igel
v1.0.0
코드를 작성하지 않고도 모델을 학습/맞춤, 테스트 및 사용할 수 있는 즐거운 기계 학습 도구입니다.
메모
나는 또한 사람들의 요청에 따라 igel용 GUI 데스크탑 앱을 작업하고 있습니다. Igel-UI에서 찾으실 수 있습니다.
목차
이 프로젝트의 목표는 기술 사용자와 비기술 사용자 모두 에게 기계 학습을 제공하는 것입니다.
가끔 기계 학습 프로토타입을 빠르게 만드는 데 사용할 수 있는 도구가 필요했습니다. 개념 증명을 구축할지, 빠른 초안 모델을 만들어 요점을 증명할지, 자동 ML을 사용할지 여부. 나는 상용구 코드를 작성하는 데 어려움을 겪고 어디서부터 시작해야 할지 너무 많이 생각하는 경우가 많습니다. 그래서 저는 이 도구를 만들기로 결정했습니다.
igel은 다른 ML 프레임워크 위에 구축되었습니다. 이는 한 줄의 코드도 작성하지 않고도 기계 학습을 사용할 수 있는 간단한 방법을 제공합니다. Igel은 사용자 정의가 가능 하지만 원하는 경우에만 가능합니다. Igel은 사용자에게 어떤 것도 사용자 정의하도록 강요하지 않습니다. 기본값 외에도 igel은 자동 ML 기능을 사용하여 데이터에 잘 맞는 모델을 찾아낼 수 있습니다.
필요한 것은 수행하려는 작업을 설명하는 yaml (또는 json ) 파일뿐입니다. 그게 다야!
Igel은 회귀, 분류 및 클러스터링을 지원합니다. Igel은 ImageClassification 및 TextClassification과 같은 자동 ML 기능을 지원합니다.
Igel은 데이터 과학 분야에서 가장 많이 사용되는 데이터 세트 유형을 지원합니다. 예를 들어, 입력 데이터 세트는 가져오려는 csv, txt, Excel 시트, json 또는 html 파일일 수 있습니다. 자동 ML 기능을 사용하는 경우 igel에 원시 데이터를 공급하면 이를 처리하는 방법을 알아낼 수도 있습니다. 이에 대해서는 나중에 예제에서 자세히 설명합니다.
$ pip install -U igel Igel의 지원 모델:
+--------------------+----------------------------+-------------------------+
| regression | classification | clustering |
+--------------------+----------------------------+-------------------------+
| LinearRegression | LogisticRegression | KMeans |
| Lasso | Ridge | AffinityPropagation |
| LassoLars | DecisionTree | Birch |
| BayesianRegression | ExtraTree | AgglomerativeClustering |
