antialiased cnns
v0.3
컨벌루션 네트워크를 다시 이동불변으로 만들기
리처드 장. ICML에서는 2019.
pip install antialiased-cnns 실행
import antialiased_cnns
model = antialiased_cnns . resnet50 ( pretrained = True ) 모델이 이미 있고 앤티앨리어싱을 수행하고 훈련을 계속하려면 이전 가중치를 다음 위치에 복사하세요.
import torchvision . models as models
old_model = models . resnet50 ( pretrained = True ) # old (aliased) model
antialiased_cnns . copy_params_buffers ( old_model , model ) # copy the weights over자신의 모델을 수정하려면 BlurPool 레이어를 사용하세요. 제공된 모델과 BlurPool 사용 방법에 대한 자세한 내용은 아래를 참조하세요.
C = 10 # example feature channel size
blurpool = antialiased_cnns . BlurPool ( C , stride = 2 ) # BlurPool layer; use to downsample a feature map
ex_tens = torch . Tensor ( 1 , C , 128 , 128 )
print ( blurpool ( ex_tens ). shape ) # 1xCx64x64 tensor업데이트
pip install antialiased-cnns 하고 pretrained=True 플래그를 사용하여 모델을 로드할 수도 있습니다.BlurPool 레이어를 사용하여 자신의 모델을 앤티앨리어싱하는 방법에 대한 지침Pip으로 이 패키지를 설치하세요.
pip install antialiased-cnns또는 이 저장소를 복제하고 요구 사항(특히 PyTorch)을 설치합니다.
https://github.com/adobe/antialiased-cnns.git
cd antialiased-cnns
pip install -r requirements.txt다음은 아마도 애플리케이션의 백본으로 사전 훈련된 앤티앨리어싱 모델을 로드합니다.
import antialiased_cnns
model = antialiased_cnns . resnet50 ( pretrained = True , filter_size = 4 ) 또한 앤티앨리어싱된 AlexNet , VGG16(bn) , Resnet18,34,50,101 , Densenet121 및 MobileNetv2 에 대한 가중치도 제공합니다(example_usage.py 참조).
antialiased_cnns 모듈에는 흐림+서브샘플링을 수행하는 BlurPool 클래스가 포함되어 있습니다. pip install antialiased-cnns 실행하거나 antialiased_cnns 하위 디렉터리를 복사합니다.
방법론 방법론은 간단합니다. 먼저 스트라이드 1로 평가한 다음 BlurPool 레이어를 사용하여 앤티앨리어싱된 다운샘플링을 수행합니다. 다음과 같은 아키텍처 변경을 수행합니다.
import antialiased_cnns
# MaxPool --> MaxBlurPool
baseline = nn . MaxPool2d ( kernel_size = 2 , stride = 2 )
antialiased = [ nn . MaxPool2d ( kernel_size = 2 , stride = 1 ),
antialiased_cnns . BlurPool ( C , stride = 2 )]
# Conv --> ConvBlurPool
baseline = [ nn . Conv2d ( Cin , C , kernel_size = 3 , stride = 2 , padding = 1 ),
nn . ReLU ( inplace = True )]
antialiased = [ nn . Conv2d ( Cin , C , kernel_size = 3 , stride = 1 , padding = 1 ),
nn . ReLU ( inplace = True ),
antialiased_cnns . BlurPool ( C , stride = 2 )]
# AvgPool --> BlurPool
baseline = nn . AvgPool2d ( kernel_size = 2 , stride = 2 )
antialiased = antialiased_cnns . BlurPool ( C , stride = 2 ) 들어오는 텐서에 C 채널이 있다고 가정합니다. 스트라이드 2 대신 스트라이드 1에서 레이어를 계산하면 메모리와 런타임이 추가됩니다. 따라서 우리는 일반적으로 큰 증가를 방지하기 위해 최고 해상도(네트워크 초기)에서 앤티앨리어싱을 건너뜁니다.
