Mega pytorch
0.1.0
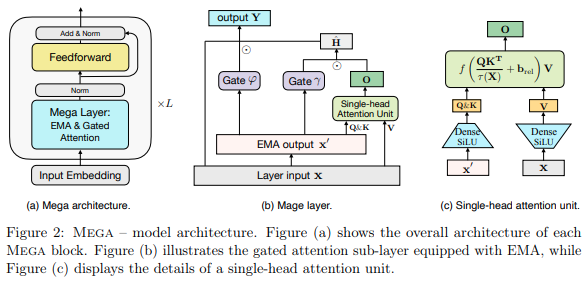
현재 Long Range Arena에서 SOTA를 보유하고 있는 아키텍처에 존재하는 Multi-headed EMA 레이어를 갖춘 Mega 레이어인 Single-head Attention을 구현하여 Pathfinder-X에서 S4를 제치고 오디오를 위한 기타 모든 작업을 수행합니다.
$ pip install mega-pytorch관심과 학습된 EMA가 결합된 메가 레이어
import torch
from mega_pytorch import MegaLayer
layer = MegaLayer (
dim = 128 , # model dimensions
ema_heads = 16 , # number of EMA heads
attn_dim_qk = 64 , # dimension of queries / keys in attention
attn_dim_value = 256 , # dimension of values in attention
laplacian_attn_fn = False , # whether to use softmax (false) or laplacian attention activation fn (true)
)
x = torch . randn ( 1 , 1024 , 128 ) # (batch, seq, dim)
out = layer ( x ) # (1, 1024, 128)풀 메가(현재는 layernorm 사용)
import torch
from mega_pytorch import Mega
mega = Mega (
num_tokens = 256 , # number of tokens
dim = 128 , # model dimensions
depth = 6 , # depth
ema_heads = 16 , # number of EMA heads
attn_dim_qk = 64 , # dimension of queries / keys in attention
attn_dim_value = 256 , # dimensino of values in attention
laplacian_attn_fn = True , # whether to use softmax (false) or laplacian attention activation fn (true)
)
x = torch . randint ( 0 , 256 , ( 1 , 1024 ))
logits = mega ( x ) # (1, 1024, 256) @inproceedings { Ma2022MegaMA ,
title = { Mega: Moving Average Equipped Gated Attention } ,
author = { Xuezhe Ma and Chunting Zhou and Xiang Kong and Junxian He and Liangke Gui and Graham Neubig and Jonathan May and Luke Zettlemoyer } ,
year = { 2022 }
}