| HuberRegression | RandomForest | FeatureAgglomeration |
| Ridge | ExtraTrees | DBSCAN |
| PoissonRegression | SVM | MiniBatchKMeans |
| ARDRegression | LinearSVM | SpectralBiclustering |
| TweedieRegression | NuSVM | SpectralCoclustering |
| TheilSenRegression | NearestNeighbor | SpectralClustering |
| GammaRegression | NeuralNetwork | MeanShift |
| RANSACRegression | PassiveAgressiveClassifier | OPTICS |
| DecisionTree | Perceptron | KMedoids |
| ExtraTree | BernoulliRBM | ---- |
| RandomForest | BoltzmannMachine | ---- |
| ExtraTrees | CalibratedClassifier | ---- |
| SVM | Adaboost | ---- |
| LinearSVM | Bagging | ---- |
| NuSVM | GradientBoosting | ---- |
| NearestNeighbor | BernoulliNaiveBayes | ---- |
| NeuralNetwork | CategoricalNaiveBayes | ---- |
| ElasticNet | ComplementNaiveBayes | ---- |
| BernoulliRBM | GaussianNaiveBayes | ---- |
| BoltzmannMachine | MultinomialNaiveBayes | ---- |
| Adaboost | ---- | ---- |
| Bagging | ---- | ---- |
| GradientBoosting | ---- | ---- |
+--------------------+----------------------------+-------------------------+자동 ML의 경우:
help 명령은 지원되는 명령과 해당 인수/옵션을 확인하는 데 매우 유용합니다.
$ igel --help예를 들어, 하위 명령에 대한 도움말을 실행할 수도 있습니다.
$ igel fit --helpIgel은 사용자 정의가 가능합니다. 원하는 것이 무엇인지 알고 모델을 수동으로 구성하려는 경우 yaml 또는 json 구성 파일을 작성하는 방법을 안내하는 다음 섹션을 확인하세요. 그런 다음 igel에게 무엇을 해야 할지, 데이터와 구성 파일을 찾을 수 있는 위치를 알려 주기만 하면 됩니다. 예는 다음과 같습니다.
