metal flash attention
v1.0.1
이 저장소는 FlashAttention의 공식 구현을 Apple Silicon으로 포팅합니다. FlashAttention 알고리즘을 재현하는 최소한의 유지 관리 가능한 소스 파일 세트입니다.
다양한 주의 알고리즘(레지스터 압력, 병렬성)의 핵심 병목 현상에 초점을 맞추기 위해 단일 방향 주의만 사용합니다. 기본 알고리즘이 올바르게 수행되면 블록 희소성과 같은 사용자 정의를 추가하는 것이 비교적 쉬워집니다.
모든 것은 런타임에 JIT 컴파일됩니다. 이는 Xcode 14.2에 내장된 실행 파일에 의존했던 이전 구현과 대조됩니다.
역방향 패스는 Dao-AILab/flash-attention보다 적은 메모리를 사용합니다. 공식 구현에서는 원자 및 부분 합계를 위한 스크래치 공간을 할당합니다. Apple 하드웨어에는 기본 FP32 원자가 없습니다( metal::atomic<float> 에뮬레이션됨). 하드웨어 지원 부족을 피하려고 시도하는 동안 FlashAttention-2 이전 커널의 대역폭 및 병렬화 병목 현상이 드러났습니다. 대체 역방향 전달은 더 높은 컴퓨팅 비용(5GEMM 대신 7GEMM)으로 설계되었습니다. Attention 매트릭스의 행 및 열 차원 모두에서 100% 병렬화 효율성을 달성합니다. 가장 중요한 것은 코딩과 유지 관리가 더 쉽다는 것입니다.
레지스터 압력 병목 현상을 극복하기 위해 많은 미친 일이 이루어졌습니다. 큰 헤드 크기(예: 256)에서는 매트릭스 블록 중 어느 것도 레지스터에 들어갈 수 없습니다. 어큐뮬레이터도 할 수 없습니다. 따라서 의도적인 레지스터 유출이 수행되지만 보다 최적화된 방식으로 수행됩니다. D 따라 차단하는 세 번째 블록 차원이 주의 알고리즘에 추가되었습니다. 어텐션 매트릭스 블록의 종횡비는 레지스터 유출로 인한 대역폭 비용을 최소화하기 위해 크게 뒤틀렸습니다. 예를 들어 평행화 차원에서는 16-32이고 횡단 차원에서는 80-128입니다. D 차원을 사용하고 어떤 피연산자가 레지스터에 들어갈 수 있는지 결정하는 대규모 매개변수 파일이 있습니다. 그런 다음 경쟁하는 많은 병목 현상의 균형을 맞추는 블록 크기를 할당합니다.
최종 결과는 무한한 시퀀스 길이와 무한한 헤드 차원에서 M1 Max(83% ALU 사용률)에서 초당 4400기가의 일관된 명령입니다. 제공되는 BF16 에뮬레이션은 혼합 정밀도에 사용됩니다(Metal의 bfloat IEEE 호환 반올림이 있으며, 이는 하드웨어 BF16이 없는 구형 칩의 주요 오버헤드입니다).
