sinkhorn transformer
0.11.4
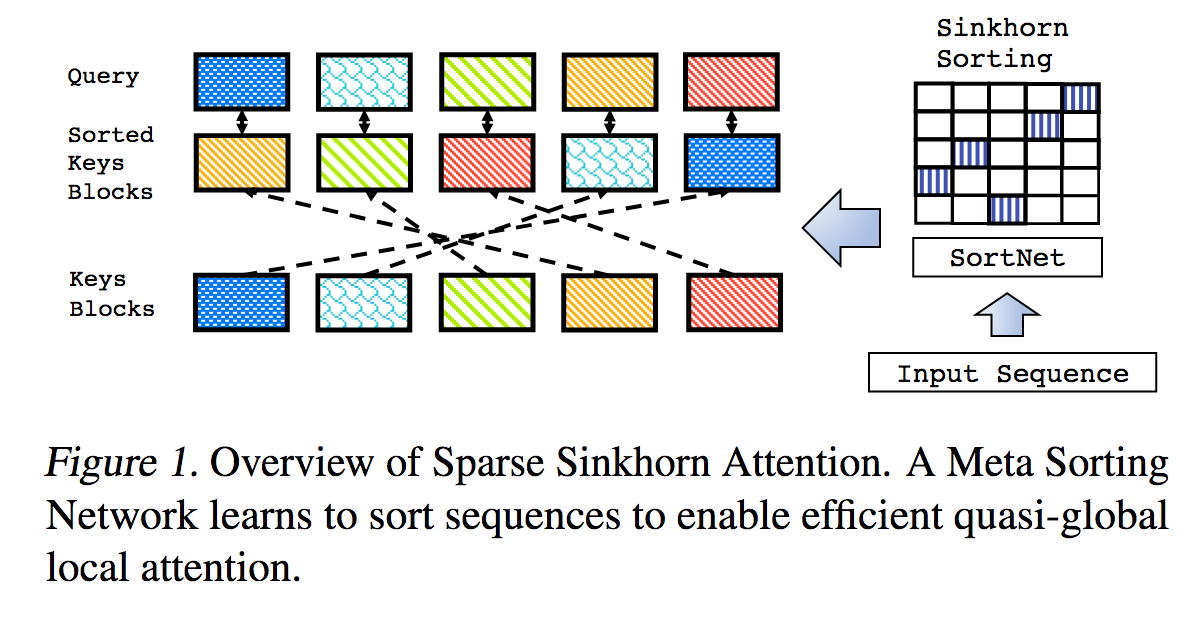
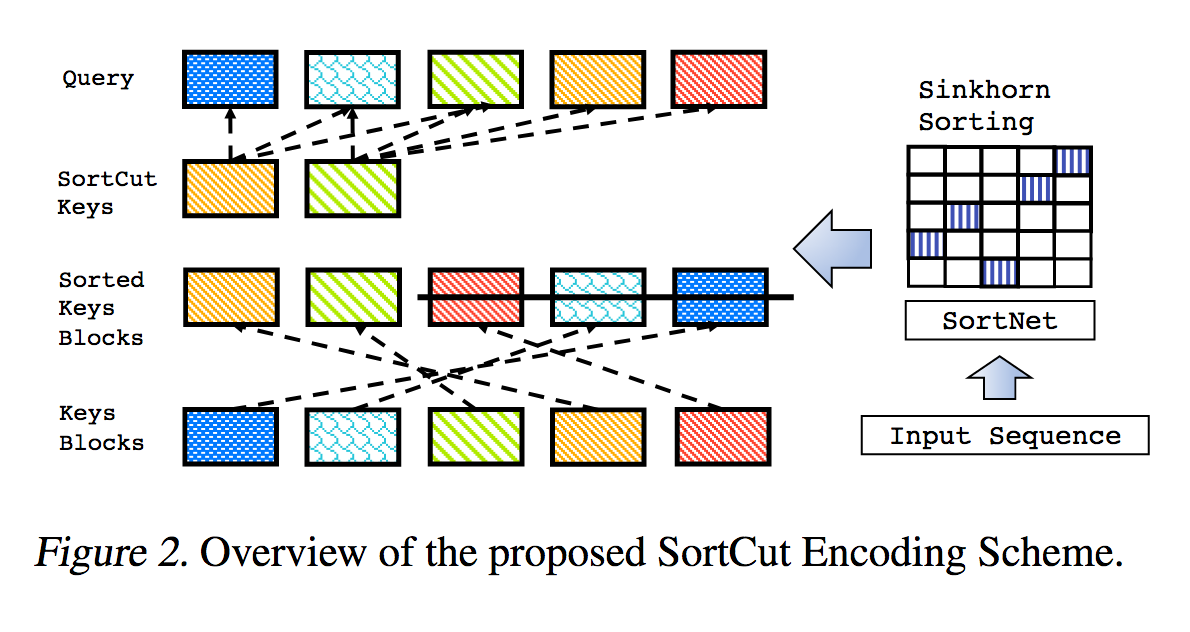
이것은 Sparse Sinkhorn Attention에 설명된 작업을 추가 개선 사항과 함께 재현한 것입니다.