$ igel fit --data_path ' path_to_your_csv_dataset.csv ' --yaml_path ' path_to_your_yaml_file.yaml '그러나 자동 ML 기능을 사용하여 igel이 모든 작업을 수행하도록 할 수도 있습니다. 이에 대한 좋은 예는 이미지 분류입니다. 이미지 라는 폴더에 원시 이미지 데이터세트가 이미 저장되어 있다고 가정해 보겠습니다.
당신이 해야 할 일은 다음을 실행하는 것뿐입니다:
$ igel auto-train --data_path ' path_to_your_images_folder ' --task ImageClassification그게 다야! Igel은 디렉터리에서 이미지를 읽고, 데이터세트를 처리하고(행렬로 변환, 크기 조정, 분할 등...) 데이터에 잘 작동하는 모델 교육/최적화를 시작합니다. 보시다시피 매우 쉽습니다. 데이터에 대한 경로와 수행하려는 작업을 제공하기만 하면 됩니다.
메모
igel은 '최적의' 모델을 찾기 위해 다양한 모델을 시도하고 성능을 비교하므로 이 기능은 계산 비용이 많이 듭니다.
help 명령을 실행하여 지침을 얻을 수 있습니다. 하위 명령에 대한 도움말을 실행할 수도 있습니다!
$ igel --help첫 번째 단계는 yaml 파일을 제공하는 것입니다(원하는 경우 json을 사용할 수도 있습니다).
.yaml 파일(관례적으로 igel.yaml이라고 부르지만 원하는 대로 이름을 지정할 수 있음)을 생성하고 직접 편집하여 이 작업을 수동으로 수행할 수 있습니다. 그러나 게으른 경우(아마도 저와 같습니다 :D) igel init 명령을 사용하여 빠르게 시작할 수 있습니다. 그러면 즉시 기본 구성 파일이 생성됩니다.
"""
igel init --help
Example:
If I want to use neural networks to classify whether someone is sick or not using the indian-diabetes dataset,
then I would use this command to initialize a yaml file n.b. you may need to rename outcome column in .csv to sick:
$ igel init -type " classification " -model " NeuralNetwork " -target " sick "
"""
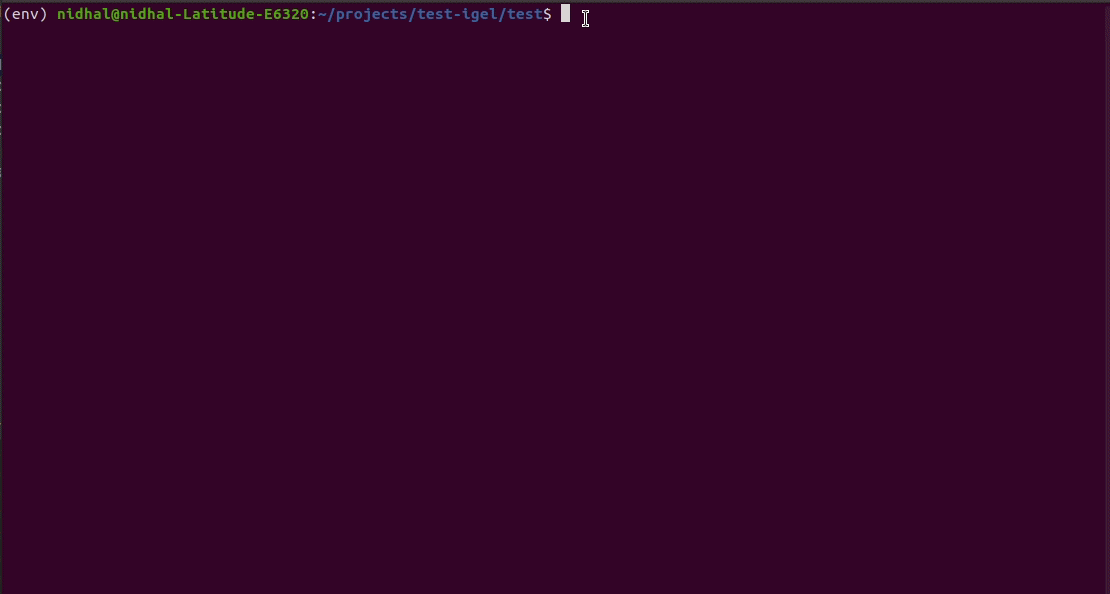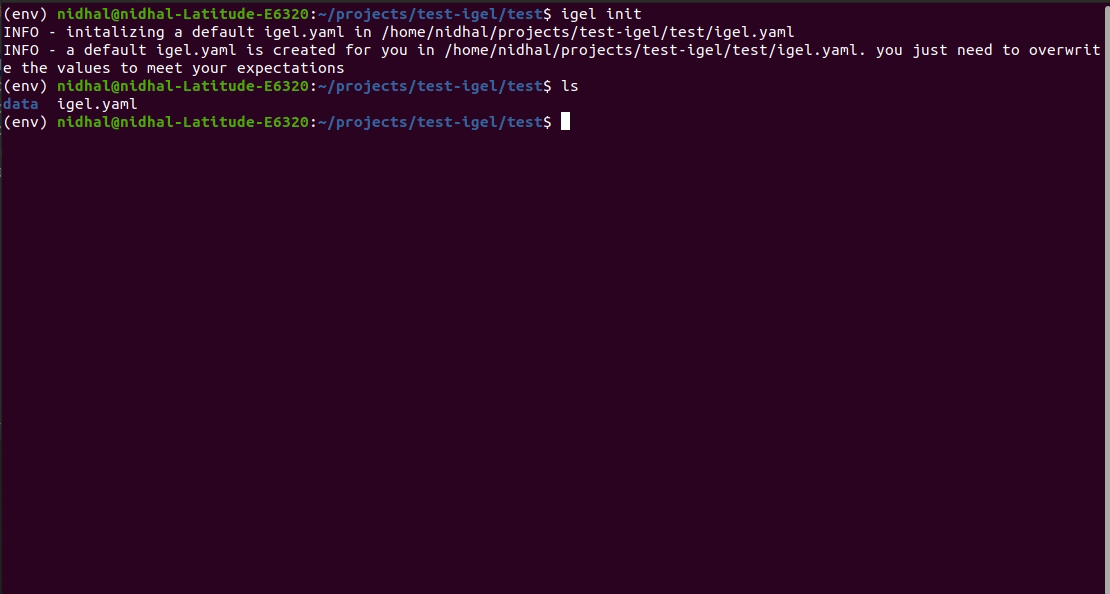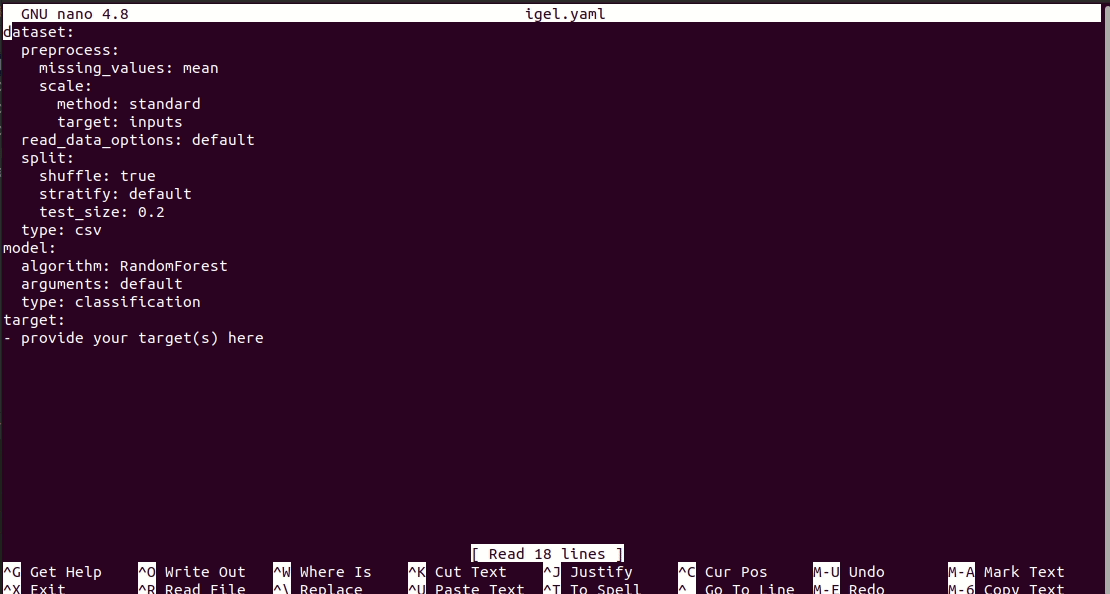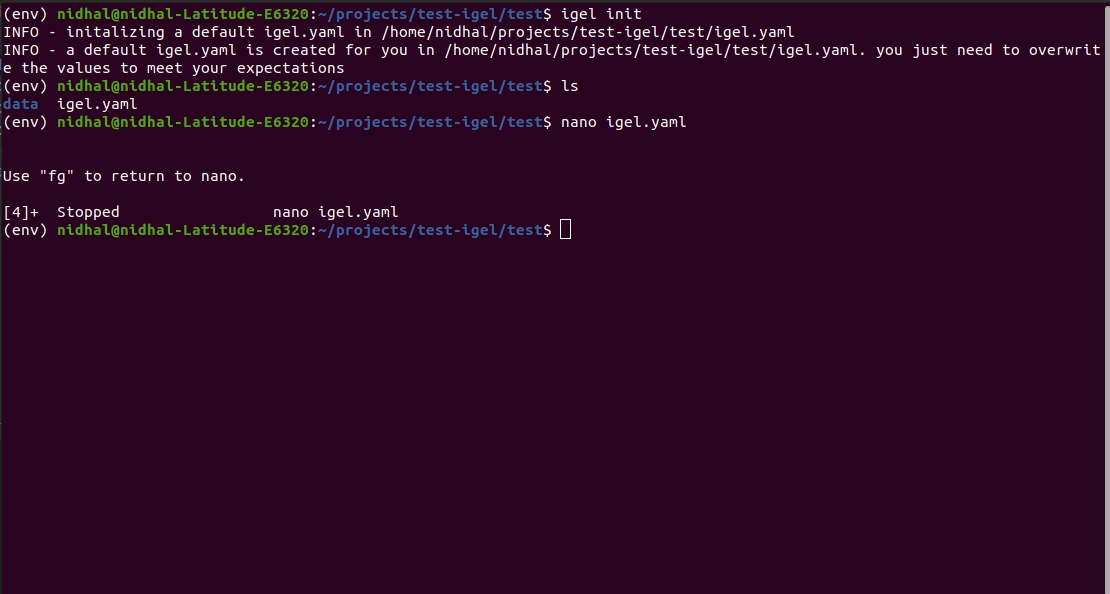
$ igel init명령을 실행하면 현재 작업 디렉터리에 igel.yaml 파일이 생성됩니다. 원하는 경우 확인하고 수정할 수 있습니다. 그렇지 않으면 처음부터 모든 것을 만들 수도 있습니다.
