linformer pytorch
version
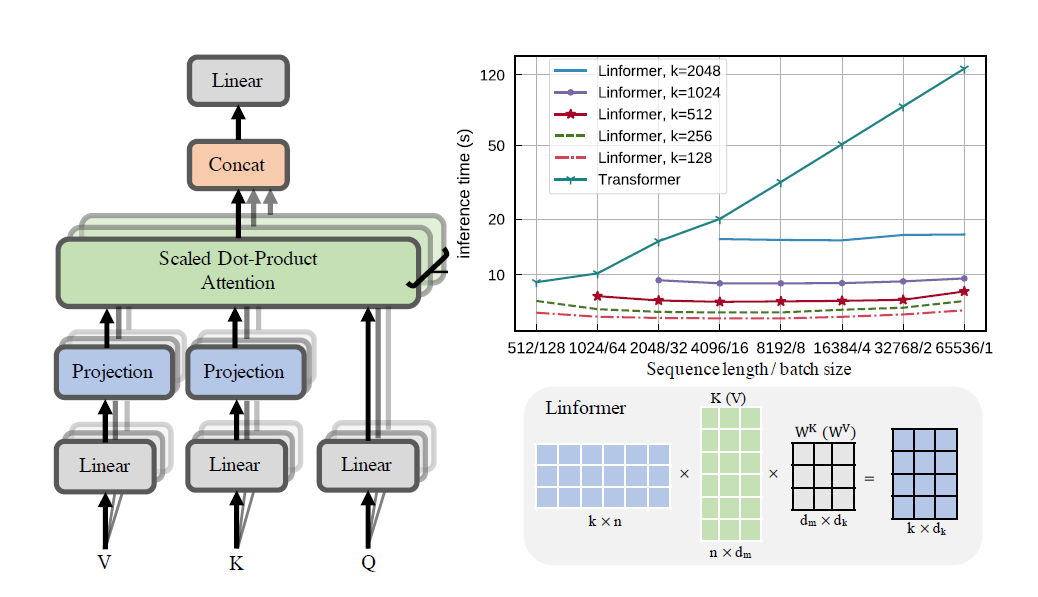
Linformer 논문의 실제 구현. 이는 n의 선형 복잡도에만 주목하므로 최신 하드웨어에서 매우 긴 시퀀스 길이(1mil+)를 처리할 수 있습니다.
이 저장소는 인코더 및 디코더 모듈을 갖춘 Attention Is All You Need 스타일 변환기입니다. 여기서 참신한 점은 이제 주의 머리를 선형으로 만들 수 있다는 것입니다. 아래에서 사용 방법을 확인하세요.
이것은 wikitext-2에서 검증되는 과정에 있습니다. 현재는 Sinkhorn Transformer와 같은 다른 Sparse Attention 메커니즘과 동일한 수준으로 수행되지만 여전히 최상의 하이퍼매개변수를 찾아야 합니다.
머리의 시각화도 가능합니다. 자세한 내용을 보려면 아래 시각화 섹션을 확인하세요.
나는 논문의 저자가 아닙니다.
123만 토큰
pip install linformer-pytorch
대안적으로,
git clone https://github.com/tatp22/linformer-pytorch.git
cd linformer-pytorch
Linformer 언어 모델
from linformer_pytorch import LinformerLM
import torch
model = LinformerLM (
num_tokens = 10000 , # Number of tokens in the LM
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
use_pos_emb = True , # Whether or not to use positional embeddings
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
emb_dim = 128 , # If you want the embedding dimension to be different than the channels for the Linformer
causal = False , # If you want this to be a causal Linformer, where the upper right of the P_bar matrix is masked out.
