eye in the sky
1.0.0
위성 이미지 분류, InterIIT Techmeet 2018, IIT 봄베이.
팀: Manideep Kolla, Aniket Mandle, Apoorva Kumar
이 저장소에는 U-Net이라는 두 가지 알고리즘의 구현이 포함되어 있습니다. 생의학적 이미지 분할을 위한 컨볼루셔널 네트워크와 위성 이미지 분류 문제를 위해 수정된 피라미드 장면 구문 분석 네트워크입니다.
main_unet.py : 지상 진실 인코딩을 포함하여 U-Net 아키텍처로 알고리즘을 훈련하기 위한 Python 코드입니다.unet.py : U-Net 레이어 구현이 포함되어 있습니다.test_unet.py : 테스트, 정확도 계산, 훈련 및 검증을 위한 혼동 행렬 계산, 훈련, 검증 및 테스트 이미지에 대한 U-Net 모델에 의한 예측 저장을 위한 코드입니다.Inter-IIT-CSRE : 모든 교육, 검증 광고 테스트 데이터가 포함되어 있습니다.Comparison_Test.pdf : 테스트 데이터와 데이터에 대한 U-Net 모델 예측을 나란히 비교합니다.train_predictions : 훈련 및 검증 이미지에 대한 U-Net 모델 예측입니다.plots : U-Net 아키텍처의 훈련 및 검증을 위한 정확도 및 손실 플롯입니다.Test_images , Test_outputs : U-Net 모델에 대한 테스트 이미지와 해당 예측을 포함합니다.class_masks , compare_pred_to_gt , images_for_doc : 문서화를 위한 여러 이미지가 포함되어 있습니다.PSPNet : 위성 이미지 분류에 PSPNet 알고리즘을 구현하기 위한 교육 파일이 포함되어 있습니다. 저장소를 복제하고 현재 작업 디렉터리를 복제된 디렉터리로 변경합니다. 이름이 train_predictions 및 test_outputs 인 폴더를 생성하여 교육 및 테스트 이미지에 대한 모델 예측 출력을 저장합니다. 저장소에 이미 이러한 폴더가 포함되어 있으므로 지금은 필요하지 않습니다.
$ git clone https://github.com/manideep2510/eye-in-the-sky.git
$ cd eye-in-the-sky
$ mkdir train_predictions
$ mkdir test_outputs
U-Net 모델을 훈련하고 가중치를 저장하려면 아래 명령을 실행하십시오.
$ python3 main_unet.py
U-Net 모델을 테스트하고, 정확도를 계산하고, 훈련 및 검증을 위한 혼동 행렬을 계산하고, 훈련, 검증 및 테스트 이미지에 대한 모델별 예측을 저장합니다.
$ python3 test_unet.py
코드를 실행하는 동안 xrange is not defined 오류가 발생할 수 있습니다. 이 오류는 코드 오류로 인한 것이 아니라 데이터세트를 읽는 데 사용했던 libtiff 라는 Python 패키지(패키지 소스 코드의 일부는 python2에 있고 일부는 python3에 있음)가 최신이 아니기 때문에 발생합니다. 이미지는 .tif 형식입니다. openCV 또는 PIL과 같은 다른 라이브러리는 4채널 .tif 이미지 읽기를 제대로 지원하지 않기 때문에 이미지를 읽을 수 없었습니다.
이 오류는 libtiff 라이브러리의 소스 코드를 편집하여 해결할 수 있습니다.
오류가 발생한 라이브러리의 소스 코드에 있는 파일로 이동하고(파일 이름은 오류가 표시될 때 터미널에 표시됩니다) 파일의 모든 xrange() (python2) 함수를 range() (파이썬3).
우리는 사용자가 처음부터 훈련할 필요가 없도록 합리적으로 좋은 사전 훈련된 가중치를 제공하고 있습니다.
| 설명 | 일 | 데이터세트 | 모델 |
|---|---|---|---|
| UNet 아키텍처 | 위성영상 분류 | IITB 데이터 세트( Inter-IIT-CSRE 폴더 참조) | 다운로드(.h5) |
사전 훈련된 가중치를 사용하려면 test_unet.py 에 언급된 .h5(가중치 파일) 파일의 이름을 필요한 경우 다운로드한 가중치 파일의 이름과 일치하도록 변경하세요.
