awesome mojo
1.0.0

Mojo — 모든 개발자, AI/ML 과학자 및 소프트웨어 엔지니어를 위한 새로운 프로그래밍 언어입니다.
멋진 Mojo 코드, 문제 해결, 솔루션 및 향후 라이브러리, 프레임워크, 소프트웨어 및 리소스의 선별된 목록입니다.
여기에 아주 새로운 기술 지식과 모범 사례를 축적해 봅시다.
Mojo는 Python의 사용자 친화성과 C++ 및 Rust의 성능 기능을 결합한 프로그래밍 언어입니다. 또한 Mojo를 통해 사용자는 Python 라이브러리의 광범위한 생태계를 활용할 수 있습니다.
간략하게
Mojo는 최고의 Python 구문과 시스템 프로그래밍 및 메타 프로그래밍을 결합하여 연구와 생산 간의 격차를 해소하는 새로운 프로그래밍 언어입니다.
hello.mojo 또는 hello. 파일 확장자는 이모티콘이 될 수 있습니다!
Modular가 이 작업을 수행하는 이유에 대해 자세히 읽을 수 있습니다. Mojo가 필요한 이유
우리가 원했던 것은 AI 분야에 널리 퍼져 있는 가속기 및 기타 이기종 시스템을 대상으로 할 수 있는 혁신적이고 확장 가능한 프로그래밍 모델이었습니다. ... 응용 AI 시스템은 이러한 모든 문제를 해결해야 하며, 단 하나의 언어만으로 이를 수행하지 못할 이유가 없다고 판단했습니다. 그리하여 모조가 탄생했습니다.
하지만 Python은 그 일을 아주 잘 해냈습니다 =)
우리는 언어 구문이나 커뮤니티를 혁신할 필요가 없다고 생각했습니다. 그래서 우리는 Python 생태계가 매우 널리 사용되고, AI 생태계에서 사랑받고, 정말 좋은 언어라고 믿기 때문에 Python 생태계를 채택하기로 결정했습니다.
모조(Mojo)는 '마법의 매력' 또는 '마법의 힘'을 의미합니다. 우리는 이것이 오늘날 AI에 널리 퍼져 있는 가속기 및 기타 이기종 시스템을 위한 혁신적인 프로그래밍 모델을 잠금 해제하는 것을 포함하여 Python :python:에 마법의 힘을 제공하는 언어에 적합한 이름이라고 생각했습니다.
Guido van Rossum 자비로운 종신 독재자이자 Christopher Arthur Lattner 의 저명한 발명가이자 창시자이며 Mojo발음에 관한 유명한 지도자 =)
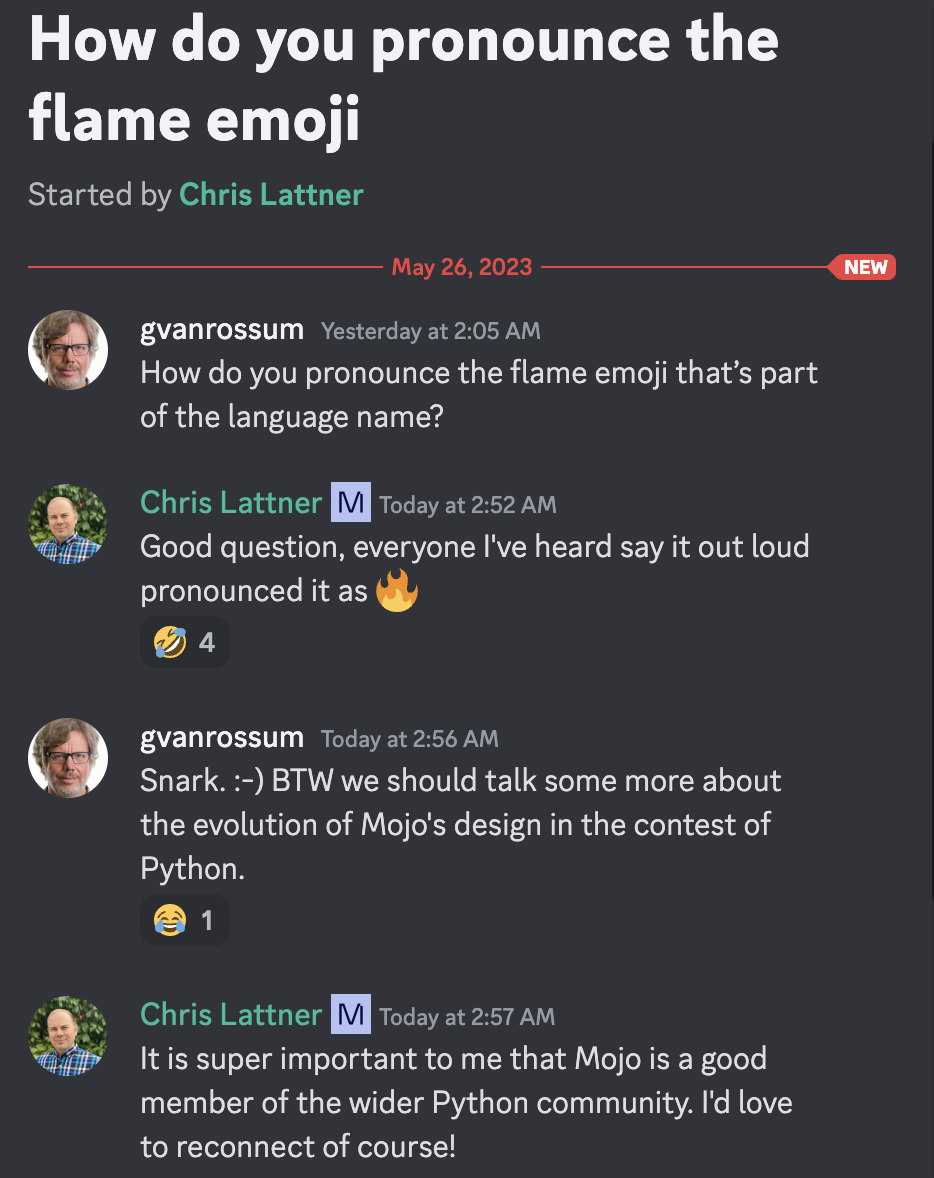
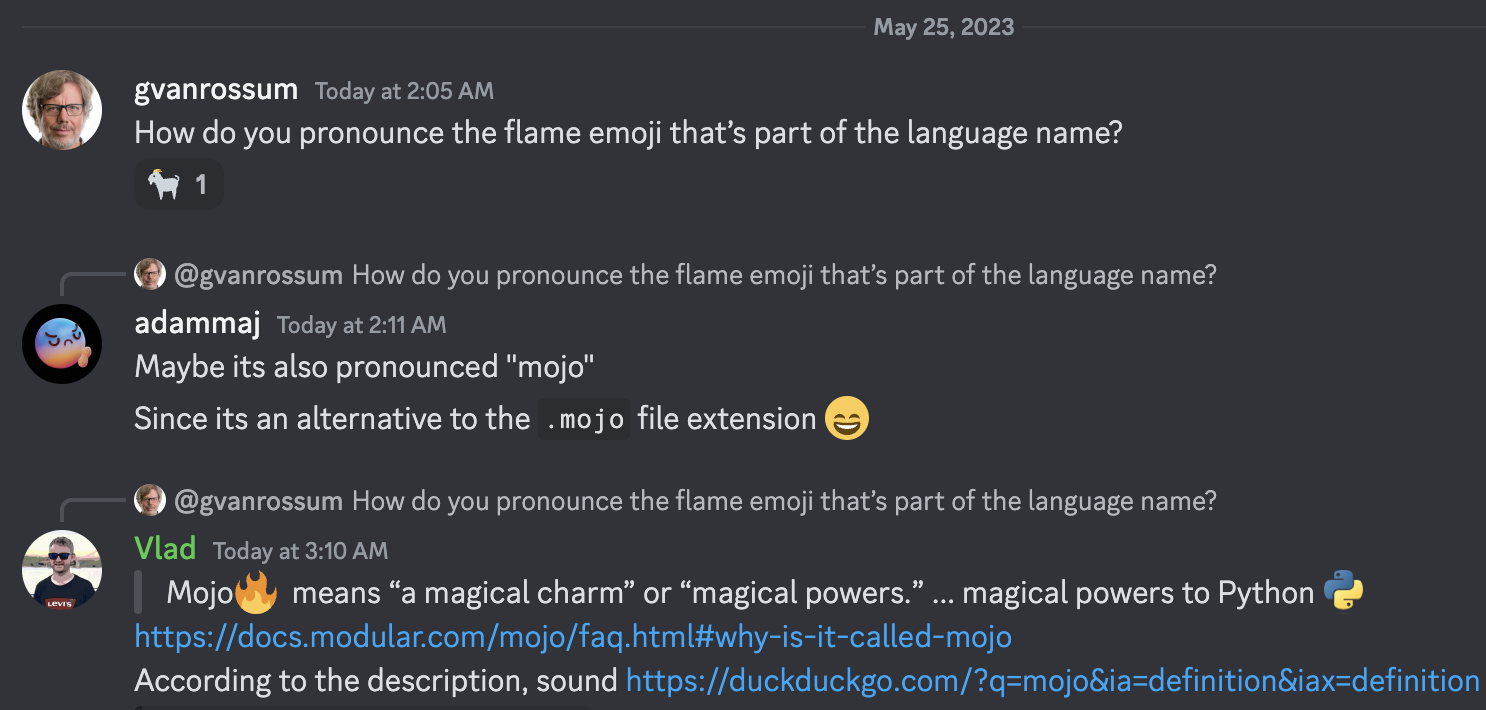
설명에 따르면
Mojo가 Rust, Swift, Julia, Zig, Nim 등의 다른 언어에서 배운 엄청난 교훈을 활용하기 때문에 이러한 프로그래밍 언어가 매우 만족스러울 것이라는 것을 누가 알겠습니까?
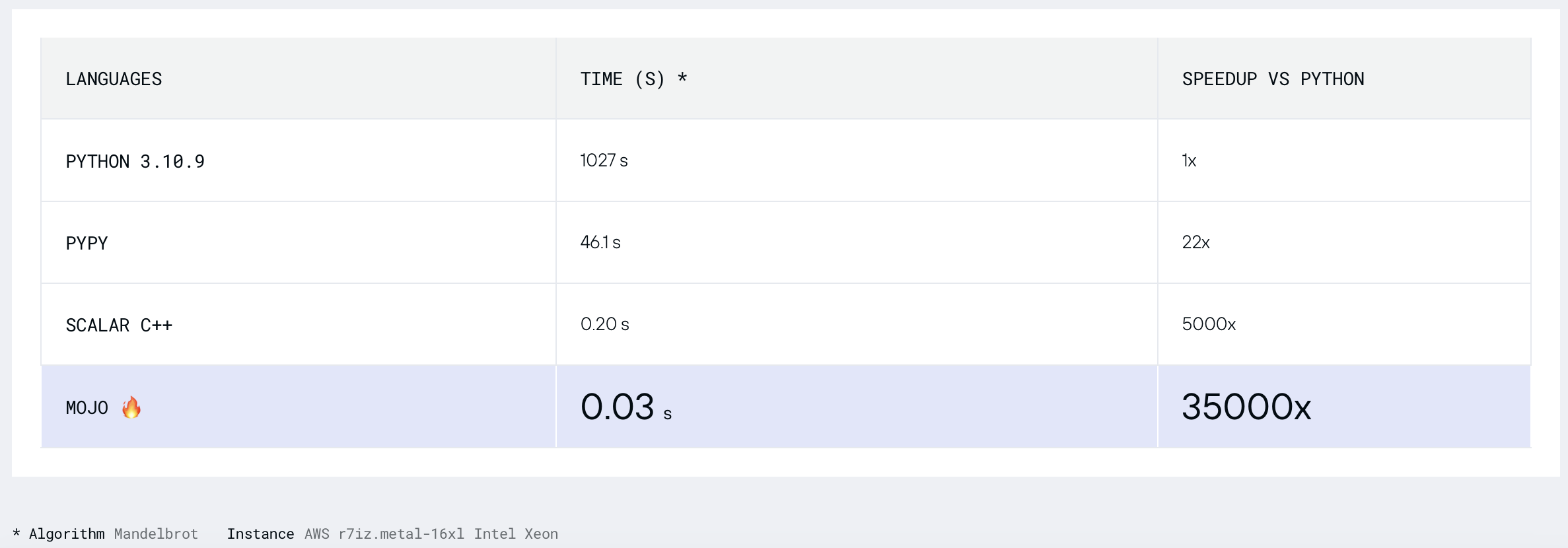
[새로운]
Github는 이제 Mojo 코드를 자동 감지합니다!
Mojo를 위한 간단하고 빠른 HTTP 프레임워크! 웹 서비스 및 간단한 API 구축에 적합합니다. 모히시안을 위한
LLama 구현 벤치마킹 프레임워크
자동화된 Python에서 Mojo 코드로 변환
프로그래밍 언어 데이터베이스 연구
2023년 10월 19일 이제 Mac에서 Mojo를 사용할 수 있습니다! 개발자 콘솔 사용
Chris Lattner: 프로그래밍과 AI의 미래 | 렉스 프리드먼 팟캐스트 #381
Mojo 및 Python 유형 시스템 설명 | 크리스 래트너와 렉스 프리드먼
Mojo는 Python 코드를 실행할 수 있나요? | 크리스 래트너와 렉스 프리드먼
Python에서 Mojo 프로그래밍 언어로 전환 | 크리스 래트너와 렉스 프리드먼
새로운 GitHub 주제 mojo-lang. 그러니 따라하시면 됩니다.
Mojo = C++/GPU 성능을 갖춘 Python에 대한 Guido van Rossum?
몇 가지 기본 작업이 포함된 Tensor 구조체 #251
numpy #267을 사용한 행렬 fn
Mojo #244의 lambda 및 parameter 클로저 및 상위 순서 함수에 대한 업데이트
2023년 5월 25일, Python의 창시자이자 명예 BDFL인 Guido van Rossum(gvanrossum#8415)이 Mojo 공개 Discord 채팅을 방문합니다.