# model definition
model :
# in the type field, you can write the type of problem you want to solve. Whether regression, classification or clustering
# Then, provide the algorithm you want to use on the data. Here I'm using the random forest algorithm
type : classification
algorithm : RandomForest # make sure you write the name of the algorithm in pascal case
arguments :
n_estimators : 100 # here, I set the number of estimators (or trees) to 100
max_depth : 30 # set the max_depth of the tree
# target you want to predict
# Here, as an example, I'm using the famous indians-diabetes dataset, where I want to predict whether someone have diabetes or not.
# Depending on your data, you need to provide the target(s) you want to predict here
target :
- sick위의 예에서는 데이터 세트의 일부 기능에 따라 누군가 당뇨병이 있는지 여부를 분류하기 위해 랜덤 포레스트를 사용하고 있습니다. 이 예제 indian-diabetes 데이터 세트에서는 유명한 인도 당뇨병을 사용했습니다.
모델에 대한 추가 인수로 n_estimators 및 max_depth 전달했습니다. 인수를 제공하지 않으면 기본값이 사용됩니다. 각 모델의 주장을 외울 필요는 없습니다. 언제든지 터미널에서 igel models 실행할 수 있습니다. 그러면 대화형 모드로 전환되어 사용하려는 모델을 입력하고 해결하려는 문제를 입력하라는 메시지가 표시됩니다. 그런 다음 Igel은 모델에 대한 정보와 사용 가능한 인수 목록 및 이를 사용하는 방법을 볼 수 있는 링크를 보여줍니다.
터미널에서 이 명령을 실행하여 모델을 맞춤/훈련하세요. 여기에서 데이터세트 경로 와 yaml 파일 경로를 제공하세요.
$ igel fit --data_path ' path_to_your_csv_dataset.csv ' --yaml_path ' path_to_your_yaml_file.yaml '
# or shorter
$ igel fit -dp ' path_to_your_csv_dataset.csv ' -yml ' path_to_your_yaml_file.yaml '