이제 논의해보자
1. 이 프로젝트의 내용은,
2. 우리가 사용하고 실험한 아키텍처
3. 프로젝트에서 사용한 몇 가지 새로운 교육 전략
원격탐사(Remote Sensing)는 일반적으로 항공기나 위성을 통해 먼 거리에서 물체나 지역에 대한 정보를 얻는 과학입니다.
우리는 위성영상 분류 문제를 의미분할 문제로 인식하고, 이를 해결하기 위해 딥러닝에 의미분할 알고리즘을 구축했습니다.
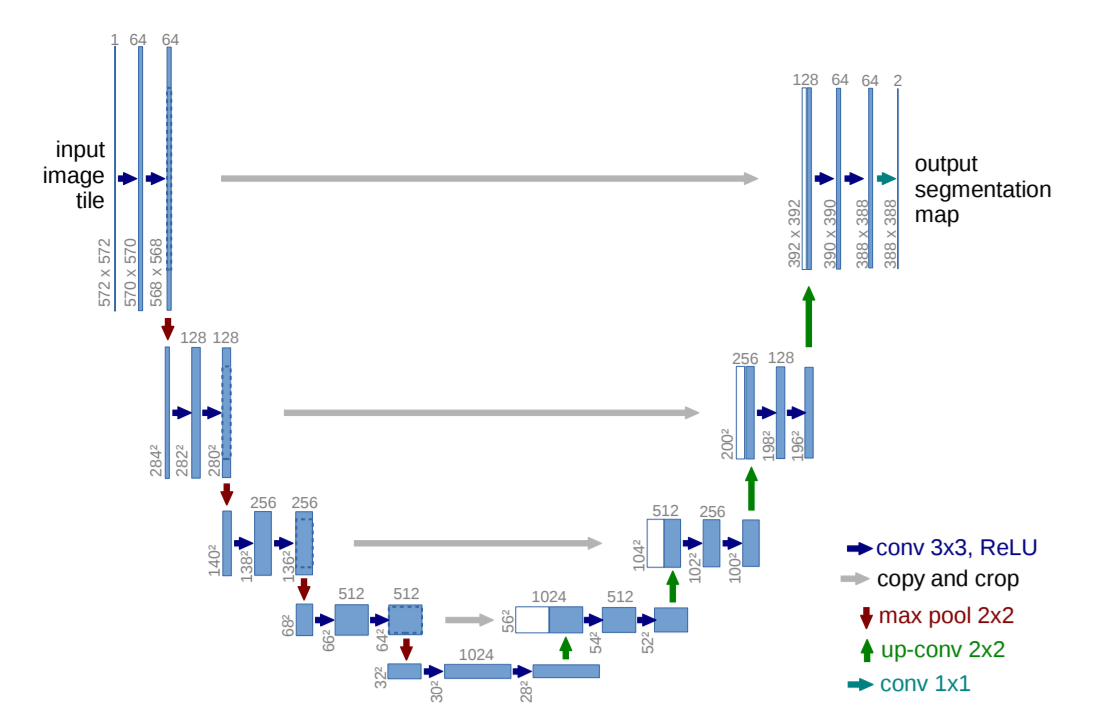
U-Net: 생의학 이미지 분할을 위한 컨벌루션 네트워크
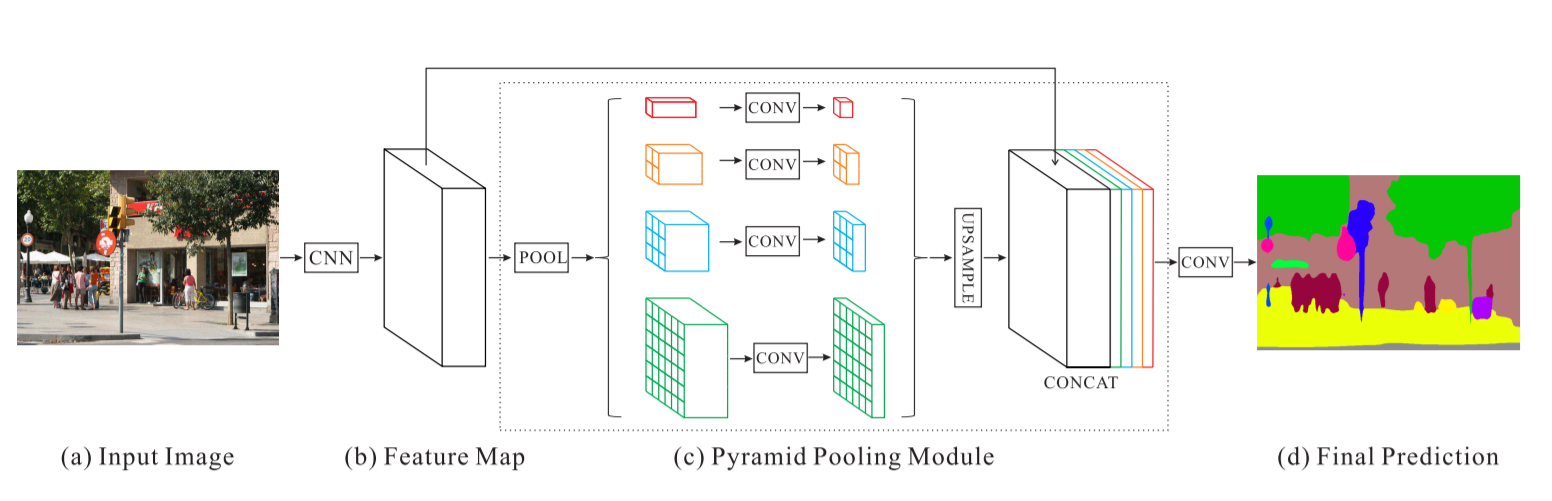
피라미드 장면 분석 네트워크 - PSPNet
제공되는 Ground Truth는 3채널 RGB 이미지입니다. 현재 데이터 세트에는 분류할 클래스가 9개 있으므로 Ground Truth에는 고유한 RGB 값이 9개만 있습니다. 이러한 9개의 서로 다른 RGB 값은 원-핫 인코딩되어 특정 클래스를 나타내는 각 채널과 함께 9개 채널 인코딩된 지상 진실을 생성합니다.
아래는 인코딩 방식입니다
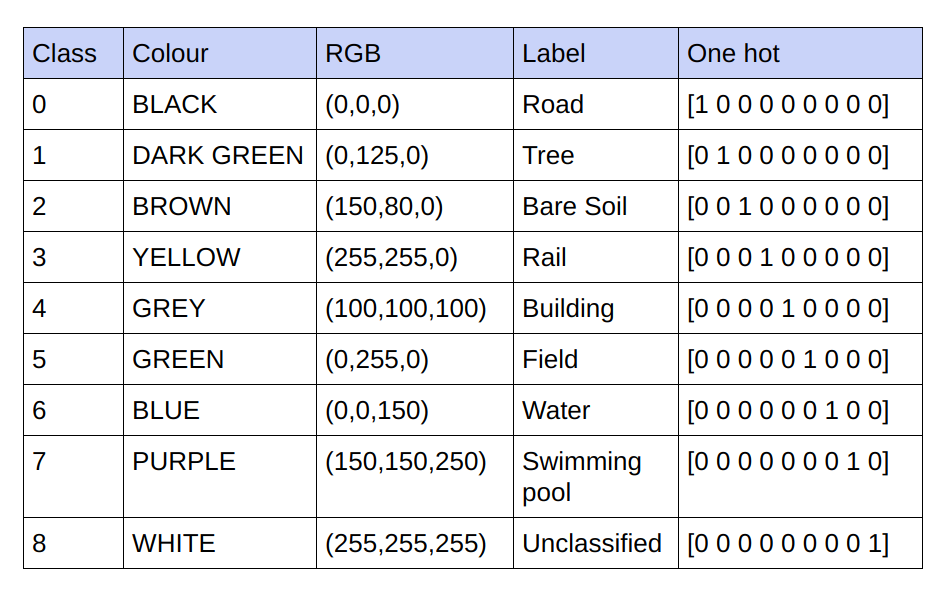