여기에는 싱크혼 정규화를 사용하여 가장 관련성이 높은 키 버킷과 쿼리 버킷을 일치시키는 순열 행렬을 샘플링하는 매개변수화된 정렬 네트워크가 포함되어 있습니다.
이 작업은 또한 가역적 네트워크와 피드포워드 청킹(Reformer에서 도입된 개념)을 도입하여 메모리를 더욱 절약합니다.
204k 토큰(데모 목적)
$ pip install sinkhorn_transformerSinkhorn Transformer 기반 언어 모델
import torch
from sinkhorn_transformer import SinkhornTransformerLM
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
max_seq_len = 8192 ,
bucket_size = 128 , # size of the buckets
causal = False , # auto-regressive or not
n_sortcut = 2 , # use sortcut to reduce memory complexity to linear
n_top_buckets = 2 , # sort specified number of key/value buckets to one query bucket. paper is at 1, defaults to 2
ff_chunks = 10 , # feedforward chunking, from Reformer paper
reversible = True , # make network reversible, from Reformer paper
emb_dropout = 0.1 , # embedding dropout
ff_dropout = 0.1 , # feedforward dropout
attn_dropout = 0.1 , # post attention dropout
attn_layer_dropout = 0.1 , # post attention layer dropout
layer_dropout = 0.1 , # add layer dropout, from 'Reducing Transformer Depth on Demand' paper
weight_tie = True , # tie layer parameters, from Albert paper
emb_dim = 128 , # embedding factorization, from Albert paper
dim_head = 64 , # be able to fix the dimension of each head, making it independent of the embedding dimension and the number of heads
ff_glu = True , # use GLU in feedforward, from paper 'GLU Variants Improve Transformer'
n_local_attn_heads = 2 , # replace N heads with local attention, suggested to work well from Routing Transformer paper
pkm_layers = ( 4 , 7 ), # specify layers to use product key memory. paper shows 1 or 2 modules near the middle of the transformer is best
pkm_num_keys = 128 , # defaults to 128, but can be increased to 256 or 512 as memory allows
)
x = torch . randint ( 0 , 20000 , ( 1 , 2048 ))
model ( x ) # (1, 2048, 20000)평범한 싱크혼 트랜스포머, 여러 겹의 싱크혼 주의
import torch
from sinkhorn_transformer import SinkhornTransformer
model = SinkhornTransformer (
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 128
)
x = torch . randn ( 1 , 2048 , 1024 )
model ( x ) # (1, 2048, 1024)Sinkhorn 인코더/디코더 변압기
import torch
from sinkhorn_transformer import SinkhornTransformerLM
DE_SEQ_LEN = 4096
EN_SEQ_LEN = 4096
enc = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
heads = 8 ,
bucket_size = 128 ,
max_seq_len = DE_SEQ_LEN ,
reversible = True ,
return_embeddings = True
). cuda ()
dec = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
causal = True ,
bucket_size = 128 ,
max_seq_len = EN_SEQ_LEN ,
receives_context = True ,
context_bucket_size = 128 , # context key / values can be bucketed differently
reversible = True
). cuda ()
x = torch . randint ( 0 , 20000 , ( 1 , DE_SEQ_LEN )). cuda ()
y = torch . randint ( 0 , 20000 , ( 1 , EN_SEQ_LEN )). cuda ()
x_mask = torch . ones_like ( x ). bool (). cuda ()
y_mask = torch . ones_like ( y ). bool (). cuda ()
context = enc ( x , input_mask = x_mask )
dec ( y , context = context , input_mask = y_mask , context_mask = x_mask ) # (1, 4096, 20000) 기본적으로 버킷 크기의 배수가 아닌 입력이 주어지면 모델은 불만을 표시합니다. 매번 동일한 패딩 계산을 하지 않으려면 도우미 Autopadder 클래스를 사용할 수 있습니다. 주어진 경우 input_mask 도 처리해 줍니다. 상황별 키/값 및 마스크도 지원됩니다.
import torch
from sinkhorn_transformer import SinkhornTransformerLM
from sinkhorn_transformer import Autopadder
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
max_seq_len = 2048 ,
bucket_size = 128 ,
causal = True
)
model = Autopadder ( model , pad_left = True ) # autopadder will fetch the bucket size and autopad input
x = torch . randint ( 0 , 20000 , ( 1 , 1117 )) # odd sequence length
model ( x ) # (1, 1117, 20000) 이 저장소는 논문에서 분리되어 현재 원래의 분류망 + 검벨 싱크혼 샘플링 대신 주목을 받고 있습니다. 아직 눈에 띄는 성능 차이를 발견하지 못했고, 새로운 방식을 사용하면 네트워크를 유연한 시퀀스 길이로 일반화할 수 있습니다. Sinkhorn을 사용해보고 싶다면 비인과적 네트워크에서만 작동하는 다음 설정을 사용하세요.
