rtdl num embeddings
v0.0.11
중요한
새로운 테이블 형식 DL 모델인 TabM을 확인하세요.
arXiv ? Python 패키지 기타 테이블 형식 DL 프로젝트
이는 "테이블 형식 딥러닝의 수치적 특징에 대한 임베딩"이라는 논문의 공식 구현입니다.
한 문장으로 말하자면, 원래 스칼라 연속 특성을 기본 백본(예: MLP, Transformer 등)에서 혼합하기 전에 벡터로 변환하면 표 형식 신경망의 다운스트림 성능이 향상됩니다.
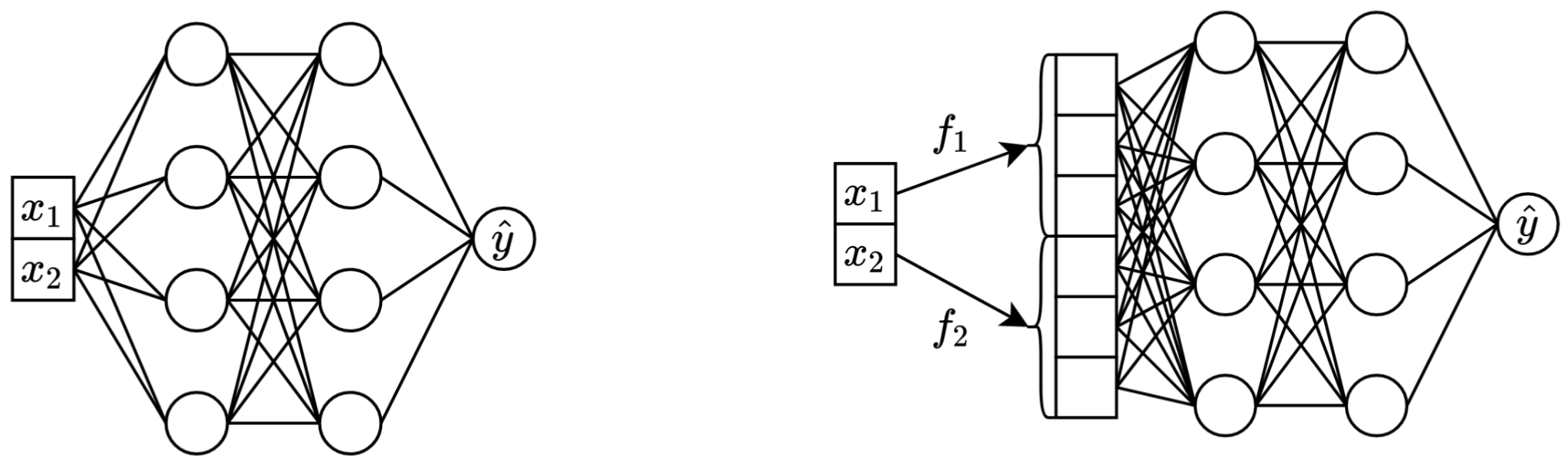
왼쪽: 두 개의 연속 특성을 입력으로 사용하는 바닐라 MLP.
오른쪽: 동일한 MLP이지만 이제 연속 기능을 위한 임베딩이 포함되어 있습니다.
더 자세히:
엄밀히 말하면 설명이 하나도 없습니다. 분명히 임베딩은 연속 기능과 관련된 다양한 과제를 처리하고 모델의 전반적인 최적화 속성을 개선하는 데 도움이 됩니다.
특히, 불규칙하게 분포된 연속 특성(및 레이블과의 불규칙한 결합 분포)은 실제 테이블 형식 데이터에서 흔히 발생하며 기존 테이블 형식 DL 모델에 대한 주요 기본 최적화 문제를 제기합니다. 이 과제를 이해하기 위한 훌륭한 참고 자료 (그리고 입력 공간을 변환하여 이러한 과제를 해결하는 훌륭한 예)는 "Fourier Feature Let Networks Learn High Frequency Functions in Low Dimensional Domains" 논문입니다.
