byol pytorch
0.8.2
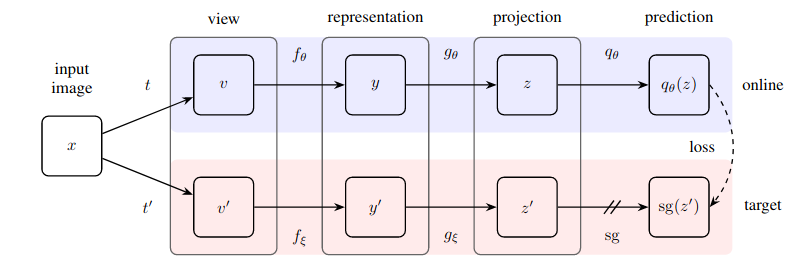
대조 학습 및 음수 쌍 지정 없이 새로운 최첨단 기술(SimCLR 능가)을 달성하는 자기 지도 학습을 위한 놀랍도록 간단한 방법을 실제로 구현합니다.
이 저장소는 이미지 기반 신경망(잔차 네트워크, 판별자, 정책 네트워크)을 쉽게 래핑하여 레이블이 지정되지 않은 이미지 데이터의 이점을 즉시 활용할 수 있는 모듈을 제공합니다.
업데이트 1: 이제 배치 정규화가 이 기술을 효과적으로 작동시키는 데 핵심이라는 새로운 증거가 있습니다.
업데이트 2: 새로운 논문은 배치 표준을 그룹 표준 + 중량 표준화로 성공적으로 대체했으며 BYOL이 작동하려면 배치 통계가 필요하다는 점을 반박했습니다.
업데이트 3: 마지막으로 이것이 작동하는 이유에 대한 몇 가지 분석이 있습니다.
Yannic Kilcher의 훌륭한 설명
이제 귀하의 조직이 라벨 비용을 지불하지 않아도 되도록 하세요 :)
$ pip install byol-pytorch(1) 이미지 크기와 (2) 숨겨진 레이어의 이름(또는 인덱스)을 지정하여 신경망을 연결하기만 하면 됩니다. 이 숨겨진 레이어의 출력은 자기 지도 학습에 사용되는 잠재 표현으로 사용됩니다.
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
learner . update_moving_average () # update moving average of target encoder
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )거의 그 정도입니다. 많은 훈련을 거친 후 이제 잔여 네트워크는 다운스트림 감독 작업에서 더 나은 성능을 발휘해야 합니다.
Kaiming He의 새 논문에서는 BYOL이 온라인 인코더의 지수 이동 평균이 되기 위해 대상 인코더가 필요하지 않다고 제안합니다. 나는 단순히 use_momentum 플래그를 False 로 설정하여 훈련에 해당 변형을 쉽게 사용할 수 있도록 이 옵션을 구축하기로 결정했습니다. 아래 예에 표시된 대로 이 경로를 사용하면 더 이상 update_moving_average 호출할 필요가 없습니다.
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
use_momentum = False # turn off momentum in the target encoder
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )하이퍼파라미터는 이미 논문에서 최적이라고 판단한 것으로 설정되어 있지만 기본 래퍼 클래스에 대한 추가 키워드 인수를 사용하여 하이퍼파라미터를 변경할 수 있습니다.
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
projection_size = 256 , # the projection size
projection_hidden_size = 4096 , # the hidden dimension of the MLP for both the projection and prediction
moving_average_decay = 0.99 # the moving average decay factor for the target encoder, already set at what paper recommends
) 기본적으로 이 라이브러리는 SimCLR 문서(BYOL 문서에서도 사용됨)의 기능 보강을 사용합니다. 그러나 자체 기능 보강 파이프라인을 지정하려면 augment_fn 키워드를 사용하여 사용자 정의 기능 보강 함수를 전달하기만 하면 됩니다.
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn
)논문에서 그들은 증강 중 하나가 다른 것보다 더 높은 가우스 블러 확률을 갖는다고 확신하는 것으로 보입니다. 마음에 드시는 대로 조정할 수도 있습니다.
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
augment_fn2 = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip (),
kornia . filters . GaussianBlur2d (( 3 , 3 ), ( 1.5 , 1.5 ))
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn ,
augment_fn2 = augment_fn2 ,
) 임베딩 또는 프로젝션을 가져오려면 return_embeddings = True 플래그를 BYOL 학습자 인스턴스에 전달하기만 하면 됩니다.
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
imgs = torch . randn ( 2 , 3 , 256 , 256 )
projection , embedding = learner ( imgs , return_embedding = True ) 저장소는 이제 ? 허깅페이스 가속. 가져온 BYOLTrainer 에 자신의 Dataset 전달하기만 하면 됩니다.
먼저 가속 CLI를 호출하여 분산 교육을 위한 구성을 설정하세요.
$ accelerate config 그런 다음 아래와 같이 ./train.py 에서 학습 스크립트를 작성합니다.
from torchvision import models
from byol_pytorch import (
BYOL ,
BYOLTrainer ,
MockDataset
)
resnet = models . resnet50 ( pretrained = True )
dataset = MockDataset ( 256 , 10000 )
trainer = BYOLTrainer (
resnet ,
dataset = dataset ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
learning_rate = 3e-4 ,
num_train_steps = 100_000 ,
batch_size = 16 ,
checkpoint_every = 1000 # improved model will be saved periodically to ./checkpoints folder
)
trainer ()그런 다음 가속 CLI를 다시 사용하여 스크립트를 시작하십시오.
$ accelerate launch ./train.py다운스트림 작업에 세분화가 포함된 경우 BYOL을 '픽셀' 수준 학습으로 확장하는 다음 저장소를 살펴보세요.
https://github.com/lucidrains/pixel-level-contrastive-learning
@misc { grill2020bootstrap ,
title = { Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning } ,
author = { Jean-Bastien Grill and Florian Strub and Florent Altché and Corentin Tallec and Pierre H. Richemond and Elena Buchatskaya and Carl Doersch and Bernardo Avila Pires and Zhaohan Daniel Guo and Mohammad Gheshlaghi Azar and Bilal Piot and Koray Kavukcuoglu and Rémi Munos and Michal Valko } ,
year = { 2020 } ,
eprint = { 2006.07733 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { chen2020exploring ,
title = { Exploring Simple Siamese Representation Learning } ,
author = { Xinlei Chen and Kaiming He } ,
year = { 2020 } ,
eprint = { 2011.10566 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