GitHub에서 Mojo 구문 강조 표시를 기다리는 중
새로운 Mojo릴리스 2023-05-24
[오래된]
모조
brew install hyperfinebrew install macchinapip3 install numpy matplotlib scipybrew install silicon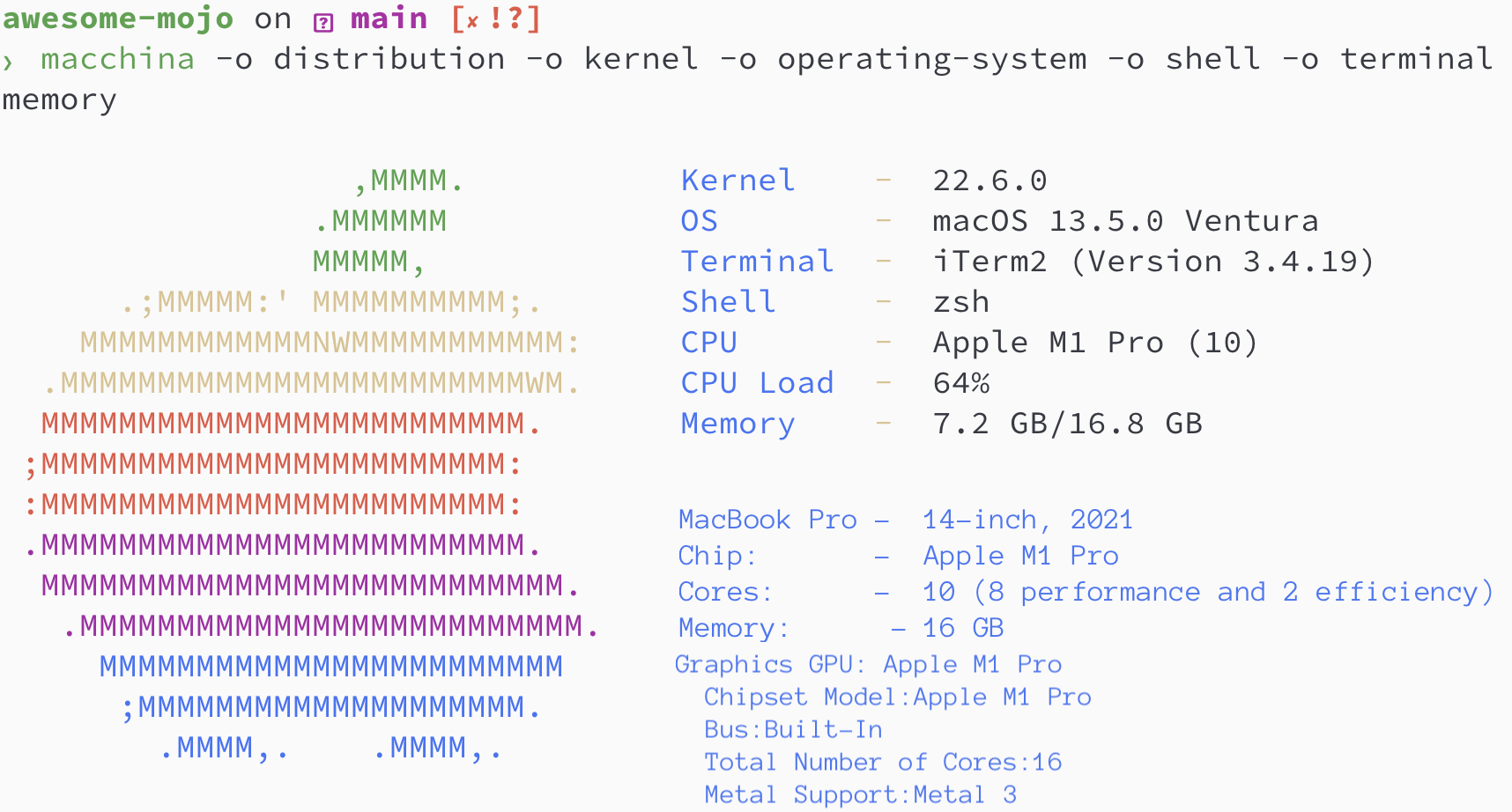
Python / Mojo / Codon / Rust 버전
> python3 --version
Python 3.11.6
> mojo --version
mojo 0.4.0 (9e33b013)
> codon --version
0.16.3
> rustc --version
rustc 1.65.0-nightly (9243168fa 2022-08-31)피보나치 수열을 찾아봅시다.
N = 100
def fibonacci_recursion ( n ):
return n if n < 2 else fibonacci_recursion ( n - 1 ) + fibonacci_recursion ( n - 2 )
fibonacci_recursion ( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json python_recursion.json ' python3 benchmarks/fibonacci_sequence/python_recursion.py '결과: TIMEOUT, 1분 후에 계산을 취소했습니다.
def fibonacci_iteration ( n ):
a , b = 0 , 1
for _ in range ( n ):
a , b = b , a + b
return a
fibonacci_iteration ( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_iteration.json ' python3 benchmarks/fibonacci_sequence/python_iteration.py ' 결과 :
벤치마크 1: python3 benchmarks/fibonacci_sequence/python_iteration.py
시간(평균 ± σ): 16374.7 µs ± 904.0 µs [사용자: 11483.5 µs, 시스템: 3680.0 µs]
범위(최소 ~ 최대): 15361.0 µs ~ 22863.3 µs 100회 실행
python3 -m compileall benchmarks/fibonacci_sequence/python_recursion.py
python3 -m compileall benchmarks/fibonacci_sequence/python_iteration.pyhyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_recursion.cpython-311.json ' python3 benchmarks/fibonacci_sequence/__pycache__/python_recursion.cpython-311.pyc '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_iteration.cpython-311.json ' python3 benchmarks/fibonacci_sequence/__pycache__/python_iteration.cpython-311.pyc ' 결과 :
벤치마크 1: python3 benchmarks/fibonacci_sequence/ pycache /python_iteration.cpython-311.pyc
시간(평균 ± σ): 16584.6 µs ± 761.5 µs [사용자: 11451.8 µs, 시스템: 3813.3 µs]
범위(최소 ~ 최대): 15592.0 µs ~ 20953.2 µs 100회 실행
fn fibonacci_recursion ( n : Int) -> Int:
return n if n < 2 else fibonacci_recursion(n - 1 ) + fibonacci_recursion(n - 2 )
fn main ():
_ = fibonacci_recursion( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_recursion.json ' mojo run benchmarks/fibonacci_sequence/mojo_recursion.mojo '결과: TIMEOUT, 1분 후에 계산을 취소했습니다.
fn fibonacci_iteration ( n : Int) -> Int:
var a : Int = 0
var b : Int = 1
for _ in range (n):
a = b
b = a + b
return a
fn main ():
_ = fibonacci_iteration( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_iteration.json ' mojo run benchmarks/fibonacci_sequence/mojo_iteration.mojo ' 결과 :
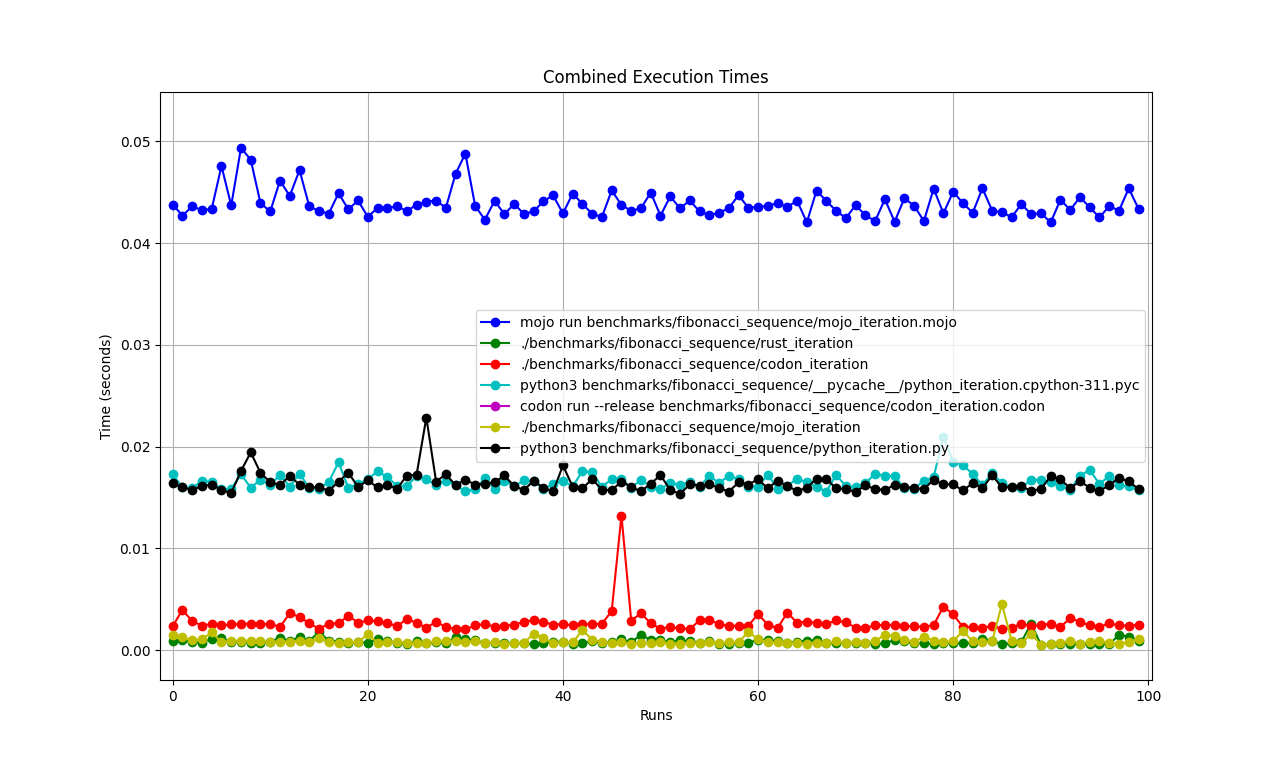
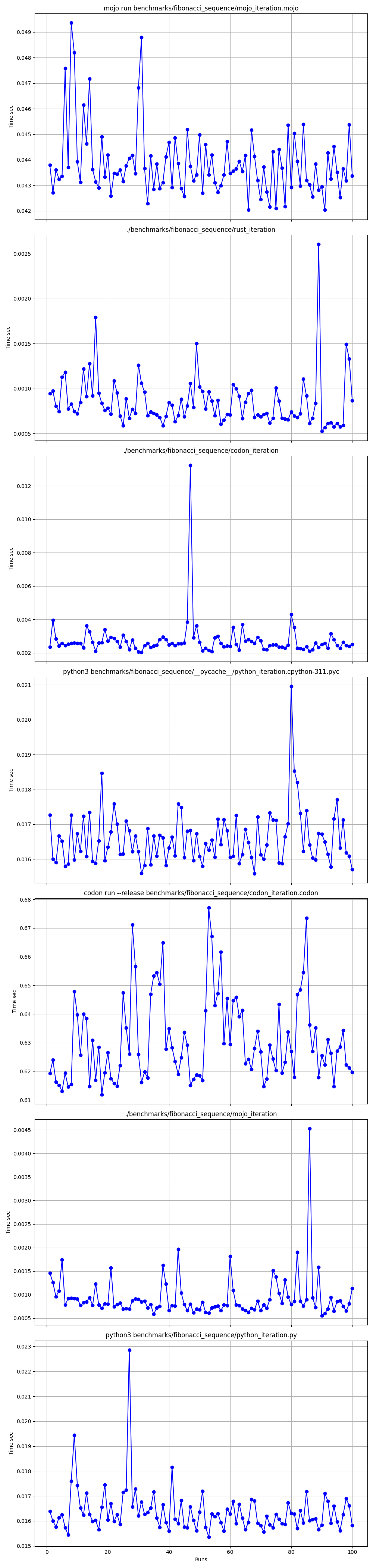
벤치마크 1: mojo 실행 benchmarks/fibonacci_sequence/mojo_iteration.mojo
시간(평균 ± σ): 43852.7 µs ± 1353.5 µs [사용자: 38156.0 µs, 시스템: 10407.3 µs]
범위(최소 ~ 최대): 42033.6 µs ~ 49357.3 µs 100회 실행
mojo build benchmarks/fibonacci_sequence/mojo_recursion.mojo
mojo build benchmarks/fibonacci_sequence/mojo_iteration.mojohyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_recursion.exe.json ' ./benchmarks/fibonacci_sequence/mojo_recursion '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_iteration.exe.json ' ./benchmarks/fibonacci_sequence/mojo_iteration ' 결과 :
벤치마크 1: ./benchmarks/fibonacci_sequence/mojo_iteration
시간(평균 ± σ): 934.6 µs ± 468.9 µs [사용자: 409.8 µs, 시스템: 247.8 µs]
범위(최소 ~ 최대): 552.7 µs ~ 4522.9 µs 100회 실행
def fibonacci_recursion(n):
return n if n < 2 else fibonacci_recursion(n - 1) + fibonacci_recursion(n - 2)
fibonacci_recursion(100)
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_recursion.json ' codon run --release benchmarks/fibonacci_sequence/codon_recursion.codon '결과: TIMEOUT, 1분 후에 계산을 취소했습니다.
def fibonacci_iteration(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a+b
return a
fibonacci_iteration(100)
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_iteration.json ' codon run --release benchmarks/fibonacci_sequence/codon_iteration.codon ' 결과 :
벤치마크 1: codon run --release benchmarks/fibonacci_sequence/codon_iteration.codon
시간(평균 ± σ): 628060.1 µs ± 10430.5 µs [사용자: 584524.3 µs, 시스템: 39358.5 µs]
범위(최소 ~ 최대): 612742.5 µs ~ 662716.9 µs 100회 실행
codon build --release -exe benchmarks/fibonacci_sequence/codon_recursion.codon
codon build --release -exe benchmarks/fibonacci_sequence/codon_iteration.codonhyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json codon_recursion.exe.json ' ./benchmarks/fibonacci_sequence/codon_recursion '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_iteration.exe.json ' ./benchmarks/fibonacci_sequence/codon_iteration ' 결과 :
벤치마크 1: ./benchmarks/fibonacci_sequence/codon_iteration
시간(평균 ± σ): 2732.7 µs ± 1145.5 µs [사용자: 1466.0 µs, 시스템: 1061.5 µs]
범위(최소 ~ 최대): 2036.6 µs ~ 13236.3 µs 100회 실행
fn fibonacci_recursive ( n : i64 ) -> i64 {
if n < 2 {
return n ;
}
return fibonacci_recursive ( n - 1 ) + fibonacci_recursive ( n - 2 ) ;
}
fn main ( ) {
let _ = fibonacci_recursive ( 100 ) ;
} rustc -C opt-level=3 benchmarks/fibonacci_sequence/rust_recursion.rs -o benchmarks/fibonacci_sequence/rust_recursion
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/rust_recursion.json ' ./benchmarks/fibonacci_sequence/rust_recursion '결과: TIMEOUT, 1분 후에 계산을 취소했습니다.
