intelligent trading bot
1.0.0
___ _ _ _ _ _ _____ _ _ ____ _
|_ _|_ __ | |_ ___| | (_) __ _ ___ _ __ | |_ |_ _| __ __ _ __| (_)_ __ __ _ | __ ) ___ | |_
| || '_ | __/ _ | | |/ _` |/ _ '_ | __| | || '__/ _` |/ _` | | '_ / _` | | _ / _ | __|
| || | | | || __/ | | | (_| | __/ | | | |_ | || | | (_| | (_| | | | | | (_| | | |_) | (_) | |_
|___|_| |_|_____|_|_|_|__, |___|_| |_|__| |_||_| __,_|__,_|_|_| |_|__, | |____/ ___/ __|
|___/ |___/
₿ Ξ ₳ ₮ ✕ ◎ ● Ð Ł Ƀ Ⱥ ∞ ξ ◈ ꜩ ɱ ε ɨ Ɓ Μ Đ ⓩ Ο Ӿ Ɍ ȿ
? 지능형 거래 신호 ? https://t.me/intelligent_trading_signals
이 프로젝트는 최첨단 기계 학습(ML) 알고리즘과 기능 엔지니어링을 사용하여 자동화된 암호화폐 거래를 위한 지능형 거래 봇을 개발하는 것을 목표로 합니다. 이 프로젝트는 다음과 같은 주요 기능을 제공합니다.
신호 서비스는 클라우드에서 실행 중이며 다음 텔레그램 채널로 신호를 보냅니다.
? 지능형 거래 신호 ? https://t.me/intelligent_trading_signals
누구나 채널을 구독하여 이 봇이 생성하는 신호에 대한 인상을 얻을 수 있습니다.
현재 봇은 다음 매개변수를 사용하여 구성됩니다.
점수가 임계값보다 낮고 채널에 알림이 전송되지 않는 무음 기간이 있습니다. 점수가 임계값보다 크면 매분마다 다음과 같은 알림이 전송됩니다.
₿ 24.518 ??? 점수: -0.26
첫 번째 숫자는 최근 종가입니다. -0.26점은 현재 종가보다 가격이 낮아질 가능성이 매우 높다는 뜻이다.
점수가 모델에 지정된 일부 임계값을 초과하면 매수 또는 매도 신호가 생성됩니다. 이는 거래를 하기 좋은 시기임을 의미합니다. 이러한 알림은 다음과 같습니다.
? 구매: ₿ 24,033 점수: +0.34
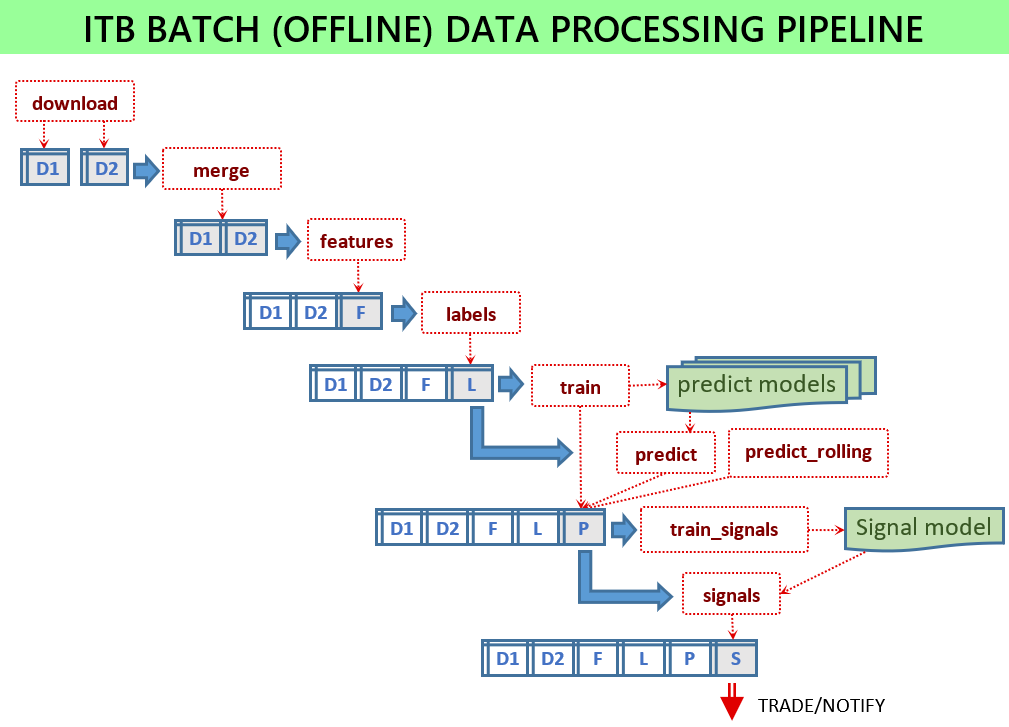
신호 전달자 서비스가 작동하려면 여러 ML 모델을 교육해야 하며 서비스에 모델 파일을 사용할 수 있어야 합니다. 모든 스크립트는 일부 입력 데이터를 로드하고 일부 출력 파일을 저장하여 배치 모드로 실행됩니다. 배치 스크립트는 scripts 모듈에 있습니다.