"""
That's it. Your "trained" model can be now found in the model_results folder
(automatically created for you in your current working directory).
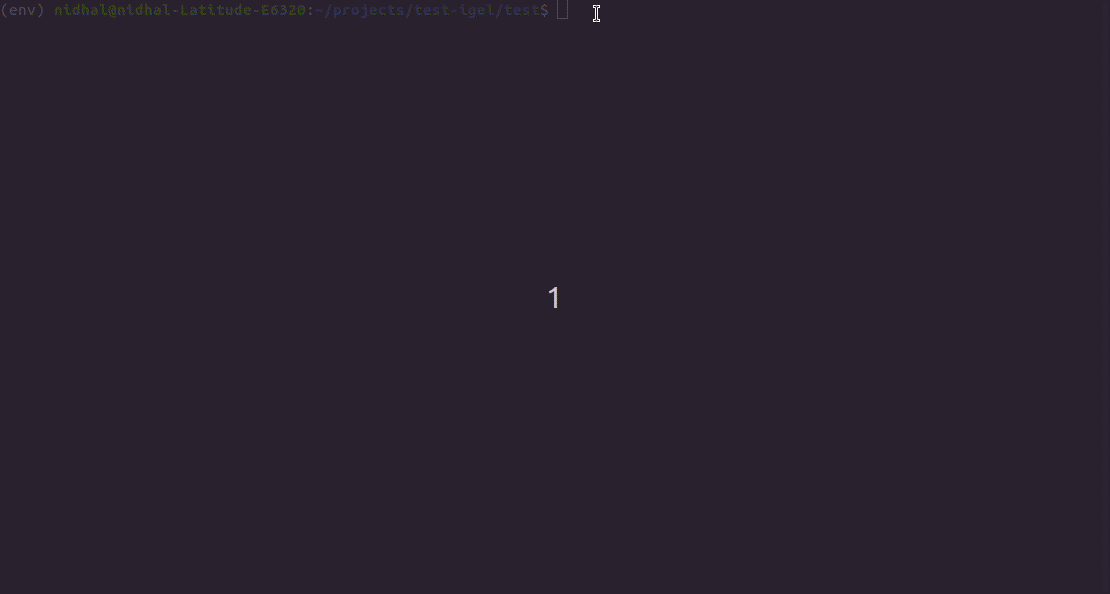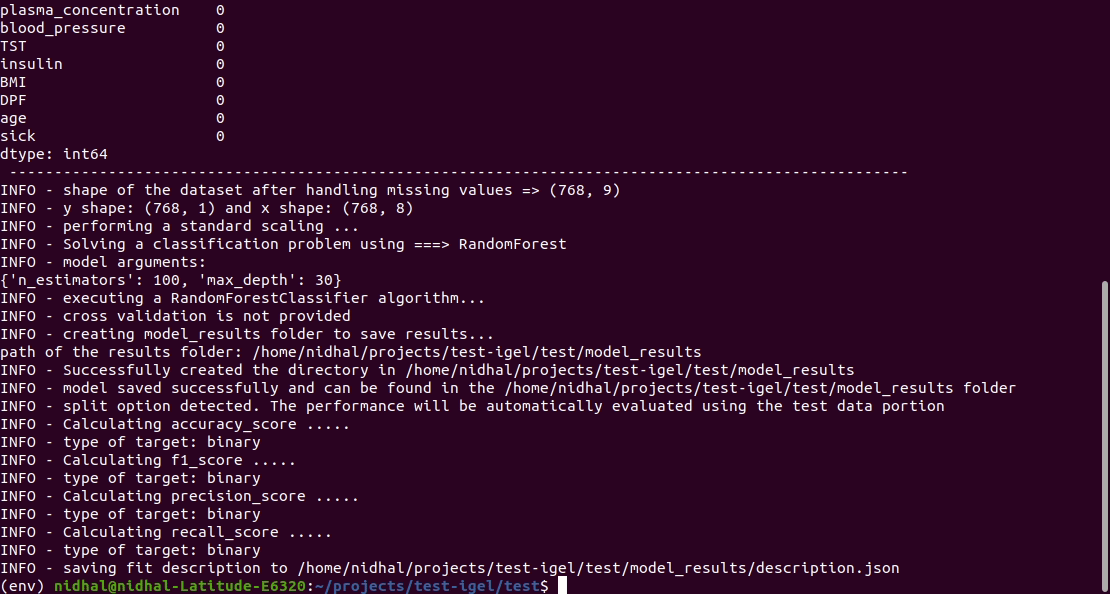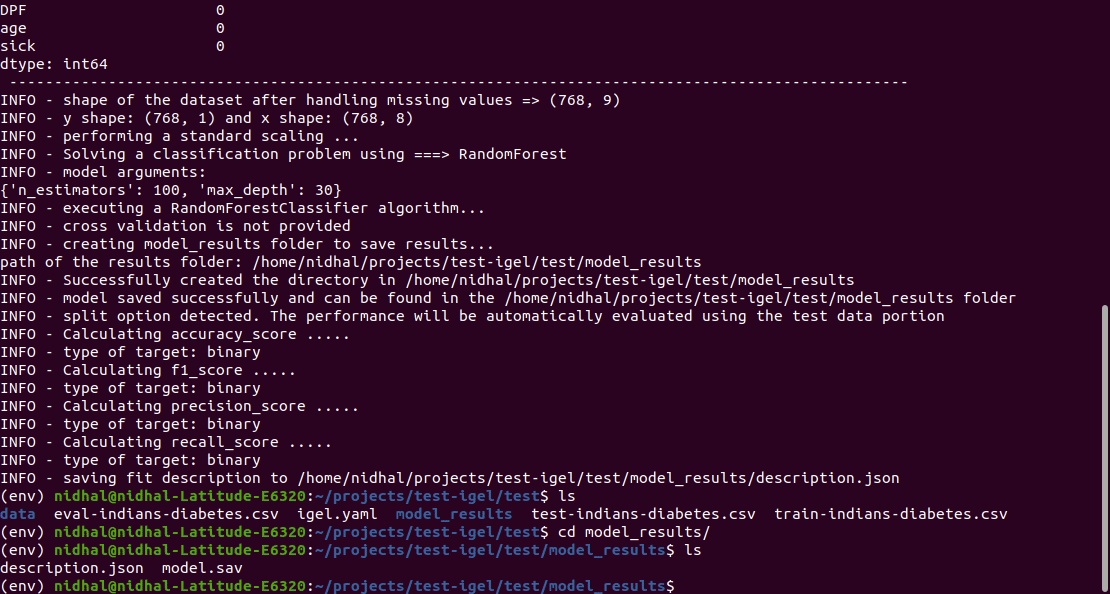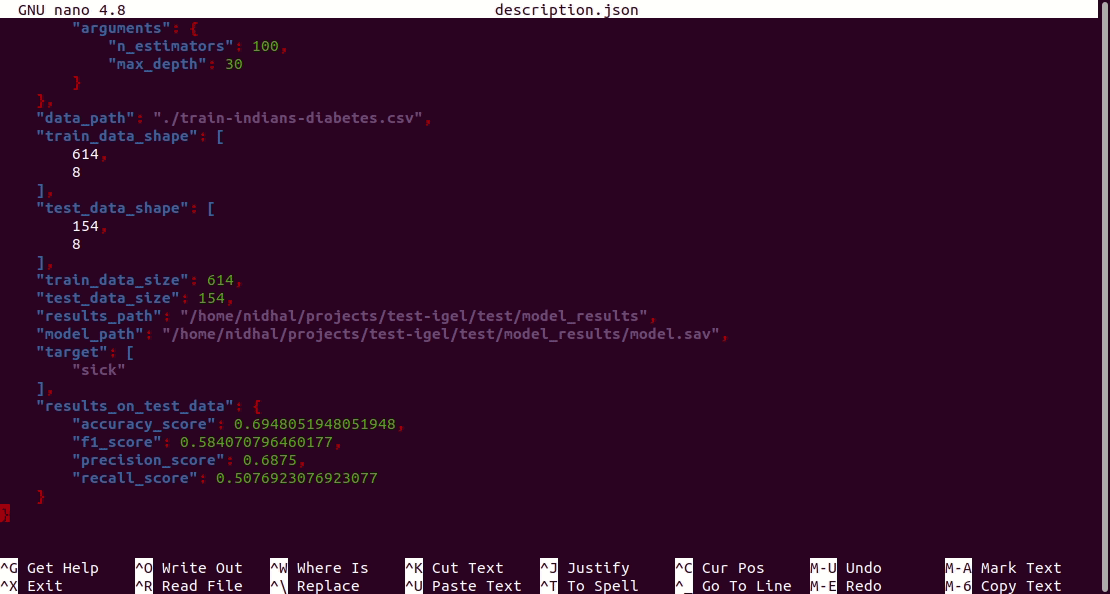
Furthermore, a description can be found in the description.json file inside the model_results folder.
"""
그런 다음 학습된/사전 맞춤된 모델을 평가할 수 있습니다.
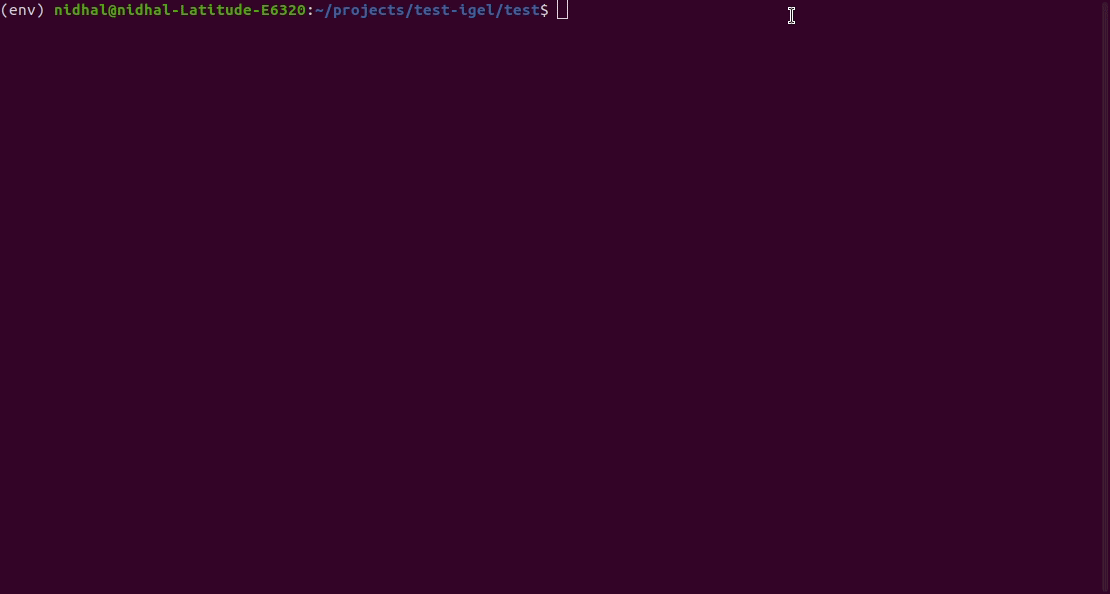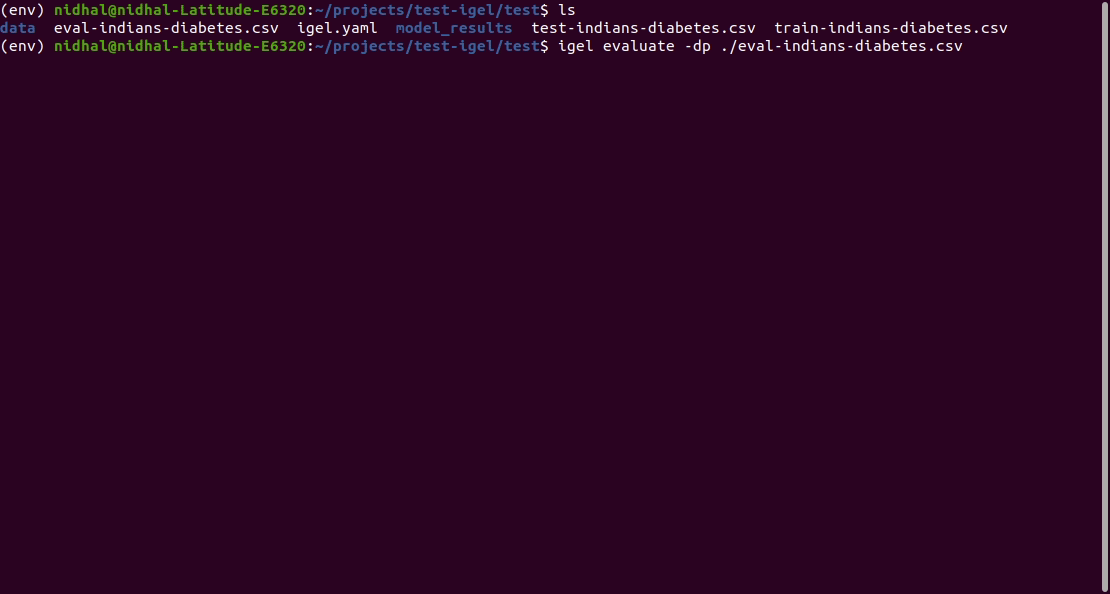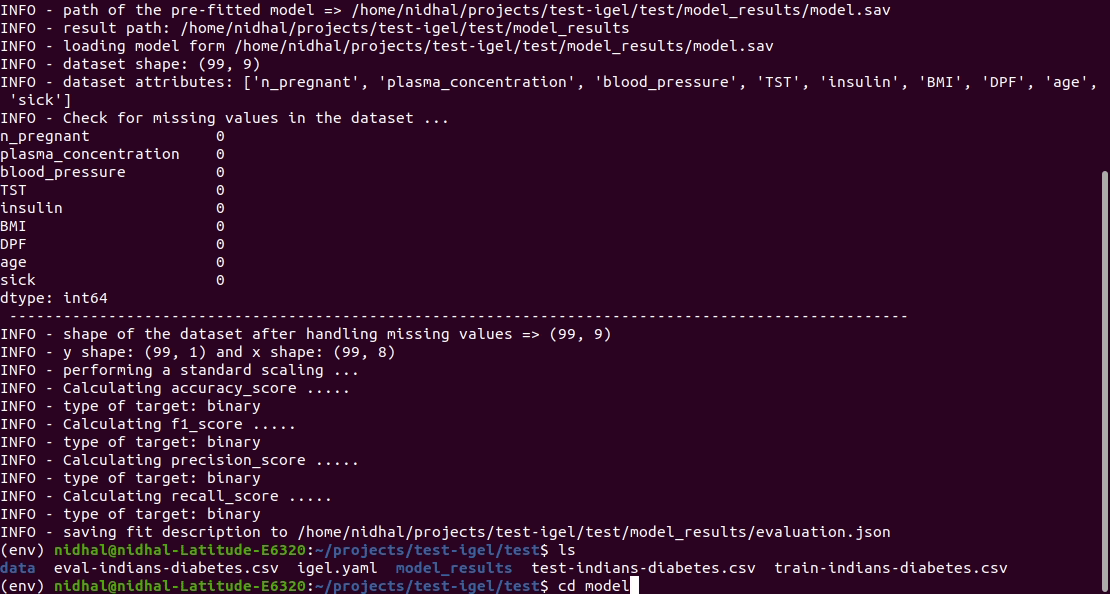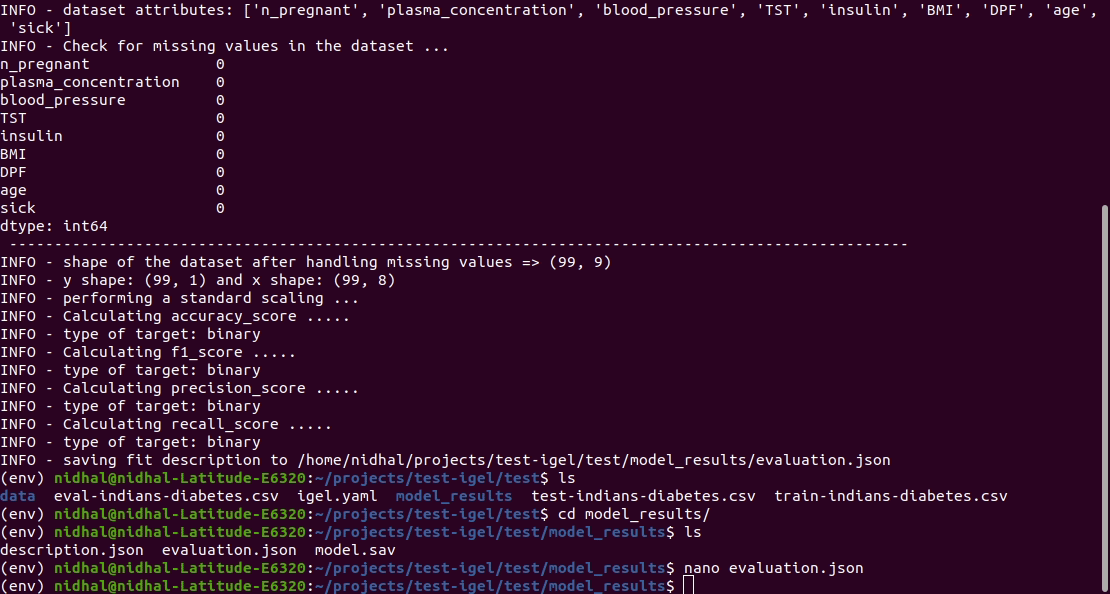
$ igel evaluate -dp ' path_to_your_evaluation_dataset.csv '
"""
This will automatically generate an evaluation.json file in the current directory, where all evaluation results are stored
"""
마지막으로, 평가 결과에 만족하면 훈련된/사전 맞춤된 모델을 사용하여 예측할 수 있습니다.
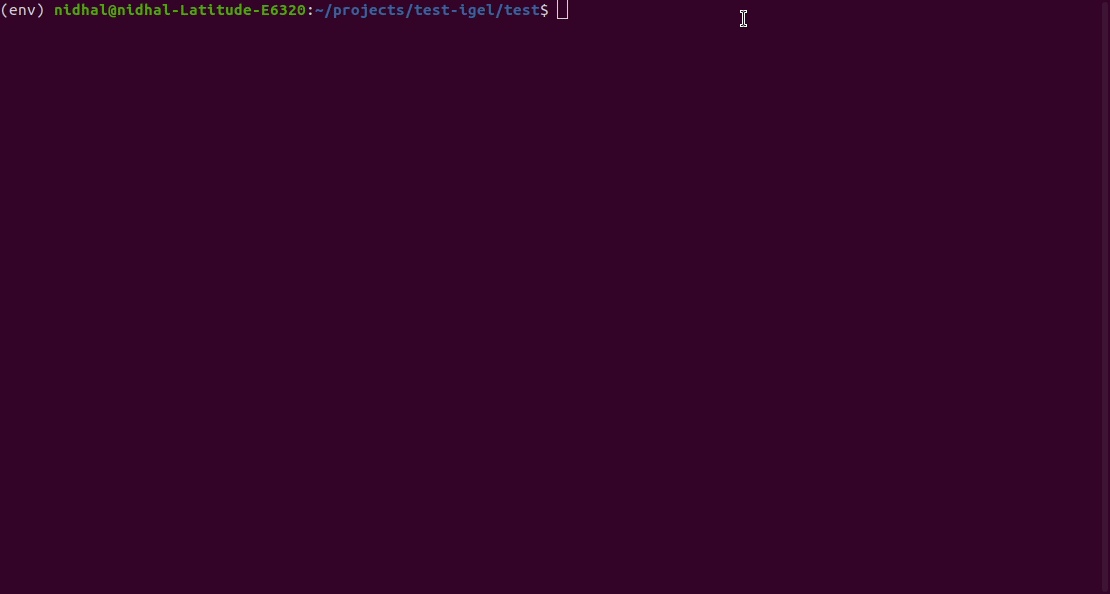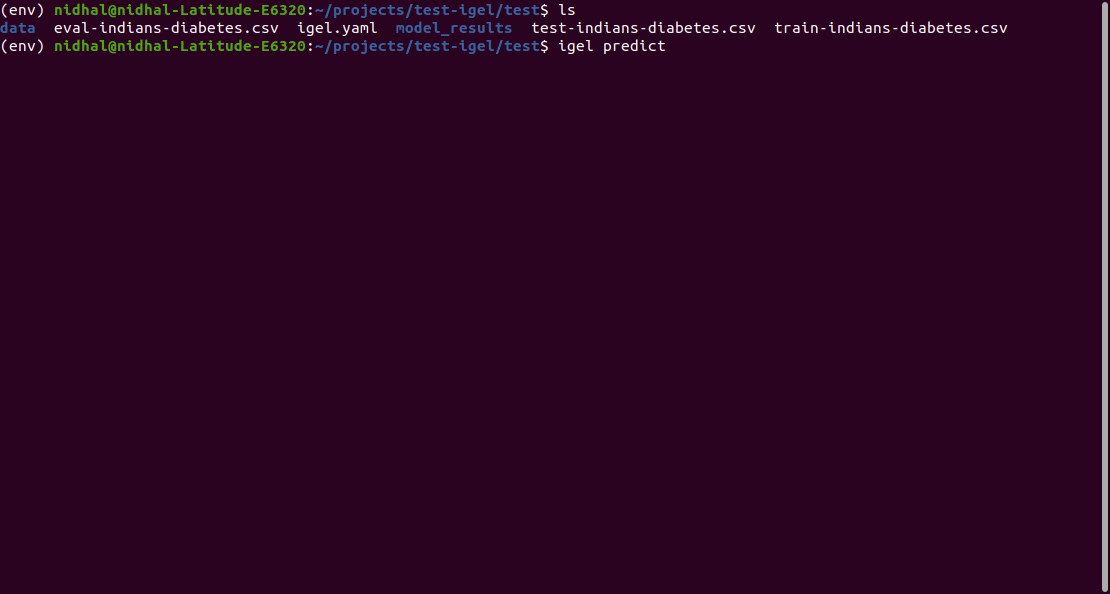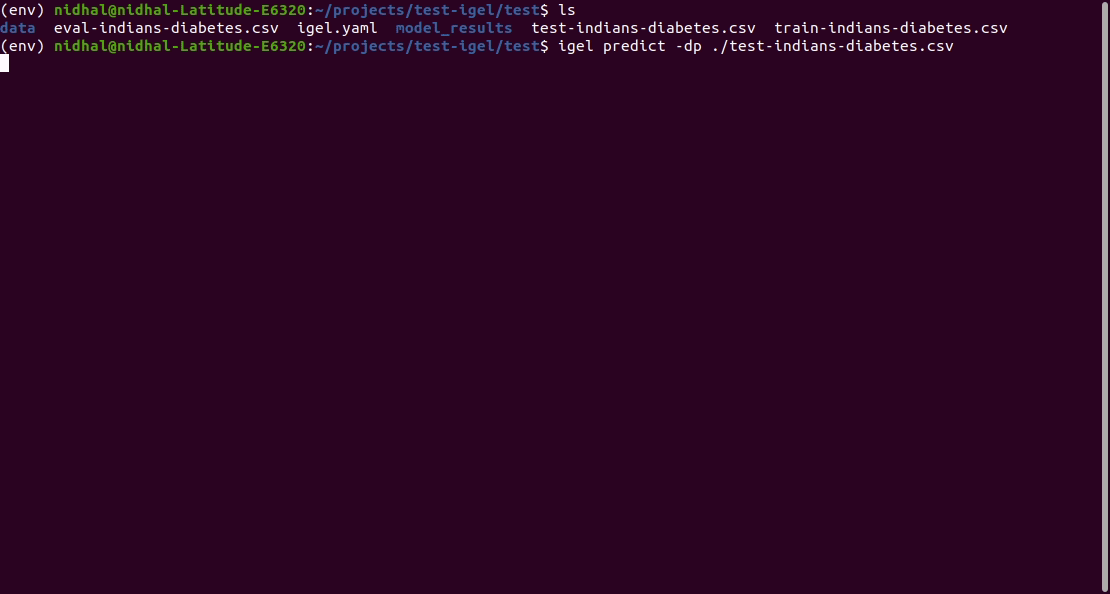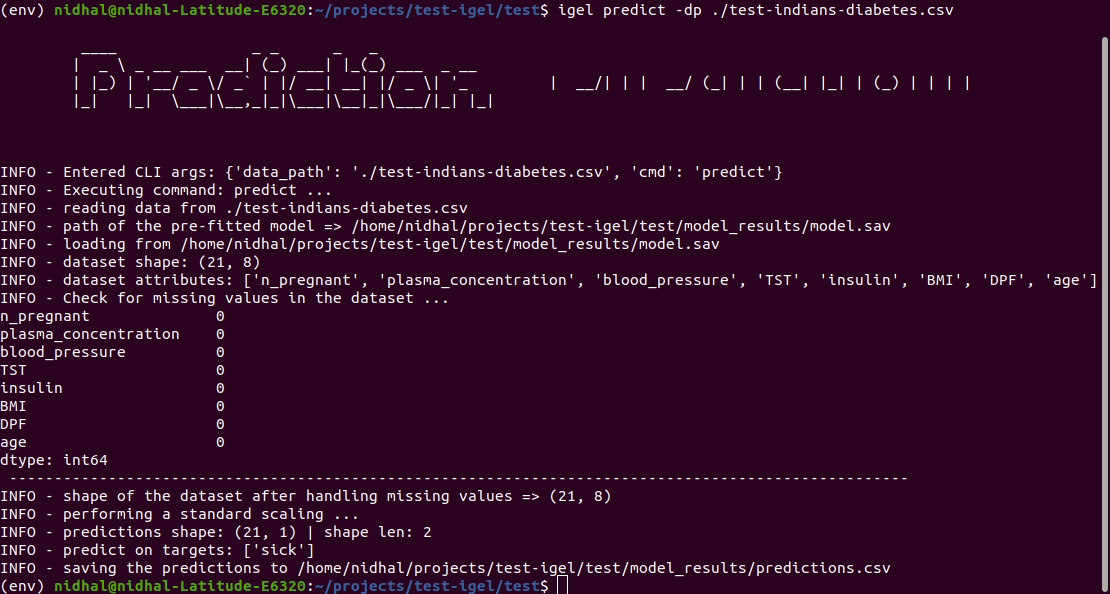
$ igel predict -dp ' path_to_your_test_dataset.csv '
"""
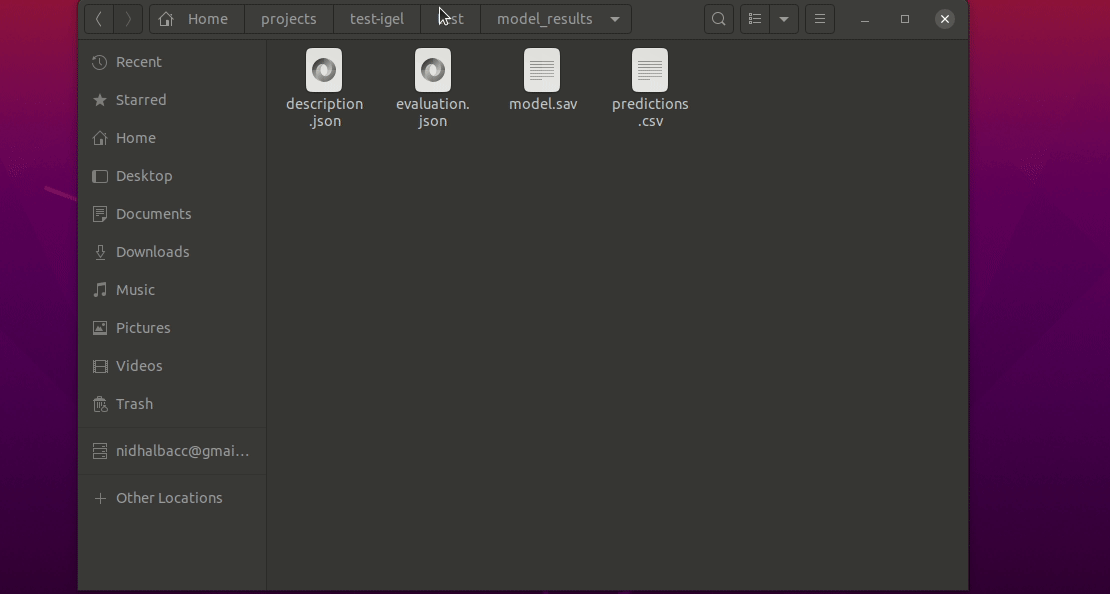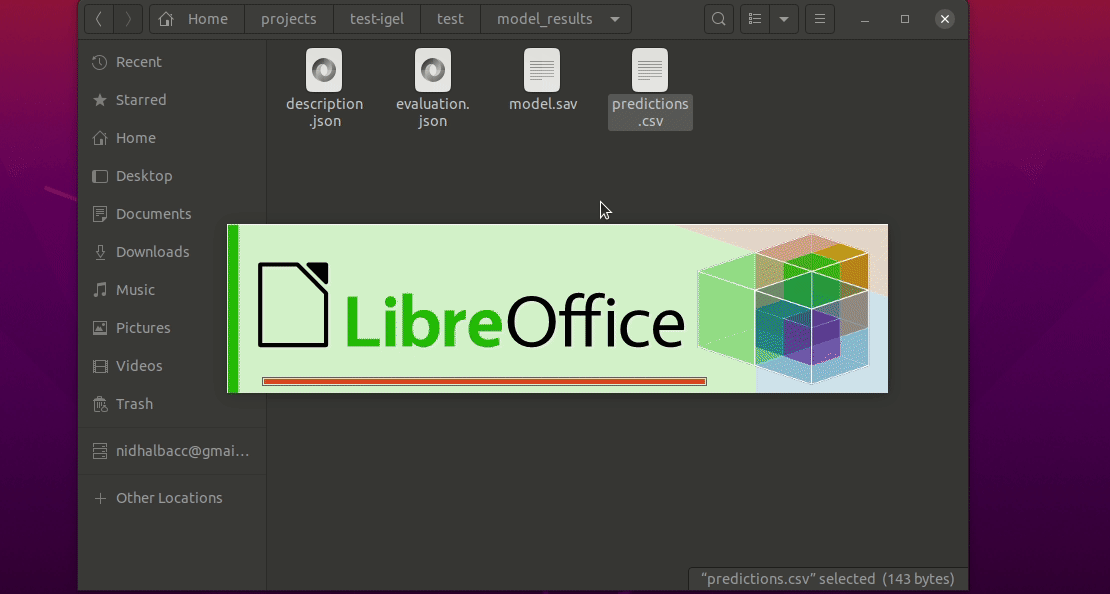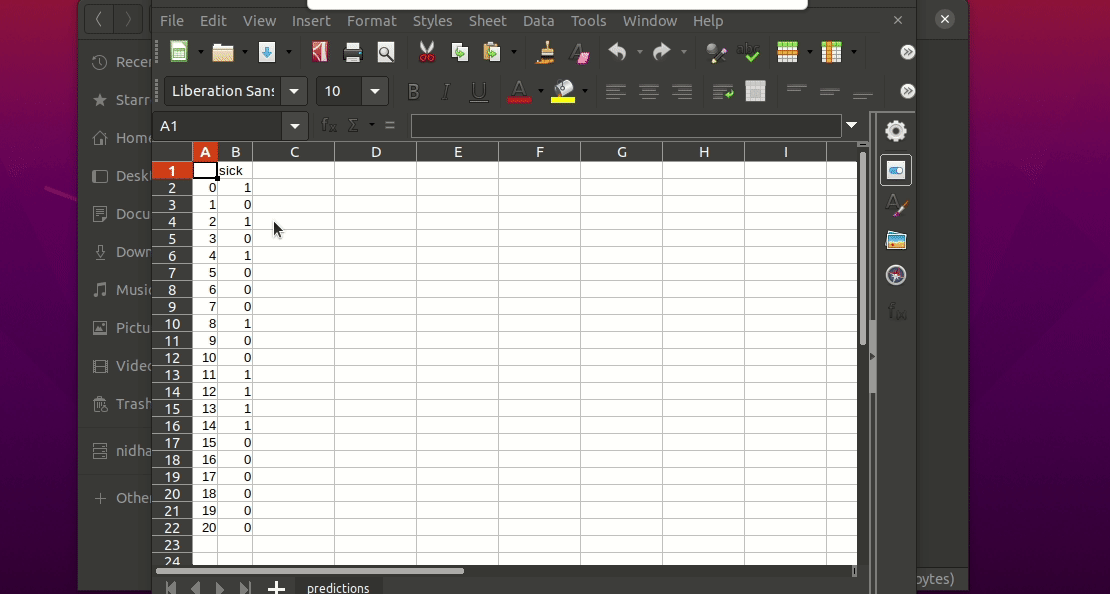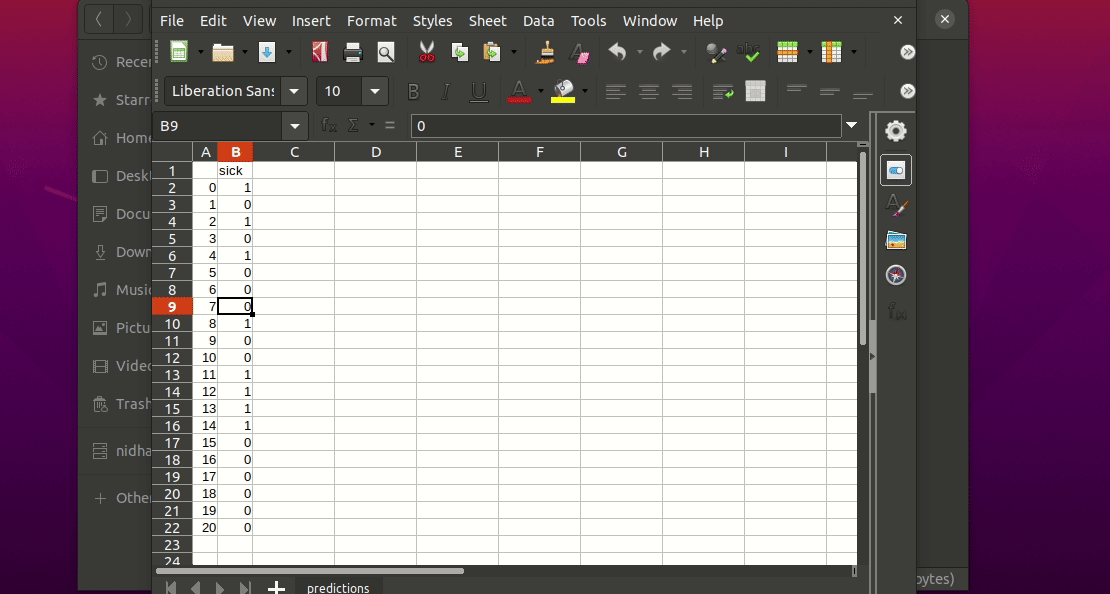
This will generate a predictions.csv file in your current directory, where all predictions are stored in a csv file
"""
실험이라는 단일 명령을 사용하여 학습, 평가 및 예측 단계를 결합할 수 있습니다.