fn fibonacci_iteration ( n : usize ) -> usize {
let mut a = 1 ;
let mut b = 1 ;
for _ in 1 ..n {
let old = a ;
a = b ;
b += old ;
}
b
}
fn main ( ) {
let _ = fibonacci_iteration ( 100 ) ;
} rustc -C opt-level=3 benchmarks/fibonacci_sequence/rust_iteration.rs -o benchmarks/fibonacci_sequence/rust_iteration
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/rust_iteration.json ' ./benchmarks/fibonacci_sequence/rust_iteration ' 결과 :
벤치마크 1: ./benchmarks/fibonacci_sequence/rust_iteration
시간(평균 ± σ): 848.9 µs ± 283.2 µs [사용자: 371.8 µs, 시스템: 261.4 µs]
범위(최소 ~ 최대): 525.9 µs ~ 2607.3 µs 100회 실행
# Merge all JSON files into benchmarks.json
python3 benchmarks/hyperfine-scripts/merge_jsons.py benchmarks/fibonacci_sequence/ benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot2.py benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot3.py benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/advanced_statistics.py benchmarks/fibonacci_sequence/benchmarks.json > benchmarks/fibonacci_sequence/benchmarks.json.md
silicon benchmarks/fibonacci_sequence/benchmarks.json.md -l python -o benchmarks/fibonacci_sequence/benchmarks.json.md.png고급 통계
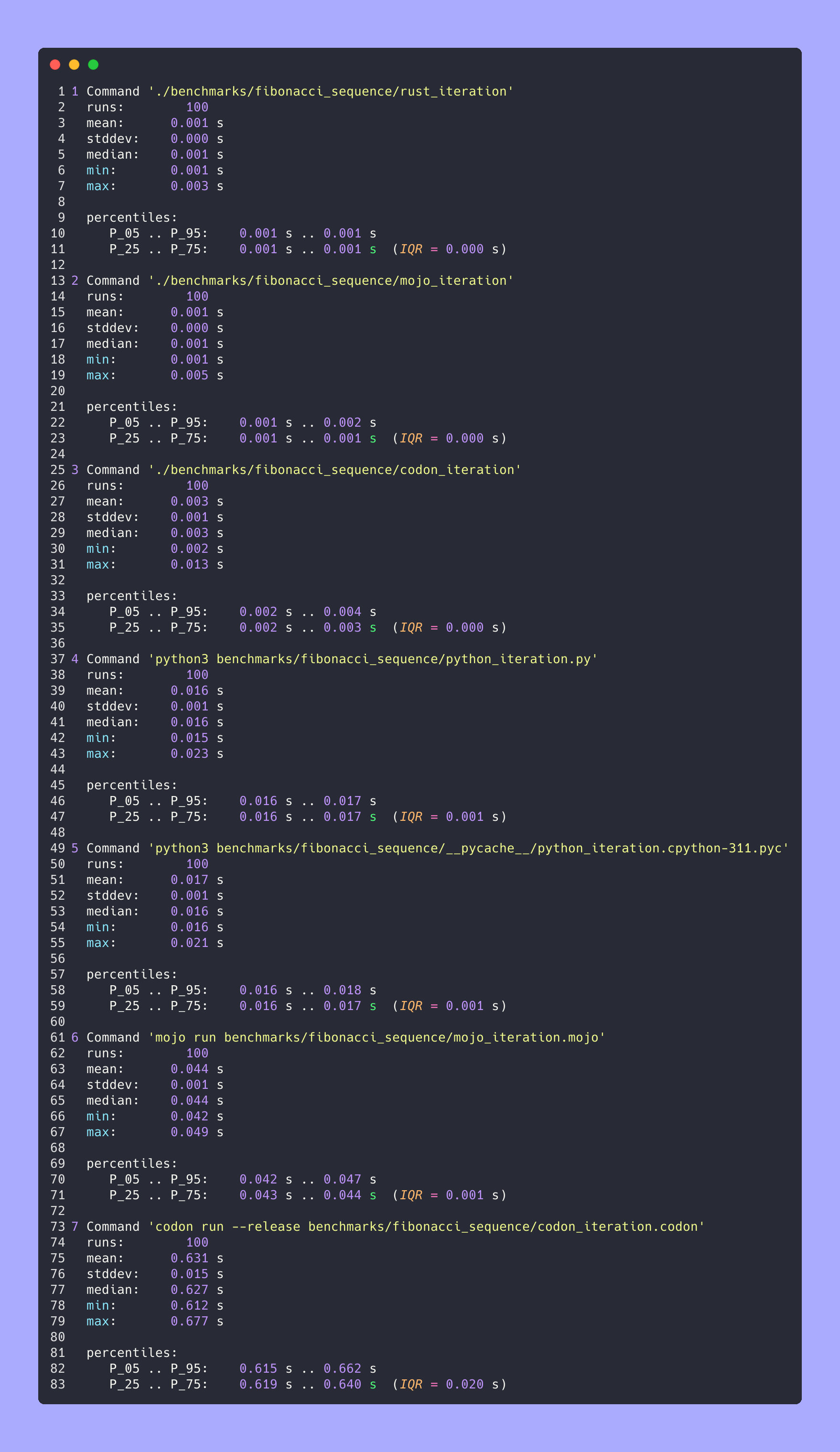
모두 함께
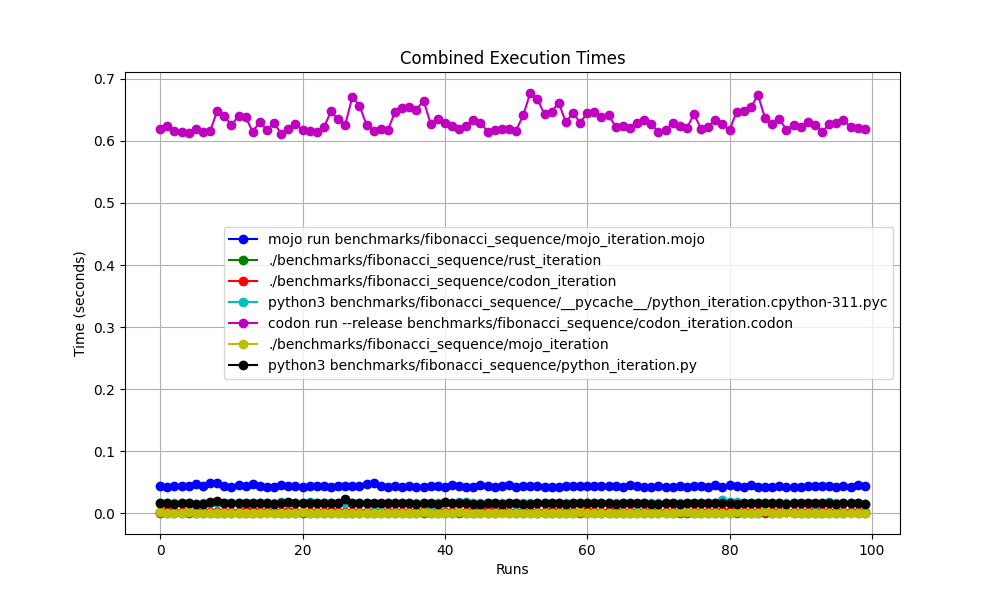
확대됨
하나씩 자세하게
장소
하지만 여기에는 많은 질문이 있습니다.
mojo run ?codon run --release 왜 그렇게 느린가요?run 보다 빠른 이유는 무엇입니까?따라서 Mojo는 Mac의 Rust만큼 빠르다고 말할 수 있습니다!
만델브로 집합을 찾아봅시다.
폭 = 960
높이 = 960
MAX_ITERS = 200
MIN_X = -2.0
MAX_X = 0.6
MIN_Y = -1.5
MAX_Y = 1.5
def mandelbrot_kernel ( c ):
z = c
for i in range ( MAX_ITERS ):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z . real * z . real + z . imag * z . imag > 4 :
return i
return MAX_ITERS
def compute_mandelbrot ():
t = [[ 0 for _ in range ( WIDTH )] for _ in range ( HEIGHT )] # Pixel matrix
dx = ( MAX_X - MIN_X ) / WIDTH
dy = ( MAX_Y - MIN_Y ) / HEIGHT
for row in range ( HEIGHT ):
for col in range ( WIDTH ):
t [ row ][ col ] = mandelbrot_kernel ( complex ( MIN_X + col * dx , MIN_Y + row * dy ))
return t
compute_mandelbrot ()python3 -m compileall benchmarks/multibrot_set/multibrot.py
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot.cpython-311.json ' python3 benchmarks/multibrot_set/__pycache__/multibrot.cpython-311.pyc ' 결과 :
벤치마크 1: python3 benchmarks/multibrot_set/ pycache /multibrot.cpython-311.pyc
시간(평균 ± σ): 5444155.4 µs ± 23059.7 µs [사용자: 5419790.1 µs, 시스템: 18131.3 µs]
범위(최소 ~ 최대): 5408155.3 µs ~ 5490548.4 µs 10회 실행
최적화가 없는 Mojo 버전입니다.
# Compute the number of steps to escape.
def multibrot_kernel ( c : ComplexFloat64) -> Int:
z = c
for i in range ( MAX_ITERS ):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z.squared_norm() > 4 :
return i
return MAX_ITERS
def compute_multibrot () -> Tensor[FloatType]:
# create a matrix. Each element of the matrix corresponds to a pixel
t = Tensor[FloatType]( HEIGHT , WIDTH )
dx = ( MAX_X - MIN_X ) / WIDTH
dy = ( MAX_Y - MIN_Y ) / HEIGHT
y = MIN_Y
for row in range ( HEIGHT ):
x = MIN_X
for col in range ( WIDTH ):
t[Index(row, col)] = multibrot_kernel(ComplexFloat64(x, y))
x += dx
y += dy
return t
_ = compute_multibrot()mojo build benchmarks/multibrot_set/multibrot.mojo
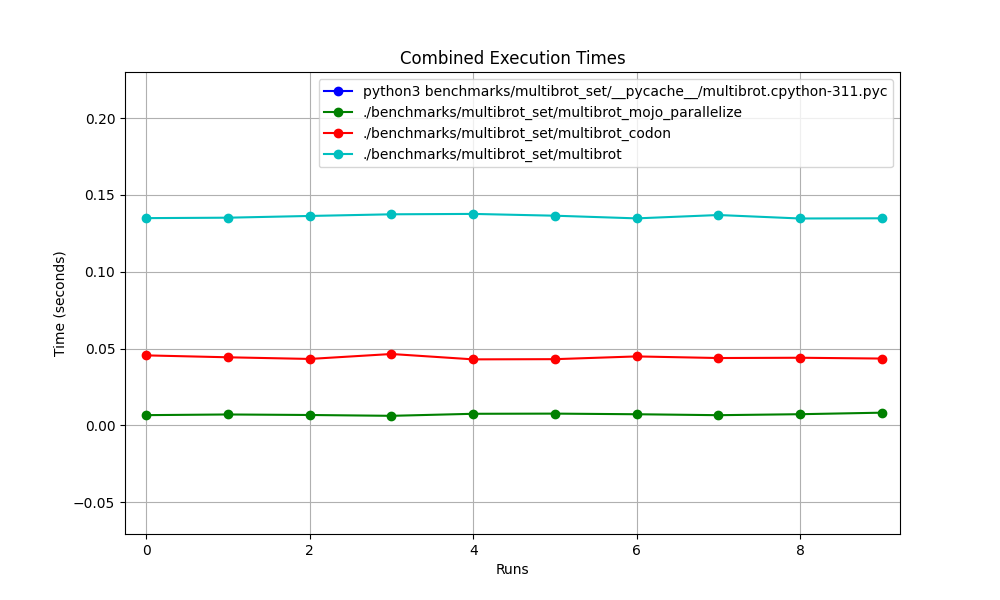
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot.exe.json ' ./benchmarks/multibrot_set/multibrot ' 결과 :
벤치마크 1: ./benchmarks/multibrot_set/multibrot
시간(평균 ± σ): 135880.5 µs ± 1175.4 µs [사용자: 133309.3 µs, 시스템: 1700.1 µs]
범위(최소 ~ 최대): 134639.9 µs ~ 137621.4 µs 10회 실행
fn mandelbrot_kernel_SIMD [
simd_width : Int
]( c : ComplexSIMD[float_type, simd_width]) -> SIMD [float_type, simd_width]:
""" A vectorized implementation of the inner mandelbrot computation. """
let cx = c.re
let cy = c.im
var x = SIMD [float_type, simd_width]( 0 )
var y = SIMD [float_type, simd_width]( 0 )
var y2 = SIMD [float_type, simd_width]( 0 )
var iters = SIMD [float_type, simd_width]( 0 )
var t : SIMD [DType.bool, simd_width] = True
for i in range ( MAX_ITERS ):
if not t.reduce_or():
break
y2 = y * y
y = x.fma(y + y, cy)
t = x.fma(x, y2) <= 4
x = x.fma(x, cx - y2)
iters = t.select(iters + 1 , iters)
return iters
fn compute_multibrot_parallelized () -> Tensor[float_type]:
let t = Tensor[float_type](height, width)
@parameter
fn worker ( row : Int):
let scale_x = (max_x - min_x) / width
let scale_y = (max_y - min_y) / height
@parameter
fn compute_vector [ simd_width : Int]( col : Int):
""" Each time we operate on a `simd_width` vector of pixels. """
let cx = min_x + (col + iota[float_type, simd_width]()) * scale_x
let cy = min_y + row * scale_y
let c = ComplexSIMD[float_type, simd_width](cx, cy)
t.data().simd_store[simd_width](
row * width + col, mandelbrot_kernel_SIMD[simd_width](c)
)