인코딩된 Ground Truth의 각 채널을 클래스로 구현

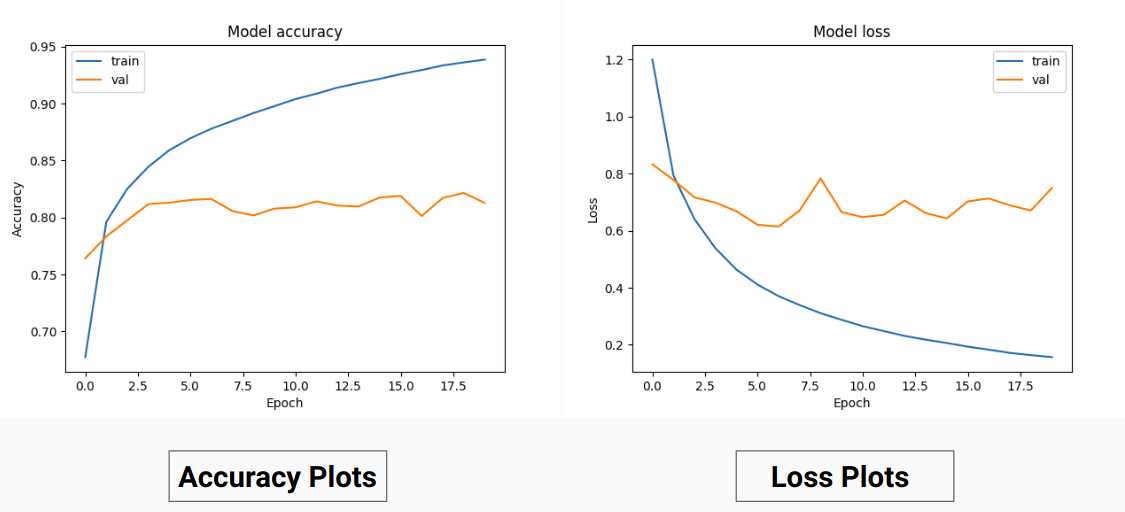
따라서 실제 RGB 값을 학습하는 대신 이를 다른 클래스의 원-핫 값으로 변환했습니다. 이 접근 방식은 훈련에 RGB 지상 진실 값을 사용할 때 검증 정확도 71% 및 훈련 정확도 65%와 비교하여 검증 정확도 85% 및 훈련 정확도 92%를 제공했습니다.
이는 효과적인 정규화 기술로 작용하기 때문에 훈련 데이터의 실제값의 분산과 평균이 감소하기 때문일 수 있습니다. 이 훈련 기법의 더 나은 성능은 또한 모델이 클래스를 나타내는 각 맵에 9개의 특징 맵이 포함된 출력을 제공하기 때문입니다. 즉, 이 훈련 기법은 모델이 9개 클래스 각각에 대해 어느 정도 별도로 훈련된 것처럼 작동합니다( 그러나 여기서 특정 클래스에 해당하는 한 채널에 대한 예측은 다른 클래스에 따라 다릅니다 .
위성 이미지 분류에 대한 PSPNet 결과:
훈련 정확도 - 49% 검증 정확도 - 60%
이유:
U-넷:
수정된 U-Net:
훈련 및 검증을 위해 Inter-IIT-CSRE/The-Eye-in-the-Sky-dataset 폴더에 있는 14개의 '.tif' 이미지를 사용했습니다.
훈련을 위해 데이터세트의 처음 13개 이미지를 사용했고 검증을 위해 14번째 이미지를 사용했습니다 .
sat 폴더의 각 위성 이미지에는 R(밴드 1), G(밴드 2), B(밴드 3) 및 NIR(밴드 4)의 4개 채널이 포함되어 있습니다.
gt 디렉토리의 실제 이미지는 RGB 이미지이며 도로, 건물, 나무, 잔디, 맨땅, 물, 철도 및 수영장의 8개 클래스를 나타냅니다.
검증 세트로 하나의 이미지(14번째 이미지)만 고려한 이유는 그것이 데이터 세트에서 가장 작은 이미지 중 하나이고 데이터 세트가 매우 작기 때문에 훈련에 더 적은 데이터를 남기고 싶지 않기 때문입니다. 우리가 고려한 검증 세트(14번째 이미지)에는 훈련 정확도가 꽤 높은 3개 클래스(Bare soil, Rail, Swimmimg poll)가 없습니다. 모든 클래스가 포함된 이미지를 고려했다면 유효성 검사 정확도가 더 좋았을 것입니다(데이터 세트의 이미지에는 모든 클래스가 포함되어 있지 않으며 모든 이미지에 하나 이상의 클래스가 누락되어 있습니다).