$ igel experiment -DP " path_to_train_data path_to_eval_data path_to_test_data " -yml " path_to_yaml_file "
"""
This will run fit using train_data, evaluate using eval_data and further generate predictions using the test_data
"""
훈련된/사전 장착된 sklearn 모델을 ONNX로 내보낼 수 있습니다.
$ igel export -dp " path_to_pre-fitted_sklearn_model "
"""
This will convert the sklearn model into ONNX
""" from igel import Igel
Igel ( cmd = "fit" , data_path = "path_to_your_dataset" , yaml_path = "path_to_your_yaml_file" )
"""
check the examples folder for more
"""다음 단계는 프로덕션에서 모델을 사용하는 것입니다. Igel은 서브 명령을 제공하여 이 작업에도 도움을 줍니다. Serve 명령을 실행하면 igel이 모델을 서비스하도록 지시합니다. 정확하게 말하면 igel은 자동으로 REST 서버를 구축하고 특정 호스트 및 포트에서 모델을 제공하며 이를 cli 옵션으로 전달하여 구성할 수 있습니다.
가장 쉬운 방법은 다음을 실행하는 것입니다.
$ igel serve --model_results_dir " path_to_model_results_directory "모델을 로드하고 서버를 시작하려면 igel에 --model_results_dir 또는 곧 -res_dir cli 옵션이 필요합니다. 기본적으로 igel은 localhost:8000 에서 모델을 제공하지만 호스트 및 포트 cli 옵션을 제공하여 이를 쉽게 재정의할 수 있습니다.
$ igel serve --model_results_dir " path_to_model_results_directory " --host " 127.0.0.1 " --port 8000Igel은 FastAPI를 사용하여 최신 고성능 프레임워크인 REST 서버를 생성하고 uvicorn을 사용하여 이를 실행합니다.
이 예시는 사전 훈련된 모델(igel init --target sick -type 분류를 실행하여 생성됨)과 예시/데이터 아래의 인도 당뇨병 데이터 세트를 사용하여 수행되었습니다. 원본 CSV의 열 헤더는 'preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi' 및 'age'입니다.
컬:
$ curl -X POST localhost:8080/predict --header " Content-Type:application/json " -d ' {"preg": 1, "plas": 180, "pres": 50, "skin": 12, "test": 1, "mass": 456, "pedi": 0.442, "age": 50} '
Outputs: {"prediction":[[0.0]]}$ curl -X POST localhost:8080/predict --header " Content-Type:application/json " -d ' {"preg": [1, 6, 10], "plas":[192, 52, 180], "pres": [40, 30, 50], "skin": [25, 35, 12], "test": [0, 1, 1], "mass": [456, 123, 155], "pedi": [0.442, 0.22, 0.19], "age": [50, 40, 29]} '
Outputs: {"prediction":[[1.0],[0.0],[0.0]]}주의사항/제한사항:
Python 클라이언트 사용 예:
from python_client import IgelClient
# the client allows additional args with defaults:
# scheme="http", endpoint="predict", missing_values="mean"
client = IgelClient ( host = 'localhost' , port = 8080 )
# you can post other types of files compatible with what Igel data reading allows
client . post ( "my_batch_file_for_predicting.csv" )
Outputs : < Response 200 > : { "prediction" :[[ 1.0 ],[ 0.0 ],[ 0.0 ]]}igel의 주요 목표는 코드를 작성하지 않고도 모델을 훈련/맞춤, 평가 및 사용할 수 있는 방법을 제공하는 것입니다. 대신, 간단한 yaml 파일에서 수행하려는 작업을 제공/설명하는 것뿐입니다.
기본적으로 yaml 파일에 설명이나 구성을 키 값 쌍으로 제공합니다. 다음은 현재 지원되는 모든 구성에 대한 개요입니다.
# dataset operations
dataset :
type : csv # [str] -> type of your dataset
read_data_options : # options you want to supply for reading your data (See the detailed overview about this in the next section)
sep : # [str] -> Delimiter to use.
delimiter : # [str] -> Alias for sep.
header : # [int, list of int] -> Row number(s) to use as the column names, and the start of the data.
names : # [list] -> List of column names to use
index_col : # [int, str, list of int, list of str, False] -> Column(s) to use as the row labels of the DataFrame,
usecols : # [list, callable] -> Return a subset of the columns
squeeze : # [bool] -> If the parsed data only contains one column then return a Series.
prefix : # [str] -> Prefix to add to column numbers when no header, e.g. ‘X’ for X0, X1, …
mangle_dupe_cols : # [bool] -> Duplicate columns will be specified as ‘X’, ‘X.1’, …’X.N’, rather than ‘X’…’X’. Passing in False will cause data to be overwritten if there are duplicate names in the columns.
dtype : # [Type name, dict maping column name to type] -> Data type for data or columns
engine : # [str] -> Parser engine to use. The C engine is faster while the python engine is currently more feature-complete.
converters : # [dict] -> Dict of functions for converting values in certain columns. Keys can either be integers or column labels.
true_values : # [list] -> Values to consider as True.
false_values : # [list] -> Values to consider as False.
skipinitialspace : # [bool] -> Skip spaces after delimiter.
skiprows : # [list-like] -> Line numbers to skip (0-indexed) or number of lines to skip (int) at the start of the file.
skipfooter : # [int] -> Number of lines at bottom of file to skip
nrows : # [int] -> Number of rows of file to read. Useful for reading pieces of large files.
na_values : # [scalar, str, list, dict] -> Additional strings to recognize as NA/NaN.
keep_default_na : # [bool] -> Whether or not to include the default NaN values when parsing the data.
na_filter : # [bool] -> Detect missing value markers (empty strings and the value of na_values). In data without any NAs, passing na_filter=False can improve the performance of reading a large file.
verbose : # [bool] -> Indicate number of NA values placed in non-numeric columns.
skip_blank_lines : # [bool] -> If True, skip over blank lines rather than interpreting as NaN values.
parse_dates : # [bool, list of int, list of str, list of lists, dict] -> try parsing the dates
infer_datetime_format : # [bool] -> If True and parse_dates is enabled, pandas will attempt to infer the format of the datetime strings in the columns, and if it can be inferred, switch to a faster method of parsing them.
keep_date_col : # [bool] -> If True and parse_dates specifies combining multiple columns then keep the original columns.
dayfirst : # [bool] -> DD/MM format dates, international and European format.
cache_dates : # [bool] -> If True, use a cache of unique, converted dates to apply the datetime conversion.
thousands : # [str] -> the thousands operator
decimal : # [str] -> Character to recognize as decimal point (e.g. use ‘,’ for European data).
lineterminator : # [str] -> Character to break file into lines.
escapechar : # [str] -> One-character string used to escape other characters.
comment : # [str] -> Indicates remainder of line should not be parsed. If found at the beginning of a line, the line will be ignored altogether. This parameter must be a single character.
encoding : # [str] -> Encoding to use for UTF when reading/writing (ex. ‘utf-8’).
dialect : # [str, csv.Dialect] -> If provided, this parameter will override values (default or not) for the following parameters: delimiter, doublequote, escapechar, skipinitialspace, quotechar, and quoting
delim_whitespace : # [bool] -> Specifies whether or not whitespace (e.g. ' ' or ' ') will be used as the sep
low_memory : # [bool] -> Internally process the file in chunks, resulting in lower memory use while parsing, but possibly mixed type inference.
memory_map : # [bool] -> If a filepath is provided for filepath_or_buffer, map the file object directly onto memory and access the data directly from there. Using this option can improve performance because there is no longer any I/O overhead.
random_numbers : # random numbers options in case you wanted to generate the same random numbers on each run
generate_reproducible : # [bool] -> set this to true to generate reproducible results
seed : # [int] -> the seed number is optional. A seed will be set up for you if you didn't provide any
split : # split options
test_size : 0.2 # [float] -> 0.2 means 20% for the test data, so 80% are automatically for training
shuffle : true # [bool] -> whether to shuffle the data before/while splitting
stratify : None # [list, None] -> If not None, data is split in a stratified fashion, using this as the class labels.
preprocess : # preprocessing options
missing_values : mean # [str] -> other possible values: [drop, median, most_frequent, constant] check the docs for more
encoding :
type : oneHotEncoding # [str] -> other possible values: [labelEncoding]
scale : # scaling options
method : standard # [str] -> standardization will scale values to have a 0 mean and 1 standard deviation | you can also try minmax
target : inputs # [str] -> scale inputs. | other possible values: [outputs, all] # if you choose all then all values in the dataset will be scaled
# model definition
model :
type : classification # [str] -> type of the problem you want to solve. | possible values: [regression, classification, clustering]
algorithm : NeuralNetwork # [str (notice the pascal case)] -> which algorithm you want to use. | type igel algorithms in the Terminal to know more
arguments : # model arguments: you can check the available arguments for each model by running igel help in your terminal
use_cv_estimator : false # [bool] -> if this is true, the CV class of the specific model will be used if it is supported
cross_validate :
cv : # [int] -> number of kfold (default 5)
n_jobs : # [signed int] -> The number of CPUs to use to do the computation (default None)
verbose : # [int] -> The verbosity level. (default 0)
hyperparameter_search :
method : grid_search # method you want to use: grid_search and random_search are supported
parameter_grid : # put your parameters grid here that you want to use, an example is provided below
param1 : [val1, val2]
param2 : [val1, val2]
arguments : # additional arguments you want to provide for the hyperparameter search
cv : 5 # number of folds
refit : true # whether to refit the model after the search
return_train_score : false # whether to return the train score
verbose : 0 # verbosity level
# target you want to predict
target : # list of strings: basically put here the column(s), you want to predict that exist in your csv dataset
- put the target you want to predict here
- you can assign many target if you are making a multioutput prediction 메모
igel은 내부적으로 팬더를 사용하여 데이터를 읽고 구문 분석합니다. 따라서 Pandas 공식 문서에서도 이 데이터 선택적 매개변수를 찾을 수 있습니다.
yaml(또는 json) 파일에 제공할 수 있는 구성에 대한 자세한 개요는 아래에 나와 있습니다. 데이터 세트에 대한 모든 구성 값이 반드시 필요한 것은 아닙니다. 선택 사항입니다. 일반적으로 igel은 데이터 세트를 읽는 방법을 알아냅니다.