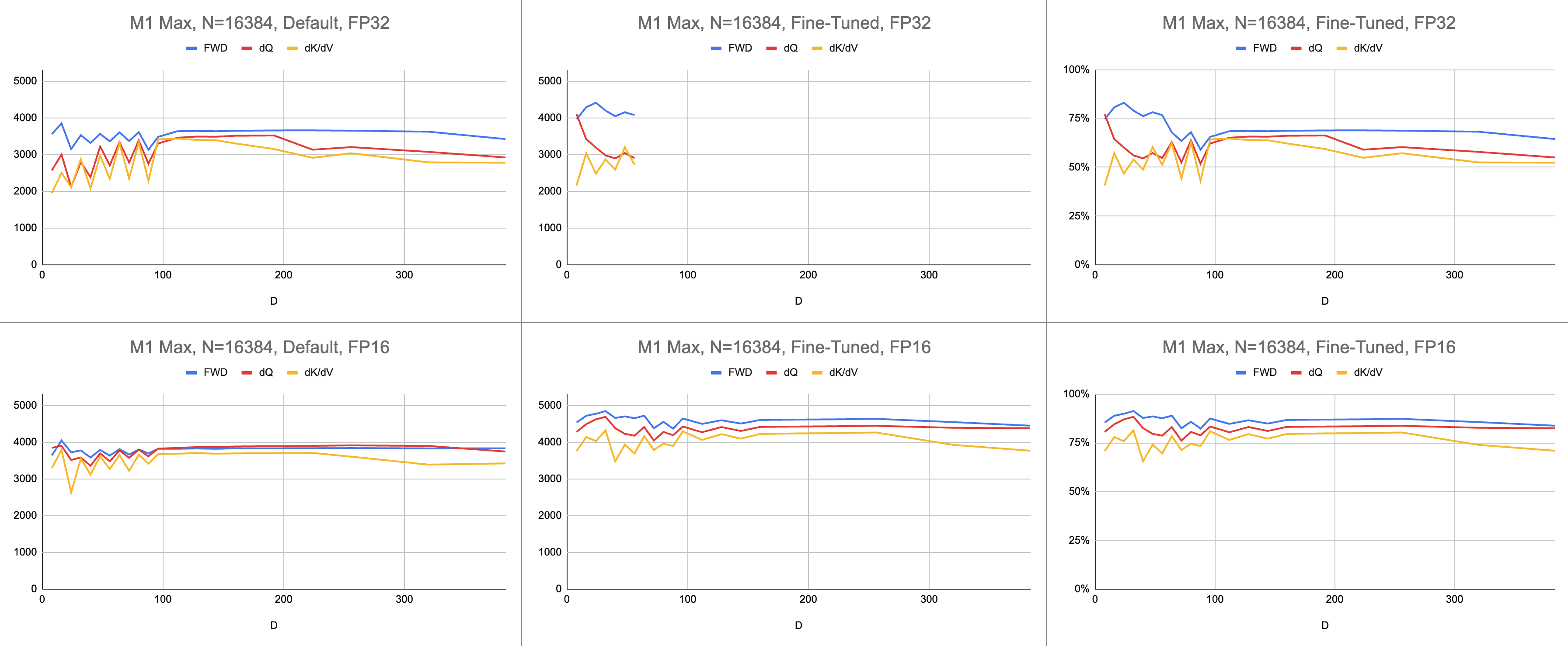
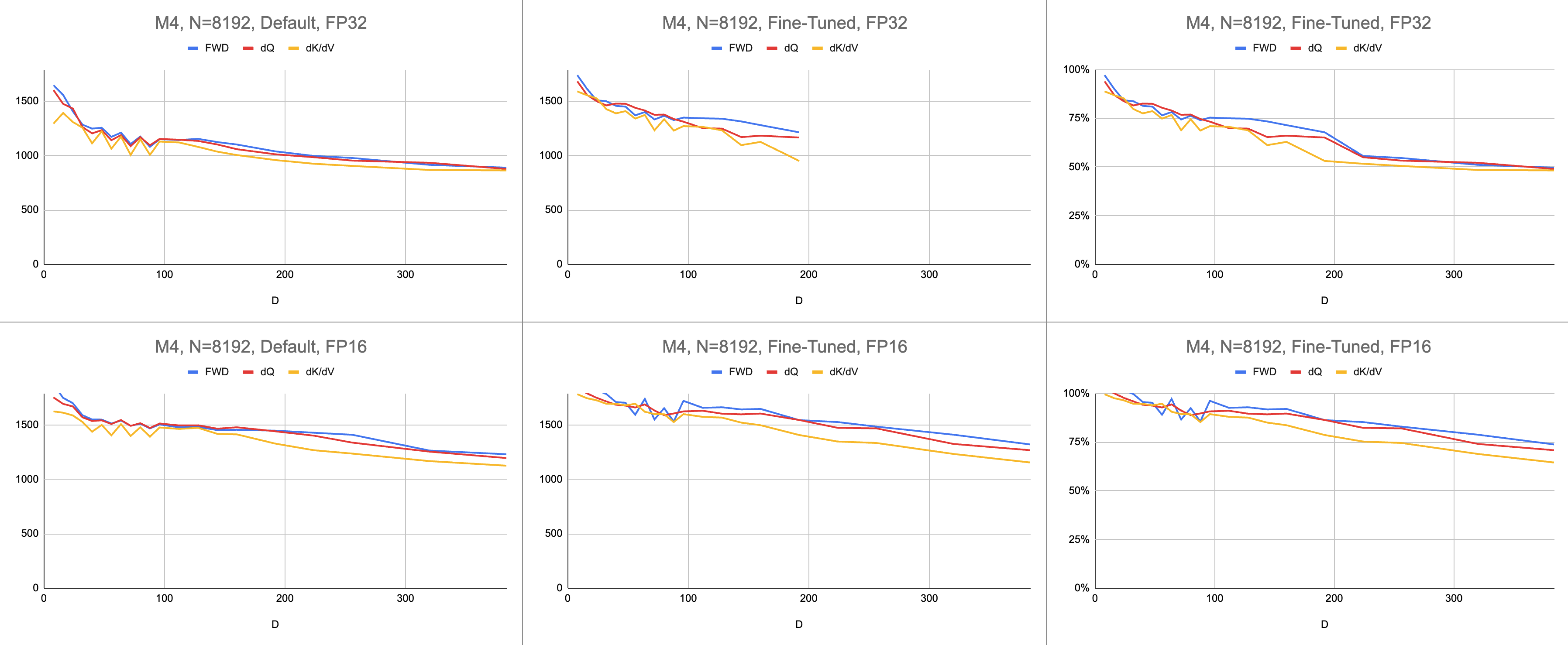
원시 데이터: https://docs.google.com/spreadsheets/d/1Xf4jrJ7e19I32J1IWIekGE9uMFTeZKoOpQ6hlUoh-xY/edit?usp=sharing
AI 분야에서 성능은 GFLOPS(초당 기가 부동 소수점 연산)로 가장 자주 보고됩니다. 이 측정항목은 모든 명령이 GEMM에서 발생한다는 단순화된 성능 모델을 반영합니다. 하드웨어가 초기 FPU에서 최신 벡터 프로세서로 발전함에 따라 가장 일반적인 부동 소수점 연산이 단일 명령으로 통합되었습니다. 융합 곱셈 덧셈(FMA). 두 개의 100x100 행렬을 곱하면 1백만 개의 FMA 명령어가 발행됩니다. 이 FMA를 두 개의 별도 지침으로 처리해야 하는 이유는 무엇입니까?