# Vectorize the call to compute_vector where call gets a chunk of pixels.
vectorize[simd_width, compute_vector](width)
# Parallelized
parallelize[worker](height, height)
return t
def main ():
_ = compute_multibrot_parallelized()mojo build benchmarks/multibrot_set/multibrot_mojo_parallelize.mojo
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_mojo_parallelize.exe.json ' ./benchmarks/multibrot_set/multibrot_mojo_parallelize ' 결과 :
벤치마크 1: ./benchmarks/multibrot_set/multibrot_mojo_parallelize
시간(평균 ± σ): 7139.4 µs ± 596.4 µs [사용자: 36535.2 µs, 시스템: 6670.1 µs]
범위(최소 ~ 최대): 6222.6 µs ~ 8269.7 µs 10회 실행
def mandelbrot_kernel(c):
z = c
for i in range(MAX_ITERS):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z.real * z.real + z.imag * z.imag > 4:
return i
return MAX_ITERS
def compute_mandelbrot():
t = [[0 for _ in range(WIDTH)] for _ in range(HEIGHT)] # Pixel matrix
dx = (MAX_X - MIN_X) / WIDTH
dy = (MAX_Y - MIN_Y) / HEIGHT
@par(collapse=2)
for row in range(HEIGHT):
for col in range(WIDTH):
t[row][col] = mandelbrot_kernel(complex(MIN_X + col * dx, MIN_Y + row * dy))
return t
compute_mandelbrot()
테스트 실행 또는 플롯의 경우(파일에서 코드 주석 처리 해제)
CODON_PYTHON=/opt/homebrew/opt/[email protected]/Frameworks/Python.framework/Versions/3.11/lib/libpython3.11.dylib codon run --release benchmarks/multibrot_set/multibrot.codon빌드 및 실행
codon build --release -exe benchmarks/multibrot_set/multibrot.codon -o benchmarks/multibrot_set/multibrot_codon
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_codon.json ' ./benchmarks/multibrot_set/multibrot_codon ' 결과 :
벤치마크 1: ./benchmarks/multibrot_set/multibrot_codon
시간(평균 ± σ): 44184.7 µs ± 1142.0 µs [사용자: 248773.9 µs, 시스템: 72935.3 µs]
범위(최소 ~ 최대): 42963.8 µs ~ 46456.2 µs 10회 실행
codon build --release -exe benchmarks/multibrot_set/multibrot_codon_par.codon -o benchmarks/multibrot_set/multibrot_codon_par
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_codon_par.json ' ./benchmarks/multibrot_set/multibrot_codon_par ' # Merge all JSON files into benchmarks.json
python3 benchmarks/hyperfine-scripts/merge_jsons.py benchmarks/multibrot_set/ benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot2.py benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot3.py benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/advanced_statistics.py benchmarks/multibrot_set/benchmarks.json > benchmarks/multibrot_set/benchmarks.json.md
silicon benchmarks/multibrot_set/benchmarks.json.md -l python -o benchmarks/multibrot_set/benchmarks.json.md.png고급 통계
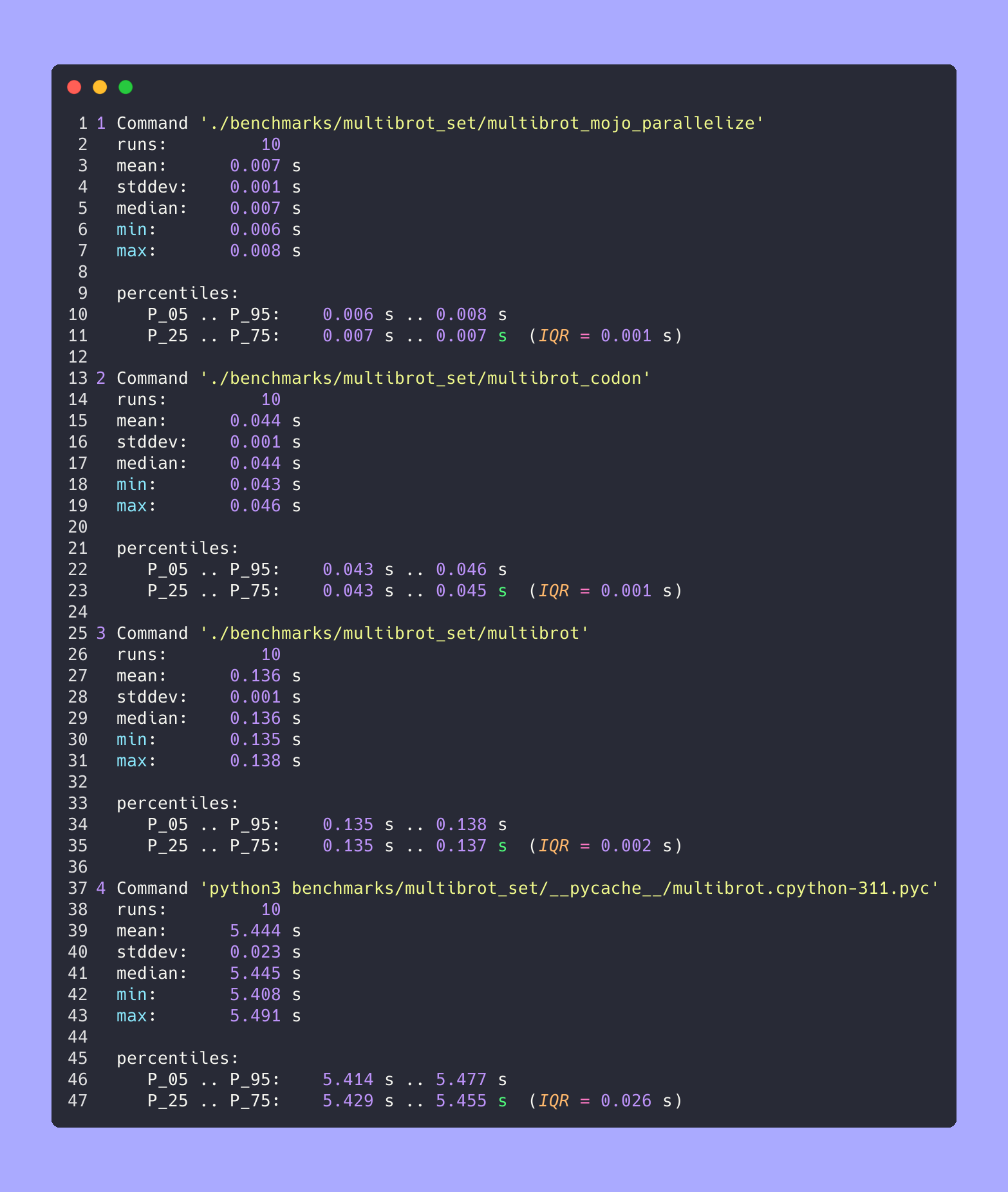
모두 함께
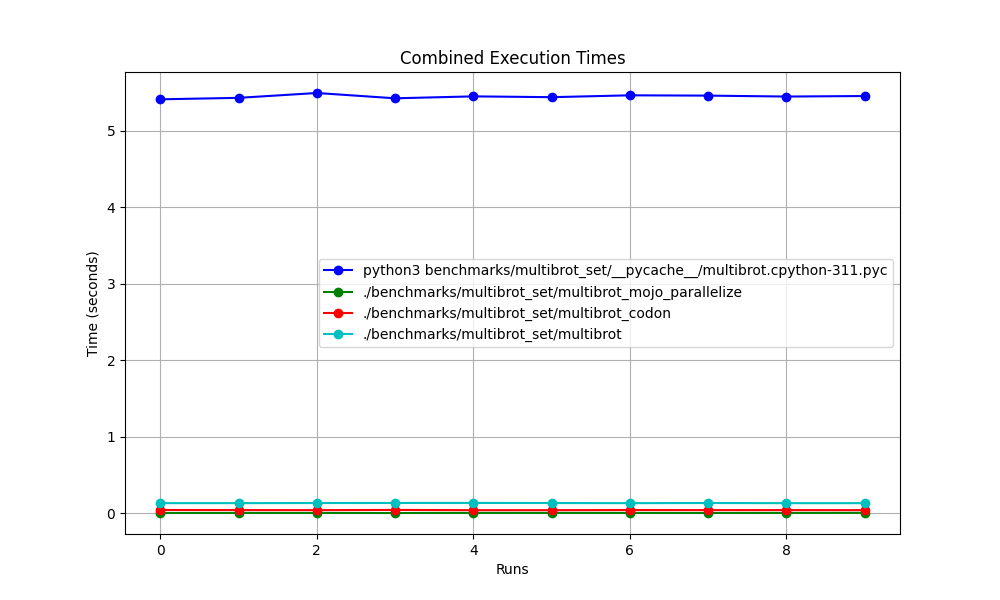
확대됨
하나씩 자세하게
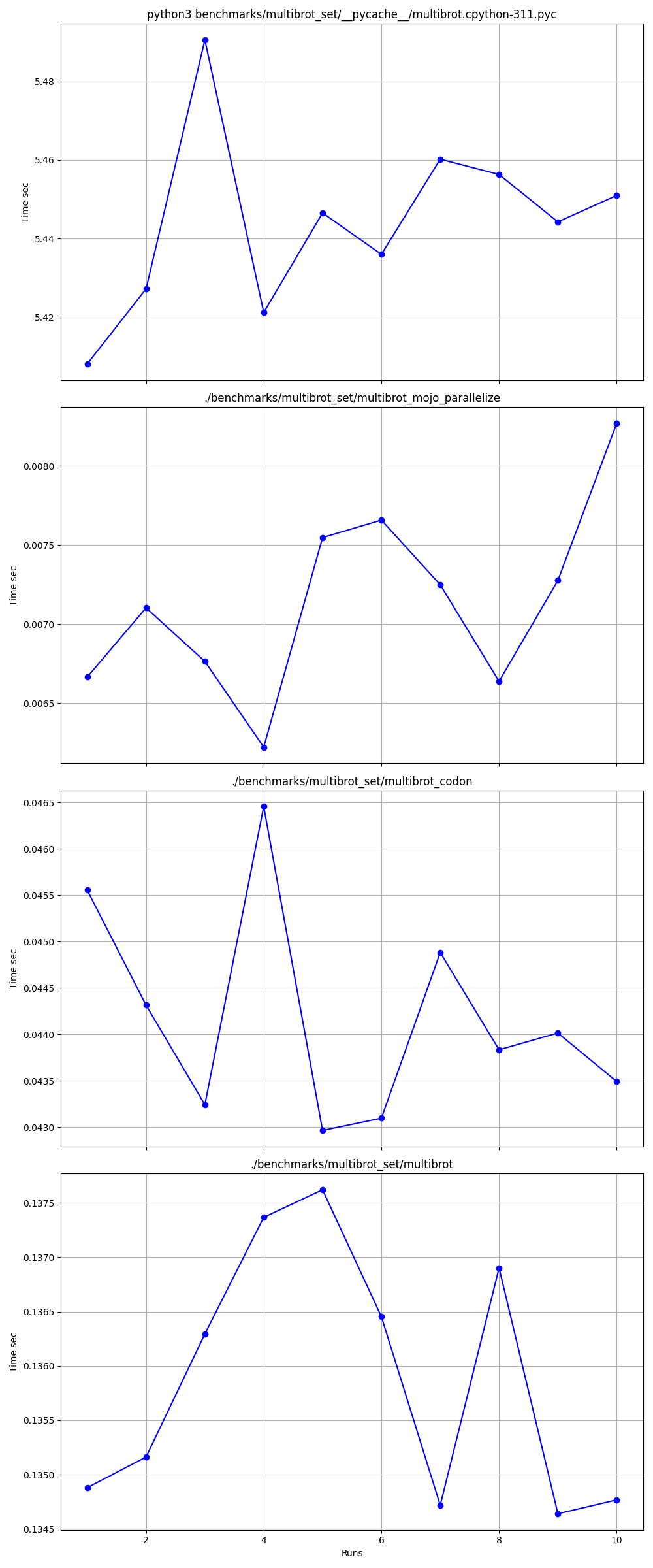
장소
모래밭:
만델브로트 = power = 2
z = z ** power + c # You can change this for different set베개 내장 ImagingEffectMandelbrot
만델브로트의 엑살루프 코돈 버전
Mandelbrot의 모듈형 Mojo 버전
모조 콤플렉스 squared_norm
Matplotlib 만델브로트
컴퓨터 과학에서 반간격 검색, 로그 검색 또는 이진 절단이라고도 알려진 이진 검색 알고리즘은 정렬된 배열 내에서 대상 값의 위치를 찾는 검색 알고리즘입니다.
Python, Mojo, Swift, V, Julia, Nim, Zig를 사용하여 코드를 작성해 보겠습니다.
참고: Python 및 Mojo 버전의 경우 일부 최적화를 남겨두고 측정 및 비교를 위해 코드를 유사하게 만듭니다.
from typing import List
import timeit
SIZE = 1000000
MAX_ITERS = 100
COLLECTION = tuple ( i for i in range ( SIZE )) # Make it aka at compile-time.
def python_binary_search ( element : int , array : List [ int ]) -> int :
start = 0
stop = len ( array ) - 1
while start <= stop :
index = ( start + stop ) // 2
pivot = array [ index ]
if pivot == element :
return index
elif pivot > element :
stop = index - 1
elif pivot < element :
start = index + 1
return - 1
def test_python_binary_search ():
_ = python_binary_search ( SIZE - 1 , COLLECTION )
print (
"Average execution time of func in sec" ,
timeit . timeit ( lambda : test_python_binary_search (), number = MAX_ITERS ),
) """Implements basic binary search."""
from Benchmark import Benchmark
from Vector import DynamicVector
alias SIZE = 1000000
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
fn mojo_binary_search ( element : Int , array : DynamicVector [ Int ]) - > Int :
var start = 0
var stop = len ( array ) - 1
while start <= stop :
let index = ( start + stop ) // 2
let pivot = array [ index ]
if pivot == element :
return index
elif pivot > element :
stop = index - 1
elif pivot < element :
start = index + 1
return - 1
@ parameter # statement runs at compile-time.
fn get_collection () - > DynamicVector [ Int ]:
var v = DynamicVector [ Int ]( SIZE )
for i in range ( SIZE ):
v . push_back ( i )
return v
fn test_mojo_binary_search () - > F64 :
fn test_closure ():
_ = mojo_binary_search ( SIZE - 1 , get_collection ())
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ test_closure ]()) / 1e9
print (
"Average execution time of func in sec " ,
test_mojo_binary_search (),
)Mojoby 커뮤니티(@ego)에 작성되어 mojo-chat에 게시된 최초의 바이너리 검색입니다.