그러나 이 read_data_options 섹션을 사용하여 추가 필드를 제공하면 도움이 될 수 있습니다. 예를 들어, 내 생각에 유용한 값 중 하나는 csv 데이터 세트의 열이 구분되는 방식을 정의하는 "sep"입니다. 일반적으로 csv 데이터세트는 쉼표로 구분되며, 이는 여기에서도 기본값입니다. 그러나 귀하의 경우에는 세미콜론으로 구분될 수 있습니다.
따라서 read_data_options에서 이를 제공할 수 있습니다. sep: ";" 만 추가하면 됩니다. read_data_options 아래에 있습니다.
| 매개변수 | 유형 | 설명 |
|---|---|---|
| 9월 | 문자열, 기본값 ',' | 사용할 구분 기호입니다. sep가 None이면 C 엔진은 자동으로 구분 기호를 감지할 수 없지만 Python 구문 분석 엔진은 가능합니다. 즉, Python의 내장 스니퍼 도구인 csv.Sniffer가 자동으로 구분 기호를 감지합니다. 또한 1자보다 길고 's+'와 다른 구분 기호는 정규식으로 해석되며 Python 구문 분석 엔진을 강제로 사용하게 됩니다. 정규식 구분 기호는 인용된 데이터를 무시하는 경향이 있습니다. 정규식 예: 'rt'. |
| 구분 기호 | 기본값 없음 | sep.의 별칭 |
| 헤더 | int, int 목록, 기본값 '추론' | 열 이름으로 사용할 행 번호와 데이터의 시작입니다. 기본 동작은 열 이름을 유추하는 것입니다. 이름이 전달되지 않으면 동작은 header=0과 동일하고 열 이름은 파일의 첫 번째 줄에서 유추됩니다. 열 이름이 명시적으로 전달되면 동작은 header=None과 동일합니다. . 기존 이름을 대체할 수 있도록 header=0을 명시적으로 전달합니다. 헤더는 열의 다중 인덱스에 대한 행 위치를 지정하는 정수 목록일 수 있습니다(예: [0,1,3]). 지정되지 않은 중간 행은 건너뜁니다(예: 이 예에서는 2행을 건너뜁니다). Skip_blank_lines=True인 경우 이 매개변수는 주석 처리된 행과 빈 행을 무시하므로 header=0은 파일의 첫 번째 행이 아닌 데이터의 첫 번째 행을 나타냅니다. |
| 이름 | 배열과 유사, 선택 사항 | 사용할 열 이름 목록입니다. 파일에 헤더 행이 포함된 경우 명시적으로 header=0을 전달하여 열 이름을 재정의해야 합니다. 이 목록의 중복은 허용되지 않습니다. |
| index_col | int, str, int / str의 시퀀스 또는 False, 기본값 없음 | 문자열 이름 또는 열 인덱스로 제공되는 DataFrame의 행 레이블로 사용할 열입니다. int / str 시퀀스가 제공되면 MultiIndex가 사용됩니다. 참고: index_col=False를 사용하면 팬더가 첫 번째 열을 인덱스로 사용하지 않도록 강제할 수 있습니다. 예를 들어 각 줄 끝에 구분 기호가 있는 잘못된 형식의 파일이 있는 경우입니다. |
| 사용 콜 | 목록형 또는 호출 가능, 선택 사항 | 열의 하위 집합을 반환합니다. 목록형인 경우 모든 요소는 위치(즉, 문서 열에 대한 정수 인덱스)이거나 사용자가 이름으로 제공했거나 문서 헤더 행에서 유추한 열 이름에 해당하는 문자열이어야 합니다. 예를 들어, 유효한 목록형 usecols 매개변수는 [0, 1, 2] 또는 ['foo', 'bar', 'baz']입니다. 요소 순서는 무시되므로 usecols=[0, 1]은 [1, 0]과 동일합니다. 요소 순서가 보존된 데이터에서 DataFrame을 인스턴스화하려면 ['foo', 'bar의 열에 대해 pd.read_csv(data, usecols=['foo', 'bar'])[['foo', 'bar']]를 사용하십시오. '] 주문 또는 ['bar', 'foo'] 주문의 경우 pd.read_csv(data, usecols=['foo', 'bar'])[['bar', 'foo']]. 호출 가능한 경우 호출 가능한 함수는 열 이름에 대해 평가되어 호출 가능한 함수가 True로 평가되는 이름을 반환합니다. 유효한 호출 가능 인수의 예는 ['AAA', 'BBB', 'DDD']의 람다 x: x.upper()입니다. 이 매개변수를 사용하면 구문 분석 시간이 훨씬 빨라지고 메모리 사용량이 줄어듭니다. |
| 짜내다 | bool, 기본값은 False | 구문 분석된 데이터에 하나의 열만 포함된 경우 Series를 반환합니다. |
| 접두사 | 문자열, 선택 사항 | 헤더가 없을 때 열 번호에 추가할 접두사(예: X0, X1, …의 경우 'X') |
| mangle_dupe_cols | bool, 기본값은 True | 중복 열은 'X'…'X'가 아닌 'X', 'X.1', …'X.N'으로 지정됩니다. False를 전달하면 열에 중복된 이름이 있는 경우 데이터를 덮어쓰게 됩니다. |
| dtype | {'c', 'python'}, 선택 사항 | 사용할 파서 엔진. C 엔진은 더 빠르고 Python 엔진은 현재 기능이 더 완벽합니다. |
| 변환기 | 사전, 선택사항 | 특정 열의 값을 변환하는 함수의 사전입니다. 키는 정수이거나 열 레이블일 수 있습니다. |
| true_values | 목록, 선택사항 | True로 간주할 값입니다. |
| false_values | 목록, 선택사항 | False로 간주할 값입니다. |
| 초기 공간 건너뛰기 | bool, 기본값은 False | 구분 기호 뒤의 공백을 건너뜁니다. |
| 건너뛰기 | 목록형, int 또는 호출 가능, 선택 사항 | 파일 시작 부분에서 건너뛸 줄 번호(0부터 인덱스) 또는 건너뛸 줄 수(int)입니다. 호출 가능한 경우 호출 가능한 함수는 행 인덱스에 대해 평가되며 행을 건너뛰어야 하면 True를 반환하고 그렇지 않으면 False를 반환합니다. 유효한 호출 가능 인수의 예는 람다 x: x in [0, 2]입니다. |
| 건너뛰기 바닥글 | 정수, 기본값 0 | 건너뛸 파일 하단의 줄 수(엔진='c'에서는 지원되지 않음) |
| 으르렁거리다 | 정수, 선택 사항 | 읽을 파일의 행 수입니다. 대용량 파일을 읽는 데 유용합니다. |
| na_values | 스칼라, str, 유사 목록 또는 dict, 선택 사항 | NA/NaN으로 인식할 추가 문자열입니다. dict가 전달된 경우 특정 열별 NA 값입니다. 기본적으로 '', '#N/A', '#N/AN/A', '#NA', '-1.#IND', '-1.#QNAN' 값은 NaN으로 해석됩니다. '-NaN', '-nan', '1.#IND', '1.#QNAN', '<NA>', 'N/A', 'NA', 'NULL', 'NaN', 'n /a', '난', '널'. |
| keep_default_na | bool, 기본값은 True | 데이터를 구문 분석할 때 기본 NaN 값을 포함할지 여부입니다. na_values가 전달되었는지 여부에 따라 동작은 다음과 같습니다. keep_default_na가 True이고 na_values가 지정되면 na_values가 구문 분석에 사용되는 기본 NaN 값에 추가됩니다. keep_default_na가 True이고 na_values가 지정되지 않은 경우 기본 NaN 값만 구문 분석에 사용됩니다. keep_default_na가 False이고 na_values가 지정된 경우 na_values에 지정된 NaN 값만 구문 분석에 사용됩니다. keep_default_na가 False이고 na_values가 지정되지 않은 경우 어떤 문자열도 NaN으로 구문 분석되지 않습니다. na_filter가 False로 전달되면 keep_default_na 및 na_values 매개변수가 무시됩니다. |
| na_filter | bool, 기본값은 True | 누락된 값 표시(빈 문자열 및 na_values 값)를 감지합니다. NA가 없는 데이터에서 na_filter=False를 전달하면 대용량 파일 읽기 성능이 향상될 수 있습니다. |
| 말 수가 많은 | bool, 기본값은 False | 숫자가 아닌 열에 배치된 NA 값의 수를 나타냅니다. |
| Skip_blank_lines | bool, 기본값은 True | True인 경우 NaN 값으로 해석하지 않고 빈 줄을 건너뜁니다. |
| 구문 분석 날짜 | bool 또는 int 목록 또는 이름 또는 목록 목록 또는 dict, 기본값 False | 동작은 다음과 같습니다: 부울. True인 경우 -> 인덱스 구문 분석을 시도합니다. int 또는 이름 목록. 예를 들어 [1, 2, 3]인 경우 -> 열 1, 2, 3을 각각 별도의 날짜 열로 구문 분석해 보세요. 목록의 목록. 예를 들어 [[1, 3]] -> 열 1과 3을 결합하고 단일 날짜 열로 구문 분석하는 경우. dict, 예: {'foo' : [1, 3]} -> 열 1, 3을 날짜로 구문 분석하고 결과 'foo'를 호출합니다. 열이나 인덱스를 날짜/시간 배열로 표현할 수 없는 경우, 예를 들어 구문 분석할 수 없는 값 또는 시간대가 혼합된 경우 열 또는 인덱스는 변경되지 않은 객체 데이터 유형으로 반환됩니다. |
| infer_datetime_format | bool, 기본값은 False | True 및 parse_dates가 활성화된 경우 pandas는 열의 날짜/시간 문자열 형식을 유추하려고 시도하고, 유추할 수 있는 경우 더 빠른 구문 분석 방법으로 전환합니다. 경우에 따라 구문 분석 속도가 5~10배 증가할 수 있습니다. |
| keep_date_col | bool, 기본값 False | True이고 구문 분석 날짜가 여러 열 결합을 지정하는 경우 원래 열을 유지합니다. |
| 날짜_파서 | 기능, 선택사항 | 일련의 문자열 열을 날짜/시간 인스턴스의 배열로 변환하는 데 사용하는 함수입니다. 기본값은 dateutil.parser.parser를 사용하여 변환을 수행합니다. Pandas는 세 가지 다른 방법으로 date_parser를 호출하려고 시도하며 예외가 발생하면 다음 단계로 진행합니다. 1) 하나 이상의 배열(parse_dates에서 정의한 대로)을 인수로 전달합니다. 2) pars_dates에 의해 정의된 열의 문자열 값을 단일 배열로 연결(행 단위)하고 이를 전달합니다. 3) 하나 이상의 문자열(parse_dates에 의해 정의된 열에 해당)을 인수로 사용하여 각 행에 대해 date_parser를 한 번씩 호출합니다. |
| 첫날 | bool, 기본값은 False | DD/MM 형식 날짜, 국제 및 유럽 형식. |