줄무늬 자르기:
주어진 고화질 이미지에서 충분한 훈련 데이터를 얻으려면 U-Net 구현의 약 31M 매개변수를 가진 분류기를 훈련하는 데 자르기가 필요합니다. 64x64의 자르기 크기에서는 개별 클래스가 과소 표현되고 객체의 기하학적 구조와 연속성이 손실되어 컨볼루션의 시야가 감소합니다.
128x128 픽셀의 자르기 창을 32의 보폭으로 사용하여 15887개의 훈련 414개 검증 이미지를 생성합니다.
이미지 크기:
자르기 전에 훈련 이미지의 크기는 스트라이드 자르기 중 편의를 위해 스트라이드의 배수로 변환됩니다.
아니오의 경우. 자르기의 수는 처음에 제로 패딩을 시도한 이미지 크기의 배수가 아닙니다. 패딩을 추가하면 훈련 및 테스트 이미지에 원치 않는 인공물이 검은색 픽셀 형태로 추가되어 잘못된 데이터 및 이미지 경계에 대한 훈련으로 이어진다는 것을 깨달았습니다.
또는 이미지의 가장 오른쪽 측면과 하단에 추가 픽셀을 추가하여 이미지 크기를 올바르게 변경했습니다. 그래서 우리는 이미지의 가장 왼쪽 부분부터 오른쪽 부족한 부분까지의 차이를 패딩했고, 이미지의 상단과 하단에도 유사하게 패딩했습니다.