func binarySearch ( items : [ Int ] , elem : Int ) -> Int {
var low = 0
var high = items . count - 1
var mid = 0
while low <= high {
mid = Int ( ( high + low ) / 2 )
if items [ mid ] < elem {
low = mid + 1
} else if items [ mid ] > elem {
high = mid - 1
} else {
return mid
}
}
return - 1
}
let items = [ 1 , 2 , 3 , 4 , 0 ] . sorted ( )
let res = binarySearch ( items : items , elem : 4 )
print ( res ) function binarysearch (lst :: Vector{T} , val :: T ) where T
low = 1
high = length (lst)
while low ≤ high
mid = (low + high) ÷ 2
if lst[mid] > val
high = mid - 1
elseif lst[mid] < val
low = mid + 1
else
return mid
end
end
return 0
end proc binarySearch [T](a: openArray [T], key: T): int =
var b = len (a)
while result < b:
var mid = ( result + b) div 2
if a[mid] < key: result = mid + 1
else : b = mid
if result >= len (a) or a[ result ] != key: result = - 1
let res = @ [ 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 12 , 14 , 16 , 18 , 20 , 22 , 25 , 27 , 30 ]
echo binarySearch (res, 10 ) const std = @import ( "std" );
fn binarySearch ( comptime T : type , arr : [] const T , target : T ) ? usize {
var lo : usize = 0 ;
var hi : usize = arr . len - 1 ;
while ( lo <= hi ) {
var mid : usize = ( lo + hi ) / 2 ;
if ( arr [ mid ] == target ) {
return mid ;
} else if ( arr [ mid ] < target ) {
lo = mid + 1 ;
} else {
hi = mid - 1 ;
}
}
return null ;
} fn binary_search (a [] int , value int ) int {
mut low := 0
mut high := a.len - 1
for low < = high {
mid := (low + high) / 2
if a[mid] > value {
high = mid - 1
} else if a[mid] < value {
low = mid + 1
} else {
return mid
}
}
return - 1
}
fn main () {
search_list := [ 1 , 2 , 3 , 5 , 6 , 7 , 8 , 9 , 10 ]
println ( binary_search (search_list, 9 ))
} fn breadth_first_search_path (graph map [ string ][] string , vertex string , target string ) [] string {
mut path := [] string {}
mut visited := [] string {init: vertex}
mut queue := [][][] string {}
queue << [[vertex], path]
for queue.len > 0 {
mut idx := queue.len - 1
node := queue[idx][ 0 ][ 0 ]
path = queue[idx][ 1 ]
queue. delete (idx)
if node == target {
path << node
return path
}
for child in graph[node] {
mut tmp := path. clone ()
if child ! in visited {
visited << child
tmp << node
queue << [[child], tmp]
}
}
}
return path
}
fn main () {
graph := map {
'A' : [ 'B' , 'C' ]
'B' : [ 'A' , 'D' , 'E' ]
'C' : [ 'A' , 'F' ]
'D' : [ 'B' ]
'E' : [ 'B' , 'F' ]
'F' : [ 'C' , 'E' ]
}
println ( 'Graph: $graph ' )
path := breadth_first_search_path (graph, 'A' , 'F' )
println ( 'The shortest path from node A to node F is: $path ' )
assert path == [ 'A' , 'C' , 'F' ]
} import timeit
SIZE = 100
MAX_ITERS = 100
def _fizz_buzz (): # Make it aka at compile-time.
res = []
for n in range ( 1 , SIZE + 1 ):
if ( n % 3 == 0 ) and ( n % 5 == 0 ):
s = "FizzBuzz"
elif n % 3 == 0 :
s = "Fizz"
elif n % 5 == 0 :
s = "Buzz"
else :
s = str ( n )
res . append ( s )
return res
DATA = _fizz_buzz ()
def fizz_buzz ():
print ( " n " . join ( DATA ))
print (
"Average execution time of Python func in sec" ,
timeit . timeit ( lambda : fizz_buzz (), number = MAX_ITERS ),
)
# Average execution time of Python func in sec 0.005334990004485007 ( import '[java.io OutputStream])
( require '[clojure.java.io :as io])
( def devnull ( io/writer ( OutputStream/nullOutputStream )))
( defmacro timeit [n expr]
`(with-out-str ( time
( dotimes [_# ~( Math/pow 1 n)]
( binding [*out* devnull]
~expr)))))
( defmacro macro-fizz-buzz [n]
`( fn []
( print
~( apply str
( for [i ( range 1 ( inc n))]
( cond
( zero? ( mod i 15 )) " FizzBuzz n "
( zero? ( mod i 5 )) " Buzz n "
( zero? ( mod i 3 )) " Fizz n "
:else ( str i " n " )))))))
( print ( timeit 100 ( macro-fizz-buzz 100 )))
; ; "Elapsed time: 0.175486 msecs"
; ; Average execution time of Clojure func in sec 0.000175486 seconds from String import String
from Benchmark import Benchmark
alias SIZE = 100
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
@ parameter # statement runs at compile-time.
fn _fizz_buzz () - > String :
var res : String = ""
for n in range ( 1 , SIZE + 1 ):
if ( n % 3 == 0 ) and ( n % 5 == 0 ):
res += "FizzBuzz"
elif n % 3 == 0 :
res += "Fizz"
elif n % 5 == 0 :
res += "Buzz"
else :
res += String ( n )
res += " n "
return res
fn fizz_buzz ():
print ( _fizz_buzz ())
fn run_benchmark () - > F64 :
fn _closure ():
_ = fizz_buzz ()
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of func in sec " ,
run_benchmark (),
)
# Average execution time of func in sec 0.000104 이는 커뮤니티(@Ego)가 Mojo로 작성한 최초의 Fizz 버즈입니다.
우리는 알고리즘에 대한 잘 알려진 참고서인 알고리즘 소개 A3의 알고리즘을 사용할 것입니다.
그 명성으로 인해 약어 " CLRS "(Cormen, Leiserson, Rivest, Stein) 또는 초판에서는 " CLR "(Cormen, Leiserson, Rivest)이 일반적으로 사용되었습니다.
2장 "2.3.1 분할 정복 접근법".
% % python
import timeit
MAX_ITERS = 100
def merge ( A , p , q , r ):
n1 = q - p + 1
n2 = r - q
L = [ None ] * n1
R = [ None ] * n2
for i in range ( n1 ):
L [ i ] = A [ p + i ]
for j in range ( n2 ):
R [ j ] = A [ q + 1 + j ]
i = 0
j = 0
k = p
while i < n1 and j < n2 :
if L [ i ] <= R [ j ]:
A [ k ] = L [ i ]
i += 1
else :
A [ k ] = R [ j ]
j += 1
k += 1
while i < n1 :
A [ k ] = L [ i ]
i += 1
k += 1
while j < n2 :
A [ k ] = R [ j ]
j += 1
k += 1
def merge_sort ( A , p , r ):
if p < r :
q = ( p + r ) // 2
merge_sort ( A , p , q )
merge_sort ( A , q + 1 , r )
merge ( A , p , q , r )
def run_benchmark_merge_sort ():
A = [ 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 ]
merge_sort ( A , 0 , len ( A ) - 1 )
print (
"Average execution time of Python `merge_sort` in sec" ,
timeit . timeit ( lambda : run_benchmark_merge_sort (), number = MAX_ITERS ),
)
# Average execution time of Python `merge_sort` in sec 0.019136679999064654
def run_benchmark_sort ():
A = [ 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 ]
A . sort ()
print (
"Average execution time of Python builtin `sort` in sec" ,
timeit . timeit ( lambda : run_benchmark_sort (), number = MAX_ITERS ),
)
# Average execution time of Python builtin `sort` in sec 0.00019922800129279494 from Benchmark import Benchmark
from Vector import DynamicVector
from StaticTuple import StaticTuple
from Sort import sort
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
fn merge ( inout A : DynamicVector [ Int ], p : Int , q : Int , r : Int ):
let n1 = q - p + 1
let n2 = r - q
var L = DynamicVector [ Int ]( n1 )
var R = DynamicVector [ Int ]( n2 )
for i in range ( n1 ):
L [ i ] = A [ p + i ]
for j in range ( n2 ):
R [ j ] = A [ q + 1 + j ]
var i = 0
var j = 0
var k = p
while i < n1 and j < n2 :
if L [ i ] <= R [ j ]:
A [ k ] = L [ i ]
i += 1
else :
A [ k ] = R [ j ]
j += 1
k += 1
while i < n1 :
A [ k ] = L [ i ]
i += 1
k += 1
while j < n2 :
A [ k ] = R [ j ]
j += 1
k += 1
fn merge_sort ( inout A : DynamicVector [ Int ], p : Int , r : Int ):
if p < r :
let q = ( p + r ) // 2
merge_sort ( A , p , q )
merge_sort ( A , q + 1 , r )
merge ( A , p , q , r )
@ parameter
fn create_vertor () - > DynamicVector [ Int ]:
let st = StaticTuple [ MAX_ITERS , Int ]( 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 )
var v = DynamicVector [ Int ]( st . __len__ ())
for i in range ( st . __len__ ()):
v . push_back ( st [ i ])
return v
fn run_benchmark_merge_sort () - > F64 :
fn _closure ():
var A = create_vertor ()
merge_sort ( A , 0 , len ( A ) - 1 )
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of Mojo `merge_sort` in sec " ,
run_benchmark_merge_sort (),
)
# Average execution time of Mojo `merge_sort` in sec 1.1345999999999999e-05
fn run_benchmark_sort () - > F64 :
fn _closure ():
var A = create_vertor ()
sort ( A )
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of Mojo builtin `sort` in sec " ,
run_benchmark_sort (),
)
# Average execution time of Mojo builtin `sort` in sec 2.988e-06다음과 같이 사용할 수 있습니다.
# Usage: merge_sort
var A = create_vertor ()
merge_sort ( A , 0 , len ( A ) - 1 )
print ( len ( A ))
print ( A [ 0 ], A [ 99 ]) 내장된 from Sort import sort 퀵정렬은 구현보다 조금 더 빠르지만 언어 및 평소와 같이 알고리즘 =) 및 프로그래밍 패러다임을 통해 최적화할 수 있습니다.
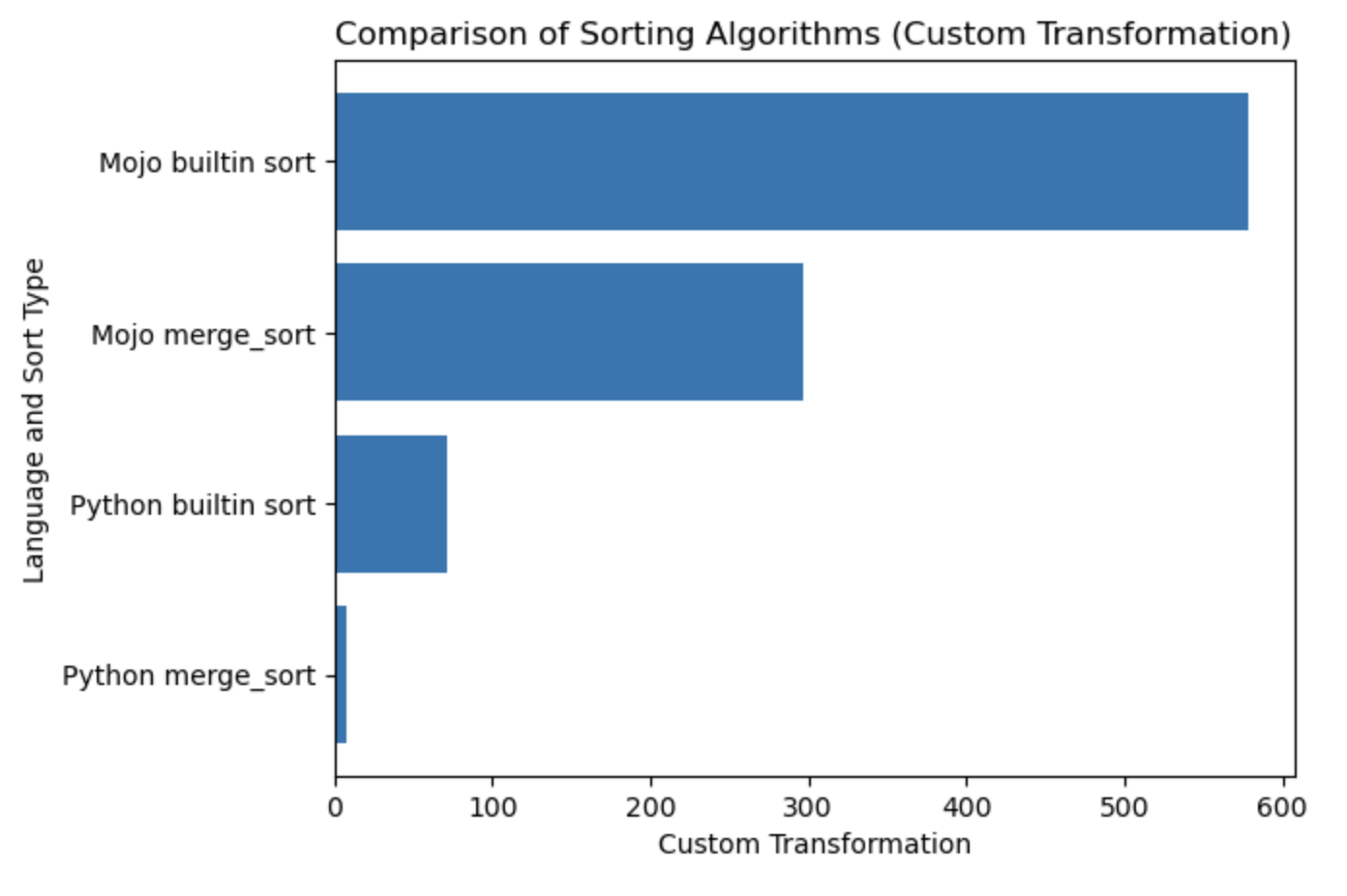
| 랑 | 비서 |
|---|---|
| 파이썬 병합_정렬 | 0.019136679 |
| Python 내장 정렬 | 0.000199228 |
| 모조 병합_정렬 | 0.000011346 |
| Mojo 내장 정렬 | 0.000002988 |
이 테이블에 대한 플롯을 작성해 보겠습니다.
#%%python
import matplotlib . pyplot as plt
import numpy as np
languages = [ 'Python merge_sort' , 'Python builtin sort' , 'Mojo merge_sort' , 'Mojo builtin sort' ]
seconds = [ 0.019136679 , 0.000199228 , 0.000011346 , 0.000002988 ]
# Apply a custom transformation to the values
transformed_seconds = [ np . sqrt ( 1 / x ) for x in seconds ]
plt . barh ( languages , transformed_seconds )
plt . xlabel ( 'Custom Transformation' )
plt . ylabel ( 'Language and Sort Type' )
plt . title ( 'Comparison of Sorting Algorithms (Custom Transformation)' )
plt . show ()메모를 플롯하면 많을수록 더 좋고 빠릅니다.
여기 HelloMojo에서 시작하여 여기에서 [매개변수] 및 [매개변수 표현식] 매개변수화를 이해하는 것이 좋습니다. 이 예에서처럼:
fn concat [ len1 : Int , len2 : Int ]( lhs : MySIMD [ len1 ], rhs : MySIMD [ len2 ]) - > MySIMD [ len1 + len2 ]:
let result = MySIMD [ len1 + len2 ]()
for i in range ( len1 ):
result [ i ] = lhs [ i ]
for j in range ( len2 ):
result [ len1 + j ] = rhs [ j ]
return result
let a = MySIMD [ 2 ]( 1 , 2 )
let x = concat [ 2 , 2 ]( a , a )
x . dump () 컴파일 시간 [매개변수]: fn concat[len1: Int, len2: Int] .