이 질문은 모든 부동 소수점 연산이 동일하게 생성되지 않는 주의와 관련이 있습니다. 소프트맥스 동안의 지수화는 단일 클록 주기에서 발생하며 대부분의 다른 명령은 FMA 장치로 이동합니다. 소프트맥스 중 일부 곱셈과 덧셈은 근처의 덧셈이나 곱셈과 융합될 수 없습니다. 이것을 FMA와 동일하게 취급하고 하드웨어가 FMA를 두 배 더 느리게 실행한다고 가정해야 할까요? GEMM 성능 모델이 셰이더가 ALU 하드웨어를 효과적으로 사용하고 있는지 여부를 어떻게 설명할 수 있는지는 불분명합니다.
기가플롭 대신 기가인스트럭션을 사용하여 셰이더의 성능이 얼마나 좋은지 이해합니다. 이는 알고리즘에 더 직접적으로 매핑됩니다. 예를 들어 하나의 GEMM은 N^3 FMA 명령어입니다. Forward attention은 두 개의 행렬 곱셈 또는 2 * D * N^2 FMA 명령을 수행합니다. 후방 주의(Dao-AILab/flash-attention 구현에 의한)는 5 * D * N^2 FMA 명령입니다. 이 표를 Flash1, Flash2 또는 Flash3 논문의 지붕선 모델과 비교해 보십시오.