훈련 예시 1: 훈련 데이터의 이미지 '2.tif'
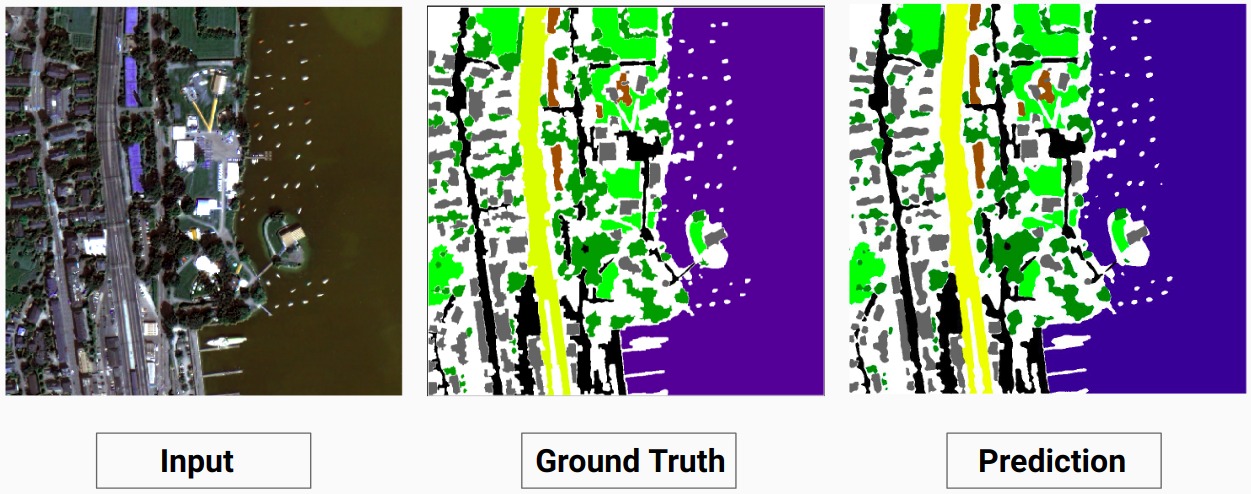
훈련 예시 2: 훈련 데이터의 이미지 '4.tif'
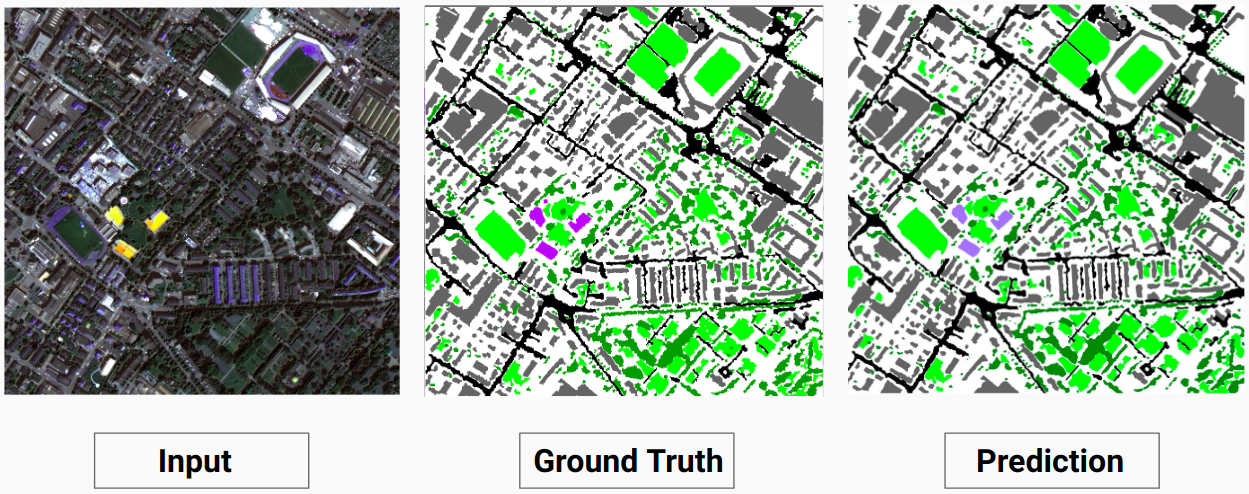
검증 예: 데이터세트의 이미지 '14.tif'

우리 모델은 인간 주석자가 할 수 없었던 일부 클래스를 예측할 수 있습니다. 이미지에서 식별할 수 없는 클래스는 사람 주석자에 의해 흰색 픽셀로 표시됩니다. 우리 모델은 이러한 흰색 픽셀 중 일부를 일부 클래스로 올바르게 예측할 수 있지만 흰색 픽셀이 모델에 의해 별도의 클래스로 간주되므로 전체 정확도가 감소했습니다.
여기서 모델은 흰색 픽셀을 정확하고 입력 이미지에서 명확하게 볼 수 있는 건물로 예측할 수 있습니다.
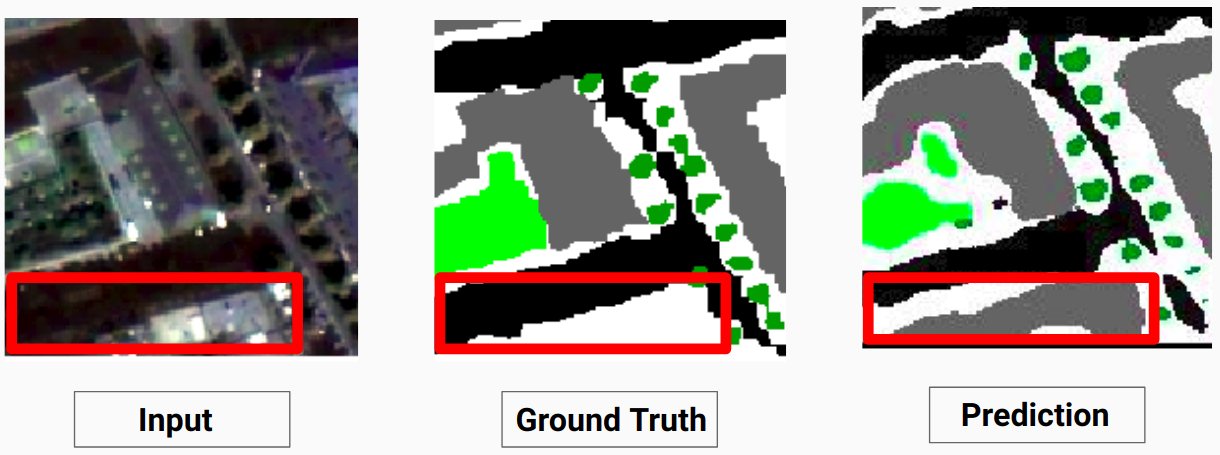
테스트 이미지와 모델에 의한 예측 출력 간의 비교를 보려면 Comparison_Test.pdf 확인하세요.
