make a video pytorch
0.4.0
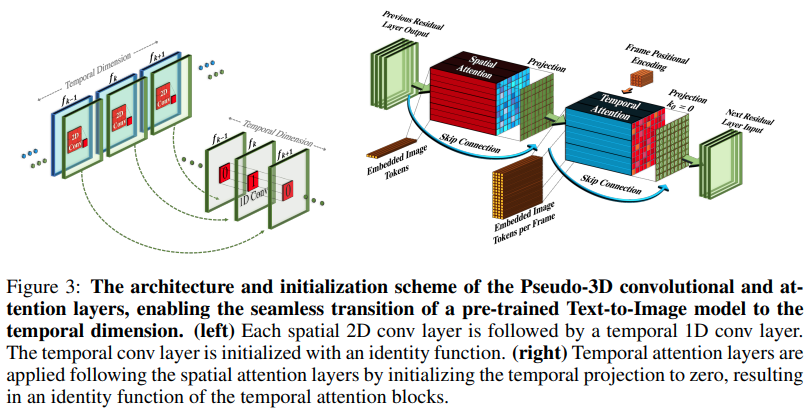
Pytorch에서 Meta AI의 비디오 생성기에 대한 새로운 SOTA 텍스트인 Make-A-Video 구현. 그들은 의사-3D 컨볼루션(축 컨볼루션)과 시간적 주의를 결합하고 훨씬 더 나은 시간적 융합을 보여줍니다.
의사 3D 컨볼루션은 새로운 개념이 아닙니다. 이는 이전에 "차원 하이브리드 잔류 네트워크"와 같은 단백질 접촉 예측과 같은 다른 맥락에서 탐구된 적이 있습니다.
논문의 요점은 SOTA 텍스트-이미지 모델을 사용하고(여기서는 DALL-E2를 사용하지만 동일한 학습 포인트가 Imagen에 쉽게 적용됨) 시간 경과에 따른 관심을 끌기 위해 몇 가지 사소한 수정과 기타 방법을 적용하는 것입니다. 컴퓨팅 비용을 절감하고, 프레임 보간을 올바르게 수행하고, 훌륭한 비디오 모델을 얻으십시오.
AI 커피 브레이크 설명
최첨단 인공지능 연구를 위한 Stability.ai의 아낌없는 후원
자신의 논문을 통해 생성 인공 지능에 혁명을 가져온 조나단 호(Jonathan Ho)
단순히 천재적인 추상화인 einops의 Alex입니다. 다른 말은 없습니다.
$ pip install make-a-video-pytorch비디오 기능 전달
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
video = torch . randn ( 1 , 256 , 8 , 16 , 16 ) # (batch, features, frames, height, width)
conv_out = conv ( video ) # (1, 256, 8, 16, 16)
attn_out = attn ( video ) # (1, 256, 8, 16, 16)이미지를 전달하면(이미지를 먼저 사전 훈련하는 경우) 시간적 컨볼루션과 Attention이 모두 자동으로 건너뜁니다. 즉, 이를 2d Unet에서 직접 사용한 다음 해당 훈련 단계가 완료되면 3d Unet으로 포팅할 수 있습니다. 임시 모듈은 논문에서 수행한 것처럼 ID를 출력하도록 초기화됩니다.
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
images = torch . randn ( 1 , 256 , 16 , 16 ) # (batch, features, height, width)
conv_out = conv ( images ) # (1, 256, 16, 16)
attn_out = attn ( images ) # (1, 256, 16, 16)3차원 특징이 입력되면 공간적으로만 훈련을 수행하도록 두 모듈을 제어할 수도 있습니다.
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
video = torch . randn ( 1 , 256 , 8 , 16 , 16 ) # (batch, features, frames, height, width)
# below it will not train across time
conv_out = conv ( video , enable_time = False ) # (1, 256, 8, 16, 16)
attn_out = attn ( video , enable_time = False ) # (1, 256, 8, 16, 16) 이미지 또는 비디오 교육에 구애받지 않고 비디오가 전달되더라도 시간을 무시할 수 있는 전체 SpaceTimeUnet
import torch
from make_a_video_pytorch import SpaceTimeUnet
unet = SpaceTimeUnet (
dim = 64 ,
channels = 3 ,
dim_mult = ( 1 , 2 , 4 , 8 ),
resnet_block_depths = ( 1 , 1 , 1 , 2 ),
temporal_compression = ( False , False , False , True ),
self_attns = ( False , False , False , True ),
condition_on_timestep = False ,
attn_pos_bias = False ,
flash_attn = True
). cuda ()
# train on images
images = torch . randn ( 1 , 3 , 128 , 128 ). cuda ()
images_out = unet ( images )
assert images . shape == images_out . shape
# then train on videos
video = torch . randn ( 1 , 3 , 16 , 128 , 128 ). cuda ()
video_out = unet ( video )
assert video_out . shape == video . shape
# or even treat your videos as images
video_as_images_out = unet ( video , enable_time = False )연구에서 제공하는 최고의 위치 임베딩에 주의를 기울이세요.
관심을 끌다
플래시 주의 추가
dalle2-pytorch가 훈련을 위해 SpaceTimeUnet 수용할 수 있는지 확인하세요
@misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @article { Dong2021AttentionIN ,
title = { Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth } ,
author = { Yihe Dong and Jean-Baptiste Cordonnier and Andreas Loukas } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2103.03404 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { shleifer2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Sam Shleifer and Myle Ott } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
}

