gigagan pytorch
0.2.20

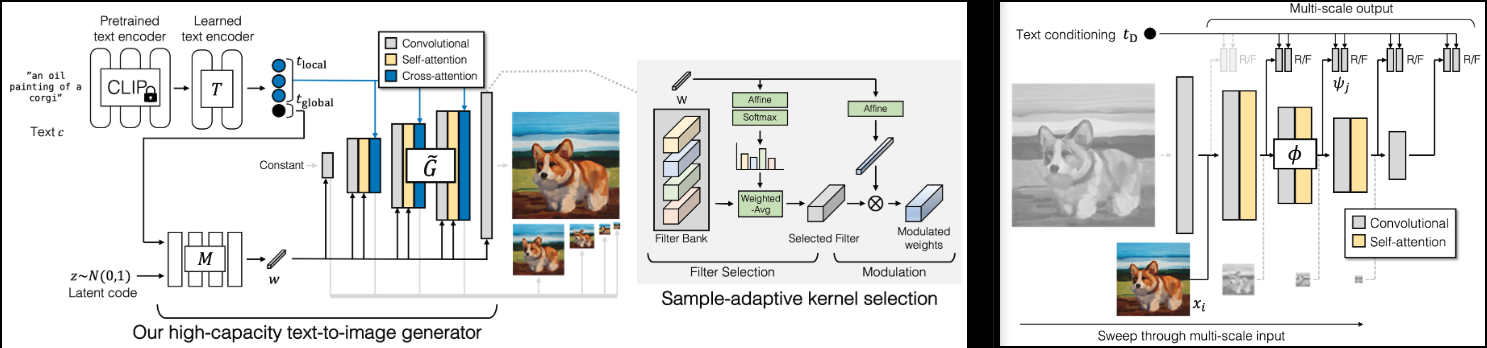
Adobe의 새로운 SOTA GAN인 GigaGAN(프로젝트 페이지) 구현.
또한 더 빠른 수렴(층 여기 건너뛰기)과 더 나은 안정성(판별기의 재구성 보조 손실)을 위해 경량 gan에서 얻은 몇 가지 결과를 추가하겠습니다.
또한 이 문서의 하이라이트인 1k - 4k 업샘플러에 대한 코드도 포함됩니다.
LAION 커뮤니티와 함께 복제 작업에 도움을 주고 싶으시다면 가입해 주세요.
안정성AI와? 오픈 소스 인공 지능에 대한 독립성을 제공해준 다른 후원자와 관대한 후원에 대해 포옹합니다.
? 가속화 라이브러리를 위한 Huggingface
SOTA 오픈 소스 대조 학습 텍스트-이미지 모델을 위한 OpenClip의 모든 관리자
매우 유용한 코드 검토와 판별기의 척도 불변성을 구축하는 방법에 대한 토론에 대해 Xavier에게 감사드립니다!
생성기와 업샘플러 모두에 대한 초기 샘플링 코드를 요청하는 풀 요청 @CerebralSeed!
코드 검토를 위해 Keerth하고 논문과의 일부 불일치를 지적하십시오!
$ pip install gigagan-pytorch초보자를 위한 단순 무조건 GAN
import torch
from gigagan_pytorch import (
GigaGAN ,
ImageDataset
)
gan = GigaGAN (
generator = dict (
dim_capacity = 8 ,
style_network = dict (
dim = 64 ,
depth = 4
),
image_size = 256 ,
dim_max = 512 ,
num_skip_layers_excite = 4 ,
unconditional = True
),
discriminator = dict (
dim_capacity = 16 ,
dim_max = 512 ,
image_size = 256 ,
num_skip_layers_excite = 4 ,
unconditional = True
),
amp = True
). cuda ()
# dataset
dataset = ImageDataset (
folder = '/path/to/your/data' ,
image_size = 256
)
dataloader = dataset . get_dataloader ( batch_size = 1 )
# you must then set the dataloader for the GAN before training
gan . set_dataloader ( dataloader )
# training the discriminator and generator alternating
# for 100 steps in this example, batch size 1, gradient accumulated 8 times
gan (
steps = 100 ,
grad_accum_every = 8
)
# after much training
images = gan . generate ( batch_size = 4 ) # (4, 3, 256, 256)무조건적인 Unet 업샘플러의 경우
import torch
from gigagan_pytorch import (
GigaGAN ,
ImageDataset
)
gan = GigaGAN (
train_upsampler = True , # set this to True
generator = dict (
style_network = dict (
dim = 64 ,
depth = 4
),
dim = 32 ,
image_size = 256 ,
input_image_size = 64 ,
unconditional = True
),
discriminator = dict (
dim_capacity = 16 ,
dim_max = 512 ,
image_size = 256 ,
num_skip_layers_excite = 4 ,
multiscale_input_resolutions = ( 128 ,),
unconditional = True
),
amp = True
). cuda ()
dataset = ImageDataset (
folder = '/path/to/your/data' ,
image_size = 256
)
dataloader = dataset . get_dataloader ( batch_size = 1 )
gan . set_dataloader ( dataloader )
# training the discriminator and generator alternating
# for 100 steps in this example, batch size 1, gradient accumulated 8 times
gan (
steps = 100 ,
grad_accum_every = 8
)
# after much training
lowres = torch . randn ( 1 , 3 , 64 , 64 ). cuda ()
images = gan . generate ( lowres ) # (1, 3, 256, 256) G - 발전기MSG - 멀티스케일 생성기D - 판별자MSD - 다중 스케일 판별기GP - 그라디언트 페널티SSL - 판별기의 보조 재구성(경량 GAN에서)VD - 시각 보조 판별기VG - 시각 보조 생성기CL - 발전기 고정 손실MAL - 일치 인식 손실 정상적인 실행에는 G , MSG , D , MSD 가 있으며 값은 0 에서 10 사이이고 일반적으로 일정하게 유지됩니다. 1,000번의 훈련 단계 후에도 이 값이 세 자리 숫자로 지속된다면 이는 뭔가 잘못되었음을 의미합니다. 생성기와 판별기 값이 가끔 음수로 떨어지는 것은 괜찮지만 위의 범위로 다시 올라야 합니다.