런타임 (Args) : fn concat(lhs: MySIMD, rhs: MySIMD) .
대괄호(대괄호 [] 로 묶인 매개변수 PEP695 구문.
이제 Python에서:
def func ( a : _T , b : _T ) -> _T :
...이제 Mojo에서:
def func [ T ]( a : T , b : T ) -> T :
... [매개변수] 는 이름이 지정되고 Mojo 프로그램의 일반 값과 같은 유형을 갖지만 parameters[] 컴파일 타임 에 평가됩니다.
런타임 프로그램은 [매개변수] 값을 사용할 수 있습니다. 왜냐하면 매개변수는 런타임 프로그램에서 필요하기 전에 컴파일 타임에 확인되기 때문입니다. 그러나 컴파일 타임 매개변수 표현식은 런타임 값을 사용할 수 없습니다.
PEP673의 Self 유형
fn __sub__ ( self , rhs : Self ) - > Self :
let result = MySIMD [ size ]()
for i in range ( size ):
result [ i ] = self [ i ] - rhs [ i ]
return result문서에서 Fields 라는 단어를 찾을 수 있습니다. Python에서는 클래스 속성 이라고도 합니다.
따라서 dot 으로 호출합니다.
from DType import DType
let bool_type = DType . bool from DType import DType
DType . si8 from DType import DType
from SIMD import SIMD , SI8
alias MY_SIMD_DType_si8 = SIMD [ DType . si8 , 1 ]
alias MY_SI8 = SI8
print ( MY_SIMD_DType_si8 == MY_SI8 )
# true from DType import DType
from SIMD import SIMD , SI8
from Vector import DynamicVector
from String import String
alias a = DynamicVector [ SIMD [ DType . si8 , 1 ]]
alias b = DynamicVector [ SI8 ]
print ( a == b )
print ( a == String )
print ( b == String )
# all true 따라서 String 은 DynamicVector[SIMD[DType.si8, 1]] 과 같은 것에 대한 별칭일 뿐입니다.
VariadicList from List import VariadicList
fn destructuring_arguments ( * args : Int ):
let my_var_list = VariadicList ( args )
for i in range ( len ( my_var_list )):
print ( "argument" , i , ":" , my_var_list [ i ])
destructuring_arguments ( 1 , 2 , 3 , 4 )초기 컬렉션을 만드는 데 매우 유용합니다. 우리는 다음과 같이 쓸 수 있습니다:
from Vector import DynamicVector
from StaticTuple import StaticTuple
fn create_vertor () - > DynamicVector [ Int ]:
let st = StaticTuple [ 4 , Int ]( 1 , 2 , 3 , 4 )
var v = DynamicVector [ Int ]( st . __len__ ())
for i in range ( st . __len__ ()):
v . push_back ( st [ i ])
return v
v = create_vertor ()
print ( v [ 0 ], v [ 3 ])
# or
from List import VariadicList
fn create_vertor () - > DynamicVector [ Int ]:
let var_list = VariadicList ( 1 , 2 , 3 , 4 )
var v = DynamicVector [ Int ]( len ( var_list ))
for i in range ( len ( var_list )):
v . push_back ( var_list [ i ])
return v
v = create_vertor ()
print ( v [ 0 ], v [ 3 ])함수 def 및 fn에 대해 자세히 읽어보세요.
from String import String
# String concatenation
print ( String ( "'" ) + String ( 1 ) + "' n " )
# Python's join
print ( String ( "|" ). join ( "a" , "b" , "c" ))
# String format
from IO import _printf as print
let x : Int = 1
print ( "'%i' n " , x . value )문자열의 경우 형식 문자열 슬라이스[start:end:step]와 함께 내장 슬라이스를 사용할 수 있습니다.
from String import String
let hello_mojo = String ( "Hello Mojo!" )
print ( "Till the end:" , hello_mojo [ 0 ::])
print ( "Before last 2 chars:" , hello_mojo [ 0 : - 2 ])
print ( "From start to the end with step 2:" , hello_mojo [ 0 :: 2 ])
print ( "From start to the before last with step 3:" , hello_mojo [ 0 : - 1 : 3 ])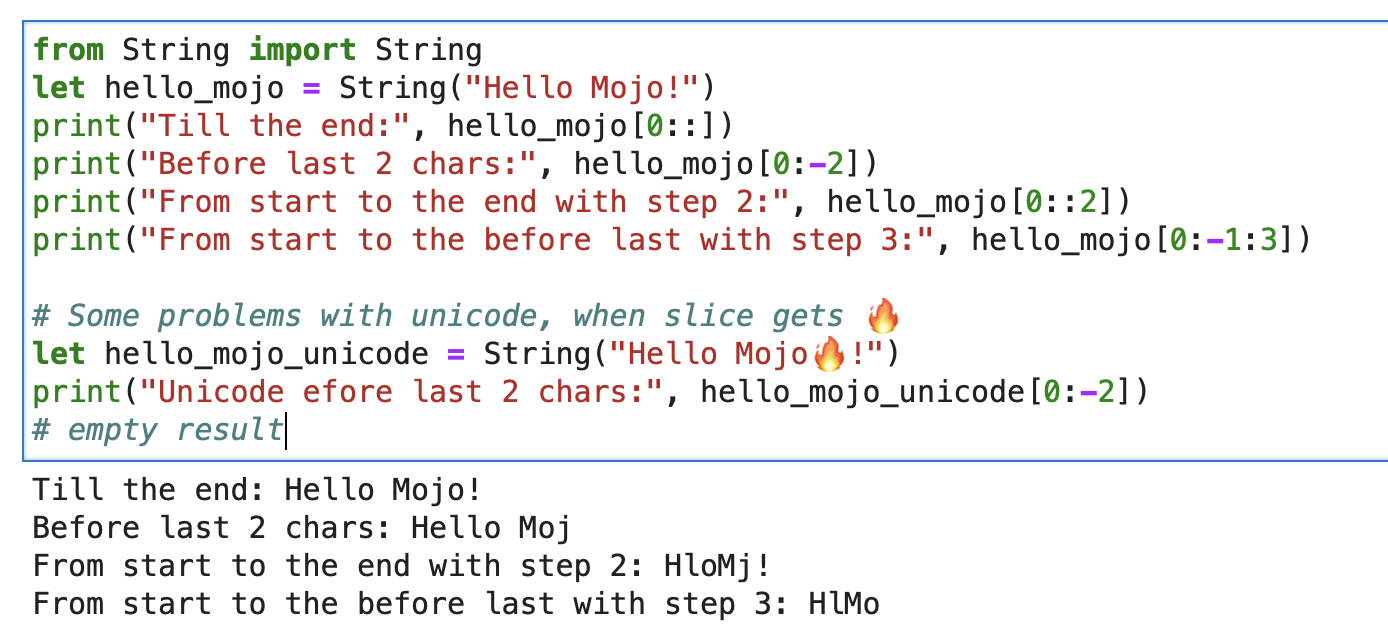
슬라이싱할 때 유니코드에 몇 가지 문제가 있습니다.
let hello_mojo_unicode = String ( "Hello Mojo!" )
print ( "Unicode efore last 2 chars:" , hello_mojo_unicode [ 0 : - 2 ])
# no result, silents여기에 설명과 토론이 있습니다.
mbstowcs - 멀티바이트 문자열을 와이드 문자 문자열로 변환
struct 데코레이터(Python @dataclass . 자동으로 __init__ , __copyinit__ , __moveinit__ 메소드를 생성합니다.
@ value
struct dataclass :
var name : String
var age : Int @value 데코레이터는 멤버가 copyable 및/또는 movable 유형에서만 작동합니다.
사소한 유형. 이 데코레이터는 유형이 복사 가능한 __copyinit__ 및 이동 가능한 __moveinit__ 이어야 함을 Mojo에 알려줍니다. 또한 Mojo는 CPU 레지스터에 값을 전달하는 것을 선호합니다. structs memory 통과하는 대신 register 에 전달되도록 선택할 수 있습니다.
@ register_passable ( "trivial" )
struct Int :
var value : __mlir_type . `!pop.scalar<index>`컴파일러 최적화 에 대한 완전한 제어를 제공하는 데코레이터. 이 함수가 호출될 때 항상 인라인 하도록 컴파일러에 지시합니다.
@ always_inline
fn foo ( x : Int , y : Int ) - > Int :
return x + y
fn bar ( z : Int ):
let r = foo ( z , z ) # This call will be inlined"파라메트릭" 캡처 클로저를 생성하기 위해 런타임 값을 캡처하는 중첩 함수에 배치할 수 있습니다. 런타임 값을 캡처하는 클로저를 매개변수 값으로 전달할 수 있습니다.
@ always_inline
@ parameter
fn test (): return 일부 캐스팅 예시
s : StringLiteral
let p = DTypePointer [ DType . si8 ]( s . data ()). bitcast [ DType . ui8 ]()
var result = 0
result += (( p . simd_load [ 64 ]( offset ) >> 6 ) != 0b10 ). cast [ DType . ui8 ](). reduce_add (). to_int ()
let rest_p : DTypePointer [ DType . ui8 ] = stack_allocation [ simd_width , UI8 , 1 ]()
from Bit import ctlz
s : String
i : Int
let code = s . buffer . data . load ( i )
let byte_length_code = ctlz ( ~ code ). to_int ()DTypePointer - 지정된 DType으로 주소를 저장하여 SIMD 작업에 편리하게 액세스하여 데이터를 할당, 로드 및 수정할 수 있습니다.
from Pointer import DTypePointer
from DType import DType
from Random import rand
from Memory import memset_zero
# `heap`
var my_pointer_on_heap = DTypePointer [ DType . ui8 ]. alloc ( 8 )
memset_zero ( my_pointer_on_heap , 8 )
# `stack or register`
var data = my_pointer_on_heap . simd_load [ 8 ]( 0 )
print ( data )
rand ( my_pointer_on_heap , 4 )
# `data` does not contain a reference to the `heap`, so load the data again
data = my_pointer_on_heap . simd_load [ 8 ]( 0 )
print ( data )
# simd_load and simd_store
var half = my_pointer_on_heap . simd_load [ 4 ]( 0 )
half = half + 1
my_pointer_on_heap . simd_store [ 4 ]( 4 , half )
print ( my_pointer_on_heap . simd_load [ 8 ]( 0 ))
# Pointer move back
my_pointer_on_heap -= 1
print ( my_pointer_on_heap . simd_load [ 8 ]( 0 ))
# Mast free memory
my_pointer_on_heap . free ()Struct는 Scoup을 제한하여 포인터의 잠재적 위험을 최소화할 수 있습니다.
DTypePointer에 관한 Mojo Dojo 블로그의 훌륭한 기사는 여기를 참조하세요.
게다가 그의 예제 Matrix Struct 및 DTypePointer
포인터는 모든 register_passable type 에 대한 주소를 저장하고 그 중 n 개를 heap 에 할당합니다.
from Pointer import Pointer
from Memory import memset_zero
from String import String
@ register_passable # for syntaxt like `let coord = p1[0]` and let it be passed through registers.
struct Coord : # memory-only type
var x : UI8
var y : UI8
var p1 = Pointer [ Coord ]. alloc ( 2 )
memset_zero ( p1 , 2 )
var coord = p1 [ 0 ] # is an identifier to memory on the stack or in a register
print ( coord . x )
# Store the value
coord . x = 5
coord . y = 5
print ( coord . x )
# We need to store the data.
p1 . store ( 0 , coord )
print ( p1 [ 0 ]. x )
# Mast free memory
p1 . free ()포인터에 관한 전체 기사
플러스 예 포인터 및 구조체
Modular Intrinsics는 일종의 실행 백엔드 입니다.
Mojo-> MLIR Dialects -> 최적화 코드 및 아키텍처가 포함된 실행 백엔드.
MLIR은 다양한 프로그래밍 언어 및 아키텍처 에 대한 다양한 변환 및 최적화 패스를 구현하는 컴파일러 인프라 마녀입니다.
MLIR 자체는 운영 체제 syscall과 상호 작용하는 기능을 직접 제공하지 않습니다.
운영 체제 서비스에 대한 저수준 인터페이스는 일반적으로 대상 프로그래밍 언어 또는 운영 체제 자체 수준에서 처리됩니다. MLIR은 언어 및 대상에 구애받지 않도록 설계되었으며 기본 초점은 최적화 수행을 위한 중간 표현을 제공하는 것입니다. MLIR에서 운영 체제 시스템 호출을 수행하려면 대상별 백엔드를 사용해야 합니다.
그러나 이러한 execution backends 사용하면 기본적으로 OS 시스템 호출에 액세스할 수 있습니다. 그리고 우리는 C/LLVM/Python 관련 전 세계를 내부적으로 보유하고 있습니다.
실제로 동일한 내용을 빠르게 살펴보겠습니다.
from OS import getenv
print ( getenv ( "PATH" ))
print ( getenv ( StringRef ( "PATH" )))
# or like this
from SIMD import SI8
from Intrinsics import external_call
var path1 = external_call [ "getenv" , StringRef ]( StringRef ( "PATH" ))
print ( path1 . data )
var path2 = external_call [ "getenv" , StringRef ]( "PATH" )
print ( path2 . data )
let abs_10 = external_call [ "abs" , SI8 , Int ]( - 10 )
print ( abs_10 ) 이 간단한 예에서는 external_call 사용하여 Mojo와 libc 함수 간의 캐스팅 유형으로 OS 환경 변수를 가져왔습니다. 꽤 멋지다, 응!
저는 이 주제에 대해 많은 아이디어를 갖고 있으며 곧 이를 구현할 기회를 간절히 기다리고 있습니다. 행동을 취하면 놀라운 결과가 나올 수 있습니다 =)
흥미로운 일을 해 봅시다 - libc function gethostname을 호출하십시오.
함수에는 int gethostname (char *name, size_t size) 인터페이스가 있습니다.
이를 위해 Intrinsics 모듈의 도우미 함수 external_call을 사용하거나 자체 MLIR을 작성할 수 있습니다.