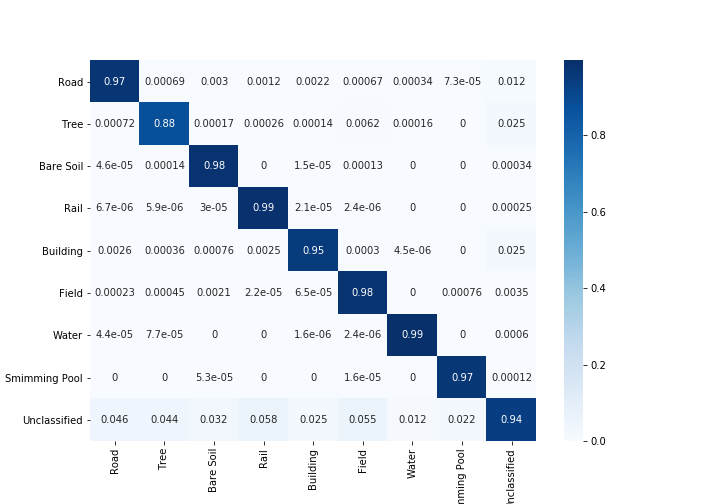
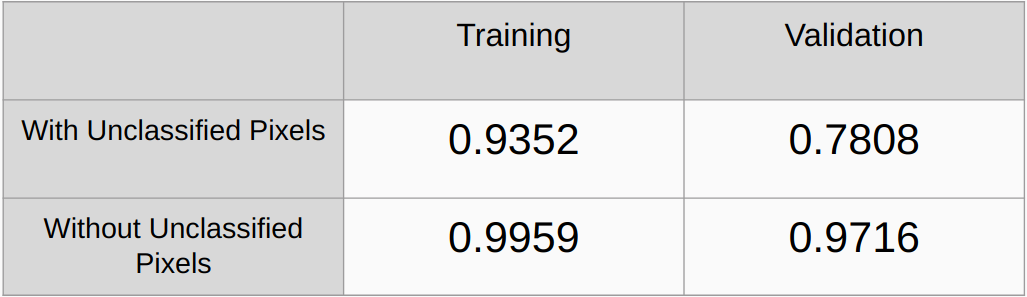
분류되지 않은 픽셀을 고려한 경우와 고려하지 않은 경우의 카파 계수
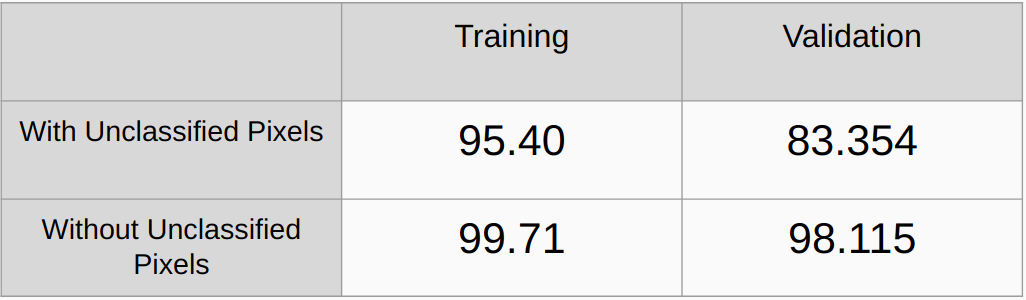
분류되지 않은 픽셀을 고려한 경우와 고려하지 않은 경우의 전체 정확도
L2 Regularizarion, Drupout 등 정규화 방법을 추가하고 성능을 확인해야 함
RGB 값을 수동으로 찾는 대신 실제 실제 RGB 값을 모두 자동으로 감지하고 원핫 인코딩하는 알고리즘을 구현합니다.
[1] U-Net: 생의학적 이미지 분할을 위한 컨볼루셔널 네트워크, Olaf Ronneberger, Philipp Fischer 및 Thomas Brox
[2] 피라미드 장면 분석 네트워크, Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, Jiaya Jia
[3] 딥 러닝을 통한 의미론적 분할에 대한 2017 가이드, Sasank Chilamkurthy