안티앨리어싱을 추가한 후 훈련 계속하기 이미 모델을 훈련한 다음 안티앨리어싱을 추가한 경우 이전 모델에서 세부 조정할 수 있습니다.
antialiased_cnns . copy_params_buffers ( old_model , antialiased_model )그래도 문제가 해결되지 않으면 버퍼가 아닌 매개변수만 복사하면 됩니다. 앤티앨리어싱을 추가해도 매개변수가 추가되지 않으므로 매개변수 목록이 동일합니다. (버퍼를 추가하므로 버퍼를 일치시키기 위해 일부 경험적 방법이 사용되며 이로 인해 오류가 발생할 수 있습니다.)
antialiased_cnns . copy_params ( old_model , antialiased_model )정확성 (이미지가 올바르게 분류되는 빈도)과 일관성 (동일한 이미지의 두 시프트가 동일하게 분류되는 빈도)이 모두 향상되는 것을 관찰했습니다.
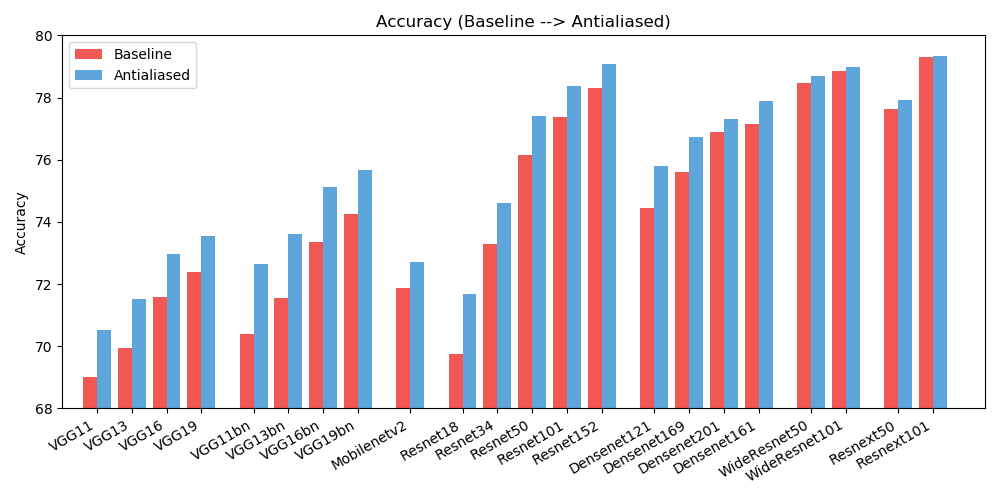
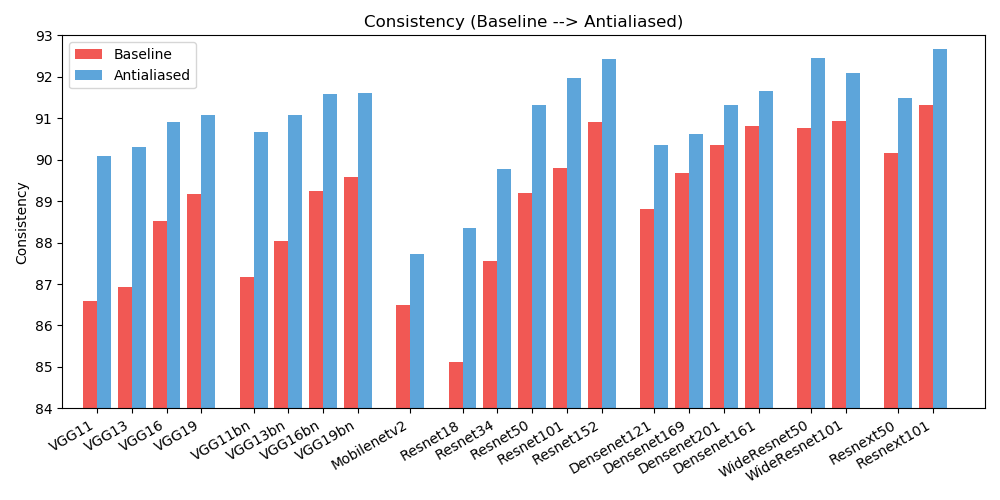
| 정확성 | 기준선 | 앤티앨리어싱 | 델타 |
|---|---|---|---|
| 알렉스넷 | 56.55 | 56.94 | +0.39 |
| vgg11 | 69.02 | 70.51 | +1.49 |
| vgg13 | 69.93 | 71.52 | +1.59 |
| vgg16 | 71.59 | 72.96 | +1.37 |
| vgg19 | 72.38 | 73.54 | +1.16 |
| vgg11_bn | 70.38 | 72.63 | +2.25 |
| vgg13_bn | 71.55 | 73.61 | +2.06 |
| vgg16_bn | 73.36 | 75.13 | +1.77 |
| vgg19_bn | 74.24 | 75.68 | +1.44 |
| resnet18 | 69.74 | 71.67 | +1.93 |
| resnet34 | 73.30 | 74.60 | +1.30 |
| resnet50 | 76.16 | 77.41 | +1.25 |
| resnet101 | 77.37 | 78.38 | +1.01 |
| resnet152 | 78.31 | 79.07 | +0.76 |
| resnext50_32x4d | 77.62 | 77.93 | +0.31 |
| resnext101_32x8d | 79.31 | 79.33 | +0.02 |
| wide_resnet50_2 | 78.47 | 78.70 | +0.23 |
| wide_resnet101_2 | 78.85 | 78.99 | +0.14 |
| 덴스넷121 | 74.43 | 75.79 | +1.36 |
| 덴스넷169 | 75.60 | 76.73 | +1.13 |
| 덴스넷201 | 76.90 | 77.31 | +0.41 |
| 덴스넷161 | 77.14 | 77.88 | +0.74 |
| mobilenet_v2 | 71.88 | 72.72 | +0.84 |
