss://[email protected]/demo_data/green_tripdata_2020-04.csv" ,
preprocessing = add_new_dropoff_and_fare_amount_column ,
event_timestamp_column = "new_lpep_dropoff_datetime" ,
timestamp_format = "yyyy-MM-dd HH:mm:ss" ) agg_features = [ Feature ( name = "f_location_avg_fare" ,
key = location_id , # Query/join key of the feature(group)
feature_type = FLOAT ,
transform = WindowAggTransformation ( # Window Aggregation transformation
agg_expr = "cast_float(fare_amount)" ,
agg_func = "AVG" , # Apply average aggregation over the window
window = "90d" )), # Over a 90-day window
]
agg_anchor = FeatureAnchor ( name = "aggregationFeatures" ,
source = batch_source ,
features = agg_features ) # Compute a new feature(a.k.a. derived feature) on top of an existing feature
derived_feature = DerivedFeature ( name = "f_trip_time_distance" ,
feature_type = FLOAT ,
key = trip_key ,
input_features = [ f_trip_distance , f_trip_time_duration ],
transform = "f_trip_distance * f_trip_time_duration" )
# Another example to compute embedding similarity
user_embedding = Feature ( name = "user_embedding" , feature_type = DENSE_VECTOR , key = user_key )
item_embedding = Feature ( name = "item_embedding" , feature_type = DENSE_VECTOR , key = item_key )
user_item_similarity = DerivedFeature ( name = "user_item_similarity" ,
feature_type = FLOAT ,
key = [ user_key , item_key ],
input_features = [ user_embedding , item_embedding ],
transform = "cosine_similarity(user_embedding, item_embedding)" )자세한 내용은 스트리밍 소스 수집 가이드를 읽어보세요.
자세한 내용은 Feathr의 특정 시점 정확성 및 특정 시점 가입을 읽어보세요.
빠른 시작 Jupyter Notebook을 따라 사용해 보세요. 노트북에 대한 좀 더 자세한 설명이 포함된 빠른 시작 가이드도 함께 제공됩니다.
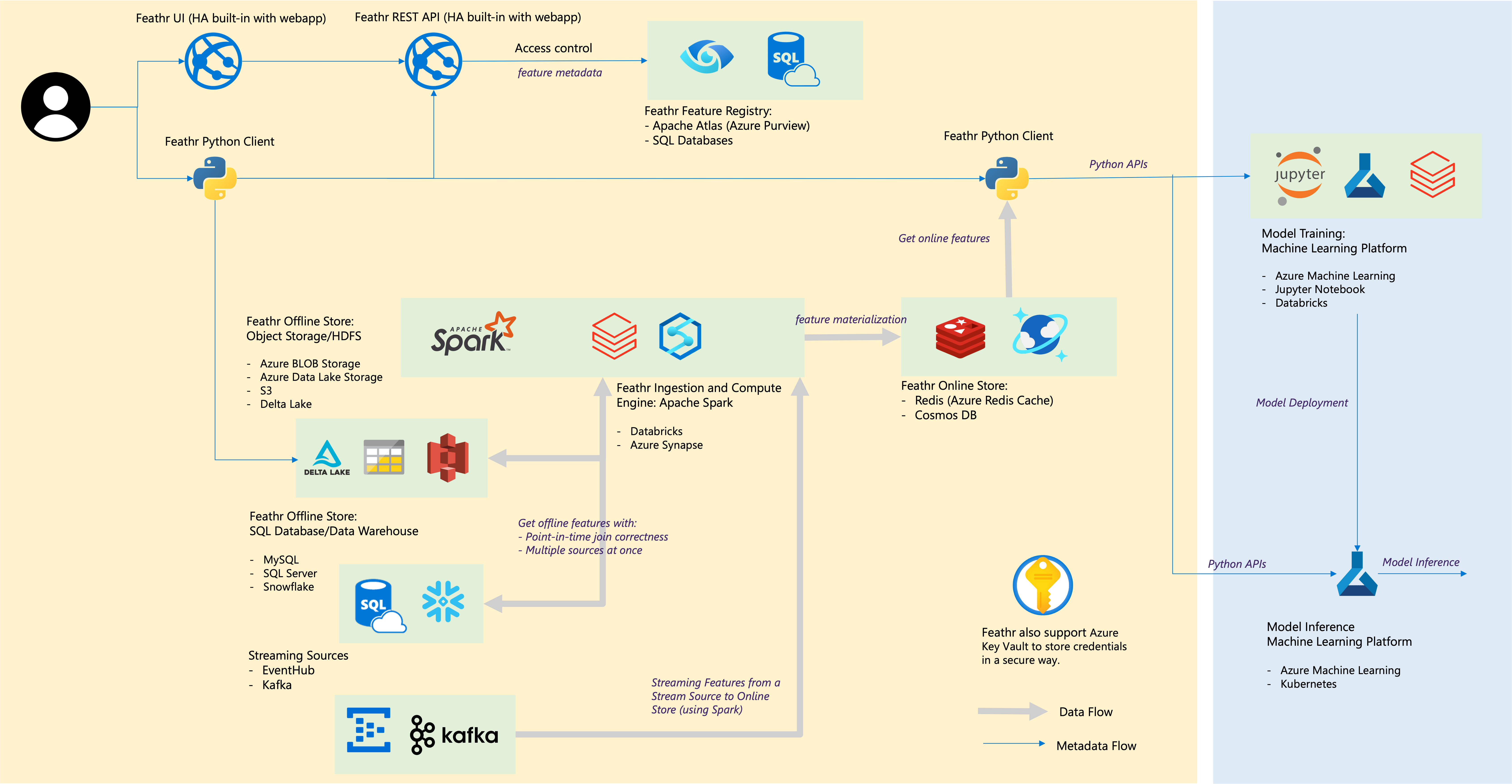
| 깃털 구성 요소 | 클라우드 통합 |
|---|---|
| 오프라인 스토어 – 객체 스토어 | Azure Blob 저장소, Azure ADLS Gen2, AWS S3 |
| 오프라인 스토어 – SQL | Azure SQL DB, Azure Synapse 전용 SQL 풀, VM의 Azure SQL, Snowflake |
| 스트리밍 소스 | 카프카, 이벤트허브 |
| 온라인 상점 | 레디스, 애저 코스모스 DB |
| 기능 등록 및 거버넌스 | Azure Purview, Azure SQL Server와 같은 ANSI SQL |
| 컴퓨팅 엔진 | Azure Synapse Spark 풀, Databricks |
| 머신러닝 플랫폼 | Azure 기계 학습, Jupyter 노트북, Databricks 노트북 |
| 파일 형식 | 쪽모이 세공 마루, ORC, Avro, JSON, Delta Lake, CSV |
| 신임장 | Azure Key Vault |
커뮤니티를 위해 구축하고 커뮤니티에 의해 구축하세요. 커뮤니티 가이드라인을 확인하세요.
질문과 토론을 위해 Slack 채널에 참여하세요(또는 초대 링크를 클릭하세요).