코드를 살펴보자:
from Intrinsics import external_call
from SIMD import SIMD , SI8
from DType import DType
from Vector import DynamicVector
from DType import DType
from Pointer import DTypePointer , Pointer
# We can use `from String import String` but for clarification we will use a full form.
# DynamicVector[SIMD[DType.si8, 1]] == DynamicVector[SI8] == String
# Compile time stuff.
alias cArrayOfStrings = DynamicVector [ SIMD [ DType . si8 , 1 ]]
alias capacity = 1024
var c_pointer_to_array_of_strings = DTypePointer [ DType . si8 ]( cArrayOfStrings ( capacity ). data )
var c_int_result = external_call [ "gethostname" , Int , DTypePointer [ DType . si8 ], Int ]( c_pointer_to_array_of_strings , capacity )
let mojo_string_result = String ( c_pointer_to_array_of_strings . address )
print ( "C function gethostname result code:" , c_int_result )
print ( "C function gethostname result value:" , star_hostname ( mojo_string_result ))
@ always_inline
fn star_hostname ( hostname : String ) - > String :
# [Builtin Slice](https://docs.modular.com/mojo/MojoBuiltin/BuiltinSlice.html)
# string slice[start:end:step]
return hostname [ 0 : - 1 : 2 ]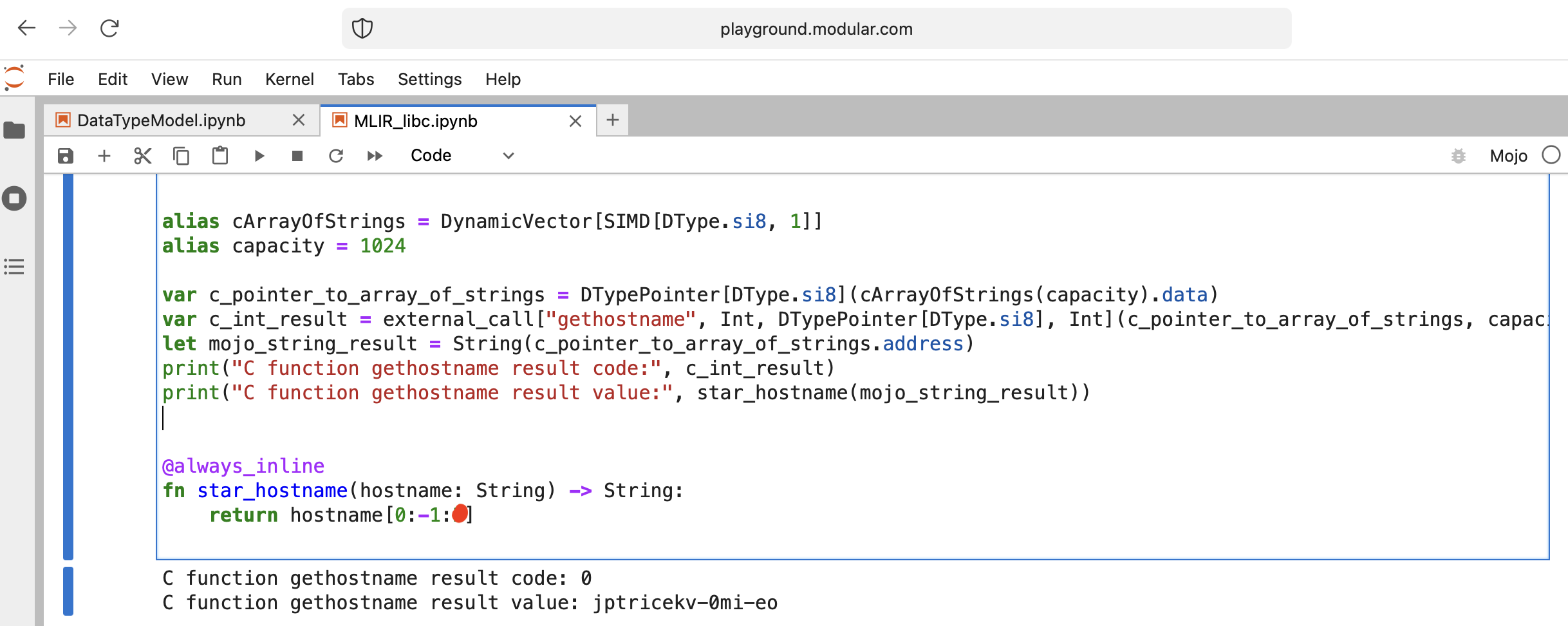
Mojo를 사용하여 웹을 위한 몇 가지 작업을 수행해 보겠습니다. Playground.modular.com에서는 인터넷에 접속할 수 없습니다. 하지만 한 컴퓨터에서 TCP와 같은 흥미로운 작업을 훔칠 수 있습니다.
PythonInterface를 사용하여 Mojo에서 첫 번째 TCP 클라이언트-서버 코드를 작성해 보겠습니다.
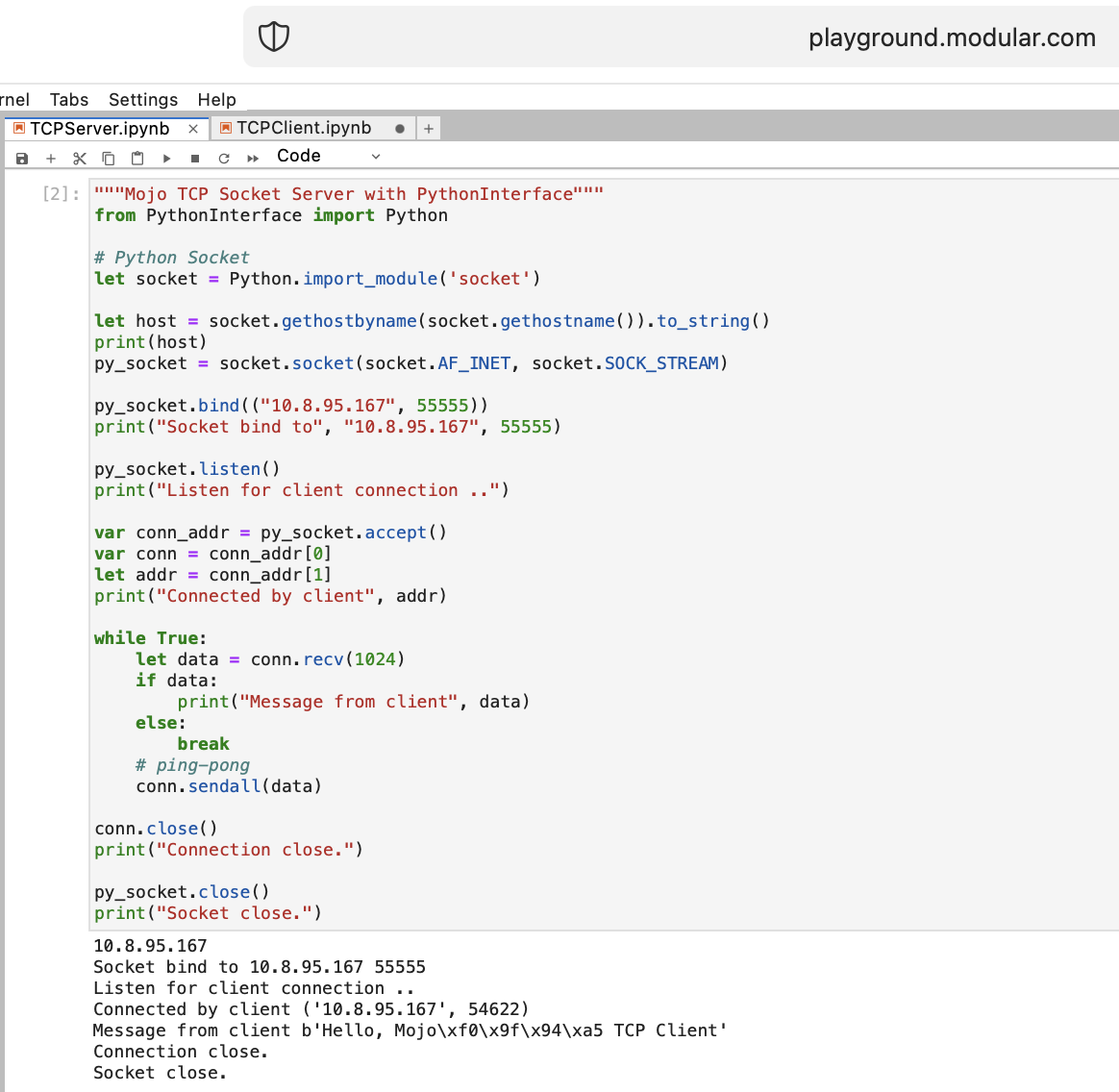
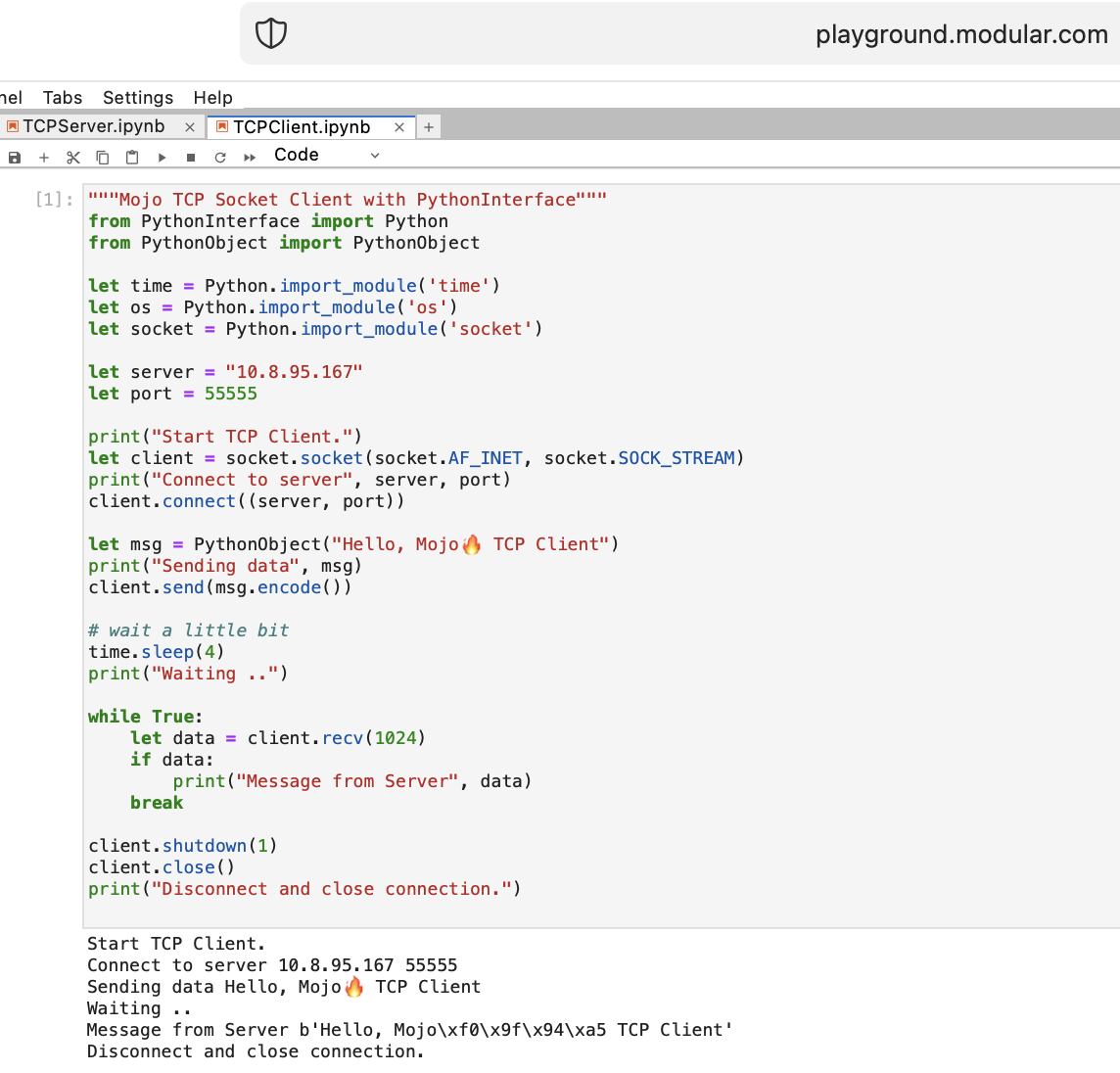
두 개의 별도 노트북을 생성하고 TCPSocketServer를 먼저 실행한 다음 TCPSocketClient를 실행해야 합니다.
이 코드의 Python 버전은 다음을 제외하고 거의 동일합니다.
withleta, b = (1, 2) 와 같은 구조 분해Mojo의 TCP 서버 이후에 우리는 앞으로 나아갈 것입니다 =)
이상하지만 Mojo를 사용하여 최신 Python 웹 서버 FastAPI를 실행해 보겠습니다!
FastAPI 코드를 플레이그라운드에 업로드해야 합니다. 따라서 로컬 컴퓨터에서 다음을 수행하십시오.
pip install --target=web fastapi uvicorn
tar -czPf web.tar.gz web 웹 인터페이스를 통해 web.tar.gz 플레이그라운드에 업로드합니다.
그런 다음 install 해야 합니다. 적절한 폴더에 넣으면 됩니다.
% % python
import os
import site
site_packages_path = site . getsitepackages ()[ 0 ]
# install fastapi
os . system ( f"tar xzf web.tar.gz -C { site_packages_path } " )
os . system ( f"cp -r { site_packages_path } /web/* { site_packages_path } /" )
os . system ( f"ls { site_packages_path } | grep fastapi" )
# clean packages
os . system ( f"rm -rf { site_packages_path } /web" )
os . system ( f"rm web.tar.gz" ) from PythonInterface import Python
# Python fastapi
let fastapi = Python . import_module ( "fastapi" )
let uvicorn = Python . import_module ( "uvicorn" )
var app = fastapi . FastAPI ()
var router = fastapi . APIRouter ()
# tricky part
let py = Python ()
let py_code = """lambda: 'Hello Mojo!'"""
let py_obj = py . evaluate ( py_code )
print ( py_obj )
router . add_api_route ( "/mojo" , py_obj )
app . include_router ( router )
print ( "Start FastAPI WEB Server" )
uvicorn . run ( app )
print ( "Done" ) from PythonInterface import Python
let http_client = Python . import_module ( "http.client" )
let conn = http_client . HTTPConnection ( "localhost" , 8000 )
conn . request ( "GET" , "/mojo" )
let response = conn . getresponse ()
print ( response . status , response . reason , response . read ())평소와 같이 두 개의 별도 노트북을 생성하고 FastAPI를 먼저 실행한 다음 FastAPIClient를 실행해야 합니다.
열려 있는 질문이 많이 있지만 기본적으로 우리는 목표를 달성합니다.