그러나 불규칙한 분포가 임베딩이 유용한 유일한 이유인지는 확실하지 않습니다.
package/ 디렉토리에 있는 Python 패키지는 실제 및 향후 작업에 논문을 사용하는 데 권장되는 방법입니다.
문서의 나머지 부분 :
exp/ 디렉토리에는 논문에 사용된 다양한 모델과 데이터세트에 대한 수많은 결과와 (조정된) 하이퍼파라미터가 포함되어 있습니다.
예를 들어 MLP 모델의 측정항목을 살펴보겠습니다. 먼저 보고서( report.json 파일)를 로드해 보겠습니다.
import json
from pathlib import Path
import pandas as pd
df = pd . json_normalize ([
json . loads ( x . read_text ())
for x in Path ( 'exp' ). glob ( 'mlp/*/0_evaluation/*/report.json' )
])이제 각 데이터 세트에 대해 모든 무작위 시드에 대한 평균 테스트 점수를 계산해 보겠습니다.
print ( df . groupby ( 'config.data.path' )[ 'metrics.test.score' ]. mean (). round ( 3 ))출력은 논문의 표 3과 정확히 일치합니다.
config.data.path
data/adult 0.854
data/california -0.495
data/churn 0.856
data/covtype 0.964
data/fb-comments -5.686
data/gesture 0.632
data/higgs-small 0.720
data/house -32039.399
data/microsoft -0.747
data/otto 0.818
data/santander 0.912
Name: metrics.test.score, dtype: float64
위의 접근 방식은 하이퍼파라미터를 탐색하여 다양한 알고리즘의 일반적인 하이퍼파라미터 값에 대한 직관을 얻는 데에도 사용할 수 있습니다. 예를 들어, MLP 모델의 조정된 학습률 중앙값을 계산하는 방법은 다음과 같습니다.
메모
일부 알고리즘(예: MLP, MLP-LR, MLP-PLR)의 경우 최신 프로젝트에서는 유사한 방식으로 탐색할 수 있는 더 많은 결과를 제공합니다. 예를 들어 TabR에 대한 이 문서를 참조하세요.
경고
이 접근 방식은 주의해서 사용하세요. 초매개변수 값을 연구할 때:
print ( df [ df [ 'config.seed' ] == 0 ][ 'config.training.lr' ]. quantile ( 0.5 ))
# Output: 0.0002716544410603358중요한
이 섹션은 깁니다. 이 섹션의 개요를 보려면 텍스트 편집기에서 GitHub의 "개요" 기능을 사용하세요 .
예선:
/usr/local/cuda-11.1/bin 이 항상 PATH 환경 변수에 있는지 확인하세요. export PROJECT_DIR= < ABSOLUTE path to the repository root >
# example: export PROJECT_DIR=/home/myusername/repositories/num-embeddings
git clone https://github.com/yandex-research/tabular-dl-num-embeddings $PROJECT_DIR
cd $PROJECT_DIR
conda create -n num-embeddings python=3.9.7
conda activate num-embeddings
pip install torch==1.10.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txt
# if the following commands do not succeed, update conda
conda env config vars set PYTHONPATH= ${PYTHONPATH} : ${PROJECT_DIR}
conda env config vars set PROJECT_DIR= ${PROJECT_DIR}
# the following command appends ":/usr/local/cuda-11.1/lib64" to LD_LIBRARY_PATH;
# if your LD_LIBRARY_PATH already contains a path to some other CUDA, then the content
# after "=" should be "<your LD_LIBRARY_PATH without your cuda path>:/usr/local/cuda-11.1/lib64"
conda env config vars set LD_LIBRARY_PATH= ${LD_LIBRARY_PATH} :/usr/local/cuda-11.1/lib64
conda env config vars set CUDA_HOME=/usr/local/cuda-11.1
conda env config vars set CUDA_ROOT=/usr/local/cuda-11.1
# (optional) get a shortcut for toggling the dark mode with cmd+y
conda install nodejs
jupyter labextension install jupyterlab-theme-toggle
conda deactivate
conda activate num-embeddings라이선스: 데이터 세트를 다운로드하면 모든 구성 요소의 라이선스에 동의하게 됩니다. 우리는 해당 라이선스 외에 새로운 제한 사항을 부과하지 않습니다. 논문에서 출처 목록을 찾을 수 있습니다.
cd $PROJECT_DIR
wget " https://www.dropbox.com/s/r0ef3ij3wl049gl/data.tar?dl=1 " -O num_embeddings_data.tar
tar -xvf num_embeddings_data.tar아래 코드는 캘리포니아 주택 데이터세트의 MLP 결과를 재현합니다. 다른 알고리즘과 데이터 세트의 파이프라인은 완전히 동일합니다.