| 작업 | 일하다 |
|---|---|
| 스퀘어 GEMM | N^3 |
| 앞으로 주의 | (2D + 5) * N^2 |
| 역방향 나이브 어텐션 | 4D * N^2 |
| 역방향 플래시주의 | (5D + 5) * N^2 |
| FWD + BWD 결합 | (7D + 10) * N^2 |
FP32 원자의 복잡성으로 인해 MFA는 역방향 전달에 대해 다른 접근 방식을 사용했습니다. 이것은 컴퓨팅 비용이 더 높습니다. 역방향 전달을 dQ 및 dK/dV 두 개의 개별 커널로 분할합니다. 드롭다운에 의사코드가 표시됩니다. 이를 Flash1, Flash2 또는 Flash3 논문의 알고리즘 중 하나와 비교해 보세요.
| 작업 | 일하다 |
|---|---|
| 앞으로 | (2D + 5) * N^2 |
| 역방향 dQ | (3D + 5) * N^2 |
| 역방향 dK/dV | (4D + 5) * N^2 |
| FWD + BWD 결합 | (9D + 15) * N^2 |
// Forward
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// (m, l, P) = softmax(m, l, S * scaleFactor)
//
// O *= correction
// load V[c]
// O += P * V
// }
// O /= l
//
// L = m + logBaseE(l)
//
// Backward Query
// D = dO * O
//
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// P = exp(S - L)
//
// load V[c]
// dP = dO * V^T
// dS = P * (dP - D) * scaleFactor
//
// load K[c]
// dQ += dS * K
// }
//
// Backward Key-Value
// for r in 0..<R {
// load Q[r]
// load L[r]
// S^T = K * Q^T
// P^T = exp(S^T - L)
//
// load dO[r]
// dV += P^T * dO
//
// load dO[r]
// load D[r]
// dP^T = V * dO^T
// dS^T = P^T * (dP^T - D) * scaleFactor
//
// load Q[r]
// dK += dS^T * Q
// }성능은 컴퓨팅 작업량을 계산한 다음 초로 나누어 측정합니다. 최종 결과는 "초당 기가명령"입니다. 다음으로 지붕선 모델이 필요합니다. 아래 표는 GFLOPS의 절반으로 계산된 GINSTRS의 지붕선을 보여줍니다. ALU 활용률은 (초당 실제 기가 명령 수) / (초당 예상 기가 명령 수)입니다. 예를 들어 M1 Max는 일반적으로 혼합 정밀도로 80%의 ALU 활용률을 달성합니다.
이 모델에는 한계가 있습니다. 작은 헤드 치수에서는 M3세대와 함께 분해됩니다. 여러 컴퓨팅 단위를 동시에 활용하여 겉보기 활용도가 100%를 넘을 수 있습니다. 대부분의 경우 벤치마크는 성능이 얼마나 남아 있는지에 대한 정확한 모델을 제공합니다.
var operations : Int
switch benchmarkedKernel {
case . forward :
operations = 2 * headDimension + 5
case . backwardQuery :
operations = 3 * headDimension + 5
case . backwardKeyValue :
operations = 4 * headDimension + 5
}
operations *= ( sequenceDimension * sequenceDimension )
operations *= dispatchCount
// Divide the work by the latency, resulting in throughput.
let instrs = Double ( operations ) / Double ( latencySeconds )
let ginstrs = Int ( instrs / 1e9 )| 하드웨어 | GFLOPS | 긴스트르스 |
|---|---|---|
| M1 맥스 | 10616 | 5308 |
| M4 | 3580 | 1790년 |
Metal 포트는 공식 FlashAttention 저장소와 얼마나 잘 비교됩니까? "원자 dQ" 알고리즘을 사용하여 100% 성능을 달성했다고 상상해 보세요. 그런 다음 실제 MFA 저장소로 전환한 결과 모델 교육이 4배 더 느린 것으로 나타났습니다. 이는 공식 저장소의 지붕선의 25%입니다. 이 비율을 얻으려면 세 커널 모두의 평균 ALU 사용률에 7 / 9 곱합니다. Apple 하드웨어에 대한 통계에는 좀 더 미묘한 모델이 사용되었지만 이것이 그 핵심입니다.