모든 것이 구성되면 다음 스크립트를 실행해야 합니다.
python -m scripts.download_binance -c config.jsonpython -m scripts.merge -c config.jsonpython -m scripts.features -c config.jsonpython -m scripts.labels -c config.jsonpython -m scripts.train -c config.jsonpython -m scripts.signals -c config.jsonpython -m scripts.train_signals -c config.json 구성 파일이 없으면 스크립트는 테스트 목적으로 유용하며 좋은 성능을 보여주기 위한 것이 아닌 기본 매개변수를 사용합니다. config-sample-v0.6.0.jsonc 와 같이 각 릴리스에 제공되는 샘플 구성 파일을 사용하세요.
두 스크립트의 기본 구성 매개변수는 data_sources 의 소스 목록입니다. 이 목록의 한 항목은 데이터 소스와 동일한 이름을 가진 열을 다른 소스와 구별하는 데 사용되는 column_prefix 지정합니다.
최신 기록 데이터 다운로드: python -m scripts.download_binance -c config.json
여러 과거 데이터세트를 하나의 데이터세트로 병합: python -m scripts.merge -c config.json
이 스크립트는 파생된 기능을 계산하기 위한 것입니다.
python -m scripts.features -c config.json 생성될 기능 목록은 구성 파일의 feature_sets 목록을 통해 구성됩니다. 기능이 생성되는 방법은 구성 섹션에 지정된 일부 매개변수가 있는 기능 생성기 에 의해 정의됩니다.
talib 기능 생성기는 TA-lib 기술 분석 라이브러리를 사용합니다. 구성의 예는 다음과 같습니다. "config": {"columns": ["close"], "functions": ["SMA"], "windows": [5, 10, 15]}itbstats 기능 생성기는 scipy_skew , scipy_kurtosis , lsbm (평균보다 긴 파업), fmax (최대값의 첫 번째 위치), mean , std , area , slope 와 같은 tsfresh에서 찾을 수 있는 함수를 구현합니다. 일반적인 매개변수는 다음과 같습니다 "config": {"columns": ["close"], "functions": ["skew", "fmax"], "windows": [5, 10, 15]}itblib 기능 생성기는 ITB에 구현되어 있지만 대부분의 기능은 talib를 통해 (훨씬 더 빠르게) 생성될 수 있습니다.tsfresh tsfresh 라이브러리에서 함수를 생성합니다. 이 스크립트는 입력 파일에 새 열을 추가한다는 점에서 기능 생성과 유사합니다. 그러나 이러한 열은 우리가 예측하려는 내용과 온라인 모드에서 실행할 때 알려지지 않은 내용을 설명합니다. 예를 들어, 향후 가격 인상이 있을 수 있습니다.
python -m scripts.labels -c config.json 생성할 라벨 목록은 구성의 label_sets 목록을 통해 구성됩니다. 하나의 레이블 세트는 추가 열을 생성하는 함수를 가리킵니다. 해당 구성은 기능 구성과 매우 유사합니다.
highlow 라벨 생성기는 가격이 미래의 특정 기간 내에서 지정된 임계값보다 높을 경우 True를 반환합니다.highlow2 이전에 큰 감소(증가)가 없었다는 조건으로 향후 증가(감소)를 계산합니다. 일반적인 구성은 다음과 같습니다. "config": {"columns": ["close", "high", "low"], "function": "high", "thresholds": [1.0, 1.5, 2.0], "tolerance": 0.2, "horizon": 10080, "names": ["first_high_10", "first_high_15", "first_high_20"]}topbot 더 이상 사용되지 않음topbot2 최대값과 최소값을 계산합니다(True로 표시됨). 레이블이 지정된 모든 최대값(최소값)은 지정된 수준보다 낮은(높은) 최소값(최대값)으로 둘러싸여 있음이 보장됩니다. 인접한 최소값과 최대값 사이에 필요한 최소 차이는 level 매개변수를 통해 지정됩니다. 공차 매개변수를 사용하면 최대/최소에 가까운 지점도 포함할 수 있습니다. 일반적인 구성은 다음과 같습니다 "config": {"columns": "close", "function": "bot", "level": 0.02, "tolerances": [0.1, 0.2], "names": ["bot2_1", "bot2_2"]} 이 스크립트는 지정된 입력 기능과 레이블을 사용하여 여러 ML 모델을 교육합니다.