# You must explicitly set CUDA_VISIBLE_DEVICES if you want to use GPU
export CUDA_VISIBLE_DEVICES="0"
# Create a copy of the 'official' config
cp exp/mlp/california/0_tuning.toml exp/mlp/california/1_tuning.toml
# Run tuning (on GPU, it takes ~30-60min)
python bin/tune.py exp/mlp/california/1_tuning.toml
# Evaluate single models with 15 different random seeds
python bin/evaluate.py exp/mlp/california/1_tuning 15
# Evaluate ensembles (by default, three ensembles of size five each)
python bin/ensemble.py exp/mlp/california/1_evaluation
"메트릭" 섹션에서는 얻은 결과를 요약하는 방법을 보여줍니다.
코드는 다음과 같이 구성됩니다.
bintrain4.py (논문의 모든 임베딩과 백본을 구현합니다)xgboost_.pycatboost_.pytune.pyevaluate.pyensemble.pydatasets.py 데이터 세트 분할을 작성하는 데 사용되었습니다.synthetic.pytrain1_synthetic.pylib 에는 bin 의 프로그램에서 사용하는 일반적인 도구가 포함되어 있습니다.exp 실험 구성 및 결과(메트릭, 조정된 구성 등)가 포함되어 있습니다. 중첩된 폴더의 이름은 논문의 이름을 따릅니다(예: exp/mlp-plr 논문의 MLP-PLR 모델에 해당함).package 이 문서의 Python 패키지가 포함되어 있습니다.CUDA_VISIBLE_DEVICES 명시적으로 설정해야 합니다.lib.dump_config 및 lib.load_config 사용하세요.스크립트 실행의 일반적인 패턴은 다음과 같습니다.
python bin/my_script.py a/b/c.toml 여기서 a/b/c.toml 은 입력 구성 파일(config)입니다. 출력은 a/b/c 에 위치합니다. 구성 구조는 일반적으로 bin/my_script.py 의 Config 클래스를 따릅니다.
구성 대신 명령줄 인수를 사용하는 스크립트도 있습니다(예: bin/{evaluate.py,ensemble.py} ).
결과를 재현하려면 이들 모두가 필요하지만 향후 작업에는 train4.py 만 필요합니다. 그 이유는 다음과 같습니다.
bin/train1.py bin/train0.py 의 기능 상위 집합을 구현합니다.bin/train3.py bin/train1.py 의 기능 상위 집합을 구현합니다.bin/train4.py bin/train3.py 의 기능 상위 집합을 구현합니다. 주어진 실험을 실행하는 데 4개의 스크립트 중 어느 것이 사용되었는지 확인하려면 해당 튜닝 구성의 "프로그램" 필드를 확인하세요. 예를 들어 캘리포니아 주택 데이터세트의 MLP에 대한 튜닝 구성은 exp/mlp/california/0_tuning.toml 입니다. 구성은 bin/train0.py 가 사용되었음을 나타냅니다. 이는 exp/mlp/california/0_evaluation 의 구성이 특히 bin/train0.py 와 호환된다는 것을 의미합니다. 이를 확인하려면 그 중 하나를 별도의 위치에 복사하고 bin/train0.py 에 전달하면 됩니다.
mkdir exp/tmp
cp exp/mlp/california/0_evaluation/0.toml exp/tmp/0.toml
python bin/train0.py exp/tmp/0.toml
ls exp/tmp/0
@inproceedings{gorishniy2022embeddings,
title={On Embeddings for Numerical Features in Tabular Deep Learning},
author={Yury Gorishniy and Ivan Rubachev and Artem Babenko},
booktitle={{NeurIPS}},
year={2022},
}