GP 와 SSL 0 으로 푸시되어야 합니다. GP 때때로 급증할 수 있습니다. 나는 그것을 네트워크가 어떤 깨달음을 겪고 있는 것으로 상상하고 싶습니다.
GigaGAN 클래스는 이제? 촉진 신경. accelerate CLI를 사용하여 두 단계로 다중 GPU 교육을 쉽게 수행할 수 있습니다.
학습 스크립트가 있는 프로젝트 루트 디렉터리에서 다음을 실행합니다.
$ accelerate config그런 다음 동일한 디렉토리에서
$ accelerate launch train . py 무조건 훈련할 수 있는지 확인하세요
관련 논문을 읽고 3가지 보조 손실을 모두 제거하세요.
유넷 업샘플러
논문이 약간 모호했기 때문에 다중 스케일 입력 및 출력에 대한 코드 검토를 받으십시오.
업샘플링 네트워크 아키텍처 추가
기본 생성기와 업샘플러 모두에 대해 무조건 작업 수행
기본 및 업샘플러 모두에 대해 텍스트 조건 훈련 작업을 수행합니다.
무작위 샘플링 패치로 정찰 효율성 향상
생성기와 판별자가 사전 인코딩된 CLIP 텍스트 인코딩도 허용할 수 있는지 확인하세요.
보조 손실을 검토한다
기존 GAN 시대의 검증된 기술인 차별화 가능한 기능 추가
모든 변조 투영을 적응형 conv2d 클래스로 이동합니다.
가속 추가
클립은 모든 모듈에 대해 선택 사항이어야 하며 GigaGAN 에 의해 관리되어야 하며 텍스트 -> 텍스트 삽입은 한 번 처리됩니다.
효율성을 위해 다중 규모 차원에서 무작위 하위 집합을 선택하는 기능 추가
Lightweight|stylegan2-pytorch에서 CLI를 통한 포트
텍스트 이미지를 위한 laion 데이터세트 연결
@misc { https://doi.org/10.48550/arxiv.2303.05511 ,
url = { https://arxiv.org/abs/2303.05511 } ,
author = { Kang, Minguk and Zhu, Jun-Yan and Zhang, Richard and Park, Jaesik and Shechtman, Eli and Paris, Sylvain and Park, Taesung } ,
title = { Scaling up GANs for Text-to-Image Synthesis } ,
publisher = { arXiv } ,
year = { 2023 } ,
copyright = { arXiv.org perpetual, non-exclusive license }
} @article { Liu2021TowardsFA ,
title = { Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis } ,
author = { Bingchen Liu and Yizhe Zhu and Kunpeng Song and A. Elgammal } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2101.04775 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Karras2020ada ,
title = { Training Generative Adversarial Networks with Limited Data } ,
author = { Tero Karras and Miika Aittala and Janne Hellsten and Samuli Laine and Jaakko Lehtinen and Timo Aila } ,
booktitle = { Proc. NeurIPS } ,
year = { 2020 }
} @article { Xu2024VideoGigaGANTD ,
title = { VideoGigaGAN: Towards Detail-rich Video Super-Resolution } ,
author = { Yiran Xu and Taesung Park and Richard Zhang and Yang Zhou and Eli Shechtman and Feng Liu and Jia-Bin Huang and Difan Liu } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2404.12388 } ,
url = { https://api.semanticscholar.org/CorpusID:269214195 }
}