method = "learnable" , # The method of how to perform the projection. Supported methods are 'convolution', 'learnable', and 'no_params'
ff_intermediate = None , # See the section below for more information
). cuda ()
x = torch . randint ( 1 , 10000 ,( 1 , 512 )). cuda ()
y = model ( x )
print ( y ) # (1, 512, 10000) Linformer 자기 주의, MHAttention 및 FeedForward 스택
from linformer_pytorch import Linformer
import torch
model = Linformer (
input_size = 262144 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
). cuda ()
x = torch . randn ( 1 , 262144 , 64 ). cuda ()
y = model ( x )
print ( y ) # (1, 262144, 64)Linformer 멀티헤드 주목
from linformer_pytorch import MHAttention
import torch
model = MHAttention (
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim = 8 , # Dim of each attn head
dim_k = 128 , # What to sample the input length down to
nhead = 8 , # Number of heads
dropout = 0 , # Dropout for each of the heads
activation = "gelu" , # Activation after attention has been concat'd
checkpoint_level = "C2" , # If C2, checkpoint each of the heads
parameter_sharing = "layerwise" , # What level of parameter sharing to do
E_proj , F_proj , # The E and F projection matrices
full_attention = False , # Use full attention instead
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x )
print ( y ) # (1, 512, 64)종이의 참신함, 리니어 어텐션 헤드
from linformer_pytorch import LinearAttentionHead
import torch
model = LinearAttentionHead (
dim = 64 , # Dim 2 of the input
dropout = 0.1 , # Dropout of the P matrix
E_proj , F_proj , # The E and F layers
full_attention = False , # Use Full Attention instead
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x , x , x )
print ( y ) # (1, 512, 64)인코더/디코더 모듈.
참고: 인과 관계의 경우 LinformerLM 에서 causal=True 플래그를 설정하여 (n,k) 주의 매트릭스의 오른쪽 상단을 가릴 수 있습니다.
import torch
from linformer_pytorch import LinformerLM
encoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
k_reduce_by_layer = 1 ,
return_emb = True ,
)
decoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
decoder_mode = True ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
x_mask = torch . ones_like ( x ). bool ()
y_mask = torch . ones_like ( y ). bool ()
enc_output = encoder ( x , input_mask = x_mask )
print ( enc_output . shape ) # (1, 512, 128)
dec_output = decoder ( y , embeddings = enc_output , input_mask = y_mask , embeddings_mask = x_mask )
print ( dec_output . shape ) # (1, 512, 10000) E 및 F 행렬을 얻는 쉬운 방법은 get_EF 함수를 호출하여 수행할 수 있습니다. 예를 들어, n 이 1000 이고 k 가 100 인 경우:
from linfromer_pytorch import get_EF
import torch
E = get_EF ( 1000 , 100 ) method 플래그를 사용하면 linformer가 다운샘플링을 수행하는 방법을 설정할 수 있습니다. 현재 세 가지 방법이 지원됩니다.
learnable : 이 다운샘플링 방법은 학습 가능한 n,k nn.Linear 모듈을 생성합니다.convolution : 이 다운샘플링 방법은 보폭과 커널 크기가 n/k 인 1d 컨볼루션을 생성합니다.no_params : N(0,1/k) 앞의 값을 갖는 고정 n,k 행렬을 생성합니다.앞으로는 풀링이나 다른 것을 포함할 수도 있습니다. 그러나 현재로서는 이것이 존재하는 옵션입니다.
메모리 절약을 더욱 도입하기 위한 시도로 체크포인트 수준 개념이 도입되었습니다. 현재 세 가지 체크포인트 수준은 C0 , C1 및 C2 입니다. 체크포인트 레벨을 올릴 때 메모리 절약을 위해 속도를 희생합니다. 즉, 체크포인트 레벨 C0 은 가장 빠르지만 GPU에서 가장 많은 공간을 차지하고, C2 는 가장 느리지만 GPU에서 가장 적은 공간을 차지합니다. 각 체크포인트 레벨의 세부 내용은 다음과 같습니다.
C0 : 체크포인트가 없습니다. 모델은 모든 Attention Head와 ff 레이어를 GPU 메모리에 유지하면서 실행됩니다.C1 : 각 MultiHead attention과 각 ff 레이어를 체크포인트합니다. 이를 통해 depth 늘리면 메모리에 미치는 영향이 최소화됩니다.C2 : C1 수준의 최적화와 함께 각 MultiHead Attention 레이어의 각 헤드를 검사합니다. 이를 통해 nhead 늘리면 메모리에 미치는 영향이 줄어듭니다. 그러나 torch.cat 과 함께 헤드를 연결하는 것은 여전히 많은 메모리를 차지하므로 앞으로는 최적화될 것으로 기대됩니다.성능 세부 사항은 아직 알려지지 않았지만 시도하려는 사용자를 위한 옵션이 존재합니다.