Nvidia 하드웨어의 활용도를 계산하기 위해 FP16/BF16 ALU에 GFLOPS를 사용했습니다. 논문의 각 그래프에서 가장 높은 GFLOPS를 312000(A100 SXM), 989000(H100 SXM)으로 나눴습니다. 더 큰 헤드 크기와 레지스터 집약적 커널(역방향 전달)의 경우 벤치마크가 보고되지 않았습니다. 나는 그들이 무한 헤드 치수에서 레지스터 압력 문제를 해결하지 못했다는 것을 확인했습니다. 예를 들어 누산기는 항상 레지스터에 보관됩니다. 이 글을 쓰는 시점에는 D=256 역방향 그래디언트가 올바른 결과로 실행된다는 구체적인 증거를 본 적이 없습니다.
| A100, 플래시2, FP16 | 디 = 64 | 디 = 128 | 디 = 256 |
|---|---|---|---|
| 앞으로 | 192000 | 223000 | 0 |
| 뒤로 | 170000 | 196000 | 0 |
| 앞으로 + 뒤로 | 176000 | 203000 | 0 |
| H100, 플래시3, FP16 | 디 = 64 | 디 = 128 | 디 = 256 |
|---|---|---|---|
| 앞으로 | 497000 | 648000 | 756000 |
| 뒤로 | 474000 | 561000 | 0 |
| 앞으로 + 뒤로 | 480000 | 585000 | 0 |
| H100, 플래시3, FP8 | 디 = 64 | 디 = 128 | 디 = 256 |
|---|---|---|---|
| 앞으로 | 613000 | 1008000 | 1171000 |
| 뒤로 | 0 | 0 | 0 |
| 앞으로 + 뒤로 | 0 | 0 | 0 |
| A100, 플래시2, FP16 | 디 = 64 | 디 = 128 | 디 = 256 |
|---|---|---|---|
| 앞으로 | 62% | 71% | 0% |
| 앞으로 + 뒤로 | 56% | 65% | 0% |
| H100, 플래시3, FP16 | 디 = 64 | 디 = 128 | 디 = 256 |
|---|---|---|---|
| 앞으로 | 50% | 66% | 76% |
| 앞으로 + 뒤로 | 48% | 59% | 0% |
| M1 아키텍처, FP16 | 디 = 64 | 디 = 128 | 디 = 256 |
|---|---|---|---|
| 앞으로 | 86% | 85% | 86% |
| 앞으로 + 뒤로 | 62% | 63% | 64% |
| M3 아키텍처, FP16 | 디 = 64 | 디 = 128 | 디 = 256 |
|---|---|---|---|
| 앞으로 | 94% | 91% | 82% |
| 앞으로 + 뒤로 | 71% | 69% | 61% |
| 2020년에 생산된 하드웨어 | 디 = 64 | 디 = 128 | 디 = 256 |
|---|---|---|---|
| A100 | 56% | 65% | 0% |
| M1—M2 아키텍처 | 62% | 63% | 64% |
| 2023년에 생산된 하드웨어 | 디 = 64 | 디 = 128 | 디 = 256 |
|---|---|---|---|
| H100(FP8 GFLOPS 사용) | 24% | 30% | 0% |
| H100(FP16 GFLOPS 사용) | 48% | 59% | 0% |
| M3—M4 아키텍처 | 71% | 69% | 61% |
더 많은 계산을 수행함에도 불구하고 Apple 하드웨어는 동일한 작업을 수행하는 Nvidia 하드웨어보다 더 빠르게 변환기를 훈련합니다. 서로 다른 GPU 간의 크기 차이를 정규화합니다. GPU가 얼마나 효율적으로 활용되는지에만 집중합니다.