python -m scripts.train -c config.jsonprediction-metrics.txt 파일을 생성합니다.구성:
model_store.py 에 설명되어 있습니다.train_features 에 지정됩니다.labels 에 지정되어 있습니다.algorithms 에 지정됩니다. 이 단계의 목표는 다양한 라벨에 대해 다양한 알고리즘으로 생성된 예측 점수를 집계하는 것입니다. 결과는 다음 단계의 신호 규칙에 의해 소비되는 것으로 예상되는 하나의 점수입니다. 집계 매개변수는 score_aggregation 섹션에 지정됩니다. buy_labels 및 sell_labels 집계 절차에서 처리되는 입력 예측 점수를 지정합니다. window 롤링 집계에 사용된 이전 단계의 수이고 combine 두 가지 점수 유형(구매 및 레이블)을 하나의 출력 점수로 결합하는 방식입니다.
집계 절차에 의해 생성된 점수는 숫자이며 신호 규칙의 목표는 거래 결정(구매, 판매 또는 아무것도 하지 않음)을 내리는 것입니다. 신호 규칙의 매개변수는 trade_model 에 설명되어 있습니다.
이 스크립트는 많은 매수-매도 신호 매개변수를 사용하여 거래를 시뮬레이션한 후 가장 성과가 좋은 신호 매개변수를 선택합니다.
python -m scripts.train_signals -c config.json이 스크립트는 하나의 동일한 작업을 주기적으로 실행하는 서비스를 시작합니다. 최신 데이터 로드, 기능 생성, 예측, 신호 생성, 구독자에게 알림:
python -m service.server -c config.json두 가지 문제가 있습니다.
python -m scripts.predict_rolling -c config.jsonpython -m scripts.train_signals -c config.json구성 매개변수는 다음 두 파일에 지정됩니다.
App 클래스의 config 필드에 있는 service.App.py-c config.jsom 인수. 이 구성 파일의 값은 이 파일이 스크립트 또는 서비스에 로드될 때 App.config 의 값을 덮어씁니다. App.py 및 config.json 모두에서 가장 중요한 필드는 다음과 같습니다.
data_folder - 배치 오프라인 스크립트에만 필요한 데이터 파일의 위치symbol BTCUSDT 와 같은 거래 쌍입니다.labels 레이블로 처리되는 열 이름 목록입니다. 학습과 예측에 사용되는 새 라벨을 정의하는 경우 여기에 이름을 지정해야 합니다.algorithms 훈련에 사용되는 알고리즘 이름 목록train_features 훈련 및 예측을 위한 입력 기능으로 사용되는 모든 열 이름 목록입니다.buy_labels 및 sell_labels 신호에 사용되는 예측 열 목록trade_model 신호 전달자의 매개변수(주로 일부 임계값)trader 거래자 매개변수에 대한 섹션입니다. 현재는 철저히 테스트되지 않았습니다.collector 이 매개변수 섹션은 데이터 수집 서비스용입니다. 데이터 수집 서비스에는 두 가지 유형이 있습니다. 데이터 공급자에 대한 정기적인 요청과 동기화되는 동기식 서비스와 데이터 공급자를 구독하고 새 데이터가 사용 가능해지면 즉시 알림을 받는 비동기식 스트리밍 서비스입니다. 작동 중이지만 철저하게 테스트되지 않았으며 기본 서비스에 통합되지 않았습니다. 현재 주요 사용 패턴은 수동 배치 데이터 업데이트, 기능 생성 및 모델 교육에 의존합니다. 이러한 데이터 수집 서비스를 사용하는 한 가지 이유는 1) 더 빠른 업데이트 2) 주문서와 같은 일반 API에서 데이터를 사용할 수 없기 때문입니다(이 데이터를 사용하는 일부 기능이 있지만 기본 워크플로에 통합되지 않음).자세한 내용은 App.config의 샘플 구성 파일 및 설명을 참조하세요.
매분마다 신호 발생기는 다음 단계를 수행하여 가격이 상승할지 하락할지 예측합니다.
참고:
서비스 시작: python3 -m service.server -c config.json
거래자는 작업 중이지만 철저히 디버깅되지 않았습니다. 특히 안정성과 신뢰성에 대한 테스트를 거치지 않았습니다. 따라서 기본적인 기능을 갖춘 프로토타입으로 간주되어야 합니다. 현재는 Signaler와 통합되어 있지만 더 나은 설계에서는 별도의 서비스가 되어야 합니다.
백테스팅
외부 통합