논문에서 메모리 절약을 도입하려는 또 다른 시도는 투영 간 매개변수 공유를 도입하는 것이었습니다. 이는 논문의 섹션 4에 언급되어 있습니다. 특히 저자가 논의한 4가지 유형의 매개변수 공유가 있었고 모두 이 저장소에 구현되었습니다. 첫 번째 옵션은 가장 많은 메모리를 차지하며 각 추가 옵션은 필요한 메모리 요구 사항을 줄입니다.
none : 매개변수 공유가 아닙니다. 모든 헤드와 모든 레이어에 대해 각 레이어의 모든 헤드에 대해 새로운 E 및 새로운 F 행렬이 계산됩니다.headwise : 각 레이어에는 고유한 E 및 F 매트릭스가 있습니다. 레이어의 모든 헤드는 이 매트릭스를 공유합니다.kv : 각 레이어에는 고유한 투영 행렬 P 있고 각 레이어마다 E = F = P 있습니다. 모든 머리는 이 투영 행렬 P 공유합니다.layerwise : 하나의 투영 행렬 P 있고 모든 레이어의 모든 헤드는 E = F = P 사용합니다. 논문에서 시작된 것처럼 이는 12개의 레이어, 12개의 헤드 네트워크에 대해 각각 288 , 24 , 12 및 1 서로 다른 투영 행렬이 있음을 의미합니다.
k_reduce_by_layer 옵션을 사용하면 layerwise 옵션이 첫 번째 레이어에 대해 k 차원을 사용하므로 효과적이지 않습니다. 따라서 k_reduce_by_layer 값이 0 보다 큰 경우 layerwise 공유 옵션을 사용하지 않아야 할 가능성이 높습니다.
또한 저자에 따르면 그림 3에서 이 매개변수 공유는 실제로 최종 결과에 큰 영향을 미치지 않습니다. 따라서 모든 것에 대해 layerwise 공유를 고수하는 것이 가장 좋지만 사용자가 이를 시도해 볼 수 있는 옵션이 있습니다.
현재 Linformer 구현에서 발생하는 사소한 문제 중 하나는 시퀀스 길이가 모델의 input_size 플래그와 일치해야 한다는 것입니다. Padder는 텐서가 네트워크에 공급될 수 있도록 입력 크기를 채웁니다. 예:
from linformer_pytorch import Linformer , Padder
import torch
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_d = 32 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 6 ,
depth = 3 ,
checkpoint_level = "C1" ,
)
model = Padder ( model )
x = torch . randn ( 1 , 500 , 16 ) # This does not match the input size!
y = model ( x )
print ( y ) # (1, 500, 16) 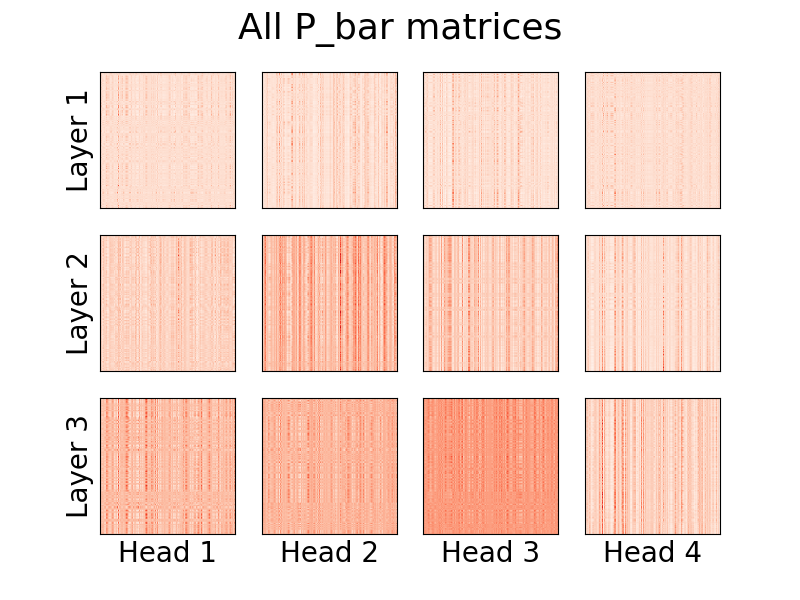
버전 0.8.0 부터 이제 linformer의 주의 헤드를 시각화할 수 있습니다! 이것이 실제로 작동하는 모습을 보려면 Visualizer 클래스를 가져오고 plot_all_heads() 함수를 실행하여 각 수준에서 크기(n,k)의 모든 어텐션 헤드에 대한 그림을 확인하세요. Visualizer 클래스가 머리를 적절하게 시각화할 수 있도록 P_bar 행렬을 저장하므로 순방향 패스에서 visualize=True 지정해야 합니다.