아마도 메인 저장소는 FP32 원자성을 피하고 GPU 코어에 맞지 않을 때 의도적으로 레지스터를 유출하는 알고리즘을 시도해야 할 것입니다. 가능한 문제 크기의 작은 하위 집합에 대해 하드 코딩된 지원을 제공하므로 이는 가능성이 낮아 보입니다. 동기는 D 가 2의 거듭제곱이고 128보다 작은 가장 일반적인 모델을 지원하는 것 같습니다. 그 밖의 경우 사용자는 완전히 다른 기본 모델을 사용할 수 있는 대체 폴백 구현(예: MFA 저장소)에 의존해야 합니다. 연산.
macOS에서는 Swift 패키지를 다운로드하고 -Xswiftc -Ounchecked 사용하여 컴파일합니다. 이 컴파일러 옵션은 성능에 민감한 CPU 코드에 필요합니다. 릴리스 모드는 단일 변경 사항이 있을 때마다 전체 코드베이스를 처음부터 다시 컴파일해야 하기 때문에 사용할 수 없습니다. Finder에서 Git 저장소로 이동하여 Package.swift 두 번 클릭하세요. Xcode 창이 팝업되어야 합니다. 왼쪽에는 파일 계층이 있어야 합니다. 계층 구조를 풀 수 없다면 문제가 발생한 것입니다.
git clone https://github.com/philipturner/metal-flash-attention
swift build -Xswiftc -Ounchecked # Does it even compile?
swift test -Xswiftc -Ounchecked # Does the test suite finish in ~10 seconds?
또는 SwiftUI 템플릿을 사용하여 새 Xcode 프로젝트를 만듭니다. "Hello, world!" 를 재정의합니다. String 반환하는 함수에 대한 호출이 포함된 문자열입니다. 이 함수는 선택한 스크립트를 실행한 다음 exit(0) 호출하므로 화면에 아무것도 렌더링하기 전에 앱이 충돌합니다. Xcode 콘솔의 출력을 코드에 대한 피드백으로 사용합니다. 이 작업 흐름은 macOS 및 iOS와 모두 호환됩니다.
Project > your project's name > Build Settings > Swift Compiler - Code Generation > Optimization Level 을 통해 -Xswiftc -Ounchecked 옵션을 추가하세요. 표의 두 번째 열에는 프로젝트 이름이 나열됩니다. 드롭다운에서 기타를 클릭하고 나타나는 패널에 -Ounchecked 입력하세요. 다음으로 이 저장소를 Swift 패키지 종속성으로 추가하세요. Tests/FlashAttention 아래에서 일부 테스트를 살펴보세요. 이러한 테스트 중 하나에 대한 원시 소스 코드를 프로젝트에 복사합니다. 이전 단락의 함수에서 테스트를 호출합니다. 콘솔에 표시되는 내용을 검사합니다.
Metal 코드 생성을 수정하려면(예: 멀티 헤드 또는 마스크 지원 추가) 원시 Swift 코드를 Xcode 프로젝트에 복사하세요. 별도의 폴더에 있는 git clone 사용하거나 GitHub에서 원시 파일을 ZIP으로 다운로드하세요. metal-flash-attention 포크에 연결하고 변경 사항을 클라우드에 자동 저장하는 방법도 있지만 설정이 더 어렵습니다. 이전 단락에서 Swift 패키지 종속성을 제거합니다. 선택한 테스트를 다시 실행하세요. 콘솔에 무언가를 컴파일하고 표시합니까?
다음 폴더 중 하나에서 여러 줄 문자열 리터럴 중 하나를 찾습니다.
Sources/FlashAttention/Attention/AttentionKernel
Sources/FlashAttention/GEMM/GEMMKernel
그 중 하나에 임의의 텍스트를 추가하십시오. 프로젝트를 다시 컴파일하고 실행하십시오. 뭔가 크게 잘못될 것입니다. 예를 들어 Metal 컴파일러에서 오류가 발생할 수 있습니다. 이런 일이 발생하지 않으면 다른 곳에서 다른 코드 줄을 엉망으로 만들어 보십시오. 테스트가 여전히 통과되면 Xcode가 변경 사항을 등록하지 않는 것입니다.
블록 희소성 등을 코딩하는 작업을 진행하세요. 코드가 전혀 작동하는지, 빠르게 작동하는지, 모든 문제 규모에서 빠르게 작동하는지에 대한 피드백을 받으세요. 원시 소스 코드를 앱에 통합하거나 다른 프로그래밍 언어로 번역하세요.