| 캐시_날짜 | bool, 기본값은 True | True인 경우 고유한 변환 날짜 캐시를 사용하여 날짜/시간 변환을 적용합니다. 중복 날짜 문자열, 특히 시간대 오프셋이 있는 문자열을 구문 분석할 때 속도가 크게 향상될 수 있습니다. |
| 수천 | 문자열, 선택 사항 | 천 단위 구분 기호입니다. |
| 소수 | str, 기본값 '.' | 소수점으로 인식할 문자입니다(예: 유럽 데이터의 경우 ',' 사용). |
| 라인터미네이터 | str(길이 1), 선택 사항 | 파일을 여러 줄로 나누는 문자입니다. C 파서에서만 유효합니다. |
| escapechar | str(길이 1), 선택 사항 | 다른 문자를 이스케이프하는 데 사용되는 1문자 문자열입니다. |
| 논평 | 문자열, 선택 사항 | 나머지 줄을 구문 분석하지 않아야 함을 나타냅니다. 줄의 시작 부분에서 발견되면 해당 줄은 모두 무시됩니다. |
| 부호화 | 문자열, 선택 사항 | 읽기/쓰기 시 UTF에 사용할 인코딩입니다(예: 'utf-8'). |
| 방언 | str 또는 csv.Dialect, 선택 사항 | 제공되는 경우 이 매개변수는 구분 기호, 큰따옴표, escapechar, Skipinitialspace, quotechar 및 인용 매개변수의 값(기본값 여부)을 재정의합니다. |
| 메모리 부족 | bool, 기본값은 True | 내부적으로 파일을 청크로 처리하여 구문 분석하는 동안 메모리 사용량이 줄어들지만 혼합 유형 추론이 발생할 수 있습니다. 혼합 유형이 없도록 하려면 False를 설정하거나 dtype 매개변수를 사용하여 유형을 지정하십시오. 전체 파일은 관계없이 단일 DataFrame으로 읽혀집니다. |
| 메모리_맵 | bool, 기본값은 False | 파일 객체를 메모리에 직접 매핑하고 거기에서 직접 데이터에 액세스합니다. 이 옵션을 사용하면 더 이상 I/O 오버헤드가 없으므로 성능이 향상될 수 있습니다. |
이 섹션에서는 igel 의 기능을 입증하기 위해 완전한 엔드투엔드 솔루션이 제공됩니다. 앞서 설명한 대로 yaml 구성 파일을 생성해야 합니다. 다음은 의사결정 트리 알고리즘을 사용하여 누군가 당뇨병에 걸렸는지 여부를 예측하는 엔드투엔드 예입니다. 데이터 세트는 예제 폴더에서 찾을 수 있습니다.
model :
type : classification
algorithm : DecisionTree
target :
- sick $ igel fit -dp path_to_the_dataset -yml path_to_the_yaml_file이제 igel이 모델을 피팅하고 이를 현재 디렉터리의 model_results 폴더에 저장합니다.
사전 피팅된 모델을 평가합니다. Igel은 model_results 디렉터리에서 사전 맞춤된 모델을 로드하고 평가합니다. 평가 명령을 실행하고 평가 데이터에 대한 경로를 제공하기만 하면 됩니다.
$ igel evaluate -dp path_to_the_evaluation_dataset그게 다야! Igel은 모델을 평가하고 model_results 폴더 내의 Evaluation.json 파일에 통계/결과를 저장합니다.
사전 피팅된 모델을 사용하여 새 데이터를 예측합니다. 이는 igel에 의해 자동으로 수행되므로 예측을 사용하려는 데이터에 대한 경로를 제공하기만 하면 됩니다.
$ igel predict -dp path_to_the_new_dataset그게 다야! Igel은 사전 맞춤된 모델을 사용하여 예측을 수행하고 이를 model_results 폴더 내의 Predictions.csv 파일에 저장합니다.
yaml 파일에 제공하여 일부 전처리 방법이나 기타 작업을 수행할 수도 있습니다. 다음은 데이터가 훈련용으로 80%, 검증/테스트용으로 20%로 분할되는 예입니다. 또한 분할하는 동안 데이터가 섞입니다.
또한 누락된 값을 평균으로 대체하여 데이터를 전처리합니다(중앙값, 모드 등을 사용할 수도 있음). 자세한 내용은 이 링크를 확인하세요.
# dataset operations
dataset :
split :
test_size : 0.2
shuffle : True
stratify : default
preprocess : # preprocessing options
missing_values : mean # other possible values: [drop, median, most_frequent, constant] check the docs for more
encoding :
type : oneHotEncoding # other possible values: [labelEncoding]
scale : # scaling options
method : standard # standardization will scale values to have a 0 mean and 1 standard deviation | you can also try minmax
target : inputs # scale inputs. | other possible values: [outputs, all] # if you choose all then all values in the dataset will be scaled
# model definition
model :
type : classification
algorithm : RandomForest
arguments :
# notice that this is the available args for the random forest model. check different available args for all supported models by running igel help
n_estimators : 100
max_depth : 20
# target you want to predict
target :
- sick그런 다음 다른 예제에 표시된 대로 igel 명령을 실행하여 모델을 맞출 수 있습니다.
$ igel fit -dp path_to_the_dataset -yml path_to_the_yaml_file평가를 위해
$ igel evaluate -dp path_to_the_evaluation_dataset생산용
$ igel predict -dp path_to_the_new_dataset 저장소의 예제 폴더에는 유명한 인도 당뇨병, 홍채 데이터 세트 및 linnerud(sklearn의) 데이터 세트가 저장되어 있는 데이터 폴더가 있습니다. 또한 각 폴더에는 시작하는 데 도움이 되는 스크립트와 yaml 파일이 있는 엔드투엔드 예제가 있습니다.
indian-diabetes-example 폴더에는 시작하는 데 도움이 되는 두 가지 예가 포함되어 있습니다.
iris-example 폴더에는 igel의 기능을 더 많이 보여주기 위해 대상 열에서 일부 전처리(1개의 핫 인코딩)가 수행되는 로지스틱 회귀 예제가 포함되어 있습니다.
또한 다중 출력 예제에는 다중 출력 회귀 예제가 포함되어 있습니다. 마지막으로 cv-example에는 교차 검증을 사용하는 Ridge 분류기를 사용하는 예제가 포함되어 있습니다.
폴더에서 교차 검증 및 하이퍼파라미터 검색 예시도 찾을 수 있습니다.
예제와 igel cli를 가지고 놀아 보는 것이 좋습니다. 그러나 원하는 경우 fit.py, 평가.py 및 예측.py를 직접 실행할 수도 있습니다.
먼저, 이미지 라벨/클래스에 따라 하위 폴더로 분류된 이미지 데이터 세트를 생성하거나 수정합니다. 예를 들어 개와 고양이 이미지가 있는 경우 2개의 하위 폴더가 필요합니다.
이 두 하위 폴더가 이미지라는 하나의 상위 폴더에 포함되어 있다고 가정하면 igel에 데이터를 공급하면 됩니다.
$ igel auto-train -dp ./images --task ImageClassificationIgel은 데이터 전처리부터 하이퍼파라미터 최적화까지 모든 작업을 처리합니다. 결국 가장 좋은 모델이 현재 작업 디렉토리에 저장됩니다.
먼저, 텍스트 레이블/클래스에 따라 하위 폴더로 분류되는 텍스트 데이터 세트를 생성하거나 수정합니다. 예를 들어 긍정적 피드백과 부정적인 피드백의 텍스트 데이터 세트가 있는 경우 2개의 하위 폴더가 필요합니다.
이 두 하위 폴더가 texts라는 하나의 상위 폴더에 포함되어 있다고 가정하면 igel에 데이터를 공급하면 됩니다.
$ igel auto-train -dp ./texts --task TextClassificationIgel은 데이터 전처리부터 하이퍼파라미터 최적화까지 모든 작업을 처리합니다. 결국 가장 좋은 모델이 현재 작업 디렉토리에 저장됩니다.
터미널에 익숙하지 않은 경우 igel UI를 실행할 수도 있습니다. 위에서 언급한 대로 컴퓨터에 igel을 설치하면 됩니다. 그런 다음 터미널에서 이 단일 명령을 실행하십시오.
$ igel gui그러면 사용하기 매우 간단한 GUI가 열립니다. GUI의 모양과 사용 방법에 대한 예를 여기에서 확인하세요: https://github.com/nidhaloff/igel-ui
docker 허브에서 먼저 이미지를 가져올 수 있습니다.
$ docker pull nidhaloff/igel그런 다음 사용하십시오.
$ docker run -it --rm -v $( pwd ) :/data nidhaloff/igel fit -yml ' your_file.yaml ' -dp ' your_dataset.csv '먼저 이미지를 빌드하여 docker 내에서 igel을 실행할 수 있습니다.
$ docker build -t igel .그런 다음 이를 실행하고 컨테이너 내부의 /data(workdir)로 현재 디렉터리(igel 디렉터리일 필요는 없음)를 연결합니다.
$ docker run -it --rm -v $( pwd ) :/data igel fit -yml ' your_file.yaml ' -dp ' your_dataset.csv ' 문제가 발생하면 언제든지 문제를 열어주세요. 또한 추가 정보/질문이 있는 경우 작성자에게 연락할 수 있습니다.
이겔 좋아하시나요? 귀하는 언제든지 다음을 통해 이 프로젝트의 개발을 도울 수 있습니다.
이 프로젝트가 유용하다고 생각하며 새로운 아이디어, 새로운 기능, 버그 수정을 가져오고 문서를 확장하고 싶습니까?
기여는 언제나 환영합니다. 먼저 지침을 읽어보세요.
MIT 라이센스
저작권 (c) 2020-현재, Nidhal Baccouri