코드의 실제 예제는 아래에서 찾을 수 있으며 동일한 코드는 ./examples/example_vis.py 에서 찾을 수 있습니다.
import torch
from linformer_pytorch import Linformer , Visualizer
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_k = 128 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
checkpoint_level = "C0" ,
parameter_sharing = "layerwise" ,
k_reduce_by_layer = 1 ,
)
# One can load the model weights here
x = torch . randn ( 1 , 512 , 16 ) # What input you want to visualize
y = model ( x , visualize = True )
vis = Visualizer ( model )
vis . plot_all_heads ( title = "All P_bar matrices" , # Change the title if you'd like
show = True , # Show the picture
save_file = "./heads.png" , # If not None, save the picture to a file
figsize = ( 8 , 6 ), # How big the figure should be
n_limit = None # If not None, limit how much from the `n` dimension to show
)이 머리가 의미하는 바에 대한 자세한 설명은 #15에서 확인할 수 있습니다.
리포머와 마찬가지로 훈련을 단순화할 수 있도록 인코더/디코더 모듈을 만들어 보겠습니다. 이는 2개의 LinformerLM 클래스처럼 작동합니다. 매개변수는 모든 하이퍼파라미터에 대해 enc_ 접두어를 갖는 인코더와 유사한 방식으로 dec_ 접두어를 갖는 디코더를 사용하여 각 매개변수에 대해 개별적으로 조정할 수 있습니다. 현재까지 구현된 내용은 다음과 같습니다.
import torch
from linformer_pytorch import LinformerEncDec
encdec = LinformerEncDec (
enc_num_tokens = 10000 ,
enc_input_size = 512 ,
enc_channels = 16 ,
dec_num_tokens = 10000 ,
dec_input_size = 512 ,
dec_channels = 16 ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
output = encdec ( x , y )이에 대한 텍스트 시퀀스를 생성하는 방법을 계획 중입니다.
ff_intermediate 튜닝 이제 모델 차원은 중간 레이어에서 다를 수 있습니다. 이 변경 사항은 ff 모듈에 적용되며 인코더에만 적용됩니다. 이제 ff_intermediate 플래그가 None이 아닌 경우 레이어는 다음과 같이 보입니다.
channels -> ff_dim -> ff_intermediate (For layer 1)
ff_intermediate -> ff_dim -> ff_intermediate (For layers 2 to depth-1)
ff_intermediate -> ff_dim -> channels (For layer depth)
반대로
channels -> ff_dim -> channels (For all layers)
input_size 및 dim_k 로 편집 가능합니다.apex 와 같은 라이브러리는 이를 통해 작동해야 하지만 실제로는 테스트되지 않았습니다.input_size , k= dim_k , d= dim_d 로 O(nkd) 정도에 가깝습니다. LinformerEncDec 수업을 완료하세요. 논문에서 결과를 재현하는 것은 이번이 처음이므로 일부 잘못된 부분이 있을 수 있습니다. 문제가 발견되면 문제를 공개해 주시면 해결하도록 노력하겠습니다.
이 Linformer Repo를 디자인하는 데 다른 희소 관심 저장소가 도움을 준 lucidrains에게 감사드립니다.
@misc { wang2020linformer ,
title = { Linformer: Self-Attention with Linear Complexity } ,
author = { Sinong Wang and Belinda Z. Li and Madian Khabsa and Han Fang and Hao Ma } ,
year = { 2020 } ,
eprint = { 2006.04768 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @inproceedings { vaswani2017attention ,
title = { Attention is all you need } ,
author = { Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, {L}ukasz and Polosukhin, Illia } ,
booktitle = { Advances in neural information processing systems } ,
pages = { 5998--6008 } ,
year = { 2017 }
}"주의 깊게 들어보세요..."