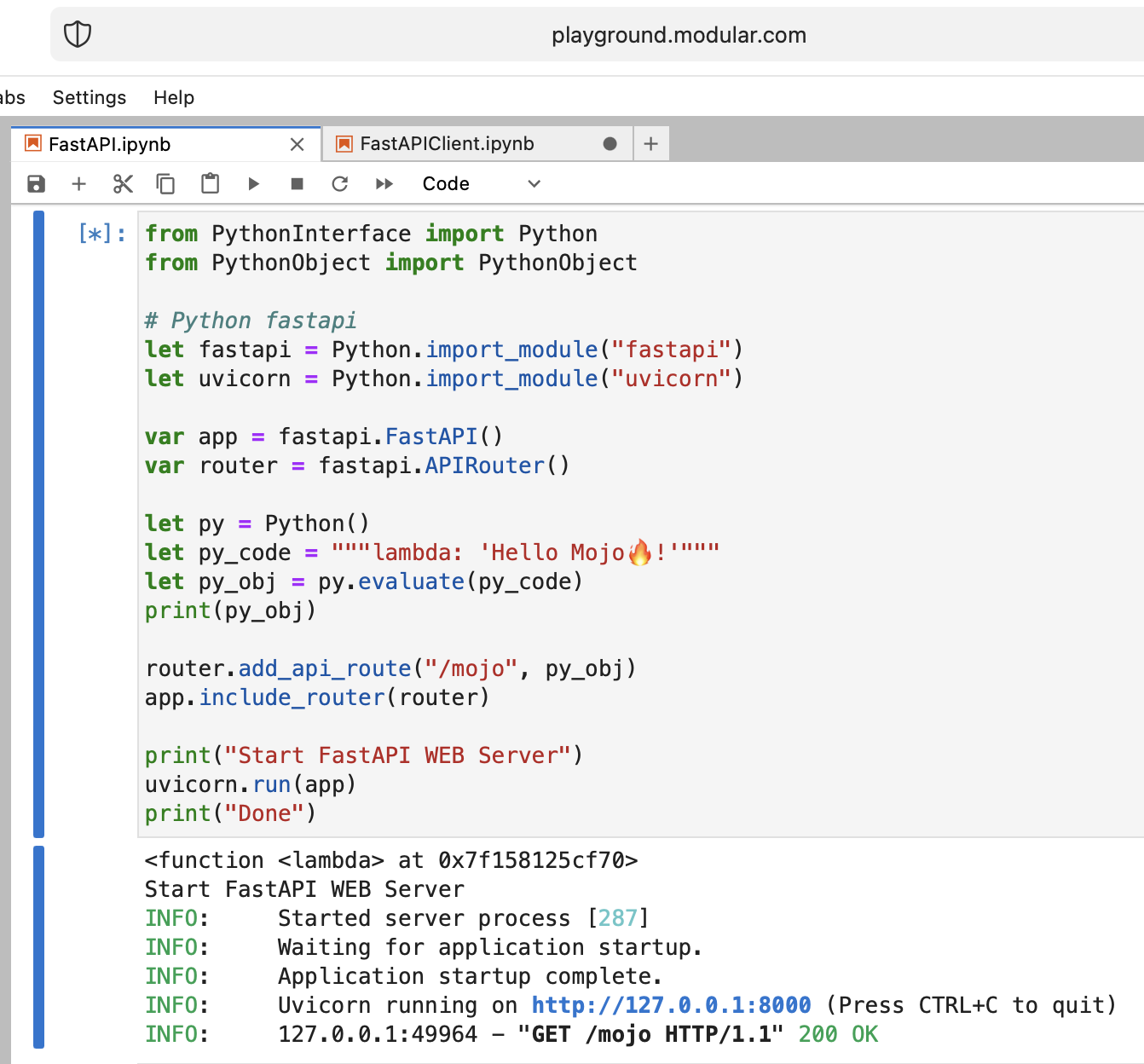
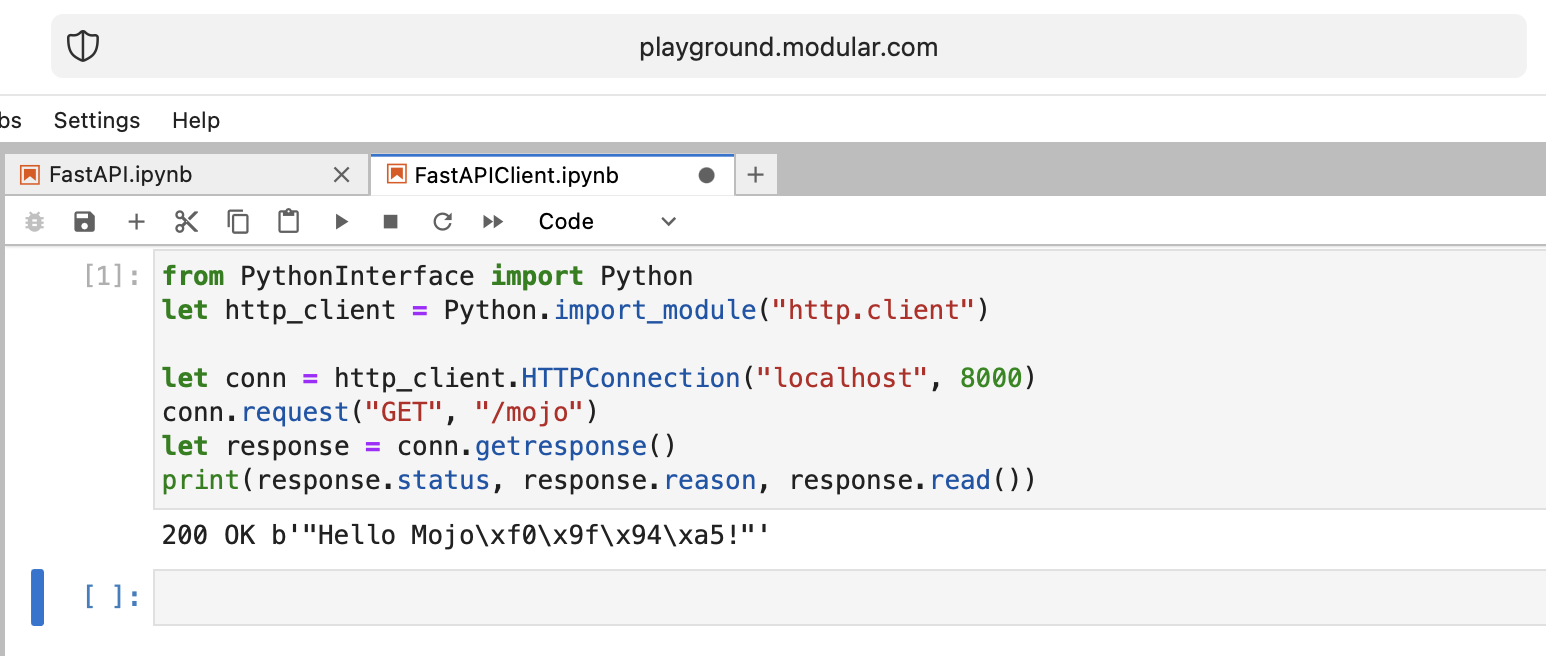
모조 잘했어!
몇 가지 공개 질문:
from PythonInterface import Python
let pyfn = Python . evaluate ( "lambda x, y: x+y" )
let functools = Python . import_module ( "functools" )
print ( functools . reduce ( pyfn , [ 1 , 2 , 3 , 4 ]))
# How to, without Mojo pyfn.so?
def pyfn ( x , y ):
retyrn x + y미래는 매우 낙관적입니다!
모래밭:
Nick Wogan의 벤치마크 Mojo vs Numba
Samay Kapadia @Zalando의 시간 활용
VSCode 또는 DataSpell에서 Mojo 플레이그라운드에 연결
맥심 잭스
from String import String
from PythonInterface import Python
let pathlib = Python . import_module ( 'pathlib' )
let txt = pathlib . Path ( 'nfl.csv' ). read_text ()
let s : String = txt . to_string ()libc 구현
from DType import DType
from Buffer import Buffer
from Pointer import Pointer
from String import String , chr
let hello = "hello"
let pointer = Pointer ( hello . data ())
print ( "variant 1" )
var result = String ()
for i in range ( len ( hello )):
result += chr ( pointer . bitcast [ Int8 ](). offset ( i ). load (). to_int ())
print ( result )
print ( "variant 2" )
print ( StringRef ( hello . data ()))
print ( "variant 3" )
print ( StringRef ( pointer . address ))
print ( "variant 4" )
let pm : Pointer [ __mlir_type . `!pop.scalar<si8>` ] = Pointer ( hello . data ())
print ( StringRef ( pm . address ))
print ( "variant 5" )
print ( String ( pointer . address ))
print ( "variant 6" )
let x = Buffer [ 8 , DType . int8 ]( pointer )
let array = x . simd_load [ 10 ]( 0 )
var result = String ()
for i in range ( len ( array )):
result += chr ( array [ i ]. to_int ())
print ( result )right click 하고 Open With > Editor 누릅니다.select all 하고 copy.ipynb 와 같은 Jupyter 확장자를 사용하여 파일 이름을 지정합니다.Github는 이를 적절하게 렌더링한 다음 누군가 자신의 플레이그라운드에서 코드를 시험해보고 싶다면 원시 코드를 복사하여 붙여넣을 수 있습니다.
제 개인적인 생각이니 너무 가혹하게 판단하지 마세요.
예를 들어 Python처럼 Mojo가 배우기 쉬운 프로그래밍 언어라고 말할 수는 없습니다.
다른 프로그래밍 언어에 대한 많은 이해, 인내 및 경험이 필요합니다.
사소하지 않은 것을 만들고 싶다면 힘들지만 재미있을 것입니다!
이 여행을 시작한 지 2주가 지났고, 이제 Mojo에 대해 잘 알게 되었다는 소식을 전해드리게 되어 기쁩니다.
그 구조와 구문 의 복잡함이 내 눈앞에서 풀리기 시작했고 나는 새롭게 발견한 이해 로 가득 차 있었습니다.
이제 이 언어로 자신있게 코드를 작성할 수 있게 되어 다양한 아이디어를 생생하게 표현할 수 있게 된 것을 자랑스럽게 생각합니다.
Mojo는 Modular Inc의 프로그래밍 언어입니다. Mojo가 여기서 논의한 이유. 회사에 대해서는 우리가 아는 바가 거의 없지만, Modular 라는 매우 멋진 이름을 가지고 있습니다.
"즉, Mojo는 마법이 아니라 모듈식입니다."
컴퓨팅, 프로그래밍, AI/ML에 관한 모든 것. 회사의 의미를 정확하게 설명하는 아주 좋은 도메인 이름입니다.
Modular의 브랜드 스토리와 Modular가 브랜드를 통해 AI를 인간화하도록 돕는 데 대한 추가 자료가 있습니다.
오늘은 Python Enum 문제에 대한 이야기를 하고 싶습니다. 소프트웨어 엔지니어로서 우리는 종종 웹에서 이를 접합니다. 상태 enum 이 포함된 데이터베이스 스키마(PostgreSQL)가 있다고 가정합니다.
CREATE TYPE public .status_type AS ENUM (
' FIRST ' ,
' SECOND '
);Python 코드에서는 이름과 값이 문자열로 필요하며(프런트엔드 측에 일부 ENUM 유형과 함께 GraphQL을 사용한다고 가정), 순서를 유지하고 이러한 열거형을 비교할 수 있는 기능이 있어야 합니다.
order2.status > order1.status > 'FIRST'
따라서 이는 대부분의 일반 언어에서 문제가 됩니다 =). 하지만 little-known Python 기능을 사용하고 열거형 클래스 메서드인 __new__ 재정의할 수 있습니다.
MALE -> 1 , FEMALE -> 2 , PostgreSQL과 같습니다.len 함수를 사용하여 멤버 수를 계산하세요! import enum
from functools import total_ordering
@ total_ordering
@ enum . unique
class BaseUniqueSortedEnum ( enum . Enum ):
"""Base unique enum class with ordering."""
def __new__ ( cls , * args , ** kwargs ):
obj = object . __new__ ( cls )
obj . index = len ( cls . __members__ ) + 1 # This code line is a piece of advice, an insight and a tip!
return obj
# and then boring Python's magic methods as usual...
def __hash__ ( self ) -> int :
return hash (
f" { self . __module__ } _ { self . __class__ . __name__ } _ { self . name } _ { self . value } "
)
def __eq__ ( self , other ) -> bool :
self . _check_type ( other )
return super (). __eq__ ( other )
def __lt__ ( self , other ) -> bool :
self . _check_type ( other )
return self . index < other . index
def _check_type ( self , other ) -> None :
if type ( self ) != type ( other ):
raise TypeError ( f"Different types of Enum: { self } != { other } " )
class Dog ( BaseUniqueSortedEnum ):
# THIS ORDER MATTERS!
BLOODHOUND = "BLOODHOUND"
WEIMARANER = "WEIMARANER"
SAME = "SAME"
class Cat ( BaseUniqueSortedEnum )
# THIS ORDER MATTERS!
BRITISH = "BRITISH"
SCOTTISH = "SCOTTISH"
SAME = "SAME"
# and some tests
assert Dog . BLOODHOUND < Dog . WEIMARANER
assert Dog . BLOODHOUND <= Dog . WEIMARANER
assert Dog . BLOODHOUND != Dog . WEIMARANER
assert Dog . BLOODHOUND == Dog . BLOODHOUND
assert Dog . WEIMARANER == Dog . WEIMARANER
assert Dog . WEIMARANER > Dog . BLOODHOUND
assert Dog . WEIMARANER >= Dog . BLOODHOUND
assert Cat . BRITISH < Cat . SCOTTISH
assert Cat . BRITISH <= Cat . SCOTTISH
assert Cat . BRITISH != Cat . SCOTTISH
assert Cat . BRITISH == Cat . BRITISH
assert Cat . SCOTTISH == Cat . SCOTTISH
assert Cat . SCOTTISH > Cat . BRITISH
assert Cat . SCOTTISH >= Cat . BRITISH
assert hash ( Dog . BLOODHOUND ) == hash ( Dog . BLOODHOUND )
assert hash ( Dog . WEIMARANER ) == hash ( Dog . WEIMARANER )
assert hash ( Dog . BLOODHOUND ) != hash ( Dog . WEIMARANER )
assert hash ( Dog . SAME ) != hash ( Cat . SAME )
# raise TypeError
Dog . SAME <= Cat . SAME
Dog . SAME < Cat . SAME
Dog . SAME > Cat . SAME
Dog . SAME >= Cat . SAME
Dog . SAME != Cat . SAME 이야기의 끝. 그리고 이 Python ENUM 통찰력을 귀하의 코딩에 활용해보세요!