| 일관성 | 기준선 | 앤티앨리어싱 | 델타 |
|---|---|---|---|
| 알렉스넷 | 78.18 | 83.31 | +5.13 |
| vgg11 | 86.58 | 90.09 | +3.51 |
| vgg13 | 86.92 | 90.31 | +3.39 |
| vgg16 | 88.52 | 90.91 | +2.39 |
| vgg19 | 89.17 | 91.08 | +1.91 |
| vgg11_bn | 87.16 | 90.67 | +3.51 |
| vgg13_bn | 88.03 | 91.09 | +3.06 |
| vgg16_bn | 89.24 | 91.58 | +2.34 |
| vgg19_bn | 89.59 | 91.60 | +2.01 |
| resnet18 | 85.11 | 88.36 | +3.25 |
| resnet34 | 87.56 | 89.77 | +2.21 |
| resnet50 | 89.20 | 91.32 | +2.12 |
| resnet101 | 89.81 | 91.97 | +2.16 |
| resnet152 | 90.92 | 92.42 | +1.50 |
| resnext50_32x4d | 90.17 | 91.48 | +1.31 |
| resnext101_32x8d | 91.33 | 92.67 | +1.34 |
| wide_resnet50_2 | 90.77 | 92.46 | +1.69 |
| wide_resnet101_2 | 90.93 | 92.10 | +1.17 |
| 덴스넷121 | 88.81 | 90.35 | +1.54 |
| 덴스넷169 | 89.68 | 90.61 | +0.93 |
| 덴스넷201 | 90.36 | 91.32 | +0.96 |
| 덴스넷161 | 90.82 | 91.66 | +0.84 |
| mobilenet_v2 | 86.50 | 87.73 | +1.23 |
혼란을 줄이기 위해 확장된 결과(다양한 필터 크기)가 여기에 있습니다. 결과를 개선하는 데 도움을 주세요!
이 저작물은 Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License에 따라 라이센스가 부여됩니다.
모든 자료는 Adobe Inc.의 Creative Commons BY-NC-SA 4.0 라이센스에 따라 제공됩니다 . 당사 논문을 인용 하고 변경 사항을 표시하여 적절한 출처를 표시하는 한 비상업적 목적 으로 자료를 사용, 재배포 및 조정할 수 있습니다. 당신이 만든 것.
저장소는 PyTorch 예제 저장소와 torchvision 모델 저장소를 기반으로 구축됩니다. 이는 BSD 스타일 라이센스입니다.
이것이 귀하의 연구에 유용하다고 생각되면 이 bibtex를 인용하는 것을 고려해 보십시오. 의견이나 피드백이 있으면 Richard Zhang <rizhang at adobe dot com>에게 문의하세요.