import torch
from sinkhorn_transformer import SinkhornTransformerLM
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 128 ,
max_seq_len = 8192 ,
use_simple_sort_net = True , # turn off attention sort net
sinkhorn_iter = 7 , # number of sinkhorn iterations - default is set at reported best in paper
n_sortcut = 2 , # use sortcut to reduce complexity to linear time
temperature = 0.75 , # gumbel temperature - default is set at reported best in paper
non_permutative = False , # allow buckets of keys to be sorted to queries more than once
)
x = torch . randint ( 0 , 20000 , ( 1 , 8192 ))
model ( x ) # (1, 8192, 20000) PKM 사용의 이점을 보려면 값의 학습률을 나머지 매개변수보다 높게 설정해야 합니다. ( 1e-2 권장)
여기 지침에 따라 올바르게 설정할 수 있습니다 https://github.com/lucidrains/product-key-memory#learning-rates
고정 길이 시퀀스에 대해 교육을 받은 Sinkhorn은 처음부터 시퀀스를 디코딩하는 데 문제가 있는 것 같습니다. 이는 주로 버킷이 패딩 토큰으로 부분적으로 채워질 때 정렬 네트워크가 일반화하는 데 문제가 있다는 사실 때문입니다.
다행히 간단한 해결책을 찾은 것 같습니다. 훈련 중에 인과 네트워크의 경우 시퀀스를 무작위로 자르고 정렬 네트워크가 일반화되도록 강제합니다. 이를 쉽게 하기 위해 AutoregressiveWrapper 인스턴스에 대한 플래그( randomly_truncate_sequence )를 제공했습니다.
import torch
from sinkhorn_transformer import SinkhornTransformerLM , AutoregressiveWrapper
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 75 ,
max_seq_len = 8192 ,
causal = True
)
model = AutoregressiveWrapper ( model )
x = torch . randint ( 0 , 20000 , ( 1 , 8192 ))
loss = model ( x , return_loss = True , randomly_truncate_sequence = True ) # (1, 8192, 20000)누군가가 더 나은 솔루션을 찾았다면 제안을 받을 수 있습니다.
인과 정렬 네트워크에는 잠재적인 문제가 있습니다. 과거의 어떤 키/값 버킷이 버킷으로 정렬되는지에 대한 결정은 첫 번째 토큰에만 의존하고 나머지 토큰에는 의존하지 않습니다(버케팅 방식과 미래의 유출 방지로 인해). 과거).
나는 버킷 크기 - 1만큼 헤드의 절반을 왼쪽으로 회전하여 마지막 토큰을 첫 번째 토큰으로 승격시켜 이 문제를 완화하려고 시도했습니다. 이는 AutoregressiveWrapper 가 학습 중에 기본적으로 왼쪽 패딩을 사용하는 이유이기도 하며, 항상 시퀀스의 마지막 토큰이 검색할 대상을 결정하도록 하기 위한 것입니다.
누구든지 더 깨끗한 해결책을 찾았다면 문제를 통해 알려주시기 바랍니다.
@misc { tay2020sparse ,
title = { Sparse Sinkhorn Attention } ,
author = { Yi Tay and Dara Bahri and Liu Yang and Donald Metzler and Da-Cheng Juan } ,
year = { 2020 } ,
url. = { https://arxiv.org/abs/2002.11296 }
} @inproceedings { kitaev2020reformer ,
title = { Reformer: The Efficient Transformer } ,
author = { Nikita Kitaev and Lukasz Kaiser and Anselm Levskaya } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=rkgNKkHtvB }
} @misc { lan2019albert ,
title = { ALBERT: A Lite BERT for Self-supervised Learning of Language Representations } ,
author = { Zhenzhong Lan and Mingda Chen and Sebastian Goodman and Kevin Gimpel and Piyush Sharma and Radu Soricut } ,
year = { 2019 } ,
url = { https://arxiv.org/abs/1909.11942 }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @misc { roy*2020efficient ,
title = { Efficient Content-Based Sparse Attention with Routing Transformers } ,
author = { Aurko Roy* and Mohammad Taghi Saffar* and David Grangier and Ashish Vaswani } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=B1gjs6EtDr }
} @inproceedings { fan2020reducing ,
title = { Reducing Transformer Depth on Demand with Structured Dropout } ,
author = { Angela Fan and Edouard Grave and Armand Joulin } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=SylO2yStDr }
} @misc { lample2019large ,
title = { Large Memory Layers with Product Keys } ,
author = { Guillaume Lample and Alexandre Sablayrolles and Marc'Aurelio Ranzato and Ludovic Denoyer and Hervé Jégou } ,
year = { 2019 } ,
eprint = { 1907.05242 } ,
archivePrefix = { arXiv }
} @misc { bhojanapalli2020lowrank ,
title = { Low-Rank Bottleneck in Multi-head Attention Models } ,
author = { Srinadh Bhojanapalli and Chulhee Yun and Ankit Singh Rawat and Sashank J. Reddi and Sanjiv Kumar } ,
year = { 2020 } ,
eprint = { 2002.07028 }
}


